Návrh databáze s více tenanty pomocí služby Azure Cosmos DB for PostgreSQL
PLATÍ PRO: ![]() Azure Cosmos DB for PostgreSQL (využívající rozšíření databáze Citus do PostgreSQL)
Azure Cosmos DB for PostgreSQL (využívající rozšíření databáze Citus do PostgreSQL)
V tomto kurzu se pomocí služby Azure Cosmos DB for PostgreSQL naučíte:
- Vytvoření clusteru
- Vytvoření schématu pomocí nástroje psql
- Tabulky horizontálních oddílů napříč uzly
- Ingestace ukázkových dat
- Dotazování dat tenanta
- Sdílení dat mezi tenanty
- Přizpůsobení schématu pro jednotlivé tenanty
Požadavky
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Vytvoření clusteru
Přihlaste se k webu Azure Portal a následujícím postupem vytvořte cluster Azure Cosmos DB for PostgreSQL:
Na webu Azure Portal přejděte do části Vytvoření clusteru Azure Cosmos DB for PostgreSQL.
Ve formuláři Vytvoření clusteru Azure Cosmos DB for PostgreSQL:
Vyplňte požadované informace na kartě Základní informace.
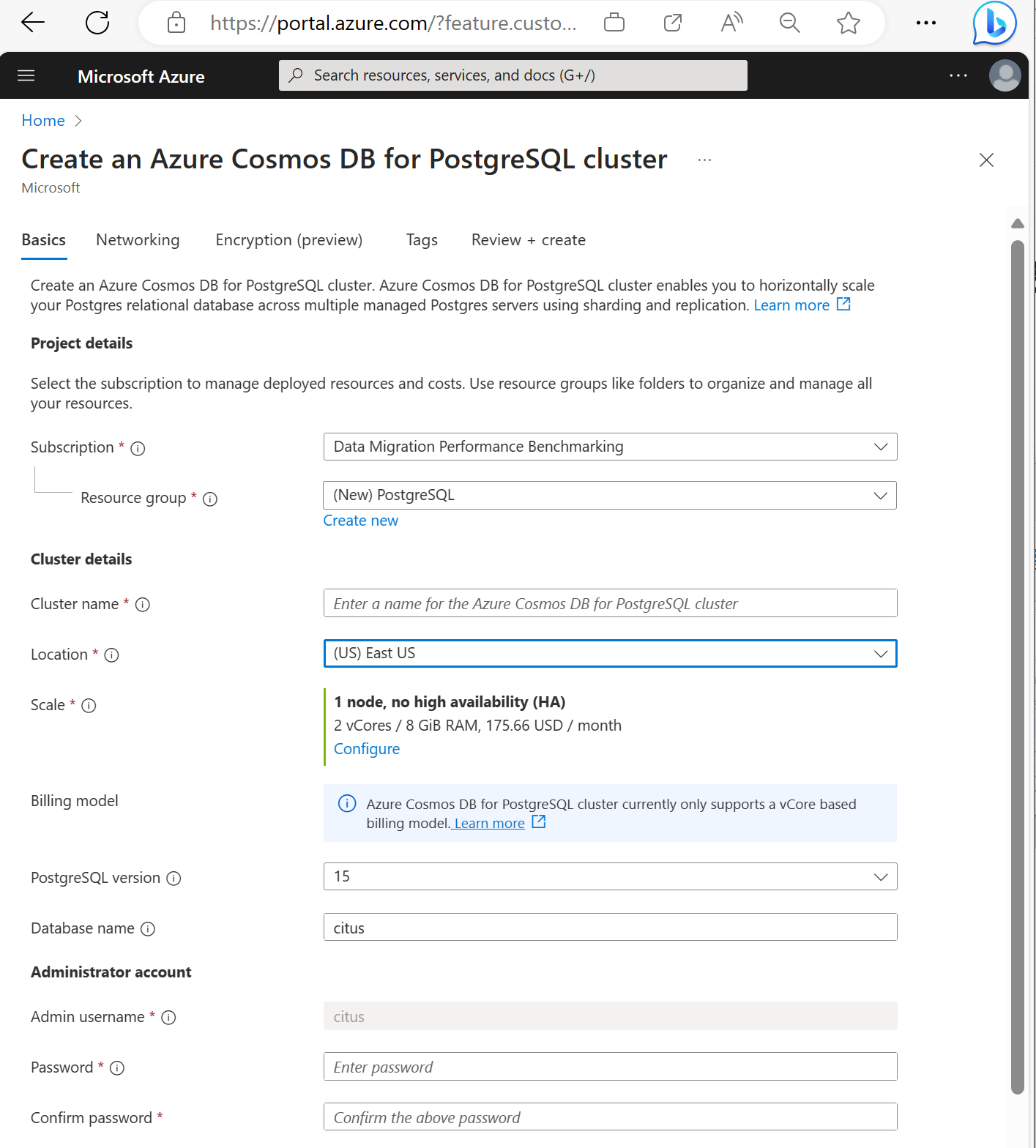
Většina možností je intuitivní, mějte však na paměti následující skutečnosti:
- Název clusteru určuje název DNS, který vaše aplikace používají pro připojení, ve formuláři
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Můžete zvolit hlavní verzi PostgreSQL, například 15. Azure Cosmos DB for PostgreSQL vždy podporuje nejnovější verzi Citus pro vybranou hlavní verzi Postgres.
- Uživatelské jméno správce musí mít hodnotu
citus. - Název databáze můžete nechat na výchozí hodnotě citus nebo definovat jediný název databáze. Po zřízení clusteru není možné přejmenovat databázi.
- Název clusteru určuje název DNS, který vaše aplikace používají pro připojení, ve formuláři
Vyberte Další: Sítě v dolní části obrazovky.
Na obrazovce Sítě vyberte Povolit veřejný přístup ze služeb a prostředků Azure v rámci Azure k tomuto clusteru.
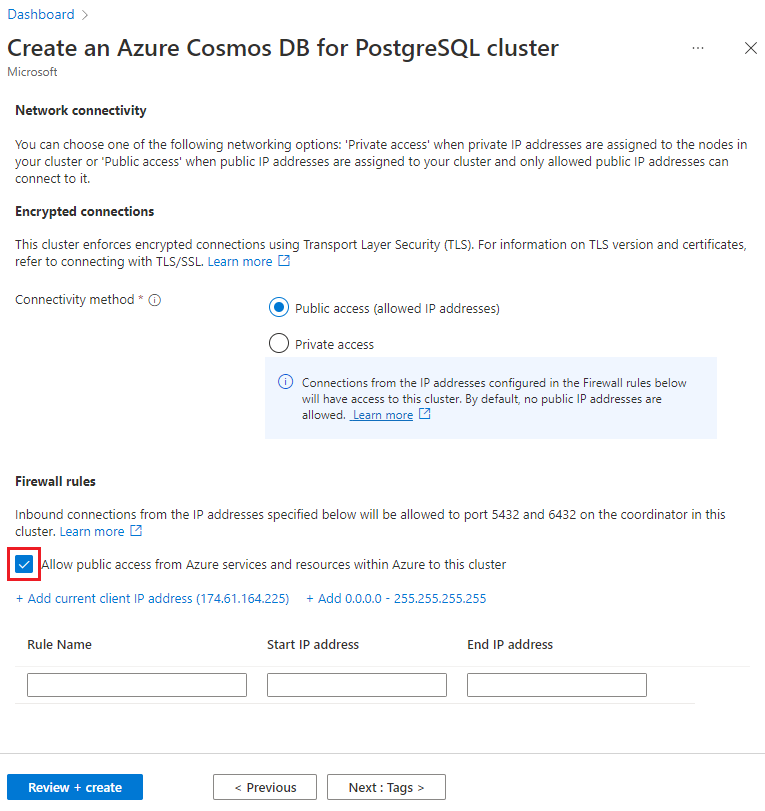
Vyberte Zkontrolovat a vytvořit a po ověření výběrem možnosti Vytvořit cluster vytvořte.
Zřizování trvá několik minut. Stránka se přesměruje na monitorování nasazení. Jakmile se stav změní z Nasazení probíhá na Nasazení se dokončilo, vyberte Přejít k prostředku.
Vytvoření schématu pomocí nástroje psql
Po připojení ke službě Azure Cosmos DB for PostgreSQL pomocí psql můžete provést některé základní úlohy. Tento kurz vás provede vytvořením webové aplikace, která inzerentům umožňuje sledovat své kampaně.
Aplikaci může používat více společností, takže vytvoříme tabulku, která bude obsahovat společnosti a další pro své kampaně. V konzole psql spusťte tyto příkazy:
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blocked_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id)
);
Každá kampaň bude platit za spouštění reklam. Přidejte také tabulku pro reklamy spuštěním následujícího kódu v psql za výše uvedeným kódem:
CREATE TABLE ads (
id bigserial,
company_id bigint,
campaign_id bigint,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, campaign_id)
REFERENCES campaigns (company_id, id)
);
Nakonec budeme sledovat statistiky o kliknutích a zobrazeních pro každou reklamu:
CREATE TABLE clicks (
id bigserial,
company_id bigint,
ad_id bigint,
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial,
company_id bigint,
ad_id bigint,
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
Nově vytvořené tabulky můžete zobrazit v seznamu tabulek nyní v psql spuštěním příkazu:
\dt
Aplikace s více tenanty můžou vynucovat jedinečnost jenom na tenanta, a proto všechny primární a cizí klíče zahrnují ID společnosti.
Tabulky horizontálních oddílů napříč uzly
Nasazení služby Azure Cosmos DB for PostgreSQL ukládá řádky tabulky na různých uzlech na základě hodnoty sloupce určeného uživatelem. Tento "distribuční sloupec" označuje, který tenant vlastní řádky.
Pojďme nastavit distribuční sloupec tak, aby byl company_id, identifikátor tenanta. V psql spusťte tyto funkce:
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
Důležité
Distribuce tabulek nebo použití horizontálního dělení založeného na schématu je nezbytná k využití funkcí výkonu služby Azure Cosmos DB for PostgreSQL. Pokud tabulky nebo schémata nedistribuujete, pracovní uzly nemůžou pomoct spouštět dotazy týkající se jejich dat.
Ingestace ukázkových dat
Mimo psql teď v normálním příkazovém řádku stáhněte ukázkové datové sady:
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
Zpět uvnitř psql hromadně načtěte data. Nezapomeňte spustit psql ve stejném adresáři, ve kterém jste stáhli datové soubory.
SET client_encoding TO 'UTF8';
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
Tato data se teď budou šířit mezi pracovní uzly.
Dotazování dat tenanta
Když aplikace požaduje data pro jednoho tenanta, může databáze spustit dotaz na jednom pracovním uzlu. Dotazy s jedním tenantem filtrují podle jednoho ID tenanta. Například následující filtry company_id = 5 dotazu pro reklamy a imprese. Zkuste ho spustit v psql, abyste viděli výsledky.
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
Sdílení dat mezi tenanty
Dosud byly všechny tabulky distribuovány company_id. Některá data ale přirozeně nepatří do žádného tenanta a dají se sdílet. Například všechny společnosti v ukázkové reklamní platformě můžou chtít získat geografické informace pro cílovou skupinu na základě IP adres.
Vytvořte tabulku pro uložení sdílených geografických informací. V psql spusťte následující příkazy:
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
Dále vytvořte geo_ips "referenční tabulku" pro uložení kopie tabulky do každého pracovního uzlu.
SELECT create_reference_table('geo_ips');
Načtěte je s ukázkovými daty. Nezapomeňte tento příkaz spustit v psql z adresáře, do kterého jste si datovou sadu stáhli.
\copy geo_ips from 'geo_ips.csv' with csv
Spojení tabulky kliknutí pomocí geo_ips je efektivní na všech uzlech. Tady je spojení, kde najdete umístění všech uživatelů, kteří klikli na reklamu 290. Zkuste spustit dotaz v psql.
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
Přizpůsobení schématu pro jednotlivé tenanty
Každý tenant může potřebovat ukládat speciální informace, které ostatní nepotřebují. Všichni tenanti ale sdílejí společnou infrastrukturu se stejným schématem databáze. Kam se můžou další data pustit?
Jedním z triků je použití otevřeného typu sloupce, jako je JSONB PostgreSQL. Naše schéma má volané clicks user_datapole JSONB .
Společnost (například pět společností) může pomocí sloupce sledovat, jestli je uživatel na mobilním zařízení.
Tady je dotaz, který vyhledá, kdo klikne na další: mobilní nebo tradiční návštěvníci.
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
Tento dotaz můžeme optimalizovat pro jednu společnost vytvořením částečného indexu.
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
Obecněji můžeme vytvořit indexy GIN pro každý klíč a hodnotu ve sloupci.
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
Vyčištění prostředků
V předchozích krocích jste vytvořili prostředky Azure v clusteru. Pokud v budoucnu tyto prostředky nepotřebujete, odstraňte cluster. Na stránce Přehled vašeho clusteru vyberte tlačítko Odstranit. Po zobrazení výzvy na automaticky otevírané stránce potvrďte název clusteru a vyberte poslední tlačítko Odstranit .
Další kroky
V tomto kurzu jste zjistili, jak zřídit cluster. Připojili jste se k němu pomocí psql, vytvořili jste schéma a distribuovaná data. Naučili jste se dotazovat data v rámci tenantů i mezi tenanty a přizpůsobit schéma pro jednotlivé tenanty.
- Informace o typech uzlů clusteru
- Určení nejlepší počáteční velikosti clusteru