Analýza transformace v mapování toku dat
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Toky dat jsou k dispozici ve službě Azure Data Factory i v kanálech Azure Synapse. Tento článek se týká mapování toků dat. Pokud s transformacemi začínáte, přečtěte si úvodní článek Transformace dat pomocí mapování toku dat.
Pomocí transformace parsování můžete analyzovat textové sloupce v datech, které jsou řetězce ve formuláři dokumentu. Aktuální podporované typy vložených dokumentů, které je možné analyzovat, jsou JSON, XML a text s oddělovači.
Konfigurace
Na konfiguračním panelu analýzy transformace nejprve vyberete typ dat obsažených ve sloupcích, které chcete analyzovat jako vložený. Transformace analýzy obsahuje také následující nastavení konfigurace.

Column
Podobně jako odvozené sloupce a agregace je vlastnost Column tam, kde buď upravíte existující sloupec tak, že ho vyberete z rozevíracího výběru. Nebo můžete sem zadat název nového sloupce. ADF ukládá analyzovaná zdrojová data v tomto sloupci. Ve většině případů chcete definovat nový sloupec, který analyzuje pole řetězce příchozího vloženého dokumentu.
Výraz
Pomocí tvůrce výrazů nastavte zdroj pro analýzu. Nastavení zdroje může být stejně jednoduché jako jen výběr zdrojového sloupce s daty, která chcete analyzovat, nebo můžete vytvořit složité výrazy pro analýzu.
Příklady výrazů
Zdrojová řetězcová data:
chrome|steel|plastic- Výraz:
(desc1 as string, desc2 as string, desc3 as string)
- Výraz:
Zdrojová data JSON:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- Výraz:
(level as string, registration as long)
- Výraz:
Zdrojová vnořená data JSON:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- Výraz:
(car as (model as string, year as integer), color as string, transmission as string)
- Výraz:
Zdrojová data XML:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- Výraz:
(Customers as (Customer as integer, CompanyName as string))
- Výraz:
Zdrojový KÓD XML s daty atributů:
<cars><car model="camaro"><year>1989</year></car></cars>- Výraz:
(cars as (car as ({@model} as string, year as integer)))
- Výraz:
Výrazy s vyhrazenými znaky:
{ "best-score": { "section 1": 1234 } }- Výše uvedený výraz nefunguje, protože znak
best-score"-" je interpretován jako operace odčítání. Pomocí proměnné s zápisem závorek v těchto případech řekněte modulu JSON, aby text interpretovat doslova:var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- Výše uvedený výraz nefunguje, protože znak
Poznámka: Pokud dojde k chybám extrahování atributů (konkrétně @model) z komplexního typu, alternativním řešením je převést komplexní typ na řetězec, odebrat symbol @ (konkrétně nahradit(toString(your_xml_string_parsed_column_name.cars.car),'@',') a pak použít transformační aktivitu PARSE JSON.
Typ výstupního sloupce
Tady je místo, kde nakonfigurujete cílové výstupní schéma z analýzy, která je zapsaná do jednoho sloupce. Nejjednodušší způsob, jak nastavit schéma pro výstup z analýzy, je vybrat tlačítko Zjistit typ v pravém horním rohu tvůrce výrazů. ADF se pokusí automaticky zjistit schéma z pole řetězce, které analyzujete a nastavíte ho ve výstupním výrazu.
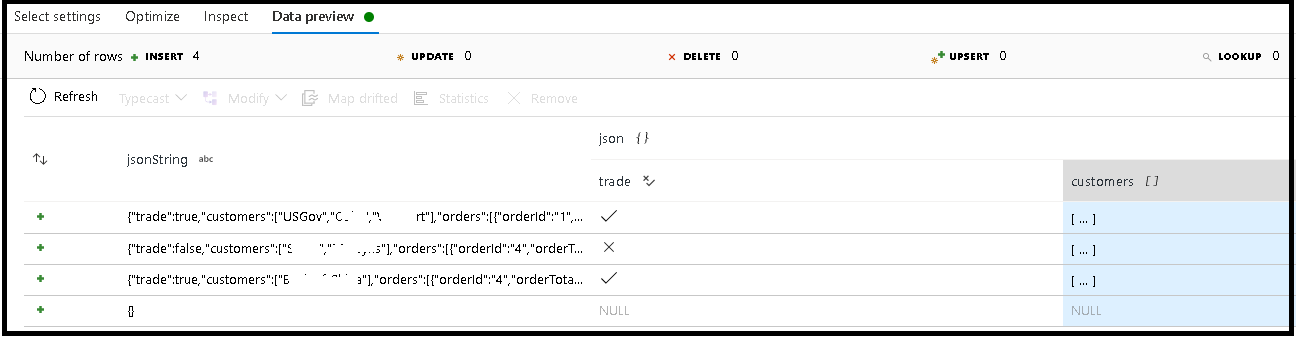
V tomto příkladu jsme definovali analýzu příchozího pole jsonString, což je prostý text, ale formátovaný jako struktura JSON. Analyzované výsledky uložíme jako JSON do nového sloupce s názvem json s tímto schématem:
(trade as boolean, customers as string[])
Zkontrolujte kartu kontroly a náhled dat a ověřte, že je výstup správně namapovaný.
Pomocí aktivity Odvozený sloupec extrahujte hierarchická data (tj. your_complex_column_name.car.model v poli výrazu).
Příklady
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
Skript toku dat
Syntaxe
Příklady
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
Související obsah
- Pomocí zploštěné transformace můžete převést řádky na sloupce.
- Transformace odvozeného sloupce slouží k transformaci řádků.