Přehled provozní kontinuity a zotavení po havárii
Provozní kontinuita a zotavení po havárii v Azure Data Exploreru umožňují vaší firmě pokračovat v provozu v případě přerušení. Tento článek popisuje dostupnost (uvnitř oblasti) a zotavení po havárii. Podrobně popisuje nativní funkce a aspekty architektury pro odolné nasazení Azure Data Exploreru. Podrobně popisuje zotavení z lidských chyb, vysoké dostupnosti a následně několik konfigurací zotavení po havárii. Tyto konfigurace závisí na požadavcích na odolnost, jako jsou cíl bodu obnovení (RPO) a cíl doby obnovení (RTO), potřebné úsilí a náklady.
Zmírnění rušivých událostí
- Lidská chyba
- Vysoká dostupnost Azure Data Exploreru
- Výpadek zóny dostupnosti Azure
- Výpadek datacentra Azure
- Výpadek oblasti Azure
Lidská chyba
Lidské chyby jsou nevyhnutelné. Uživatelé můžou omylem vyhodit cluster, databázi nebo tabulku.
Náhodné odstranění clusteru nebo databáze
Náhodné odstranění clusteru nebo databáze je nevratná akce. Jako vlastník prostředku služby Azure Data Explorer můžete zabránit ztrátě dat tím, že povolíte funkci zámku odstranění, která je dostupná na úrovni prostředků Azure.
Náhodné odstranění tabulky
Uživatelům s oprávněními správce tabulek nebo vyšším je povoleno zahodit tabulky. Pokud některý z těchto uživatelů omylem zahodí tabulku, můžete ji obnovit pomocí .undo drop table příkazu. Aby byl tento příkaz úspěšný, musíte nejprve povolit vlastnost obnovitelnosti v zásadách uchovávání informací.
Náhodné odstranění externí tabulky
Externí tabulky jsou entity schématu dotazu Kusto, které odkazují na data uložená mimo databázi. Odstranění externí tabulky odstraní pouze metadata tabulky. Můžete ji obnovit opětovným spuštěním příkazu pro vytvoření tabulky. Pomocí funkce obnovitelného odstranění můžete chránit před náhodným odstraněním nebo přepsáním souboru nebo objektu blob po dobu nakonfigurovanou uživatelem.
Vysoká dostupnost Azure Data Exploreru
Vysoká dostupnost odkazuje na odolnost proti chybám Azure Data Exploreru, jejích komponent a základních závislostí v rámci oblasti Azure. Tato odolnost proti chybám zabraňuje kritickým bodům selhání (SPOF) v implementaci. Vysoká dostupnost v Azure Data Exploreru zahrnuje vrstvu trvalosti, výpočetní vrstvu a konfiguraci sledování výsledků.
Vrstva trvalosti
Azure Data Explorer využívá Službu Azure Storage jako odolnou vrstvu trvalosti. Azure Storage automaticky poskytuje odolnost proti chybám s výchozím nastavením nabízejícím místně redundantní úložiště (LRS) v datovém centru. Existují tři repliky. Pokud během používání dojde ke ztrátě repliky, nasadí se jiná bez přerušení. Další odolnost je možná díky zónově redundantnímu úložišti (ZRS), která inteligentně umístí repliky do zón dostupnosti Azure pro zajištění maximální odolnosti proti chybám za další cenu. Úložiště s podporou ZRS se automaticky nakonfiguruje při nasazení clusteru Azure Data Exploreru do Zóny dostupnosti.
Výpočetní vrstva
Azure Data Explorer je distribuovaná výpočetní platforma a v závislosti na typu role škálování a uzlu může mít dva až mnoho uzlů. Při zřizování vyberte zóny dostupnosti pro distribuci nasazení uzlu napříč zónami pro zajištění maximální odolnosti uvnitř oblasti. Selhání zóny dostupnosti nezpůsobí úplný výpadek, ale snížení výkonu až do obnovení zóny.
Konfigurace clusteru leader-follower
Azure Data Explorer poskytuje volitelnou možnost sledování clusteru vedoucího serveru, za nímž následují další sledující clustery pro přístup jen pro čtení k datům a metadatům vedoucího serveru. Změny vedoucího znaku, například create, appenda drop jsou automaticky synchronizovány s následníky. Zatímco vedoucí pracovníci můžou zahrnovat oblasti Azure, měly by se sledovatelské clustery hostovat ve stejných oblastech jako vedoucí. Pokud je cluster vedoucího serveru vypnutý nebo dojde k náhodnému vyřazení databází nebo tabulek, clustery sledujících ztratí přístup, dokud se v vedoucí skupině neobnoví přístup.
Výpadek zóny dostupnosti Azure
Zóny dostupnosti Azure jsou jedinečná fyzická umístění ve stejné oblasti Azure. Můžou chránit výpočetní prostředky clusteru Azure Data Exploreru a data před selháním částečné oblasti. Selhání zóny je scénář dostupnosti, protože je uvnitř oblasti.
Připněte cluster Azure Data Exploreru do stejné zóny jako ostatní připojené prostředky Azure. Další informace o povolení zón dostupnosti najdete v tématu Vytvoření clusteru.
Poznámka:
Nasazení do zón dostupnosti je možné při vytváření clusteru nebo je možné ho později migrovat.
Výpadek datacentra Azure
Zóny dostupnosti Azure mají náklady a někteří zákazníci se rozhodnou nasadit bez zónové redundance. Při takovém nasazení Azure Data Exploreru dojde k výpadku datacentra Azure. Zpracování výpadku datacentra Azure je proto stejné jako výpadek oblasti Azure.
Výpadek oblasti Azure
Azure Data Explorer neposkytuje automatickou ochranu před výpadkem celé oblasti Azure. Pokud dojde k takovému výpadku, minimalizujete obchodní dopad na několik clusterů Azure Data Exploreru napříč spárovanými oblastmi Azure. Na základě cíle doby obnovení (RTO), cíle bodu obnovení (RPO) a úsilí a požadavků na náklady existuje několik konfigurací zotavení po havárii. Optimalizace nákladů a výkonu jsou možné s doporučeními Azure Advisoru a konfigurací automatického škálování .
Konfigurace zotavení po havárii
Tato část podrobně popisuje několik konfigurací zotavení po havárii v závislosti na požadavcích na odolnost (RPO a RTO), potřebné úsilí a náklady.
Cíl doby obnovení (RTO) odkazuje na dobu obnovení z přerušení. RtO 2 hodiny například znamená, že aplikace musí být spuštěná během dvou hodin od přerušení. Cíl bodu obnovení (RPO) odkazuje na interval času, který může proběhnout během přerušení, než je množství ztracených dat během tohoto období větší než povolená prahová hodnota. Pokud je například cíl bodu obnovení 24 hodin a aplikace má data od 15 let, jsou stále v rámci parametrů odsouhlaseného cíle bodu obnovení.
Procesy příjmu, zpracování a kurátorování potřebují při plánování zotavení po havárii pečlivě návrh. Příjem dat odkazuje na data integrovaná do Azure Data Exploreru z různých zdrojů; zpracování se týká transformací a podobných činností; curation odkazuje na materializovaná zobrazení, exporty do datového jezera atd.
Následují oblíbené konfigurace zotavení po havárii a jednotlivé konfigurace jsou podrobně popsány níže.
- Konfigurace aktivní-aktivní-aktivní (always-on)
- Konfigurace aktivní-aktivní
- Konfigurace aktivního pohotovostního režimu
- Konfigurace clusteru obnovení dat na vyžádání
Konfigurace aktivní-aktivní-aktivní
Tato konfigurace se také nazývá "always-on". Pro důležitá nasazení aplikací bez tolerance k výpadkům byste měli použít více clusterů Azure Data Exploreru napříč spárovanými oblastmi Azure. Paralelní nastavení příjmu dat, zpracování a curace se všemi clustery Skladová položka clusteru musí být stejná napříč oblastmi. Azure zajistí, že se aktualizace nasadí a provedou napříč spárovanými oblastmi Azure. Výpadek oblasti Azure nezpůsobí výpadek aplikace. Může docházet k určité latenci nebo snížení výkonu.
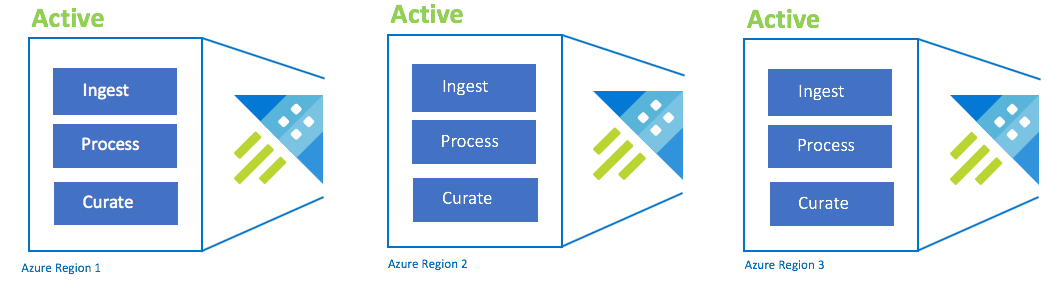
| Konfigurace | RPO | RTO | Úsilí | Náklady |
|---|---|---|---|---|
| Active-Active-Active-n | 0 hodin | 0 hodin | Lower | Nejvyšší |
Konfigurace aktivní-aktivní
Tato konfigurace je identická s konfigurací typu aktivní-aktivní, ale zahrnuje pouze dvě spárované oblasti Azure. Konfigurace duálního příjmu dat, zpracování a kurátorování Uživatelé se směrují do nejbližší oblasti. Skladová položka clusteru musí být stejná napříč oblastmi.
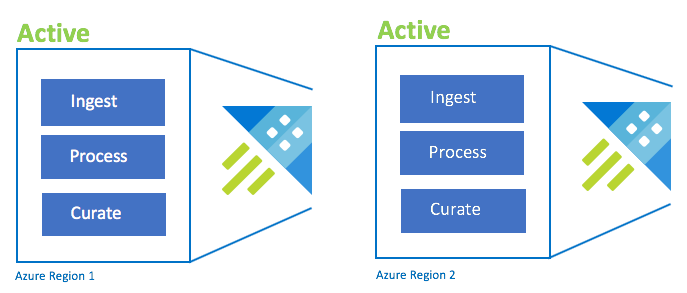
| Konfigurace | RPO | RTO | Úsilí | Náklady |
|---|---|---|---|---|
| Aktivní–aktivní | 0 hodin | 0 hodin | Lower | Vysoká |
Konfigurace aktivního pohotovostního režimu
Konfigurace aktivní-horká je podobná konfiguraci Active-Active v duálním ingestování, zpracování a curaci. Zatímco pohotovostní cluster je online pro příjem dat, zpracování a curaci, není k dispozici pro dotazování. Pohotovostní cluster nemusí být ve stejné SKU jako primární cluster. Může to být menší skladová položka a škálování, což může mít za následek menší výkon. Ve scénáři havárie se uživatelé přesměrují do pohotovostního clusteru, který se dá volitelně vertikálně navýšit, aby se zvýšil výkon.
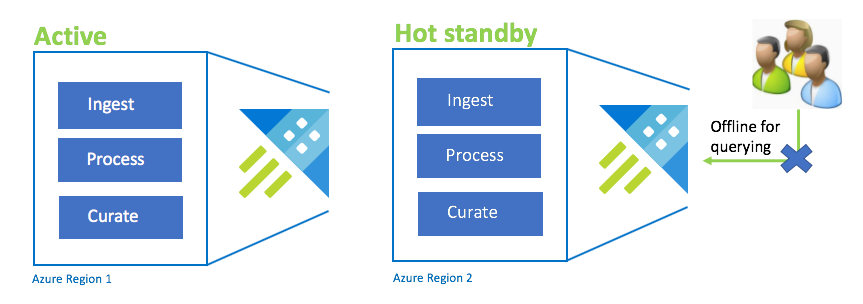
| Konfigurace | RPO | RTO | Úsilí | Náklady |
|---|---|---|---|---|
| Aktivní-aktivní pohotovostní režim | 0 hodin | Nízká | Střední | Střední |
Konfigurace obnovení dat na vyžádání
Toto řešení nabízí nejnižší odolnost (nejvyšší cíl bodu obnovení a plánovanou dobu obnovení) nejnižší náklady a nejvyšší úsilí. V této konfiguraci neexistuje žádný cluster pro obnovení dat. Nakonfigurujte průběžný export kurátorovaných dat (pokud nejsou potřeba nezpracovaná a zprostředkující data) do účtu úložiště, který je nakonfigurovaný GRS (geograficky redundantní úložiště). Pokud existuje scénář zotavení po havárii, cluster pro obnovení dat se rozsadí. V té době se použijí knihovny DDLS, konfigurace, zásady a procesy. Data se ingestují z úložiště s vlastností příjmu dat KustoCreationTime , aby se převezla doba příjmu dat, která je ve výchozím nastavení nastavená na systémový čas.
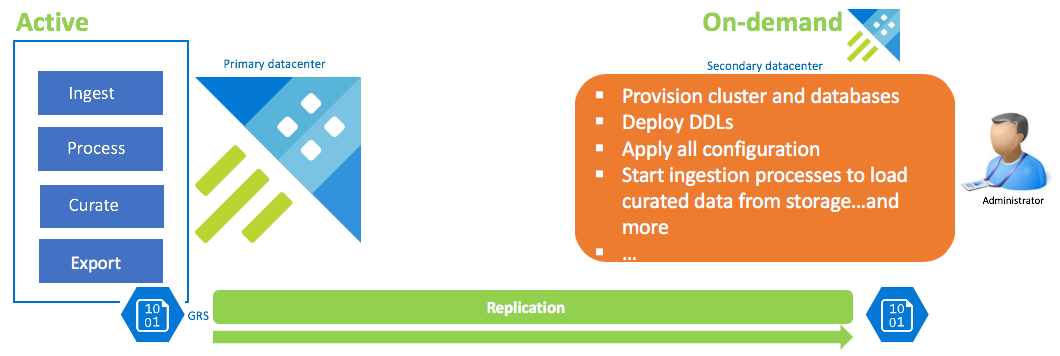
| Konfigurace | RPO | RTO | Úsilí | Náklady |
|---|---|---|---|---|
| Cluster pro obnovení dat na vyžádání | Nejvyšší | Nejvyšší | Nejvyšší | Nejnižší |
Souhrn možností konfigurace zotavení po havárii
| Konfigurace | Odolnost | RPO | RTO | Úsilí | Náklady |
|---|---|---|---|---|---|
| Active-Active-Active-n | Nejvyšší | 0 hodin | 0 hodin | Lower | Nejvyšší |
| Aktivní–aktivní | Vysoká | 0 hodin | 0 hodin | Lower | Vysoká |
| Aktivní-aktivní pohotovostní režim | Střední | 0 hodin | Nízká | Střední | Střední |
| Cluster pro obnovení dat na vyžádání | Nejnižší | Nejvyšší | Nejvyšší | Nejvyšší | Nejnižší |
Osvědčené postupy
Bez ohledu na to, kterou konfiguraci zotavení po havárii zvolíte, postupujte podle těchto osvědčených postupů:
- Všechny databázové objekty, zásady a konfigurace by měly být trvalé ve správě zdrojového kódu, aby je bylo možné uvolnit do clusteru z vašeho nástroje pro automatizaci verzí. Další informace najdete v tématu Podpora Azure DevOps pro Azure Data Explorer.
- Navrhujte, vyvíjejte a implementujte ověřovací rutiny, aby se zajistilo, že jsou všechny clustery synchronizované z hlediska dat. Azure Data Explorer podporuje připojení mezi clustery. S ověřením vám může pomoct jednoduchý počet nebo řádky napříč tabulkami.
- Postupy vydávání verzí by měly zahrnovat kontroly zásad správného řízení a vyvážení, které zajišťují zrcadlení clusterů.
- Buďte plně obeznámeni s tím, co je potřeba k vytvoření clusteru od začátku.
- Vytvořte kontrolní seznam jednotek nasazení. Seznam bude jedinečný pro vaše potřeby, ale měl by zahrnovat: skripty nasazení, připojení příjmu dat, nástroje BI a další důležité konfigurace.