Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datovou vědu, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Přehled
Ladicí režim mapování toků dat v Azure Data Factory a Synapse Analytics umožňuje interaktivně sledovat, jak se datová struktura mění během tvorby a ladění vašich toků dat. Ladicí relaci je možné použít jak v návrhových relacích toku dat, tak při ladění toků dat v rámci provádění kanálu. Pokud chcete zapnout režim ladění, použijte tlačítko Tok dat Ladění v horním panelu plátna toku dat nebo plátna kanálu, pokud máte aktivity toku dat.
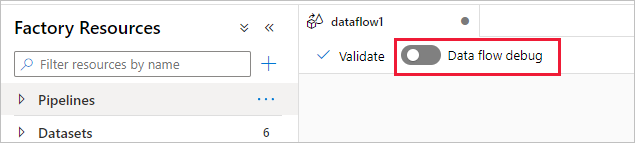

Po zapnutí posuvníku se zobrazí výzva k výběru konfigurace prostředí Integration Runtime, kterou chcete použít. Pokud zvolíte AutoResolveIntegrationRuntime, cluster s osmi jádry obecného výpočetního prostředí s výchozím 60minutovým časem naživo se rozsvítí. Pokud chcete umožnit delší dobu nečinnosti týmu před vypršením časového limitu relace, můžete zvolit vyšší nastavení TTL. Další informace o prostředích Integration Runtime pro tok dat najdete v tématu Výkon prostředí Integration Runtime.
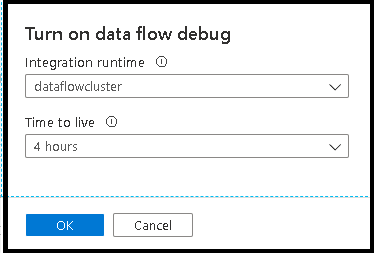
Když je zapnutý režim ladění, interaktivně sestavíte tok dat pomocí aktivního clusteru Spark. Relace se zavře, jakmile vypnete ladění. Měli byste si být vědomi hodinových poplatků účtovaných službou Data Factory, když máte zapnutou relaci ladění.
Ve většině případů je vhodné vytvořit Tok dat v režimu ladění, abyste před publikováním práce mohli ověřit obchodní logiku a zobrazit transformace dat. Použijte tlačítko "Ladit" na panelu datového potrubí k otestování toku dat v potrubí.
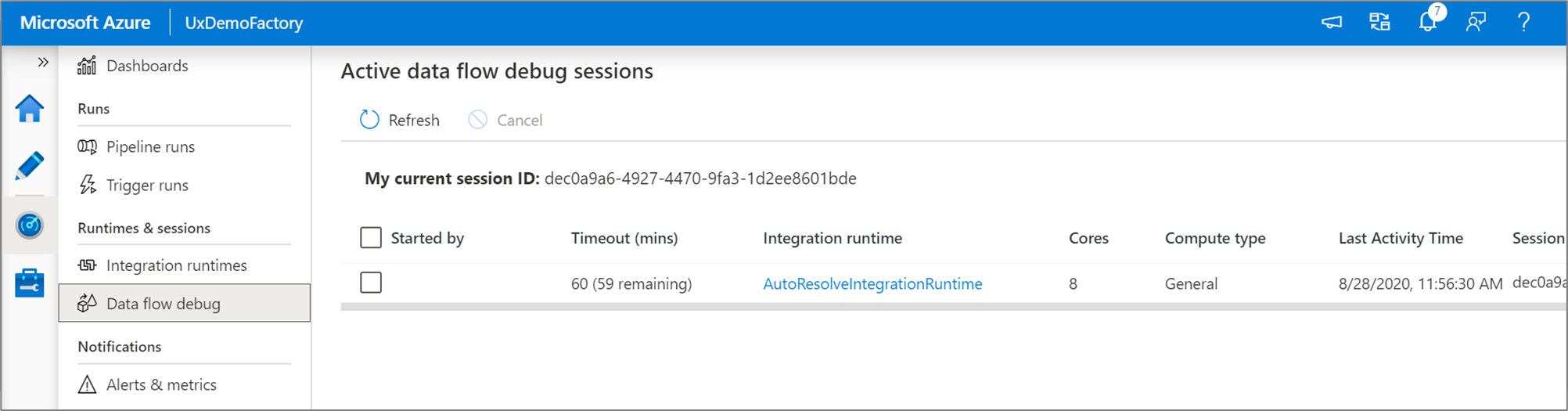
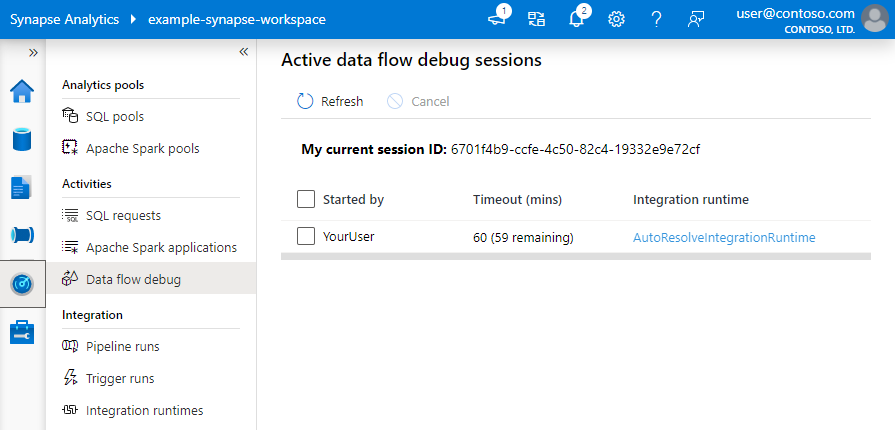
Poznámka:
Každá debugovací relace, kterou uživatel spustí z prohlížeče, je nová relace s vlastním clusterem Spark. Monitorovací pohled můžete použít pro ladicí relace zobrazené na předchozích obrázcích k zobrazení a správě ladicích relací. Za každou hodinu provozu každé ladicí relace se vám účtují poplatky, včetně času TTL.
Tento videoklip hovoří o tipech, trikech a osvědčených postupech pro ladicí režim toku dat.
Stav clusteru
Indikátor stavu clusteru v horní části návrhové plochy se změní na zelenou, když je cluster připravený k ladění. Pokud je váš cluster již teplý, zobrazí se zelený indikátor téměř okamžitě. Pokud váš cluster ještě nebyl spuštěný, když jste přešli do režimu ladění, cluster Spark provede studené spuštění. Indikátor se roztáčí, dokud prostředí nebude připravené k interaktivnímu ladění.
Až ladění dokončíte, vypněte přepínač Ladění, aby se cluster Spark mohl ukončit a už se vám nebude účtovat aktivita ladění.
Nastavení ladění
Po zapnutí režimu ladění můžete upravit, jak datový tok zobrazuje náhled dat. Nastavení ladění lze upravit kliknutím na "Nastavení ladění" na panelu nástrojů plátna toků dat. Tady můžete vybrat limit řádků nebo zdroj souborů, které se mají použít pro každou z transformací zdroje. Toto nastavení omezení řádků se vztahuje pouze na aktuální ladicí relaci. Můžete také vybrat předpřipravenou propojenou službu, která se má použít pro zdroj Azure Synapse Analytics.
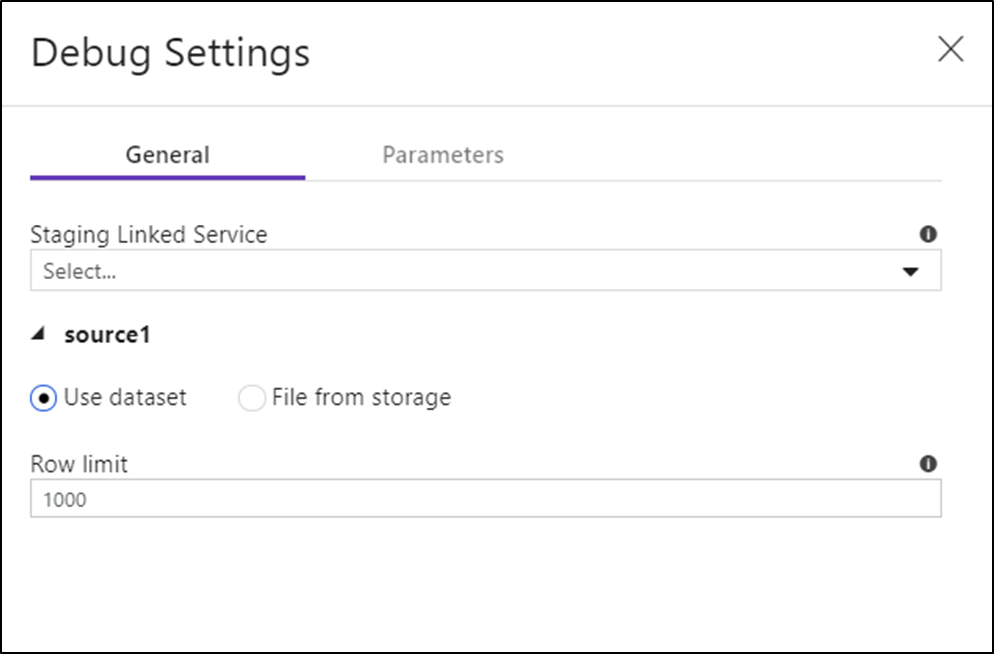
Pokud máte v datovém toku nebo některé z jejich odkazovaných datových sad parametry, můžete určit, jaké hodnoty se mají použít při ladění, a to výběrem záložky Parametry.
Pomocí nastavení vzorkování zde můžete odkazovat na ukázkové soubory nebo ukázkové tabulky dat, abyste nemuseli měnit zdrojové datové sady. Tady můžete pomocí ukázkového souboru nebo tabulky zachovat stejná nastavení logiky a vlastností v toku dat při testování podmnožinou dat.
Výchozí prostředí IR používané pro režim ladění v tocích dat je malý 4jádrový jeden pracovní uzel se 4jádrovým uzlem jednoho ovladače. To funguje dobře s menšími vzorky dat při testování logiky toku dat. Pokud během náhledu dat rozbalíte limity řádků v nastavení ladění nebo nastavíte vyšší počet vzorkovaných řádků ve zdroji během ladění kanálu, můžete zvážit nastavení většího výpočetního prostředí v novém prostředí Azure Integration Runtime. Potom můžete restartovat ladicí relaci pomocí většího výpočetního prostředí.
Náhled dat
Při ladění se karta Náhled dat rozsvítí na dolním panelu. Bez zapnutého režimu ladění Tok dat zobrazuje pouze aktuální metadata na kartě Kontrola a z každé transformace. Náhled dat se dotazuje pouze na počet řádků, které jste nastavili jako limit v nastavení ladění. Výběrem možnosti Aktualizovat aktualizujte náhled dat na základě aktuálních transformací. Pokud se zdrojová data změnila, vyberte možnost Obnovit > ze zdroje.
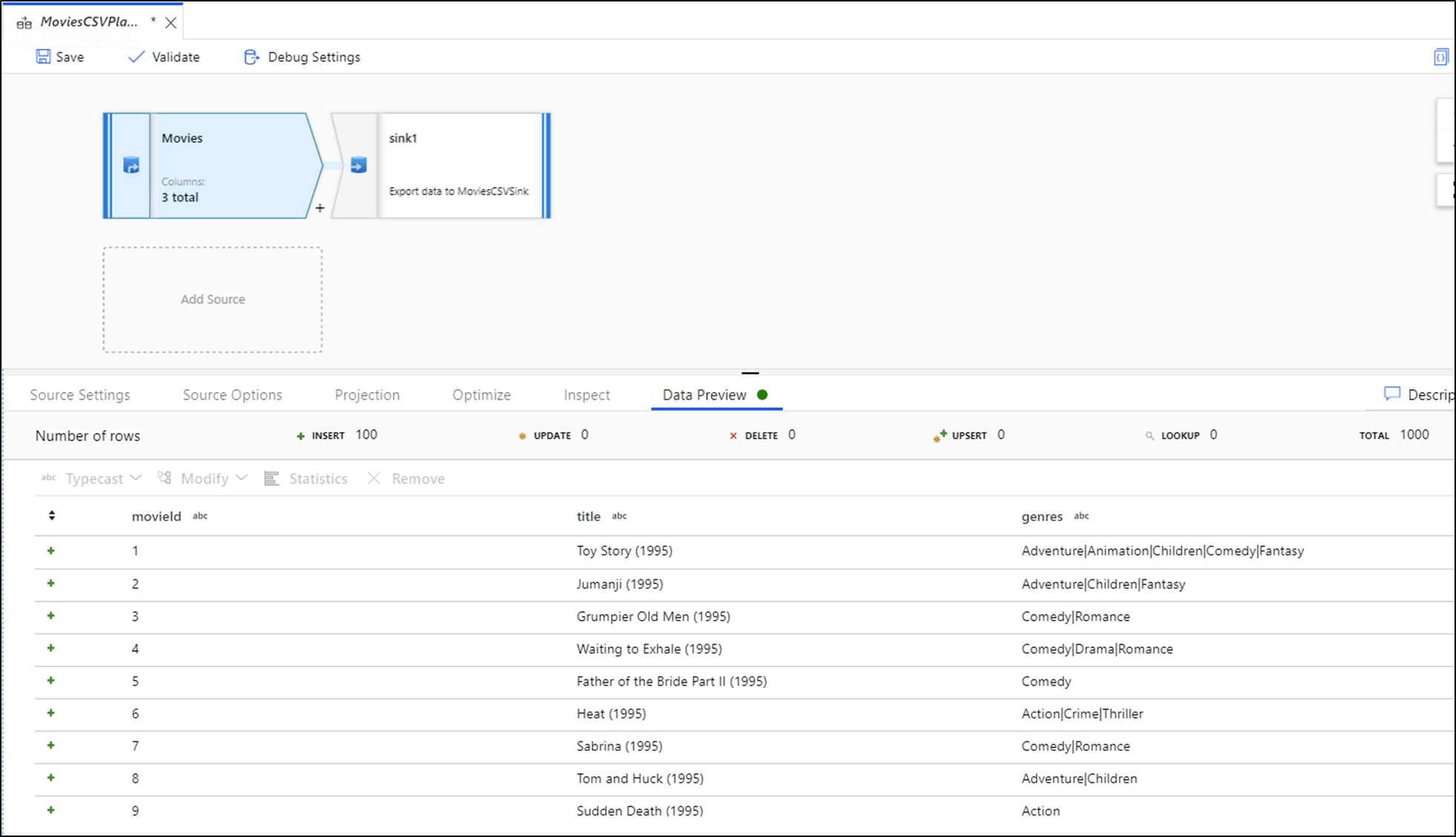
Sloupce v náhledu dat můžete seřadit a změnit jejich uspořádání přetažením. Kromě toho je v horní části panelu náhledu dat tlačítko pro export, které můžete použít k exportu dat náhledu do souboru CSV pro offline zkoumání dat. Pomocí této funkce můžete exportovat až 1 000 řádků dat náhledu.
Poznámka:
Zdroje souborů omezují jenom zobrazené řádky, nikoli řádky, které se čtou. U velmi velkých datových sad se doporučuje vzít malou část tohoto souboru a použít ji pro testování. Dočasný soubor můžete vybrat v nastavení ladění pro každý zdroj, který je typem datové sady.
Při spuštění toku dat v režimu ladění nebudou vaše data zapsána do transformace jímky. Ladicí relace je určená k tomu, aby sloužila jako testovací sada pro vaše transformace. Během ladění se jímky nevyžadují a ve vašem toku dat se ignorují. Pokud chcete otestovat zápis dat do jímky, spusťte Tok dat z kanálu a použijte provádění ladění z kanálu.
Náhled dat je snímek transformovaných dat s využitím limitů řádků a vzorkování dat z datových rámců v paměti Sparku. Proto se v tomto scénáři nevyužívají ani neotestují ovladače jímky.
Poznámka:
Náhled dat zobrazuje čas podle nastavení národního prostředí prohlížeče.
Testování podmínek spojení
Při testování spojení, Exists nebo Lookup transformací se ujistěte, že používáte malou sadu známých dat pro svůj test. Pomocí možnosti Nastavení ladění popsaného výše můžete nastavit dočasný soubor, který se má použít pro testování. To je potřeba, protože při omezování nebo vzorkování řádků z velké datové sady nemůžete předpovědět, které řádky a které klíče se čtou do toku pro účely testování. Výsledek je nedeterministický, což znamená, že vaše podmínky spojení můžou selhat.
Rychlé akce
Jakmile uvidíte náhled dat, můžete rychle vygenerovat transformaci pro přetypování, odebrání nebo úpravu sloupce. Vyberte záhlaví sloupce a pak vyberte jednu z možností z panelu nástrojů náhledu dat.
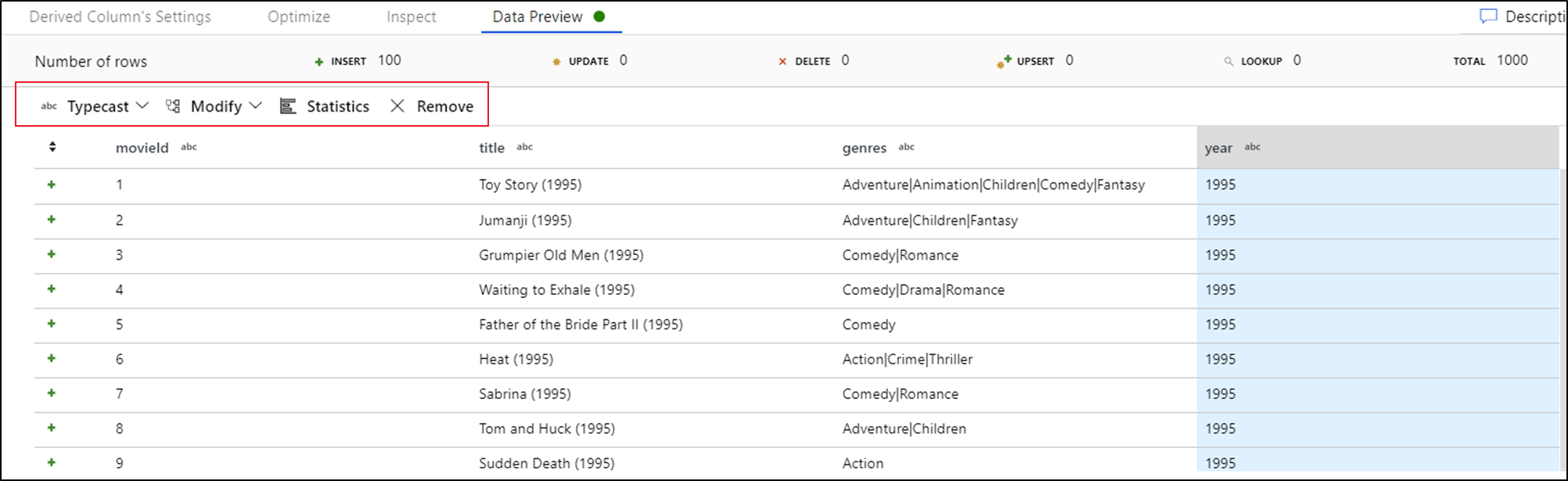
Jakmile vyberete změnu, náhled dat se okamžitě aktualizuje. Výběrem možnosti Potvrdit v pravém horním rohu vygenerujete novou transformaci.
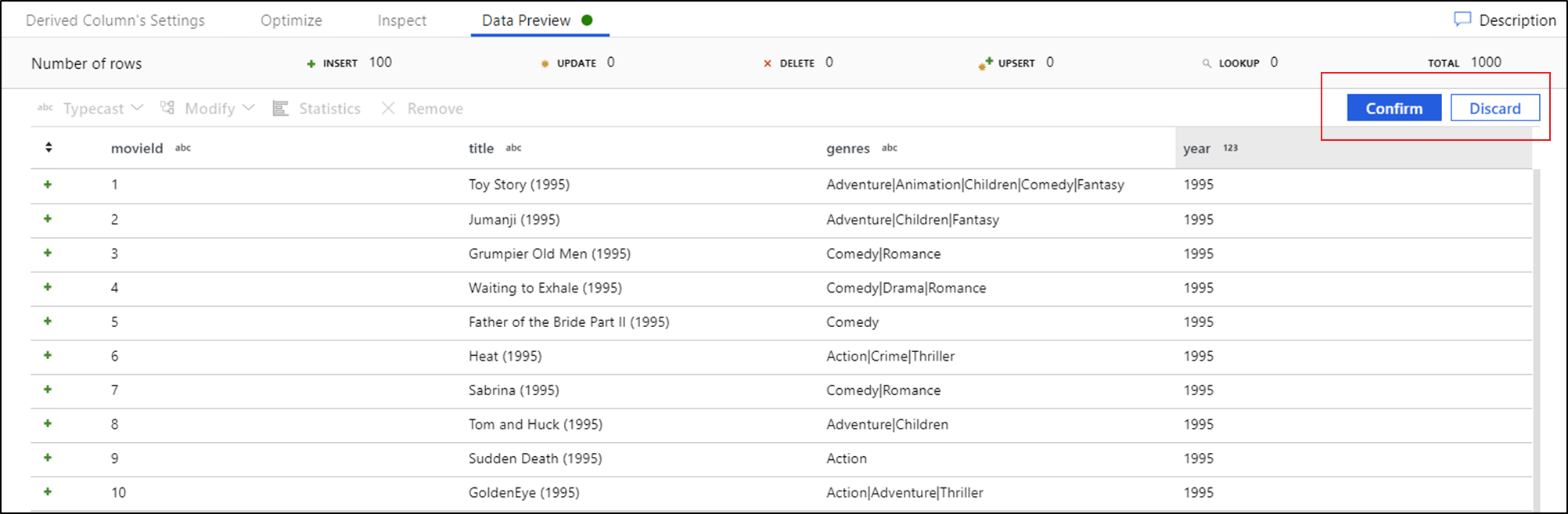
Typecast a Modify generuje transformaci odvozeného sloupce a Remove generuje transformaci Select.
Poznámka:
Pokud upravujete Tok dat, musíte před přidáním rychlé transformace znovu načíst náhled dat.
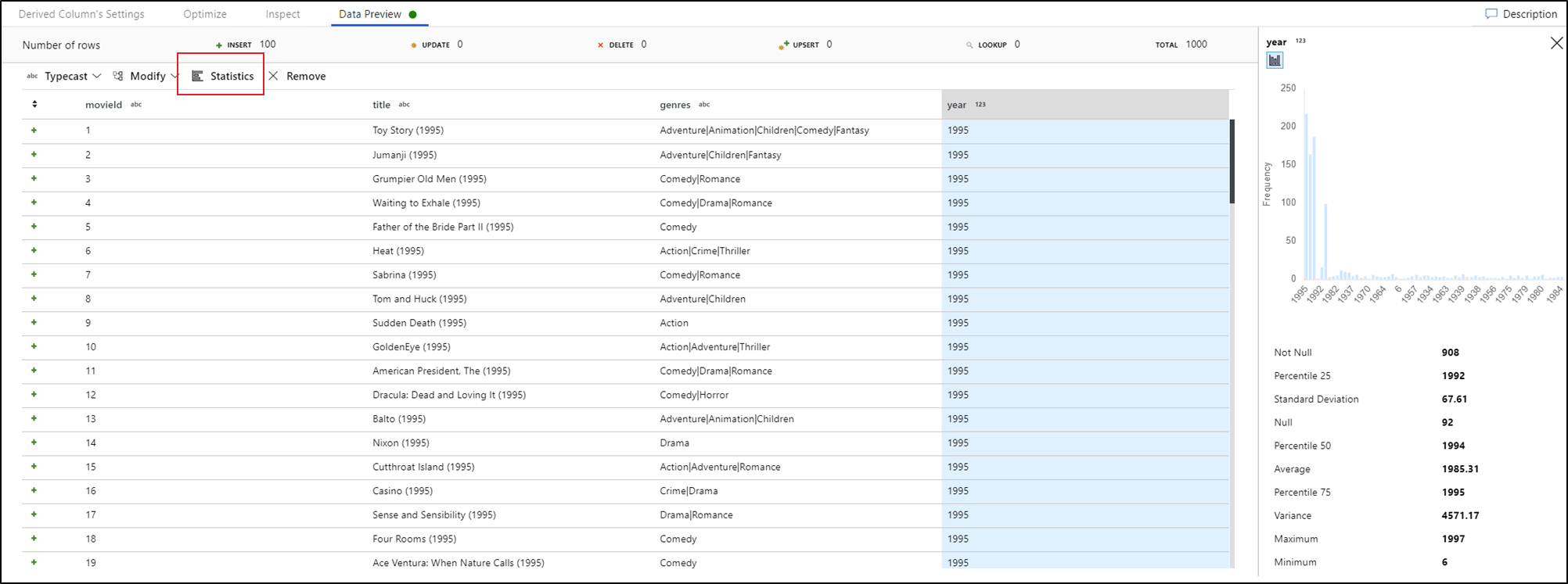
Profilace dat
Výběrem sloupce na kartě Náhled dat a kliknutím na Statistika na panelu nástrojů náhledu dat se zobrazí graf v pravé části datové mřížky s podrobnými statistikami o jednotlivých polích. Služba určuje na základě vzorkování dat, jaký typ grafu zobrazit. Pole s vysokou kardinalitou se standardně zobrazují pomocí grafů NULL/NOT NULL, zatímco kategorická a číselná data s nízkou kardinalitou jsou zobrazena pruhovými grafy ukazujícími četnost hodnot dat. Zobrazí se také maximální délka řetězcových polí, minimální/maximální hodnoty v číselných polích, standardních dev, percentilech, počtech a průměru.
Související obsah
- Jakmile dokončíte sestavování a ladění toku dat, spusťte ho z pipeliny.
- Při testování kanálu s tokem dat použijte možnost spuštění ladění kanálu .