Základní koncepty škálování ve službě Azure Cosmos DB for PostgreSQL
PLATÍ PRO: ![]() Azure Cosmos DB for PostgreSQL (využívající rozšíření databáze Citus do PostgreSQL)
Azure Cosmos DB for PostgreSQL (využívající rozšíření databáze Citus do PostgreSQL)
Než prošetříme kroky vytvoření nové aplikace, je užitečné se podívat na rychlý přehled hledaného výrazu a konceptů.
Přehled architektury
Azure Cosmos DB for PostgreSQL vám umožňuje distribuovat tabulky a/nebo schémata napříč několika počítači v clusteru a transparentně je dotazovat stejně jako v prostém PostgreSQL:
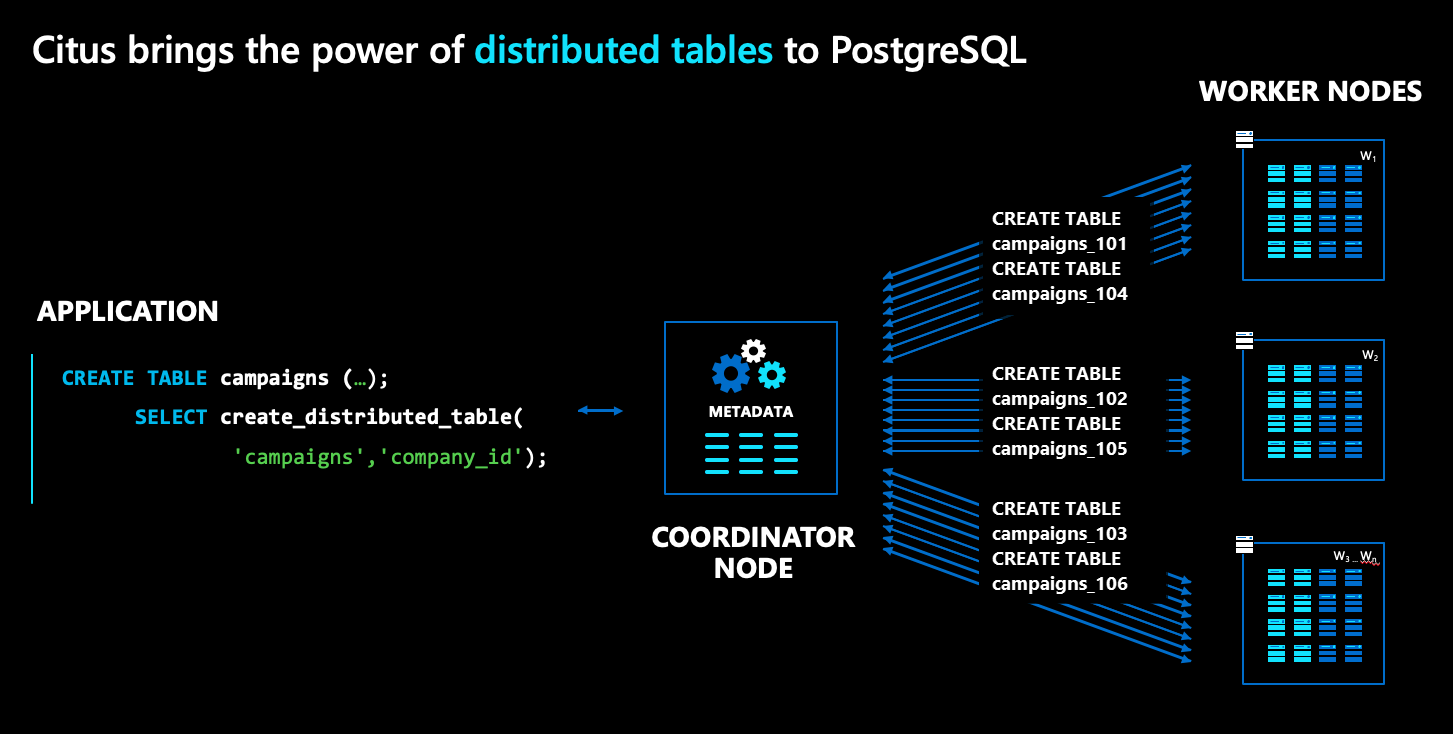
V architektuře Azure Cosmos DB for PostgreSQL existuje několik druhů uzlů:
- Koordinační uzel ukládá metadata distribuovaných tabulek a zodpovídá za distribuované plánování.
- Naproti tomu pracovní uzly ukládají skutečná data, metadata a výpočty.
- Koordinátor i pracovní procesy jsou prosté databáze PostgreSQL s načteným rozšířením
citus.
Pokud chcete distribuovat normální tabulku PostgreSQL, například campaigns v diagramu výše, spusťte příkaz s názvem create_distributed_table(). Po spuštění tohoto příkazu azure Cosmos DB for PostgreSQL transparentně vytvoří horizontální oddíly pro tabulku napříč pracovními uzly. V diagramu jsou horizontální oddíly reprezentovány jako modrá pole.
Pokud chcete distribuovat normální schéma PostgreSQL, spusťte citus_schema_distribute() příkaz. Jakmile tento příkaz spustíte, Azure Cosmos DB for PostgreSQL transparentně změní tabulky v těchto schématech na tabulky s horizontálním oddílem, které je možné přesunout jako jednotku mezi uzly clusteru.
Poznámka:
V clusteru bez pracovních uzlů jsou horizontální oddíly distribuovaných tabulek na koordinačním uzlu.
Horizontální oddíly jsou prosté (ale speciálně pojmenované) tabulky PostgreSQL, které obsahují řezy vašich dat. V našem příkladu, protože jsme distribuovali company_idkampaně campaigns horizontálních oddílů, ve kterých jsou kampaně různých společností přiřazeny různým horizontálním oddílům.
Distribuční sloupec (označovaný také jako klíč horizontálního dělení)
create_distributed_table() je magická funkce, kterou azure Cosmos DB for PostgreSQL poskytuje k distribuci tabulek a používání prostředků napříč několika počítači.
SELECT create_distributed_table(
'table_name',
'distribution_column');
Druhý argument výše vybere sloupec z tabulky jako distribuční sloupec. Může to být libovolný sloupec s nativním typem PostgreSQL (s celočíselným číslem a nejběžnějším textem). Hodnota distribučníhosloupceho sloupce určuje, do kterých řádků jde, do kterých horizontálních oddílů jde, což je důvod, proč se distribuční sloupec označuje také jako klíč horizontálního dělení.
Azure Cosmos DB for PostgreSQL rozhoduje, jak spouštět dotazy na základě jejich použití klíče horizontálního oddílu:
| Dotaz zahrnuje | Kde běží |
|---|---|
| pouze jeden klíč horizontálního oddílu | na pracovním uzlu, který obsahuje jeho horizontální oddíl |
| více klíčů horizontálních oddílů | paralelizovaná napříč několika uzly |
Volba klíče horizontálního dělení určuje výkon a škálovatelnost vašich aplikací.
- Nerovnoměrná distribuce dat na klíče horizontálních oddílů (označovaná také jako nerovnoměrná distribuce dat) není pro výkon optimální. Například nevybírejte sloupec, pro který jedna hodnota představuje 50 % dat.
- Klíče horizontálního dělení s nízkou kardinalitou můžou ovlivnit škálovatelnost. Můžete použít pouze tolik horizontálních oddílů, kolik existuje jedinečných hodnot klíčů. Vyberte klíč s kardinalitou ve stovkách až tisících.
- Spojení dvou velkých tabulek s různými klíči horizontálních oddílů může být pomalé. Zvolte společný klíč horizontálního oddílu napříč velkými tabulkami. Přečtěte si další informace o kolokaci.
Společné umístění blízko k sobě
Dalším konceptem úzce souvisejícím s klíčem horizontálního dělení je kolokace. Tabulky horizontálně dělené stejnými hodnotami distribučního sloupce jsou společné – horizontální oddíly společně slokovaných tabulek se ukládají na stejné pracovní procesy.
Níže jsou dvě tabulky horizontálně dělené stejným klíčem. site_id Jsou spolulokované.
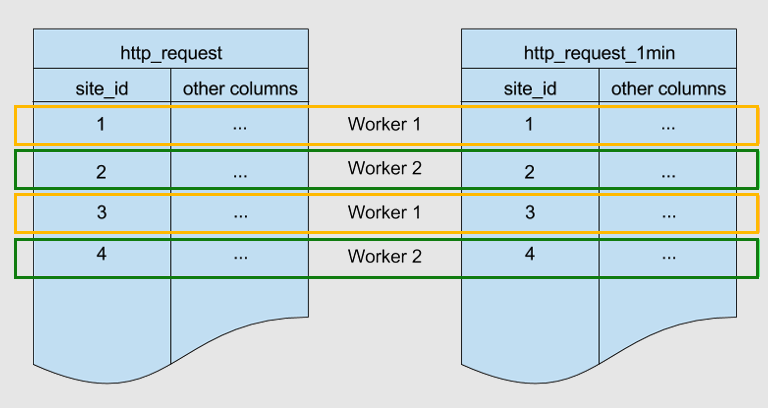
Azure Cosmos DB for PostgreSQL zajišťuje, aby řádky s odpovídající site_id hodnotou v obou tabulkách byly uloženy na stejném pracovním uzlu. Vidíte, že u obou tabulek jsou řádky s site_id=1 uloženy na pracovním procesu 1. Podobně pro ostatní ID webu.
Kolokace pomáhá optimalizovat hodnoty JOIN napříč těmito tabulkami. Pokud obě tabulky site_idpropojíte, azure Cosmos DB for PostgreSQL může spojení provést místně na pracovních uzlech bez náhodného prohazování dat mezi uzly.
Tabulky v rámci distribuovaného schématu se vždy vzájemně společně přidělují.