Kopírování dat z Azure Data Lake Storage Gen1 do Gen2 pomocí Azure Data Factory
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Azure Data Lake Storage Gen2 je sada funkcí vyhrazených pro analýzy velkých objemů dat, která je integrovaná do služby Azure Blob Storage. Můžete ji použít pro připojení k datům pomocí paradigmat systému souborů a úložiště objektů.
Pokud aktuálně používáte Azure Data Lake Storage Gen1, můžete azure Data Lake Storage Gen2 vyhodnotit zkopírováním dat z Data Lake Storage Gen1 do Gen2 pomocí Azure Data Factory.
Azure Data Factory je plně spravovaná cloudová služba pro integraci dat. Pomocí této služby můžete naplnit jezero daty z bohaté sady místních a cloudových úložišť dat a ušetřit čas při vytváření analytických řešení. Seznam podporovaných konektorů najdete v tabulce podporovaných úložišť dat.
Azure Data Factory nabízí řešení pro přesun dat se škálováním na více instancí. Vzhledem k architektuře služby Data Factory se škálováním na více instancí může ingestovat data s vysokou propustností. Další informace najdete v tématu aktivita Copy výkonu.
V tomto článku se dozvíte, jak pomocí nástroje Data Factory kopírovat data z Azure Data Lake Storage Gen1 do Azure Data Lake Storage Gen2. Podobným postupem můžete kopírovat data z jiných typů úložišť dat.
Požadavky
- Předplatné Azure. Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
- Účet Azure Data Lake Storage Gen1 s daty v něm
- Účet Azure Storage s povolenou službou Data Lake Storage Gen2 Pokud účet úložiště nemáte, vytvořte si ho.
Vytvoření datové továrny
Pokud jste ještě nevytvořili datovou továrnu, postupujte podle kroků v rychlém startu: Vytvoření datové továrny pomocí webu Azure Portal a nástroje Azure Data Factory Studio k jeho vytvoření. Po vytvoření přejděte na webu Azure Portal k datové továrně.

Na dlaždici Otevřít azure Data Factory Studio vyberte Otevřít, aby se aplikace Integrace Dat spustila na samostatné kartě.
Načtení dat do Azure Data Lake Storage Gen2
Na domovské stránce vyberte dlaždici Ingestování a spusťte nástroj pro kopírování dat.
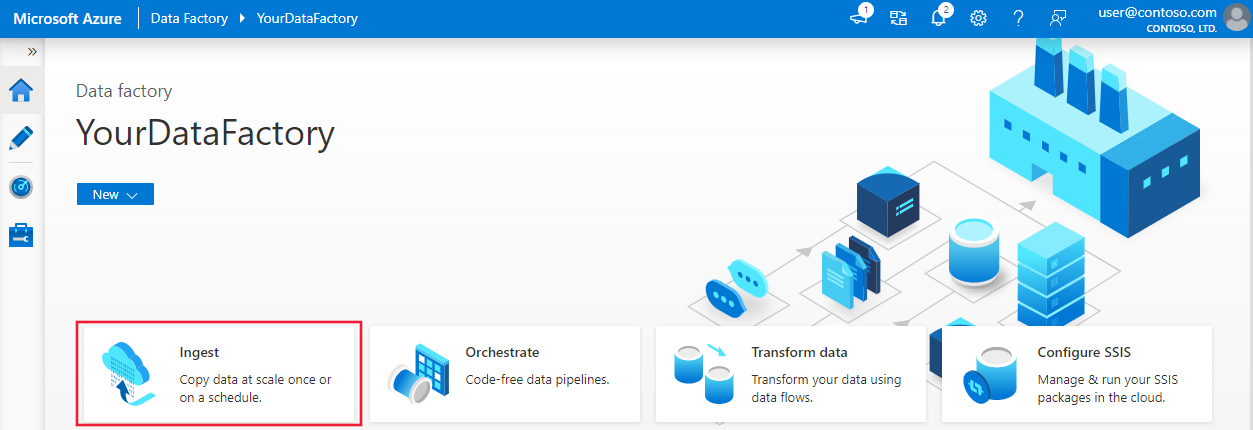
Na stránce Vlastnosti zvolte předdefinovaný úkol kopírování v části Typ úlohy a zvolte Spustit jednou podpořadím úkolů nebo plánem úkolu a pak vyberte Další.
Na stránce Zdrojové úložiště dat vyberte + Nové připojení.
V galerii konektorů vyberte Azure Data Lake Storage Gen1 a vyberte Pokračovat.
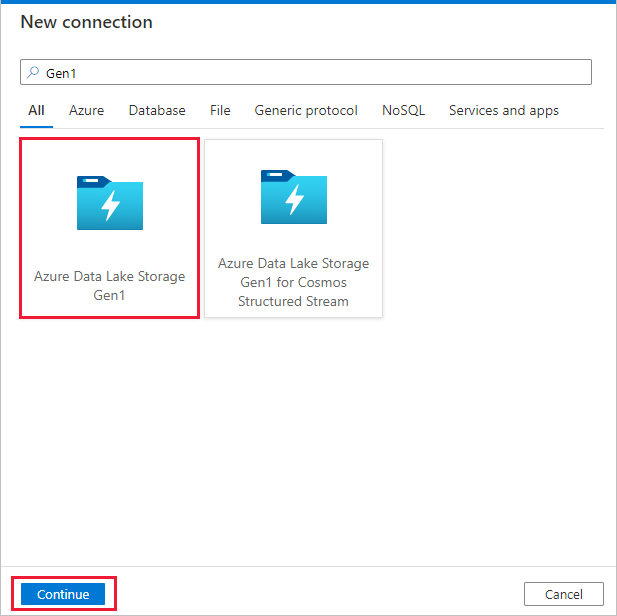
Na stránce Nové připojení (Azure Data Lake Storage Gen1) postupujte takto:
- Jako název účtu vyberte Data Lake Storage Gen1 a zadejte nebo ověřte tenanta.
- Výběrem možnosti Test připojení ověřte nastavení. Pak vyberte Vytvořit.
Důležité
V tomto návodu použijete spravovanou identitu pro prostředky Azure k ověření azure Data Lake Storage Gen1. Pokud chcete spravované identitě udělit správná oprávnění ve službě Azure Data Lake Storage Gen1, postupujte podle těchto pokynů.
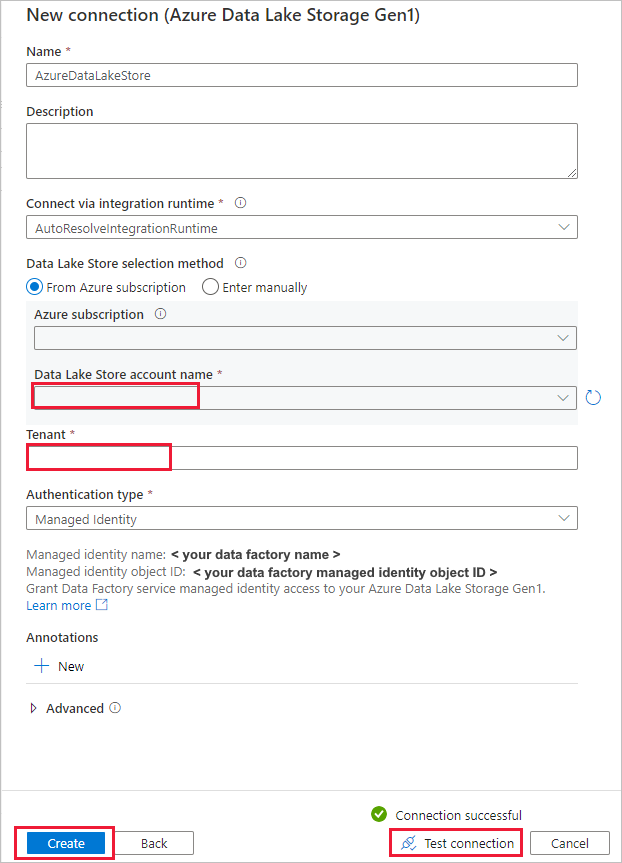
Na stránce Zdrojové úložiště dat proveďte následující kroky.
- V části Připojení vyberte nově vytvořené připojení.
- V části Soubor nebo složka přejděte do složky a souboru, který chcete zkopírovat. Vyberte složku nebo soubor a vyberte OK.
- Zadejte chování kopírování tak , že vyberete možnosti rekurzivního a binárního kopírování . Vyberte Další.

Na stránce Cílové úložiště dat vyberte + Nové připojení>Azure Data Lake Storage Gen2>Pokračovat.
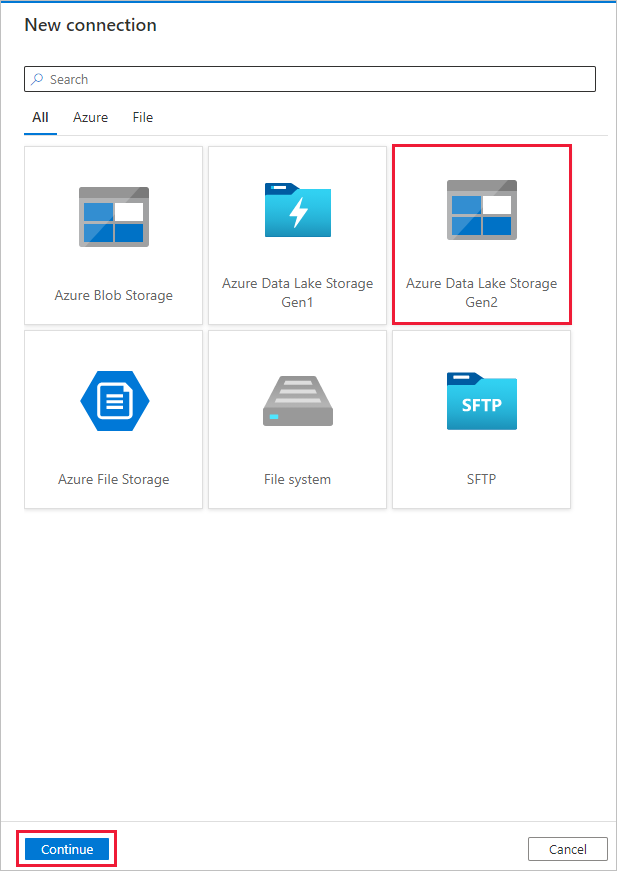
Na stránce Nové připojení (Azure Data Lake Storage Gen2) postupujte takto:
- V rozevíracím seznamu s názvem účtu úložiště vyberte svůj účet podporující Data Lake Storage Gen2.
- Výběrem Vytvořit vytvoříte propojení.
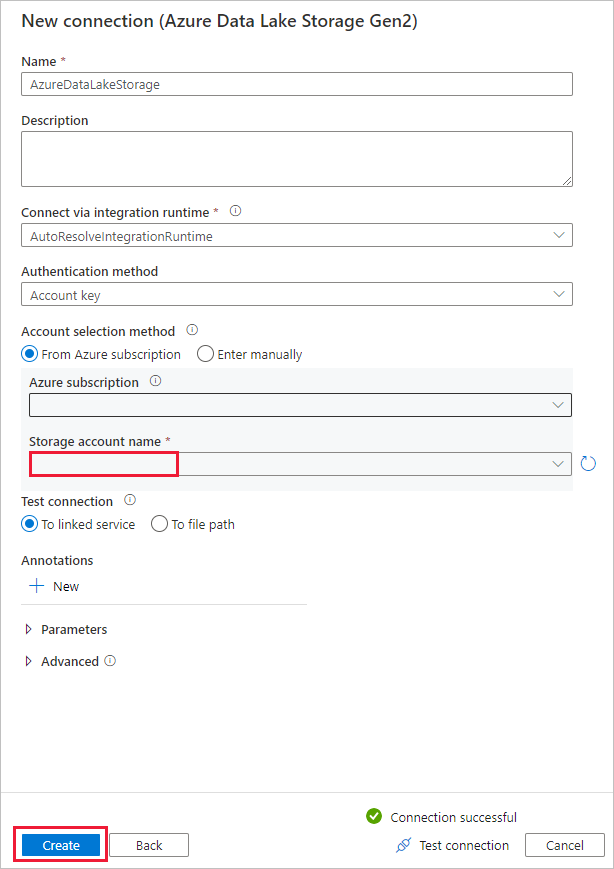
Na stránce Cílové úložiště dat proveďte následující kroky.
- V bloku připojení vyberte nově vytvořené připojení.
- V části Cesta ke složce zadejte copyfromadlsgen1 jako název výstupní složky a vyberte Další. Data Factory během kopírování vytvoří odpovídající systém souborů a podsložky Azure Data Lake Storage Gen2, pokud neexistují.
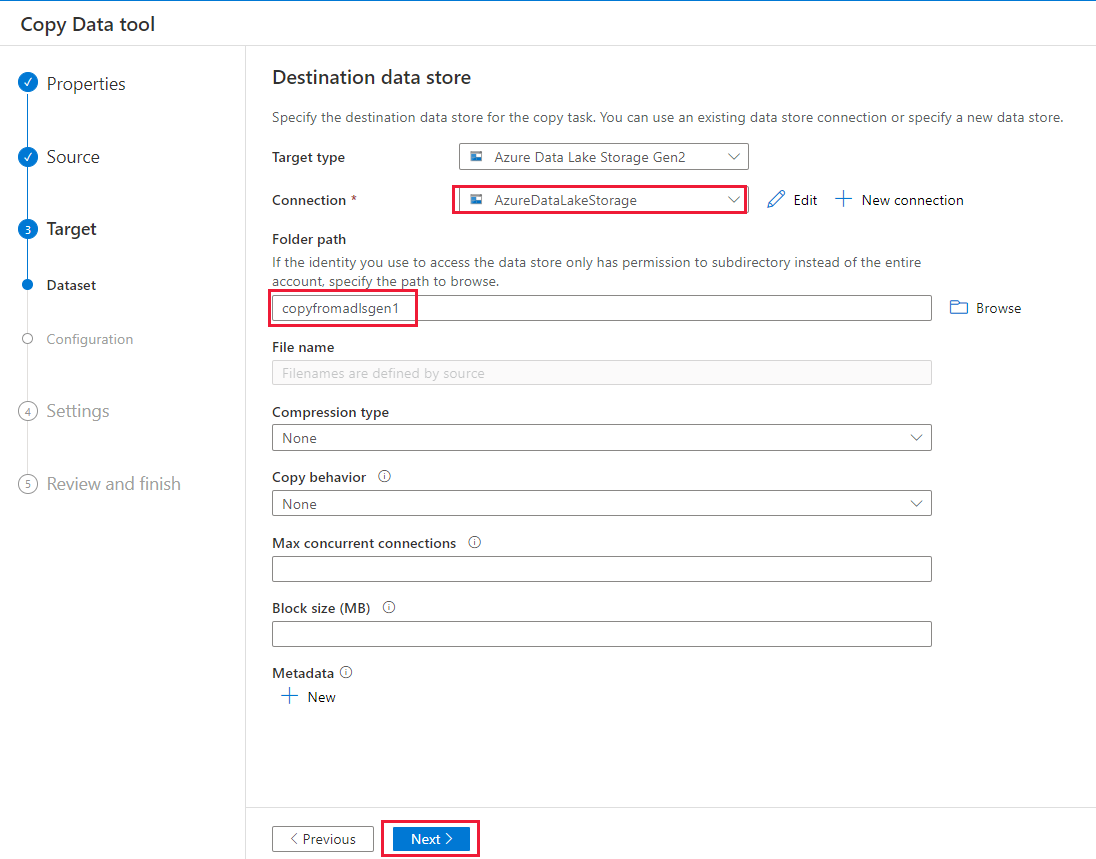
Na stránce Nastavení zadejte copyFromADLSGen1ToGen2 pro pole Název úkolu a pak vyberte Další, chcete-li použít výchozí nastavení.
Na stránce Souhrn zkontrolujte nastavení a vyberte Další.
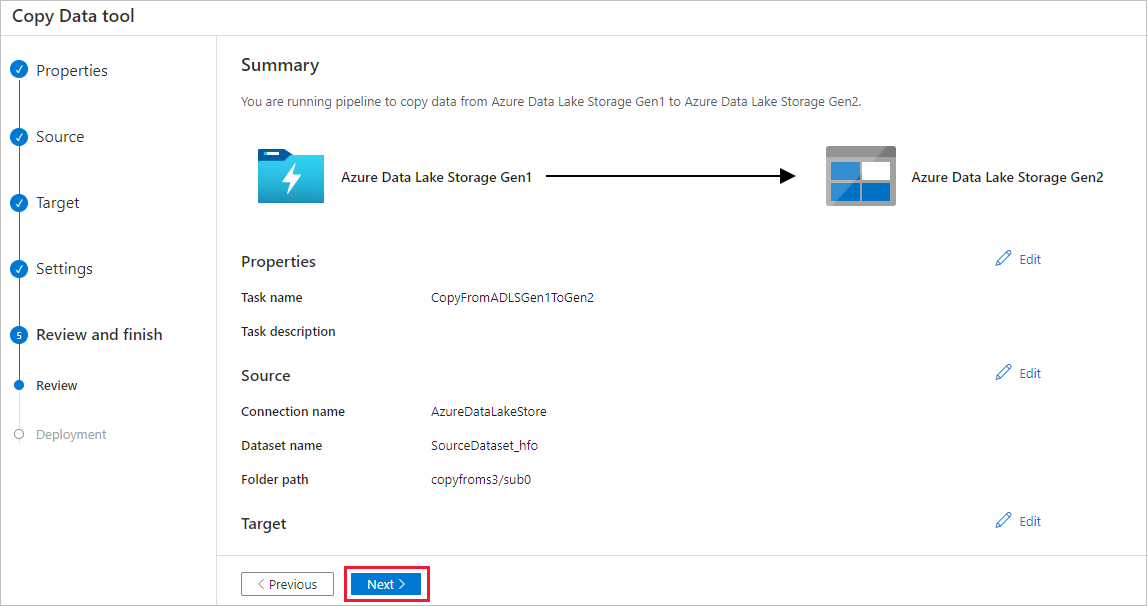
Na stránce Nasazení vyberte Monitorování, abyste mohli kanál monitorovat.
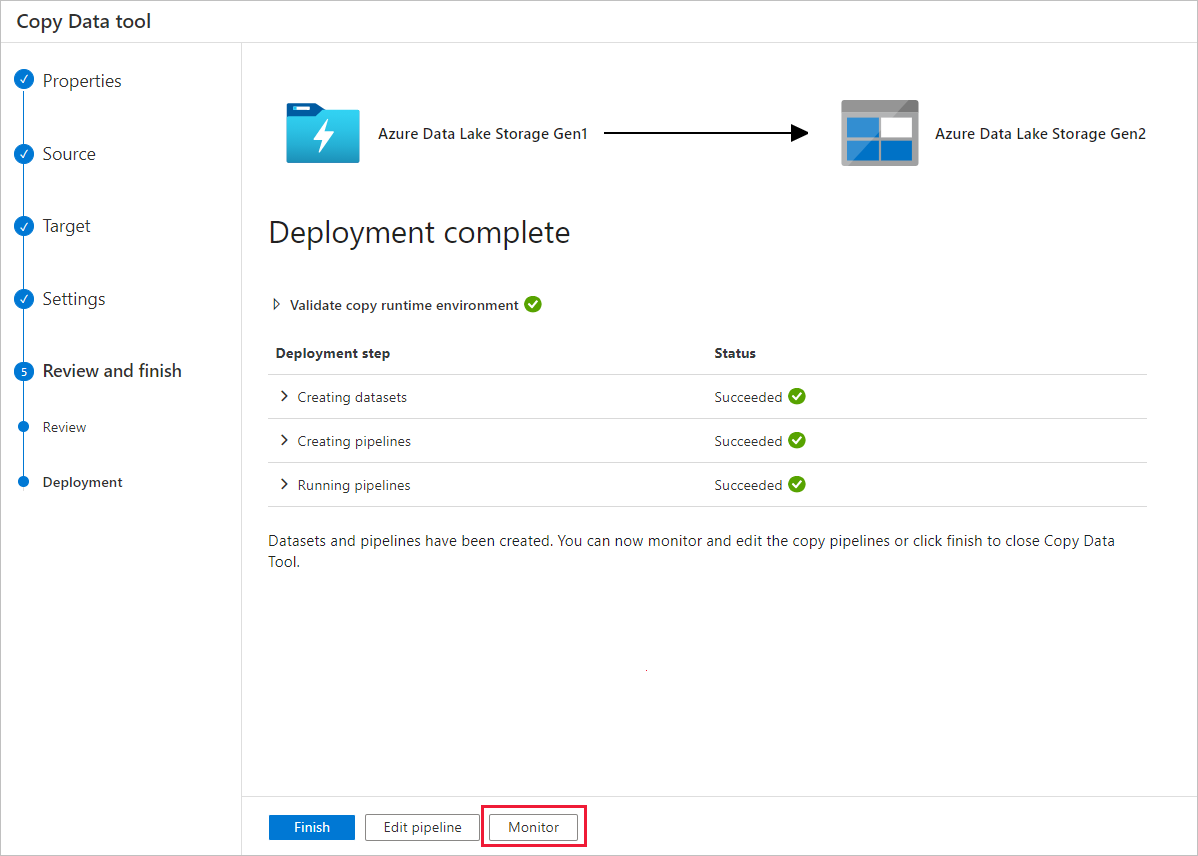
Všimněte si, že je vlevo automaticky vybraná karta Monitorování. Sloupec Název kanálu obsahuje odkazy na zobrazení podrobností o spuštění aktivit a opětovné spuštění kanálu.
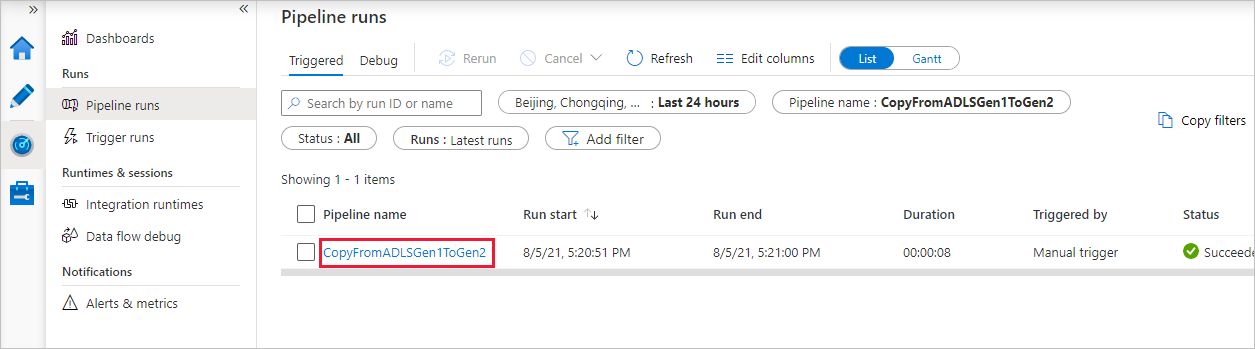
Pokud chcete zobrazit spuštění aktivit přidružená ke spuštění kanálu, vyberte odkaz ve sloupci Název kanálu. Kanál obsahuje pouze jednu aktivitu (aktivita kopírování), takže se zobrazí pouze jedna položka. Pokud chcete přepnout zpět do zobrazení spuštění kanálu, vyberte odkaz Všechna spuštění kanálu v nabídce s popisem cesty v horní části. Seznam můžete aktualizovat kliknutím na Aktualizovat.
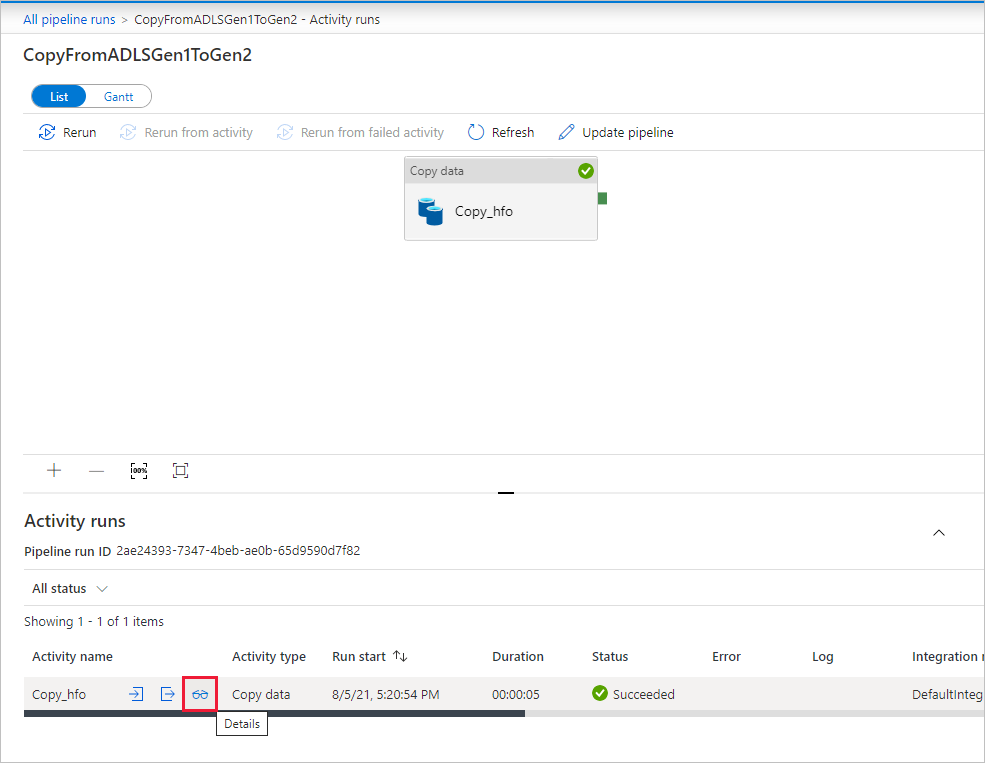
Pokud chcete monitorovat podrobnosti o spuštění pro každou aktivitu kopírování, vyberte odkaz Podrobnosti (obrázek brýle) pod sloupcem Název aktivity v zobrazení monitorování aktivit. Můžete monitorovat podrobnosti, jako je objem dat zkopírovaný ze zdroje do jímky, propustnost dat, kroky provádění s odpovídající dobou trvání a použité konfigurace.
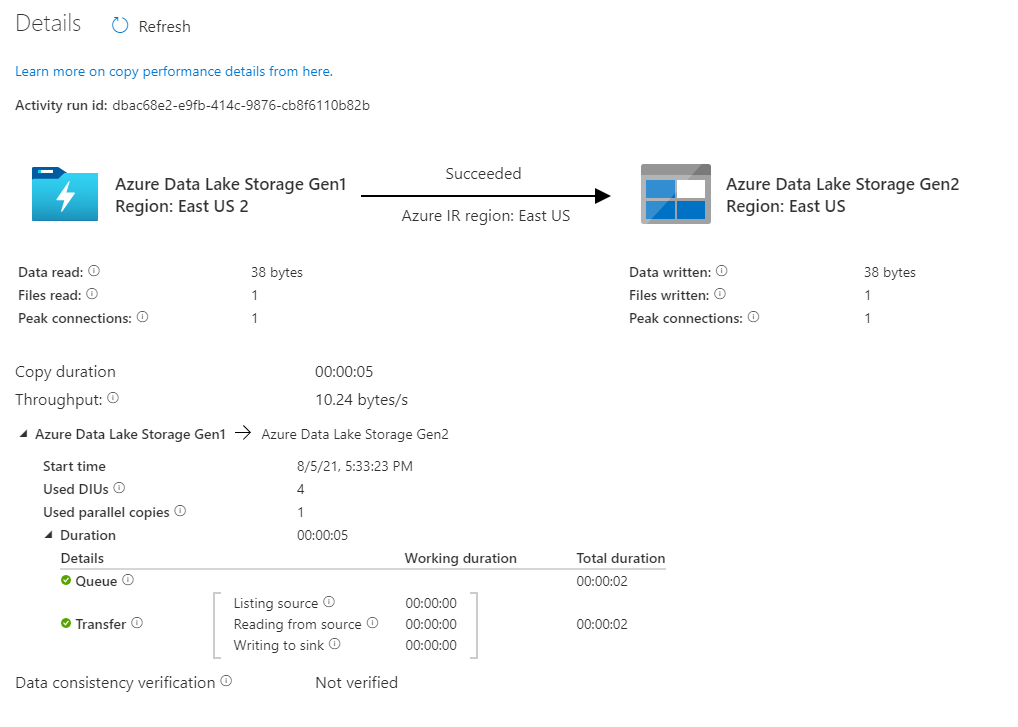
Ověřte, že se data zkopírují do vašeho účtu Azure Data Lake Storage Gen2.
Osvědčené postupy
Pokud chcete obecně posoudit upgrade z Azure Data Lake Storage Gen1 na Azure Data Lake Storage Gen2, přečtěte si téma Upgrade řešení analýzy velkých objemů dat z Azure Data Lake Storage Gen1 na Azure Data Lake Storage Gen2. Následující části představují osvědčené postupy pro použití služby Data Factory pro upgrade dat z Data Lake Storage Gen1 na Data Lake Storage Gen2.
Počáteční migrace dat snímků
Výkon
ADF nabízí bezserverovou architekturu, která umožňuje paralelismus na různých úrovních, což vývojářům umožňuje vytvářet kanály, aby plně využili šířku pásma sítě a IOPS úložiště a šířku pásma pro maximalizaci propustnosti přesunu dat pro vaše prostředí.
Zákazníci úspěšně migrovali petabajty dat sestávajících ze stovek milionů souborů z Data Lake Storage Gen1 na Gen2 s trvalou propustností 2 GB/s a vyšší.
Vyšší rychlosti přesunu dat můžete dosáhnout použitím různých úrovní paralelismu:
- Jedna aktivita kopírování může využívat škálovatelné výpočetní prostředky: při použití prostředí Azure Integration Runtime můžete pro každou aktivitu kopírování zadat až 256 jednotek integrace dat (DIU) bez serveru. Při použití místního prostředí Integration Runtime můžete ručně vertikálně navýšit kapacitu počítače nebo škálovat na více počítačů (až 4 uzly). a jedna aktivita kopírování rozdělí soubor nastavený na všechny uzly.
- Jedna aktivita kopírování čte z úložiště dat a zapisuje se do úložiště dat pomocí více vláken.
- Tok řízení ADF může paralelně spouštět více aktivit kopírování, například pomocí smyčky For Each.
Datové oddíly
Pokud je celková velikost dat ve službě Data Lake Storage Gen1 menší než 10 TB a počet souborů je menší než 1 milion, můžete zkopírovat všechna data během jednoho spuštění aktivity kopírování. Pokud máte větší množství dat ke kopírování nebo chcete flexibilně spravovat migraci dat v dávkách a provést jejich dokončení v určitém časovém rámci, rozdělte data do oddílů. Dělení také snižuje riziko jakéhokoli neočekávaného problému.
Způsob, jak rozdělit soubory, je použít rozsah názvů- listAfter/listBefore ve vlastnosti aktivity kopírování. Každou aktivitu kopírování je možné nakonfigurovat tak, aby současně zkopírovala jeden oddíl, aby více aktivit kopírování bylo možné kopírovat data z jednoho účtu Data Lake Storage Gen1 současně.
Omezování rychlosti
Osvědčeným postupem je provedení poc výkonu se reprezentativní ukázkovou datovou sadou, abyste mohli určit odpovídající velikost oddílu.
Začněte s jedním oddílem a jednou aktivitou kopírování s výchozím nastavením DIU. Paralelní kopie je vždy navržena tak, aby byla nastavena jako prázdná (výchozí). Pokud propustnost kopírování není pro vás vhodná, pomocí kroků ladění výkonu zjistěte a vyřešte kritické body výkonu.
Postupně zvyšte nastavení DIU, dokud nedosáhnete limitu šířky pásma sítě nebo vstupně-výstupních operací za sekundu a šířky pásma úložišť dat, nebo jste dosáhli maximálního počtu 256 DIU povolených u jedné aktivity kopírování.
Pokud jste maximalizovali výkon jedné aktivity kopírování, ale ještě jste nedosáhli horních limitů propustnosti vašeho prostředí, můžete paralelně spustit více aktivit kopírování.
Když se při monitorování aktivit kopírování zobrazí velký počet chyb omezování, znamená to, že jste dosáhli limitu kapacity účtu úložiště. ADF se pokusí automaticky překonat každou chybu omezování, aby se zajistilo, že nedojde ke ztrátě dat, ale příliš mnoho opakování může snížit také propustnost kopírování. V takovém případě se doporučuje snížit počet spuštěných aktivit kopírování, aby nedocházelo k významným chybám omezování. Pokud jste ke kopírování dat používali jednu aktivitu kopírování, doporučujeme snížit DIU.
Rozdílová migrace dat
K načtení pouze nových nebo aktualizovaných souborů z Data Lake Storage Gen1 můžete použít několik přístupů:
- Načtěte nové nebo aktualizované soubory podle času rozdělené složky nebo názvu souboru. Příkladem je /2019/05/13/*.
- Načtěte nové nebo aktualizované soubory podle lastModifiedDate. Pokud kopírujete velké objemy souborů, nejprve proveďte oddíly, aby se zabránilo nízké propustnosti kopírování z důvodu prohledávání celé aktivity kopírování v celém účtu Data Lake Storage Gen1 a identifikujte nové soubory.
- Identifikujte nové nebo aktualizované soubory pomocí libovolného nástroje nebo řešení třetích stran. Pak předejte název souboru nebo složky kanálu Data Factory prostřednictvím parametru nebo tabulky nebo souboru.
Správná frekvence přírůstkového načítání závisí na celkovém počtu souborů ve službě Azure Data Lake Storage Gen1 a na svazku nových nebo aktualizovaných souborů, které se mají načíst pokaždé.
Zabezpečení sítě
Ve výchozím nastavení ADF přenáší data z Azure Data Lake Storage Gen1 do Gen2 pomocí šifrovaného připojení přes protokol HTTPS. HTTPS poskytuje šifrování přenášených dat a zabraňuje odposlouchávání a útokům typu man-in-the-middle.
Pokud nechcete, aby se data přenášela přes veřejný internet, můžete dosáhnout vyššího zabezpečení přenosem dat přes privátní síť.
Zachování seznamů ACL
Pokud chcete replikovat seznamy ACL spolu s datovými soubory při upgradu z Data Lake Storage Gen1 na Data Lake Storage Gen2, přečtěte si téma Zachování seznamů ACL z Data Lake Storage Gen1.
Odolnost
V rámci jednoho spuštění aktivity kopírování má ADF integrovaný mechanismus opakování, aby mohl zpracovávat určitou úroveň přechodných selhání v úložištích dat nebo v podkladové síti. Pokud migrujete více než 10 TB dat, doporučujeme data rozdělit do oddílů, abyste snížili riziko neočekávaných problémů.
Můžete také povolit odolnost proti chybám v aktivitě kopírování a přeskočit předdefinované chyby. Ověření konzistence dat v aktivitě kopírování je také možné povolit k dalšímu ověření, aby se zajistilo, že se data nejen úspěšně zkopírují ze zdroje do cílového úložiště, ale také ověří, že jsou konzistentní mezi zdrojem a cílovým úložištěm.
Oprávnění
Konektor Data Lake Storage Gen1 ve službě Data Factory podporuje instanční objekt a spravovanou identitu pro ověřování prostředků Azure. Konektor Data Lake Storage Gen2 podporuje klíč účtu, instanční objekt a spravovanou identitu pro ověřování prostředků Azure. Pokud chcete, aby služba Data Factory mohla procházet a kopírovat všechny soubory nebo seznamy řízení přístupu (ACL), budete muset účtu udělit dostatečná oprávnění pro přístup, čtení nebo zápis všech souborů a nastavení seznamů ACL, pokud se rozhodnete. Po dokončení migrace byste měli účtu udělit roli superuživatele nebo vlastníka a po dokončení migrace odebrat zvýšená oprávnění.