Načítání rozšířené generace (RAG) s využitím virtuálních jader azure Cosmos DB pro MongoDB
V rychle se vyvíjející sférě generující umělé inteligence (LLM) velké jazykové modely (LLM), jako je GPT-3.5, transformovaly zpracování přirozeného jazyka. Nově vznikající trend umělé inteligence je však použití vektorových úložišť, které hrají klíčovou roli při vylepšování aplikací AI.
V tomto kurzu se dozvíte, jak používat Azure Cosmos DB pro MongoDB (vCore), LangChain a OpenAI k implementaci technologie RAG (Retrieval-Augmented Generation) pro vynikající výkon AI společně s diskuzí o LLM a jejich omezeních. Prozkoumáme rychle přijímané paradigma "načítání rozšířené generace" (RAG) a stručně probereme architekturu LangChain, modely Azure OpenAI. Nakonec tyto koncepty integrujeme do reálné aplikace. Na konci budou čtenáři mít solidní porozumění těmto konceptům.
Vysvětlení velkých jazykových modelů (LLM) a jejich omezení
Velké jazykové modely (LLM) jsou pokročilé modely hluboké neurální sítě vytrénované na rozsáhlých textových datových sadách, které jim umožňují porozumět a generovat text podobný člověku. I když revoluční zpracování přirozeného jazyka má LLM svá omezení:
- Halucinace: LLM někdy generují fakticky nesprávné nebo neuzemněné informace, označované jako "halucinace".
- Zastaralá data: LLM se trénují na statických datových sadách, které nemusí obsahovat nejnovější informace a omezují jejich aktuální význam.
- Žádný přístup k místním datům uživatele: LLM nemají přímý přístup k osobním nebo lokalizovaným datům a omezují jejich schopnost poskytovat přizpůsobené odpovědi.
- Omezení tokenů: LLM mají maximální limit tokenů na interakci, což omezuje množství textu, které mohou zpracovat najednou. Například gpt-3.5-turbo openAI má limit tokenu 4096.
Využití generování rozšířeného načítání (RAG)
Generování rozšířeného načítání (RAG) je architektura navržená k překonání omezení LLM. RAG používá vektorové vyhledávání k načtení relevantních dokumentů na základě vstupního dotazu a poskytuje tyto dokumenty jako kontext LLM pro generování přesnějších odpovědí. Místo toho, abyste se museli spoléhat výhradně na předem natrénované vzory, rag vylepšuje odpovědi začleněním aktuálních relevantních informací. Tento přístup pomáhá:
- Minimalizovat halucinace: Uzemnění odpovědí v faktických informacích.
- Zajistit aktuální informace: Načtení nejnovějších dat, aby se zajistily aktuální odpovědi.
- Využití externích databází: I když neuděluje přímý přístup k osobním údajům, RAG umožňuje integraci s externími znalostní báze specifickými pro uživatele.
- Optimalizace využití tokenů: Díky tomu, že se zaměříte na nejrelevavantnější dokumenty, zrychlí využití tokenů RAG.
V tomto kurzu se dozvíte, jak lze rag implementovat pomocí služby Azure Cosmos DB pro MongoDB (virtuální jádro) k vytvoření aplikace pro odpovědi na otázky přizpůsobené vašim datům.
Přehled architektury aplikací
Následující diagram architektury znázorňuje klíčové komponenty implementace RAG:
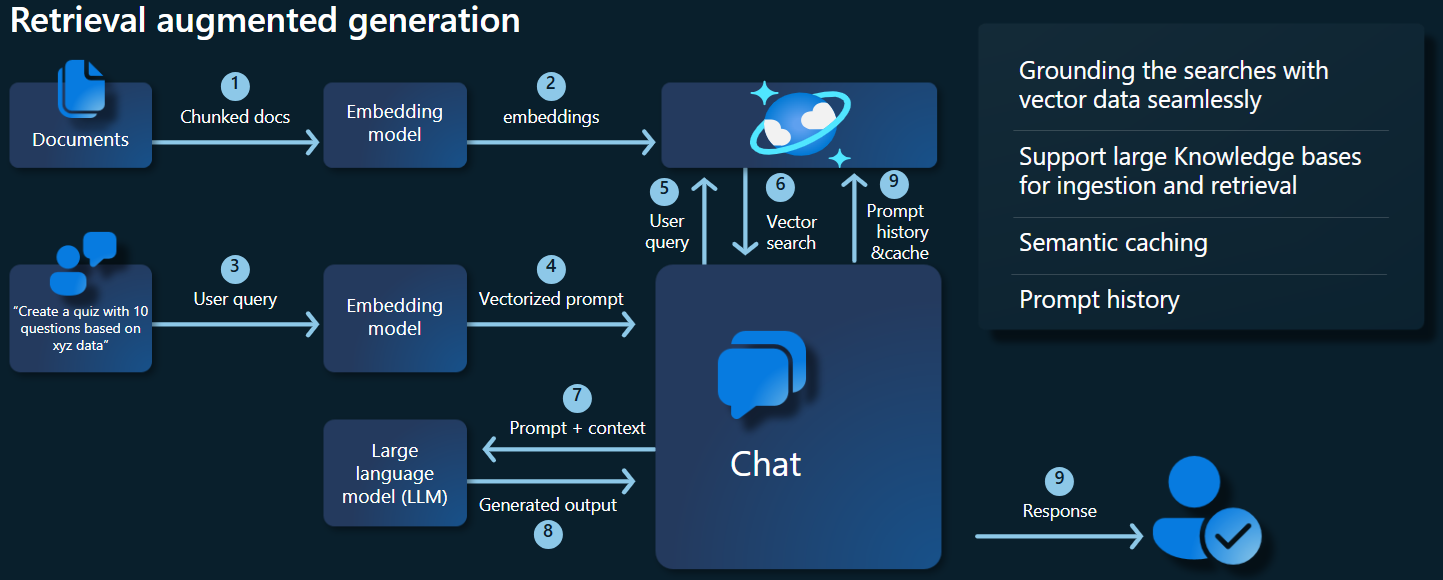
Klíčové komponenty a architektury
Teď probereme různé architektury, modely a komponenty používané v tomto kurzu a zdůrazňujeme jejich role a nuance.
Azure Cosmos DB pro MongoDB (virtuální jádra)
Azure Cosmos DB pro MongoDB (vCore) podporuje sémantické vyhledávání podobnosti, které jsou nezbytné pro aplikace využívající AI. Umožňuje reprezentovat data v různých formátech jako vektorové vkládání, které lze uložit společně se zdrojovými daty a metadaty. Pomocí přibližného algoritmu nejbližšího souseda, jako je hierarchický pohyblivý malý svět (HNSW), je možné tyto vkládání dotazovat na rychlé sémantické vyhledávání podobností.
Architektura LangChain
LangChain zjednodušuje vytváření aplikací LLM tím, že poskytuje standardní rozhraní pro řetězy, více integrací nástrojů a komplexní řetězy pro běžné úlohy. Umožňuje vývojářům umělé inteligence vytvářet aplikace LLM, které využívají externí zdroje dat.
Klíčové aspekty jazyka LangChain:
- Řetězy: Posloupnosti komponent, které řeší konkrétní úlohy.
- Komponenty: Moduly, jako jsou obálky LLM, obálky vektorového úložiště, šablony výzvy, zavaděče dat, rozdělovače textu a načítáče.
- Modularita: Zjednodušuje vývoj, ladění a údržbu.
- Popularita: Opensourcový projekt rychle získává přijetí a vyvíjí se tak, aby vyhovoval potřebám uživatelů.
rozhraní Aplikace Azure Services
App Services poskytují robustní platformu pro vytváření uživatelsky přívětivých webových rozhraní pro aplikace Gen-AI. Tento kurz používá Aplikace Azure služby k vytvoření interaktivního webového rozhraní pro aplikaci.
Modely OpenAI
OpenAI je vedoucí ve výzkumu umělé inteligence a poskytuje různé modely pro generování jazyka, vektorizaci textu, vytváření obrázků a převod zvuku na text. V tomto kurzu použijeme vložené modely OpenAI a jazykové modely, které jsou klíčové pro pochopení a generování jazykových aplikací.
Vkládání modelů oproti modelům generování jazyka
| Kategorie | Model vkládání textu | Jazykový model |
|---|---|---|
| Účel | Převod textu na vektorové vkládání | Pochopení a generování přirozeného jazyka |
| Funkce | Transformuje textová data na vysoce dimenzionální pole čísel a zachytává sémantický význam textu. | Pochopí a vytvoří text podobný člověku na základě daného vstupu. |
| Výstup | Matice čísel (vkládání vektorů). | Text, odpovědi, překlady, kód atd. |
| Příklad výstupu | Každé vkládání představuje sémantický význam textu v číselné podobě s dimenzí určenou modelem. Například text-embedding-ada-002 generuje vektory s rozměry 1536. |
Kontextově relevantní a koherentní text vygenerovaný na základě zadaného vstupu. Může například gpt-3.5-turbo generovat odpovědi na otázky, překládat text, psát kód a provádět další otázky. |
| Typické případy použití | - Sémantické vyhledávání | - Chatovací roboti |
| - Systémy doporučení | – Automatizované vytváření obsahu | |
| - Clustering a klasifikace textových dat | - Překlad jazyka | |
| - Načítání informací | -Sumarizace | |
| Reprezentace dat | Číselná reprezentace (vkládání) | Text přirozeného jazyka |
| Rozměrnost | Délka pole odpovídá počtu dimenzí v prostoru pro vložení, například 1536 dimenzí. | Obvykle se představuje jako posloupnost tokenů s kontextem určující délku. |
Hlavní komponenty aplikace
- Virtuální jádro Služby Azure Cosmos DB pro MongoDB: Ukládání a dotazování vložených vektorů
- LangChain: Vytvoření pracovního postupu LLM aplikace. Využívá nástroje, jako jsou:
- Zavaděč dokumentů: Pro načítání a zpracování dokumentů z adresáře.
- Integrace vektorových úložiště: Ukládání a dotazování vektorových vkládání ve službě Azure Cosmos DB.
- AzureCosmosDBVectorSearch: Obálka kolem vyhledávání vektorů cosmos DB
- Aplikace Azure Služby: Vytvoření uživatelského rozhraní pro aplikaci pro kosmické potraviny
- Azure OpenAI: Poskytování modelů LLM a vkládání, včetně:
- text-embedding-ada-002: Model vkládání textu, který převádí text na vektorové vkládání s rozměry 1536.
- gpt-3.5-turbo: Jazykový model pro pochopení a generování přirozeného jazyka.
Nastavení prostředí
Pokud chcete začít s optimalizací generování rozšířeného načítání (RAG) pomocí služby Azure Cosmos DB pro MongoDB (vCore), postupujte takto:
- V Microsoft Azure vytvořte následující prostředky:
- Cluster azure Cosmos DB pro virtuální jádra MongoDB: Projděte si úvodní příručku.
- Prostředek Azure OpenAI s využitím:
- Nasazení modelu vložení (například
text-embedding-ada-002). - Nasazení modelu chatu (například
gpt-35-turbo).
- Nasazení modelu vložení (například
Ukázkové dokumenty
V tomto kurzu načítáme jeden textový soubor pomocí dokumentu. Tyto soubory by měly být uloženy v adresáři s názvem data ve složce src . Obsah je následující:
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
Nahrání dokumentů
Nastavte připojovací řetězec cosmos DB pro MongoDB (virtuální jádro), název databáze, název kolekce a index:
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]Inicializuje klienta vkládání.
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )Vytvořte vkládání z dat, uložte do databáze a vraťte připojení k úložišti vektorů, Cosmos DB pro MongoDB (virtuální jádra).
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )Vytvořte následující vektorový index HNSW v kolekci (všimněte si, že název indexu je stejný jako výše).
num_lists = 100 dimensions = 1536 similarity_algorithm = CosmosDBSimilarityType.COS kind = CosmosDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
Provádění vektorových vyhledávání s využitím Cosmos DB pro MongoDB (virtuální jádra)
Připojte se k úložišti vektorů.
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )Definujte funkci, která provádí sémantické vyhledávání podobnosti pomocí služby Cosmos DB Vector Search v dotazu (všimněte si, že tento fragment kódu je jen testovací funkce).
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)Inicializace chatovacího klienta pro implementaci funkce RAG
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )Vytvoření funkce RAG
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )Převede vektorové úložiště na načítač, který může hledat relevantní dokumenty na základě zadaných parametrů.
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )Vytvořte řetěz retrieveru, který je vědom historie konverzací a zajišťuje kontextově relevantní načítání dokumentů pomocí modelu azure_openai_chat a vector_store_retriever.
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)Vytvořte řetěz, který kombinuje načtené dokumenty do koherentní odpovědi pomocí jazykového modelu (azure_openai_chat) a zadané výzvy (context_prompt).
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)Vytvořte řetěz, který zpracovává celý proces načítání, integraci řetězu retrieveru pracujícího s historií a zkombinovaný řetěz dokumentů. Tento řetězec RAG lze spustit, aby se načetly a vygenerovaly kontextově přesné odpovědi.
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
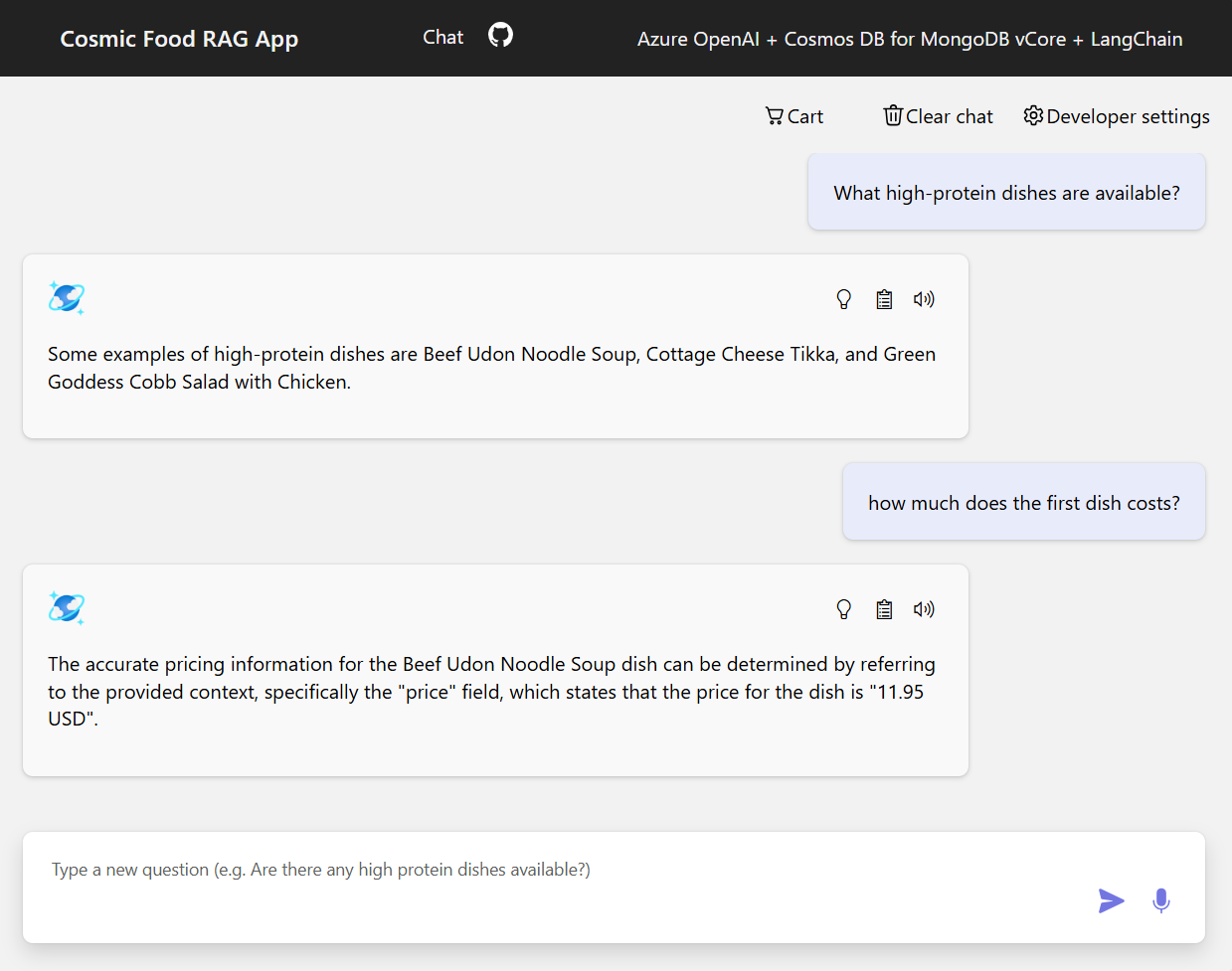
Ukázkové výstupy
Následující snímek obrazovky znázorňuje výstupy pro různé otázky. Hledání čistě sémantické podobnosti vrací nezpracovaný text ze zdrojových dokumentů, zatímco aplikace pro odpovědi na otázky využívající architekturu RAG generuje přesné a přizpůsobené odpovědi kombinací načteného obsahu dokumentu s jazykovým modelem.
Závěr
V tomto kurzu jsme prozkoumali, jak vytvořit aplikaci pro odpovědi na otázky, která komunikuje s vašimi privátními daty pomocí Cosmos DB jako úložiště vektorů. Díky využití architektury rag (retrieval-augmented generation) s využitím LangChain a Azure OpenAI jsme ukázali, jak jsou úložiště vektorů pro aplikace LLM nezbytné.
RAG je významným pokrokem v umělé inteligenci, zejména při zpracování přirozeného jazyka, a kombinování těchto technologií umožňuje vytvářet výkonné aplikace řízené AI pro různé případy použití.