Migrace dat z MongoDB do účtu Azure Cosmos DB pro MongoDB pomocí Azure Databricks
PLATÍ PRO: ![]() MongoDB
MongoDB
Tento průvodce migrací je součástí série migrace databází z MongoDB do rozhraní API služby Azure Cosmos DB pro MongoDB. Důležité kroky migrace jsou před migrací, migrací a po migraci, jak je znázorněno níže.

Migrace dat pomocí Azure Databricks
Azure Databricks je nabídka PaaS (platforma jako služba) pro Apache Spark. Nabízí způsob, jak provádět offline migrace u rozsáhlé datové sady. Azure Databricks můžete použít k offline migraci databází z MongoDB do Azure Cosmos DB pro MongoDB.
V tomto kurzu se naučíte, jak:
Zřízení clusteru Azure Databricks
Přidání závislostí
Vytvoření a spuštění poznámkového bloku Scala nebo Pythonu
Optimalizace výkonu migrace
Řešení chyb omezování rychlosti, ke kterým může dojít během migrace
Požadavky
Pro absolvování tohoto kurzu je potřeba provést následující:
- Proveďte kroky před migrací , jako je odhad propustnosti a výběr klíče horizontálního oddílu.
- Vytvořte účet Služby Azure Cosmos DB pro MongoDB.
Zřízení clusteru Azure Databricks
Podle pokynů můžete zřídit cluster Azure Databricks. Doporučujeme vybrat modul runtime Databricks verze 7.6, který podporuje Spark 3.0.
Přidání závislostí
Přidejte do clusteru konektor MongoDB pro knihovnu Spark a připojte se k nativním koncovým bodům MongoDB i Ke službě Azure Cosmos DB pro MongoDB. V clusteru vyberte Knihovny>Nainstalovat nový>Maven a pak přidejte org.mongodb.spark:mongo-spark-connector_2.12:3.0.1 souřadnice Mavenu.
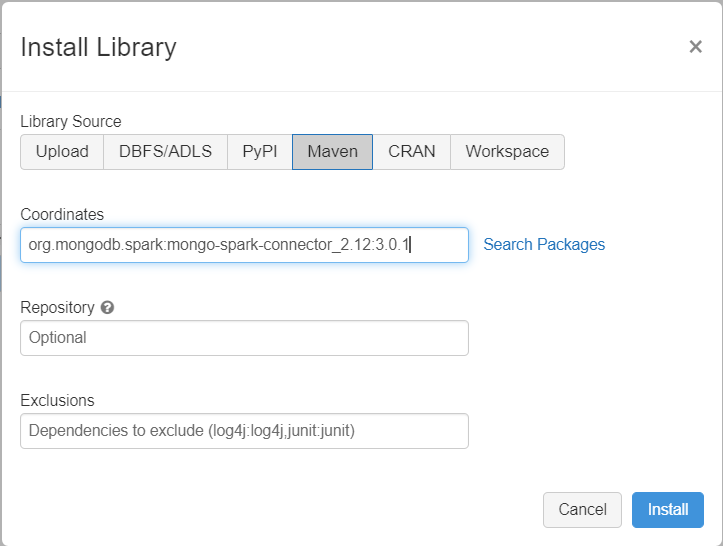
Vyberte Nainstalovat a po dokončení instalace restartujte cluster.
Poznámka:
Po instalaci konektoru MongoDB pro knihovnu Spark se ujistěte, že restartujete cluster Databricks.
Potom můžete vytvořit poznámkový blok Scala nebo Python pro migraci.
Vytvoření poznámkového bloku Scala pro migraci
Vytvoření poznámkového bloku Scala v Databricks Před spuštěním následujícího kódu nezapomeňte zadat správné hodnoty proměnných:
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
Vytvoření poznámkového bloku Pythonu pro migraci
Vytvořte poznámkový blok Pythonu v Databricks. Před spuštěním následujícího kódu nezapomeňte zadat správné hodnoty proměnných:
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
Optimalizace výkonu migrace
Výkon migrace je možné upravit pomocí těchto konfigurací:
Počet pracovních procesů a jader v clusteru Spark: Více pracovních procesů znamená více výpočetních horizontálních oddílů pro provádění úloh.
maxBatchSize: Hodnota
maxBatchSizeřídí rychlost ukládání dat do cílové kolekce Azure Cosmos DB. Pokud je však hodnota maxBatchSize příliš vysoká pro propustnost kolekce, může to způsobit chyby omezování rychlosti.V závislosti na počtu exekutorů v clusteru Spark budete muset upravit počet pracovních procesů a maxBatchSize, případně velikost (a to je důvod nákladů na RU) jednotlivých zapsaných dokumentů a omezení propustnosti cílové kolekce.
Tip
maxBatchSize = propustnost kolekce / ( náklady na RU za 1 dokument * počet pracovních procesů Sparku * počet jader procesoru na pracovní proces )
MongoDB Spark partitioner a partitionKey: Výchozí použitý partitioner je MongoDefaultPartitioner a výchozí partitionKey je _id. Partitioner lze změnit přiřazením hodnoty
MongoSamplePartitionerke vstupní konfigurační vlastnostispark.mongodb.input.partitioner. Podobně lze partitionKey změnit přiřazením příslušného názvu pole ke vstupní konfigurační vlastnostispark.mongodb.input.partitioner.partitionKey. Správný klíč oddílu vám pomůže vyhnout se nerovnoměrné distribuci dat (velký počet záznamů zapisovaných pro stejnou hodnotu klíče horizontálního oddílu).Zakažte indexy během přenosu dat: U velkých objemů migrace dat zvažte zakázání indexů, speciálně index se zástupným znakem v cílové kolekci. Indexy zvyšují náklady na RU při psaní jednotlivých dokumentů. Uvolnění těchto RU může pomoct zlepšit rychlost přenosu dat. Po migraci dat můžete indexy povolit.
Odstraňování potíží
Chyba časového limitu (kód chyby 50)
Může se zobrazit kód chyby 50 pro operace s databází Azure Cosmos DB for MongoDB. Následující scénáře můžou způsobit chyby časového limitu:
- Propustnost přidělená databázi je nízká: Ujistěte se, že má cílová kolekce přiřazenou dostatečnou propustnost.
- Nadměrná nerovnoměrná distribuce dat s velkým objemem dat Pokud máte velké množství dat, která se mají migrovat do dané tabulky, ale mají v datech značnou nerovnoměrnou distribuci, může docházet k omezování rychlosti i v případě, že máte v tabulce zřízeno několik jednotek žádostí. Jednotky žádostí jsou rozdělené rovnoměrně mezi fyzické oddíly a nerovnoměrná distribuce dat může způsobit kritické body požadavků na jeden horizontální oddíl. Nerovnoměrná distribuce dat znamená velký počet záznamů pro stejnou hodnotu klíče horizontálního oddílu.
Omezování rychlosti (kód chyby 16500)
Může se zobrazit kód chyby 16500 pro operace s databází Azure Cosmos DB for MongoDB. Jedná se o chyby omezování rychlosti a u starších účtů nebo účtů, u kterých je zakázaná funkce opakování na straně serveru.
- Povolit opakování na straně serveru: Povolte funkci opakování na straně serveru (SSR) a nechte server opakovat operace s omezeným rychlostem automaticky.
Optimalizace po migraci
Po migraci dat se můžete připojit ke službě Azure Cosmos DB a spravovat data. Můžete také postupovat podle dalších kroků po migraci, jako je optimalizace zásad indexování, aktualizace výchozí úrovně konzistence nebo konfigurace globální distribuce pro váš účet služby Azure Cosmos DB. Další informace najdete v článku o optimalizaci po migraci.
Další materiály
- Pokoušíte se naplánovat kapacitu migrace do služby Azure Cosmos DB?
- Pokud víte, že je počet virtuálních jader a serverů ve vašem existujícím databázovém clusteru, přečtěte si o odhadu jednotek žádostí pomocí virtuálních jader nebo virtuálních procesorů.
- Pokud znáte typické sazby požadavků pro vaši aktuální úlohu databáze, přečtěte si informace o odhadu jednotek žádostí pomocí plánovače kapacity služby Azure Cosmos DB.