Dotazování dat v Azure Data Lake pomocí Azure Data Exploreru
Azure Data Lake Storage je vysoce škálovatelné a nákladově efektivní řešení datového jezera pro analýzu velkých objemů dat. Kombinuje výkon vysoce výkonného systému souborů s obrovským měřítkem a ekonomikou, což vám pomůže zkrátit dobu, po kterou můžete získat přehled. Řešení Data Lake Storage Gen2 rozšiřuje funkce Azure Blob Storage a je optimalizované pro analytické úlohy.
Azure Data Explorer se integruje se službou Azure Blob Storage a Azure Data Lake Storage (Gen1 a Gen2), která poskytuje rychlý, uložený přístup do mezipaměti a indexovaný přístup k datům uloženým v externím úložišti. Data můžete analyzovat a dotazovat bez předchozího příjmu dat do Azure Data Exploreru. Můžete se také dotazovat na ingestovaná a neingestovaná externí data současně. Další informace najdete v tématu vytvoření externí tabulky pomocí průvodce webovým uživatelským rozhraním Azure Data Exploreru. Stručný přehled najdete v externích tabulkách.
Tip
Nejlepší výkon dotazů vyžaduje příjem dat do Azure Data Exploreru. Možnost dotazovat se na externí data bez předchozího příjmu dat by se měla používat pouze pro historická data nebo zřídka dotazovaná data. Optimalizujte výkon dotazů na externí data, abyste se docílili nejlepších výsledků.
Vytvoření externí tabulky
Řekněme, že máte hodně souborů CSV obsahujících historické informace o produktech uložených ve skladu a chcete provést rychlou analýzu a najít pět nejoblíbenějších produktů z minulého roku. V tomto příkladu vypadají soubory CSV takto:
| Časové razítko | ID produktu | ProductDescription |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | Disketa 3.5in DS/HD |
| 2019-01-01 11:30:55 | YDX1 | Yamaha DX1 Syntetizátor |
| ... | ... | ... |
Soubory se ukládají v Úložišti objektů blob mycompanystorage v Azure v kontejneru s názvem archivedproducts, rozděleným podle data:
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
Pokud chcete spustit dotaz KQL na tyto soubory CSV přímo, použijte .create external table příkaz k definování externí tabulky v Azure Data Exploreru. Další informace o možnostech příkazu pro vytvoření externí tabulky najdete v tématu příkazy externí tabulky.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
Externí tabulka je teď viditelná v levém podokně webového uživatelského rozhraní Azure Data Exploreru:
Oprávnění externí tabulky
- Uživatel databáze může vytvořit externí tabulku. Tvůrce tabulky se automaticky stane správcem tabulky.
- Správce clusteru, databáze nebo tabulky může upravit existující tabulku.
- Externí tabulku může dotazovat libovolný uživatel nebo čtenář databáze.
Dotazování na externí tabulku
Jakmile je definována externí tabulka, external_table() můžete funkci použít k odkaz na ni. Zbytek dotazu je standardní dotazovací jazyk Kusto.
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
Dotazování externích a přijatých dat najednou
Můžete dotazovat externí tabulky i ingestované tabulky dat v rámci stejného dotazu. join Můžete nebo union externí tabulku s jinými daty z Azure Data Exploreru, SQL serverů nebo jiných zdrojů. let( ) statement Slouží k přiřazení zkráceného názvu k externí tabulce.
V následujícím příkladu je ingestovaná tabulka dat a ArchivedProducts je externí tabulka, kterou jsme definovali dříve:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
Dotazování hierarchických formátů dat
Azure Data Explorer umožňuje dotazování hierarchických formátů, jako JSONjsou , Parquet, Avroa ORC. Pokud chcete mapovat hierarchické schéma dat na schéma externí tabulky (pokud je jiné), použijte příkazy mapování externích tabulek. Pokud například chcete dotazovat soubory protokolu JSON s následujícím formátem:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "e1ef54a6-c6f2-4389-836e-d289b37bcfe0",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "9b49d0d7-b3e6-4467-bb35-fa420a25d324",
"method": "GetFileList"
}
}
...
Definice externí tabulky vypadá takto:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
Definujte mapování JSON, které mapuje datová pole na pole definice externí tabulky:
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
Při dotazování na externí tabulku se vyvolá mapování a relevantní data se namapují na sloupce externí tabulky:
external_table('ApiCalls') | take 10
Další informace o syntaxi mapování najdete v tématu Mapování dat.
Dotazování externí tabulky TaxiRides v clusteru nápovědy
K vyzkoušení různých funkcí Azure Data Exploreru použijte testovací cluster s názvem Nápověda . Cluster nápovědy obsahuje definici externí tabulky pro datovou sadu taxislužby v New Yorku obsahující miliardy jízd taxíkem.
Vytvoření externí tabulky TaxiRides
Tato část ukazuje dotaz použitý k vytvoření externí tabulky TaxiRides v clusteru nápovědy. Vzhledem k tomu, že už je tato tabulka vytvořená, můžete tuto část přeskočit a přejít přímo na dotazy na data externí tabulky TaxiRides.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
Vytvořenou tabulku TaxiRides najdete v levém podokně webového uživatelského rozhraní Azure Data Exploreru:
Dotazování na data externí tabulky TaxiRides
Přihlaste se na https://dataexplorer.azure.com/clusters/help/databases/Samples.
Dotazování na externí tabulku TaxiRides bez dělení
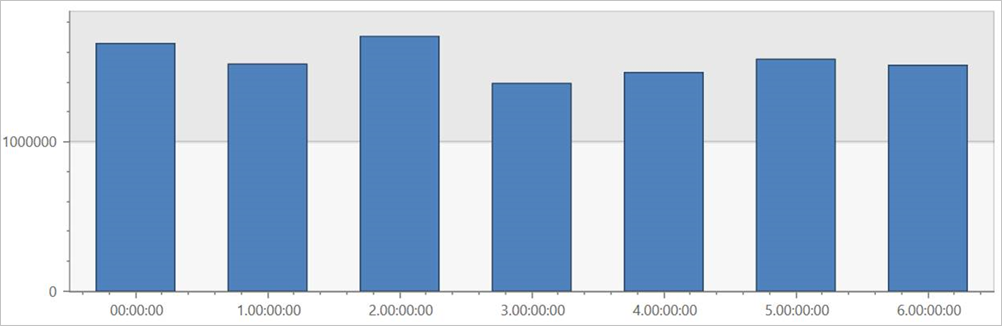
Spuštěním tohoto dotazu na externí tabulku TaxiRides zobrazte jízdy pro každý den v týdnu v celé datové sadě.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
Tento dotaz zobrazuje nejužší den v týdnu. Vzhledem k tomu, že data nejsou rozdělená na oddíly, může vrácení výsledků trvat až několik minut.
Dotazování externí tabulky TaxiRides s dělením
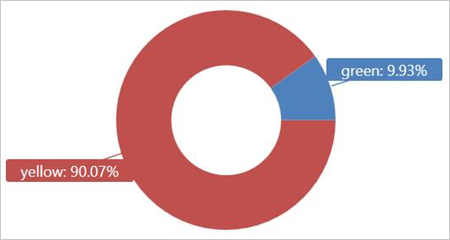
Spuštěním tohoto dotazu na externí tabulce TaxiRides zobrazíte typy taxislužby (žluté nebo zelené) použité v lednu 2017.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
Tento dotaz používá dělení, které optimalizuje čas a výkon dotazů. Dotaz filtruje dělený sloupec (pickup_datetime) a vrátí výsledky za několik sekund.
Můžete napsat další dotazy ke spuštění na externí tabulce TaxiRides a získat další informace o datech.
Optimalizace výkonu dotazů
Optimalizujte výkon dotazů v jezeře s využitím následujících osvědčených postupů pro dotazování externích dat.
Formát dat
- Pro analytické dotazy použijte sloupcový formát z následujících důvodů:
- Číst se dají jenom sloupce relevantní pro dotaz.
- Techniky kódování sloupců můžou výrazně snížit velikost dat.
- Azure Data Explorer podporuje sloupcové formáty Parquet a ORC. Formát Parquet se navrhuje kvůli optimalizované implementaci.
Oblast Azure
Zkontrolujte, že externí data jsou ve stejné oblasti Azure jako cluster Azure Data Exploreru. Toto nastavení snižuje náklady a dobu načítání dat.
Velikost souboru
Optimální velikost souboru je stovky Mb (až 1 GB) na soubor. Vyhněte se mnoha malým souborům, které vyžadují nepotřebné režijní náklady, například pomalejší proces výčtu souborů a omezené použití sloupcového formátu. Počet souborů by měl být větší než počet jader procesoru v clusteru Azure Data Exploreru.
Komprese
Komprese slouží ke snížení množství dat načtených ze vzdáleného úložiště. Pro formát Parquet použijte interní mechanismus komprese Parquet, který komprimuje skupiny sloupců samostatně, takže je můžete číst samostatně. Pokud chcete ověřit použití mechanismu komprese, zkontrolujte, zda jsou soubory pojmenovány takto: název souboru>.gz.parquet nebo< název_souboru.snappy.parquet> a nikoli< název_souboru>.parquet.gz.<
dělení na části
Uspořádejte data pomocí oddílů složek, které umožňují dotazu přeskočit irelevantní cesty. Při plánování dělení zvažte velikost souboru a běžné filtry v dotazech, jako je časové razítko nebo ID tenanta.
Velikost virtuálního počítače
Vyberte skladové položky virtuálních počítačů s více jádry a vyšší propustností sítě (paměť je méně důležitá). Další informace najdete v tématu Výběr správné skladové položky virtuálního počítače pro váš cluster Azure Data Exploreru.