Vytváření výrazů v mapování toku dat
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
V mapování toku dat se jako výrazy zadá mnoho vlastností transformace. Tyto výrazy se skládají z hodnot sloupců, parametrů, funkcí, operátorů a literálů, které se vyhodnocují jako datový typ Sparku za běhu. Mapování toků dat má vyhrazené prostředí, které vám pomůže při vytváření těchto výrazů označovaných jako Tvůrce výrazů. Použití dokončování kódu IntelliSense ke zvýrazňování, kontrole syntaxe a automatickému dokončování je tvůrce výrazů navržený tak, aby usnadnil vytváření toků dat. Tento článek vysvětluje, jak pomocí tvůrce výrazů efektivně vytvářet obchodní logiku.
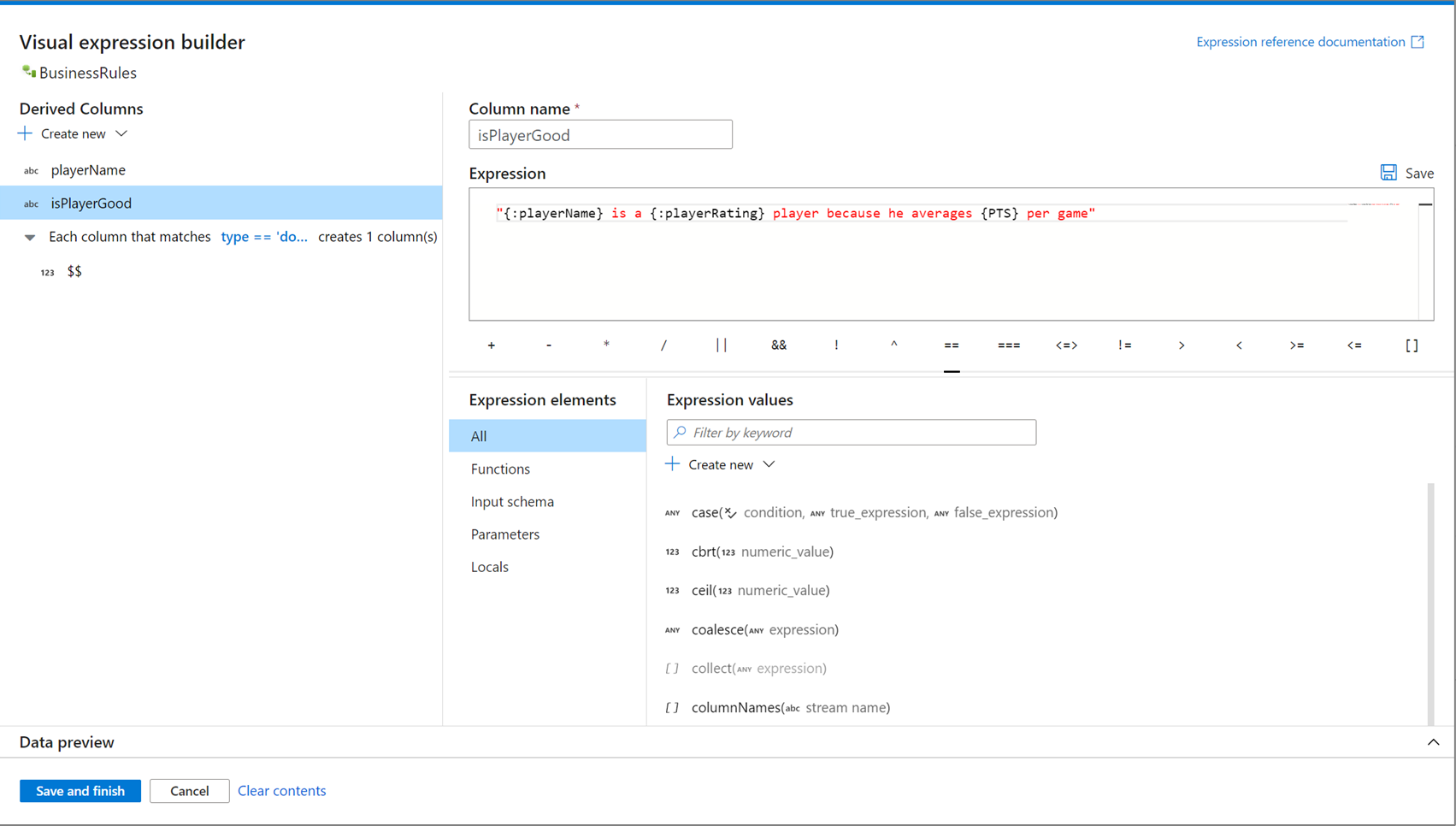
Otevření Tvůrce výrazů
Pro otevření tvůrce výrazů existuje několik vstupních bodů. Všechny jsou závislé na konkrétním kontextu transformace toku dat. Nejběžnějším případem použití jsou transformace, jako je odvozený sloupec a agregace , kde uživatelé vytvářejí nebo aktualizují sloupce pomocí jazyka výrazů toku dat. Tvůrce výrazů lze otevřít tak , že vyberete Otevřít tvůrce výrazů nad seznamem sloupců. Můžete také vybrat kontext sloupce a otevřít tvůrce výrazů přímo na tento výraz.
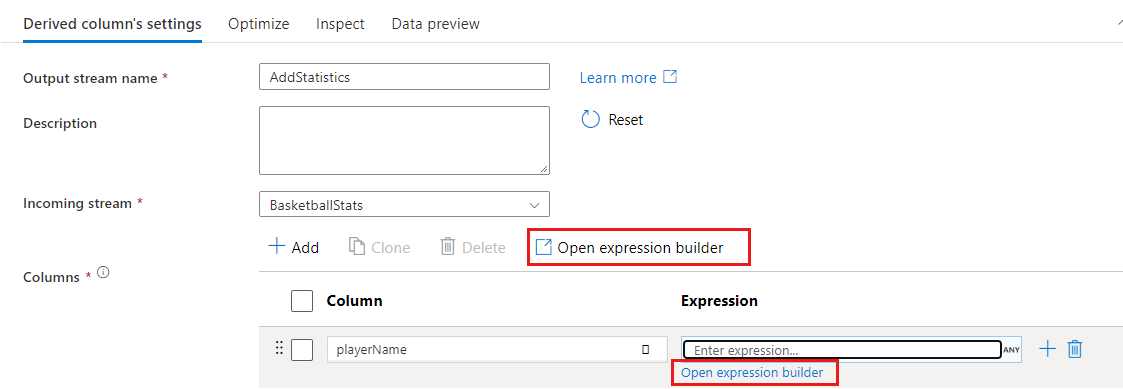
V některých transformacích, jako je filtr, se kliknutím na textové pole s modrým výrazem otevře tvůrce výrazů.
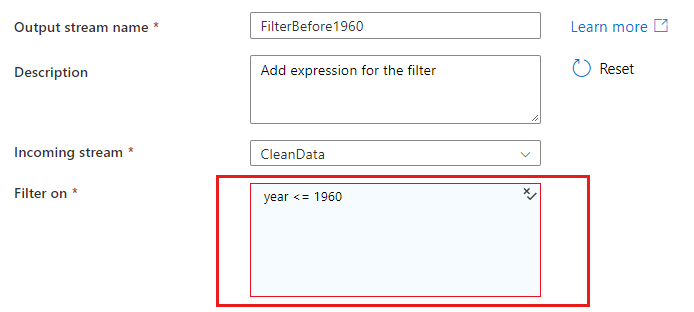
Když odkazujete na sloupce ve shodě nebo podmínce seskupit podle, výraz může extrahovat hodnoty ze sloupců. Pokud chcete vytvořit výraz, vyberte Vypočítaný sloupec.

V případech, kdy je výraz nebo hodnota literálu platnými vstupy, vyberte Přidat dynamický obsah a vytvořte výraz, který se vyhodnotí jako literálová hodnota.

Prvky výrazu
Při mapování toků dat se výrazy dají skládat z hodnot sloupců, parametrů, funkcí, místních proměnných, operátorů a literálů. Tyto výrazy musí být vyhodnoceny jako datový typ Sparku, jako je řetězec, logická hodnota nebo celé číslo.
Funkce
Mapování toků dat má předdefinované funkce a operátory, které je možné použít ve výrazech. Seznam dostupných funkcí najdete v referenčních informacích k jazyku mapování toku dat.
Uživatelem definované funkce (Preview)
Mapování toků dat podporuje vytváření a používání uživatelem definovaných funkcí. Pokud chcete zjistit, jak vytvářet a používat uživatelem definované funkce, podívejte se na uživatelem definované funkce.
Indexy pole adres
Při práci se sloupci nebo funkcemi, které vracejí typy polí, použijte pro přístup ke konkrétnímu prvku hranaté závorky ([]). Pokud index neexistuje, výraz se vyhodnotí jako NULL.
Důležité
V mapování toků dat jsou pole 1, což znamená, že první prvek je odkazován indexem. Například myArray[1] získá přístup k prvnímu prvku pole s názvem myArray.
Vstupní schéma
Pokud váš tok dat používá definované schéma v některém ze svých zdrojů, můžete na sloupec odkazovat podle názvu v mnoha výrazech. Pokud používáte posun schématu, můžete odkazovat na sloupce explicitně pomocí byName() funkcí nebo byNames() shod pomocí vzorů sloupců.
Názvy sloupců se speciálními znaky
Pokud máte názvy sloupců, které obsahují speciální znaky nebo mezery, obklopte název složenými závorkami, aby se na ně ve výrazu odkazovaly.
{[dbo].this_is my complex name$$$}
Parametry
Parametry jsou hodnoty, které se předávají do toku dat za běhu z kanálu. Pokud chcete odkazovat na parametr, vyberte parametr ze zobrazení elementů výrazu nebo na něj odkazujte znakem dolaru před jeho názvem. Například parametr s názvem parametr1 odkazuje na $parameter1parametr . Další informace najdete v tématu parametrizace mapování toků dat.
Vyhledávání v mezipaměti
Vyhledávání v mezipaměti umožňuje provést vložené vyhledávání výstupu jímky uložené v mezipaměti. Na každé jímce jsou k dispozici dvě funkce a lookup() outputs(). Syntaxe pro odkaz na tyto funkce je cacheSinkName#functionName(). Další informace najdete v tématu Jímky mezipaměti.
lookup() přebírá odpovídající sloupce v aktuální transformaci jako parametry a vrátí složitý sloupec, který se rovná řádku, který odpovídá klíčovým sloupcům v jímce mezipaměti. Vrácený složitý sloupec obsahuje podsloupce pro každý sloupec namapovaný v jímce mezipaměti. Pokud jste například měli jímku errorCodeCache mezipaměti s kódem chyby, která obsahuje sloupec klíče odpovídající kódu kódu a sloupec volaný Message. Volání errorCodeCache#lookup(errorCode).Message vrátí zprávu odpovídající kódu předaným.
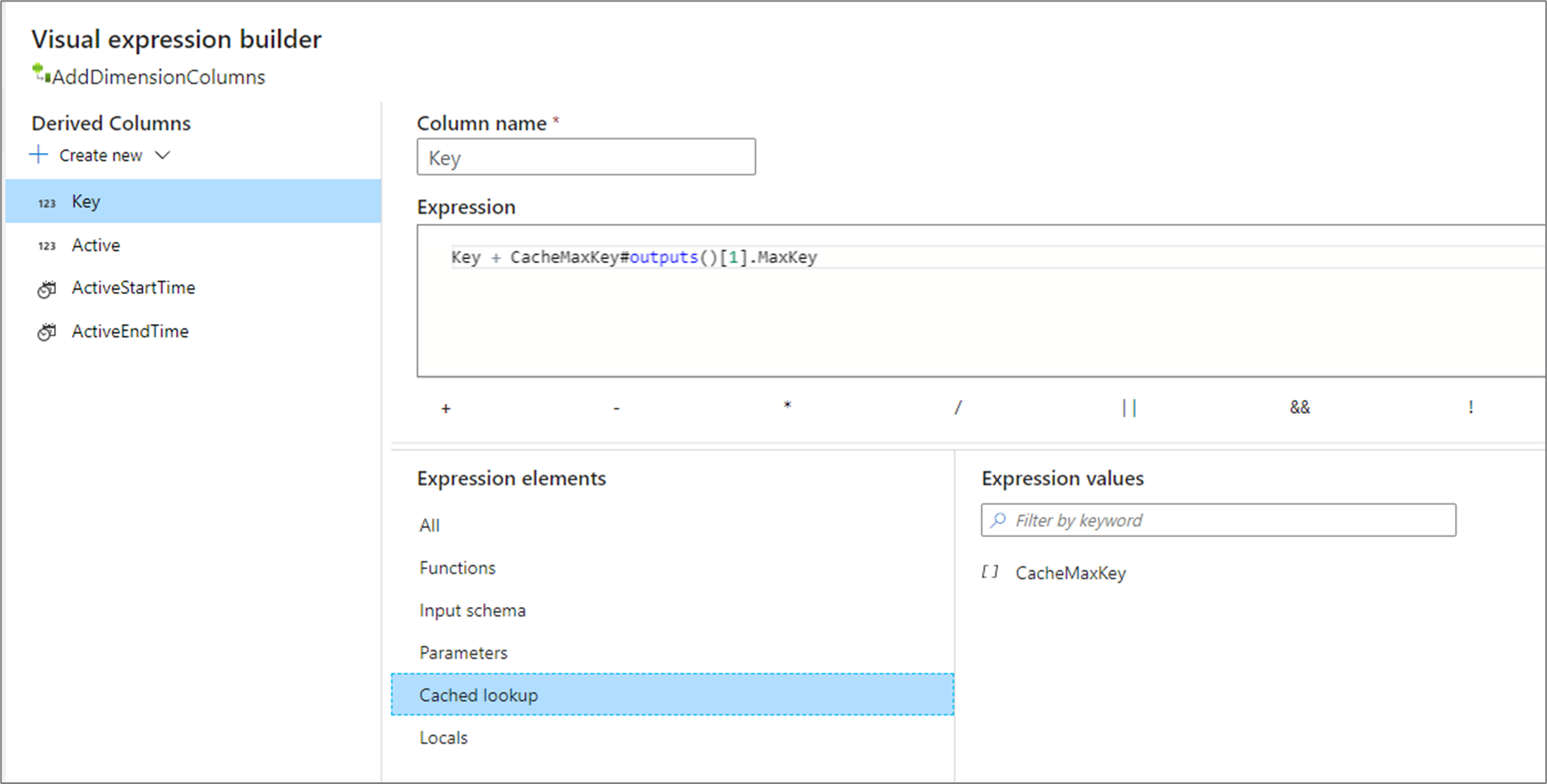
outputs() nepřijímá žádné parametry a vrací celou jímku mezipaměti jako pole složitých sloupců. Tato možnost se nedá volat, pokud jsou v jímce zadané klíčové sloupce a měly by se použít jenom v případě, že je v jímce mezipaměti několik řádků. Běžným případem použití je připojení maximální hodnoty inkrementačního klíče. Pokud jeden agregovaný řádek CacheMaxKey v mezipaměti obsahuje sloupec MaxKey, můžete na první hodnotu odkazovat voláním CacheMaxKey#outputs()[1].MaxKey.
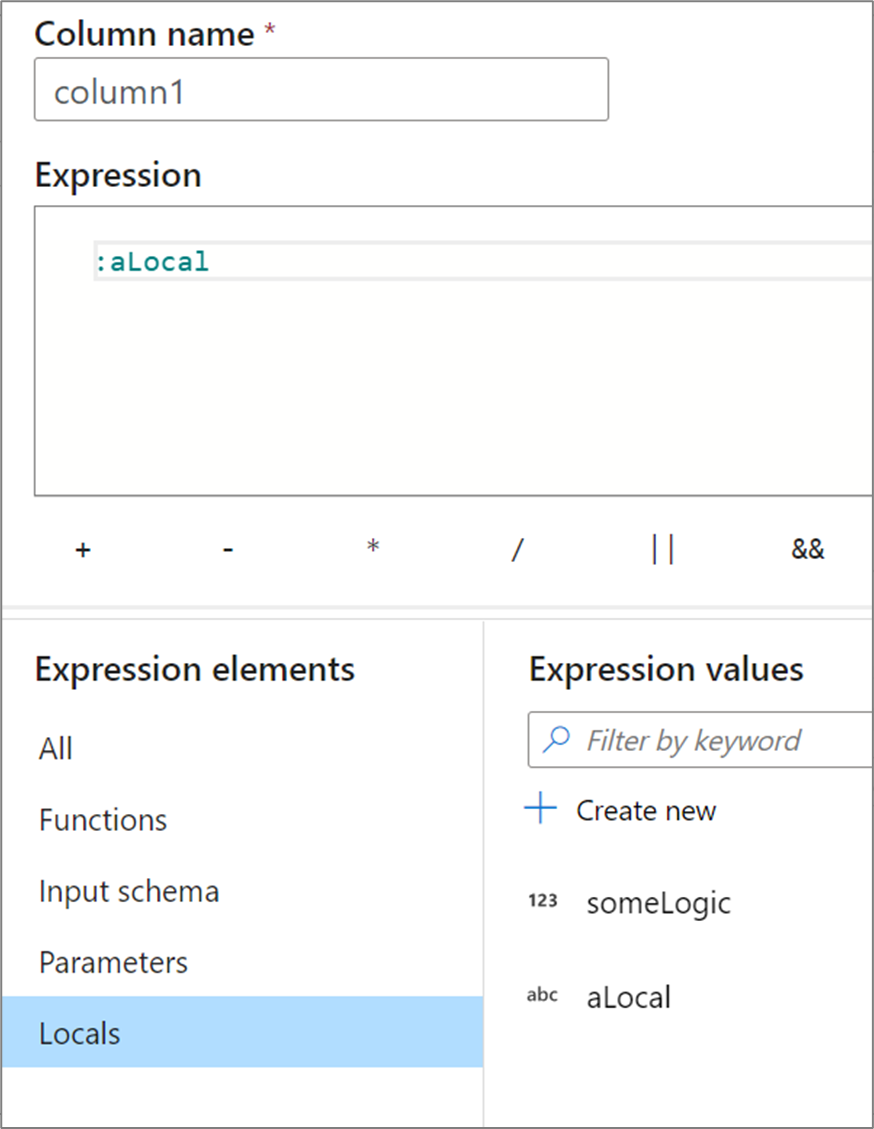
Místní hodnoty
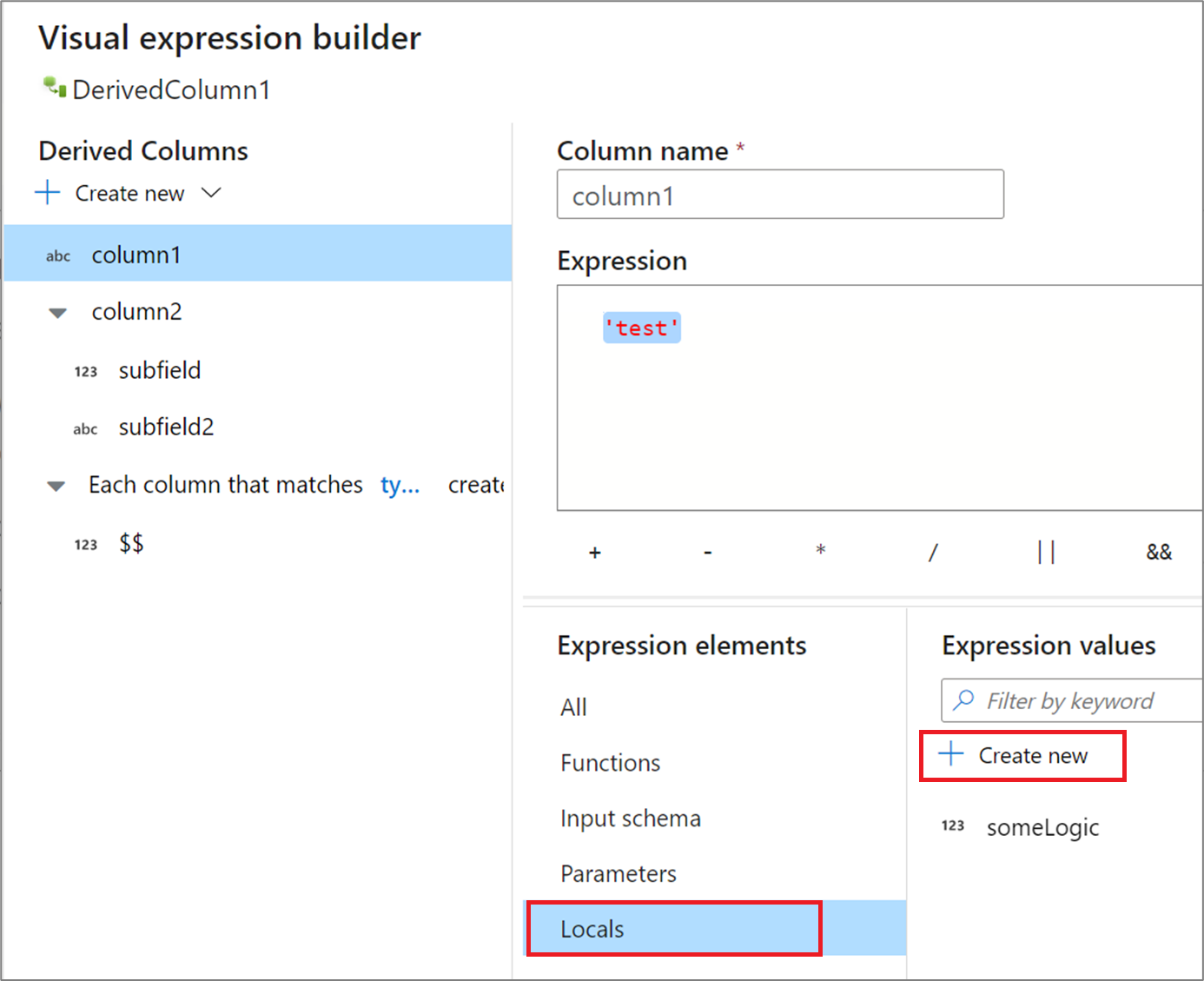
Pokud sdílíte logiku mezi více sloupci nebo chcete logiku rozčlenit do oddílů, můžete vytvořit místní proměnnou. Místní je sada logiky, která se nešířit do následující transformace. Místní hodnoty lze vytvořit v tvůrci výrazů tak, že přejdete na elementy výrazu a vyberete Místní hodnoty. Vytvořte nový výběrem možnosti Vytvořit nový.
Místní hodnoty můžou odkazovat na libovolný prvek výrazu, včetně funkcí, vstupního schématu, parametrů a jiných místních hodnot. Při odkazování na jiné místní hodnoty záleží na pořadí, protože odkazované místní musí být "nad" aktuální místní.
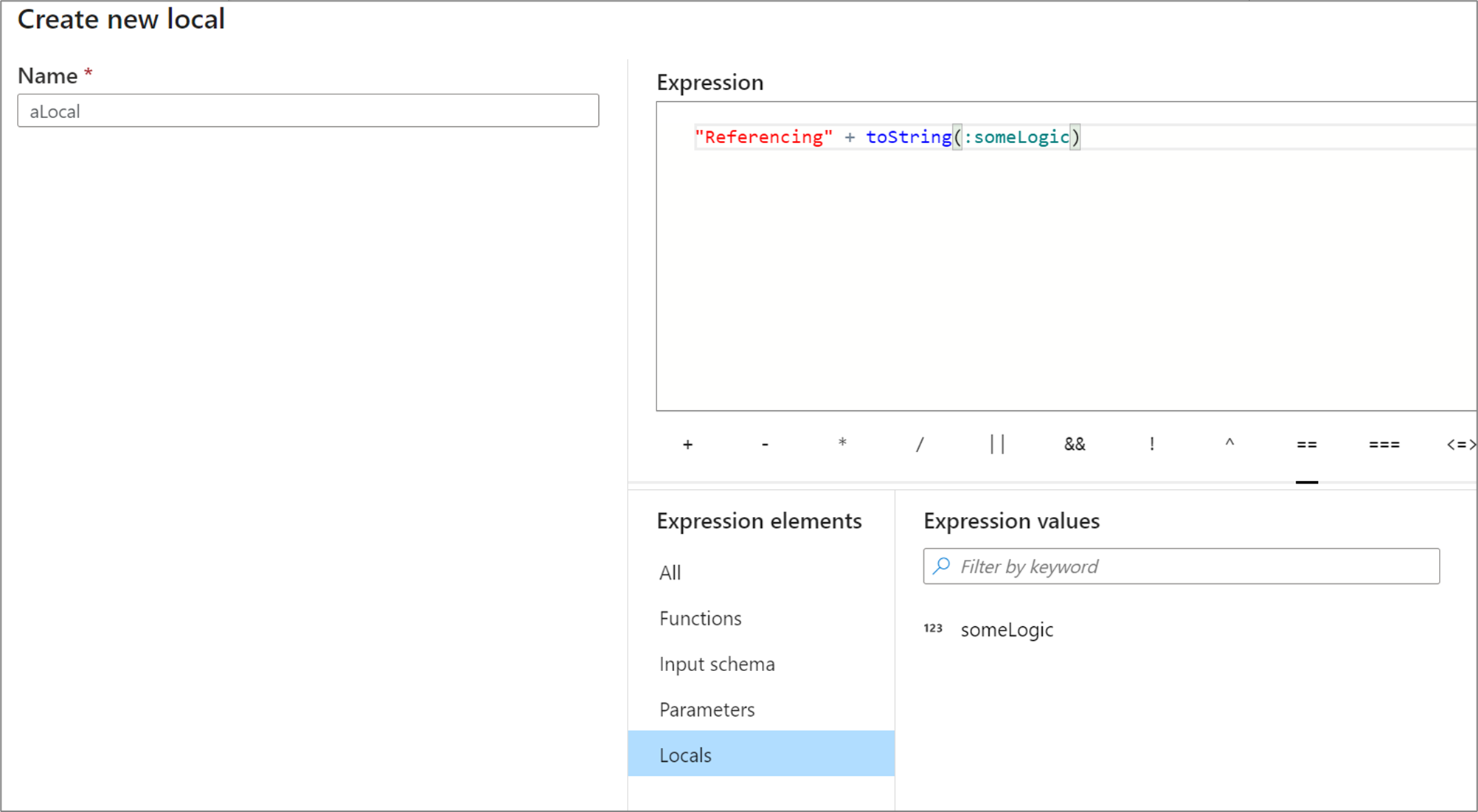
Pokud chcete odkazovat na místní objekt v transformaci, vyberte buď místní z zobrazení elementů výrazu, nebo na něj odkazujte dvojtečku před jeho názvem. Například místní název local1 by byl odkazován na :local1. Pokud chcete upravit místní definici, najeďte myší na ni v zobrazení prvků výrazu a vyberte ikonu tužky.
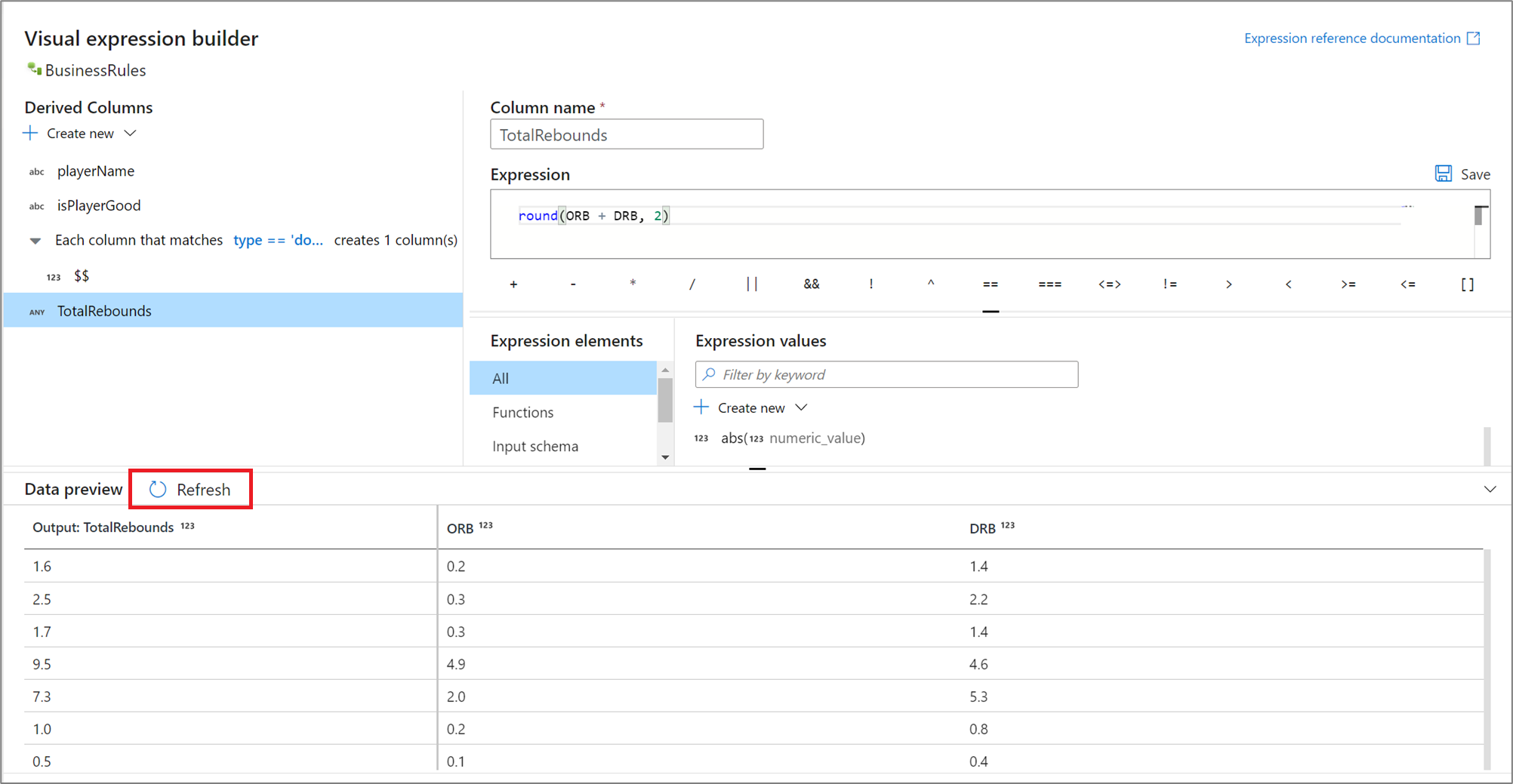
Výsledky výrazů náhledu
Pokud je režim ladění zapnutý, můžete interaktivně použít ladicí cluster k zobrazení náhledu toho, jak se výraz vyhodnotí. Výběrem možnosti Aktualizovat vedle náhledu dat aktualizujte výsledky náhledu dat. Zobrazí se výstup každého řádku se vstupními sloupci.
Interpolace řetězců
Při vytváření dlouhých řetězců, které používají elementy výrazů, použijte interpolaci řetězců k snadnému vytvoření komplexní řetězcové logiky. Interpolace řetězců zabraňuje rozsáhlému použití zřetězení řetězců, pokud jsou parametry zahrnuty do řetězců dotazu. Pomocí dvojitých uvozovek uzavřete text literálového řetězce společně s výrazy. Můžete zahrnout funkce výrazů, sloupce a parametry. Pokud chcete použít syntaxi výrazu, uzavřete ji do složených závorek.
Příklady interpolace řetězců:
"My favorite movie is {iif(instr(title,', The')>0,"The {split(title,', The')[1]}",title)}""select * from {$tablename} where orderyear > {$year}""Total cost with sales tax is {round(totalcost * 1.08,2)}""{:playerName} is a {:playerRating} player"
Poznámka:
Při použití syntaxe interpolace řetězců ve zdrojových dotazech SQL musí být řetězec dotazu na jednom řádku bez /n.
Komentování výrazů
Přidejte do výrazů komentáře pomocí syntaxe jednořádkového a víceřádkového komentáře.
Následující příklady jsou platné komentáře:
/* This is my comment *//* This is amulti-line comment */
Pokud do horní části výrazu vložíte komentář, zobrazí se v textovém poli transformace pro dokumentování transformačních výrazů.

Regulární výrazy
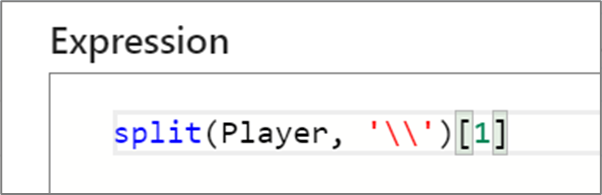
Mnoho funkcí jazyka výrazů používá syntaxi regulárních výrazů. Když používáte funkce regulárního výrazu, Tvůrce výrazů se pokusí interpretovat zpětné lomítko (\) jako řídicí sekvence znaků. Při použití zpětných lomítek v regulárním výrazu buď uzavřete celý regulární výraz do zpětných hran ('), nebo použijte dvojité zpětné lomítko.
Příklad, který používá backticks:
regex_replace('100 and 200', `(\d+)`, 'digits')
Příklad, který používá dvojité lomítko:
regex_replace('100 and 200', '(\\d+)', 'digits')
Klávesové zkratky
Níže je seznam zkratek dostupných v tvůrci výrazů. Většina klávesových zkratek intellisense je k dispozici při vytváření výrazů.
- Ctrl+K Ctrl+C: Okomentujte celý řádek.
- Ctrl+K Ctrl+U: Odkomentování
- F1: Zadejte příkazy nápovědy editoru.
- Alt+Šipka dolů: Přesuňte aktuální řádek dolů.
- Alt+Šipka nahoru: Přesunutí aktuálního řádku nahoru
- Ctrl+mezerník: Zobrazit nápovědu k kontextu
Běžně používané výrazy
Převod na data nebo časová razítka
Pokud chcete do výstupu časového razítka zahrnout řetězcové literály, zabalte převod do toString().
toString(toTimestamp('12/31/2016T00:12:00', 'MM/dd/yyyy\'T\'HH:mm:ss'), 'MM/dd /yyyy\'T\'HH:mm:ss')
Chcete-li převést milisekundy z epochy na datum nebo časové razítko, použijte toTimestamp(<number of milliseconds>). Pokud čas přichází v sekundách, vynásobte 1 000.
toTimestamp(1574127407*1000l)
Koncová "l" na konci předchozího výrazu označuje převod na dlouhý typ jako vloženou syntaxi.
Vyhledání času z epochy nebo unixového času
toLong( currentTimestamp() - toTimestamp('1970-01-01 00:00:00.000', 'yyyy-MM-dd HH:mm:ss. SSS') ) * 1000l
Vyhodnocení času toku dat
Tok dat zpracovává až do milisekund. Pro verzi 2018-07-31T20:00:00.2170000 uvidíte ve výstupu 2018-07-31T20:00:00.217 . Na portálu pro službu se časové razítko zobrazuje v aktuálním nastavení prohlížeče, což může eliminovat 217, ale když spustíte konec toku dat, 217 (část milisekund je také zpracována). Můžete použít toString(myDateTimeColumn) jako výraz a zobrazit data úplné přesnosti ve verzi Preview. Zpracujte datum a čas jako datetime místo řetězce pro všechny praktické účely.