Přehled indexování ve službě Azure Cosmos DB
PLATÍ PRO: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Skřítek
Skřítek ![]() Stůl
Stůl
Azure Cosmos DB je databáze nezávislá na schématu, která umožňuje iterovat ve vaší aplikaci bez nutnosti zabývat se správou schématu nebo indexu. Azure Cosmos DB ve výchozím nastavení automaticky indexuje všechny vlastnosti všech položek v kontejneru , aniž by bylo nutné definovat jakékoli schéma nebo konfigurovat sekundární indexy.
Cílem tohoto článku je vysvětlit, jak služba Azure Cosmos DB indexuje data a jak pomocí indexů zlepšuje výkon dotazů. Než prozkoumáte, jak přizpůsobit zásady indexování, doporučujeme projít si tuto část.
Od položek po stromy
Pokaždé, když je položka uložená v kontejneru, její obsah se promítá jako dokument JSON a pak se převede na reprezentaci stromu. Tento převod znamená, že každá vlastnost této položky je reprezentována jako uzel ve stromu. Pseudo kořenový uzel je vytvořen jako nadřazený pro všechny vlastnosti první úrovně položky. Uzly typu list obsahují skutečné skalární hodnoty přenášené položkou.
Jako příklad zvažte tuto položku:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
Tento strom představuje ukázku položky JSON:
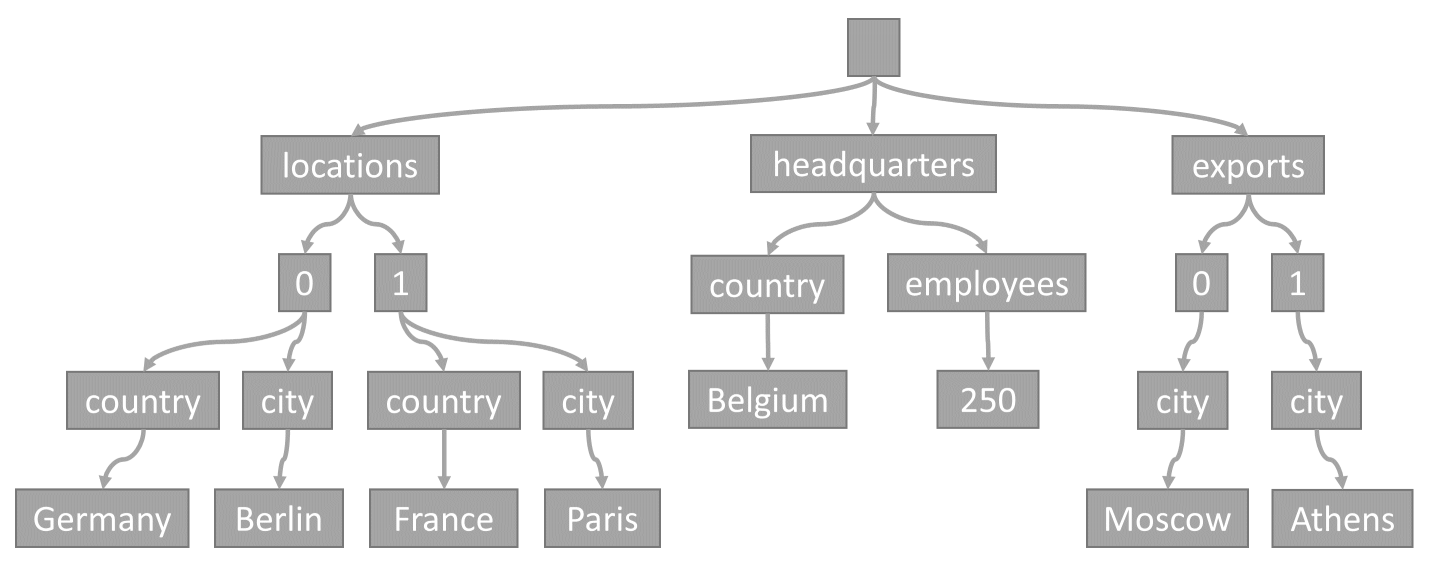
Všimněte si, jak jsou pole kódována ve stromu: každá položka v poli získá zprostředkující uzel označený indexem této položky v rámci pole (0, 1 atd.).
Z stromů na cesty k vlastnostem
Důvodem, proč Azure Cosmos DB transformuje položky na stromy, je to, že umožňuje systému odkazovat na vlastnosti pomocí jejich cest v těchto stromech. Abychom získali cestu pro vlastnost, můžeme procházet strom z kořenového uzlu do této vlastnosti a zřetězit popisky jednotlivých procházených uzlů.
Tady jsou cesty pro každou vlastnost z ukázkové položky popsané výše:
/locations/0/country: "Německo"/locations/0/city: "Berlín"/locations/1/country: "Francie"/locations/1/city: "Paříž"/headquarters/country: "Belgie"/headquarters/employees: 250/exports/0/city: "Moskva"/exports/1/city: "Athény"
Azure Cosmos DB efektivně indexuje cestu každé vlastnosti a její odpovídající hodnotu při zápisu položky.
Typy indexů
Azure Cosmos DB v současné době podporuje tři typy indexů. Tyto typy indexů můžete nakonfigurovat při definování zásad indexování.
Index rozsahu
Indexy rozsahu jsou založené na uspořádané stromové struktuře. Typ indexu rozsahu se používá pro:
Dotazy na rovnost:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")Shoda rovnosti u elementu pole
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")Dotazy na rozsah:
SELECT * FROM container c WHERE c.property > 'value'Poznámka:
(pracuje pro
>,<,>=,<=,!=)Kontrola přítomnosti vlastnosti:
SELECT * FROM c WHERE IS_DEFINED(c.property)Funkce systému řetězců:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")ORDER BYdotazy:SELECT * FROM container c ORDER BY c.propertyJOINdotazy:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
Indexy rozsahu lze použít u skalárních hodnot (řetězec nebo číslo). Výchozí zásady indexování pro nově vytvořené kontejnery u všech řetězců a čísel vynucují indexy rozsahu. Informace o konfiguraci indexů rozsahů najdete v příkladech zásad indexování rozsahu.
Poznámka:
ORDER BY Klauzule, která objednávky podle jedné vlastnosti vždy potřebuje index rozsahu a selže, pokud cesta, na kterou odkazuje, ji nemá. Podobně dotaz, ORDER BY který objednává podle více vlastností , vždy potřebuje složený index.
Prostorový index
Prostorové indexy umožňují efektivní dotazy na geoprostorové objekty, jako jsou body, čáry, mnohoúhelníky a multipolygony. Tyto dotazy používají klíčová slova ST_DISTANCE, ST_WITHIN a ST_INTERSECTS. Tady je několik příkladů, které používají typ prostorového indexu:
Geoprostorové dotazy na vzdálenost:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Geoprostorové v rámci dotazů:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })Geoprostorové protínající dotazy:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
Prostorové indexy lze použít pro správně formátované objekty GeoJSON . Body, LineStrings, Polygons a MultiPolygons jsou v současné době podporovány. Informace o konfiguraci prostorových indexů najdete v příkladech zásad prostorového indexování.
Složené indexy
Složené indexy zvyšují efektivitu při provádění operací s více poli. Složený typ indexu se používá pro:
ORDER BYdotazy na více vlastností:SELECT * FROM container c ORDER BY c.property1, c.property2Dotazy s filtrem a
ORDER BY. Tyto dotazy mohou využít složený index, pokud je vlastnost filtru přidánaORDER BYdo klauzule.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2Dotazy s filtrem dvou nebo více vlastností, kde alespoň jedna vlastnost je filtr rovnosti
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
Pokud jeden predikát filtru používá jeden typ indexu, dotazovací modul se vyhodnotí jako první před prohledáváním zbytku. Pokud máte například dotaz SQL, například SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
Výše uvedený dotaz nejprve vyfiltruje položky, kde firstName = "Andrew" pomocí indexu. Pak předá všechny položky firstName = "Andrew" prostřednictvím následného kanálu k vyhodnocení predikátu filtru CONTAINS.
Dotazy můžete urychlit a vyhnout se úplným kontrolám kontejnerů při použití funkcí, které provádějí úplnou kontrolu, jako je CONTAINS. Můžete přidat další predikáty filtru, které používají index k urychlení těchto dotazů. Pořadí klauzulí filtru není důležité. Dotazovací modul zjistí, které predikáty jsou selektivnější, a odpovídajícím způsobem dotaz spustí.
Informace o konfiguraci složených indexů najdete v příkladech složených zásad indexování.
Vektorové indexy
Vektorové indexy zvyšují efektivitu při provádění vektorových hledání pomocí VectorDistance systémové funkce. Hledání vektorů bude mít při využití vektorového indexu výrazně nižší latenci, vyšší propustnost a nižší spotřebu RU.
Informace o konfiguraci vektorových indexů najdete v příkladech zásad indexování vektorů.
ORDER BYvektorové vyhledávací dotazy:SELECT TOP 10 * FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Projekce skóre podobnosti v dotazech vektorového vyhledávání:
SELECT TOP 10 c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Filtry rozsahu podle skóre podobnosti.
SELECT TOP 10 * FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)
Důležité
V současné době jsou vektorové zásady a indexy vektorů neměnné po vytvoření. Pokud chcete provést změny, vytvořte novou kolekci.
Využití indexu
Dotazovací modul může vyhodnotit filtry dotazů seřazené podle nejúčinnějších a nejméně efektivních způsobů:
- Hledání indexu
- Přesná kontrola indexu
- Rozšířené prohledávání indexu
- Úplná kontrola indexu
- Úplná kontrola
Když indexujete cesty vlastností, dotazovací modul index automaticky použije co nejefektivněji. Kromě indexování nových cest vlastností nemusíte nic konfigurovat, abyste optimalizovali způsob, jakým dotazy používají index. Poplatky za RU dotazu jsou kombinací poplatku za RU z využití indexu a poplatku za RU při načítání položek.
Tady je tabulka, která shrnuje různé způsoby použití indexů ve službě Azure Cosmos DB:
| Typ vyhledávání indexu | Popis | Běžné příklady | Poplatek za RU z využití indexu | Poplatky za RU při načítání položek z transakčního úložiště dat |
|---|---|---|---|---|
| Hledání indexu | Čtení povinných indexovaných hodnot a načtení pouze odpovídajících položek z transakčního úložiště dat | Filtry rovnosti, IN | Konstantní filtr rovnosti | Zvyšuje se na základě počtu položek ve výsledcích dotazu. |
| Přesná kontrola indexu | Binární vyhledávání indexovaných hodnot a načítání pouze odpovídajících položek z transakčního úložiště dat | Porovnání rozsahů (>, , <= <nebo >=), StartsWith | Srovnatelné s hledáním indexů se mírně zvyšuje na základě kardinality indexovaných vlastností. | Zvyšuje se na základě počtu položek ve výsledcích dotazu. |
| Rozšířené prohledávání indexu | Optimalizované vyhledávání (ale méně efektivní než binární vyhledávání) indexovaných hodnot a načítání pouze odpovídajících položek z transakčního úložiště dat | StartsWith (nerozlišující velká a malá písmena), StringEquals (nerozlišuje velká a malá písmena) | Mírně se zvyšuje na základě kardinality indexovaných vlastností. | Zvyšuje se na základě počtu položek ve výsledcích dotazu. |
| Úplná kontrola indexu | Čtení jedinečné sady indexovaných hodnot a načtení pouze odpovídajících položek z transakčního úložiště dat | Obsahuje, EndsWith, RegexMatch, LIKE | Zvyšuje lineárně na základě kardinality indexovaných vlastností. | Zvyšuje se na základě počtu položek ve výsledcích dotazu. |
| Úplná kontrola | Načtení všech položek z transakčního úložiště dat | Horní, Dolní | – | Zvyšuje se na základě počtu položek v kontejneru. |
Při psaní dotazů byste měli použít predikáty filtru, které index používají co nejefektivněji. Pokud by například pro váš případ použití fungovalo, StartsWith Contains měli byste se rozhodnout StartsWith , protože místo úplné kontroly indexu provede přesnou kontrolu indexu.
Podrobnosti o využití indexu
V této části se podíváme na další podrobnosti o tom, jak dotazy používají indexy. Tato úroveň podrobností není nutná k tomu, abyste se naučili začít se službou Azure Cosmos DB, ale je podrobně zdokumentovaná pro zvědavé uživatele. Odkazujeme na ukázku položky sdílené dříve v tomto dokumentu:
Příklady položek:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB používá invertovaný index. Index funguje tak, že namapuje každou cestu JSON na sadu položek, které danou hodnotu obsahují. Mapování ID položky je reprezentováno na mnoha různých stránkách indexu kontejneru. Tady je ukázkový diagram invertovaného indexu pro kontejner, který obsahuje dvě ukázkové položky:
| Cesta | Hodnota | Seznam ID položek |
|---|---|---|
| /locations/0/country | Německo | 0 |
| /locations/0/country | Irsko | 2 |
| /locations/0/city | Berlin | 0 |
| /locations/0/city | Dublin | 2 |
| /locations/1/country | Francie | 0 |
| /locations/1/city | Paříž | 0 |
| /centrála/země | Belgie | 1, 2 |
| /centrála/zaměstnanci | 200 | 2 |
| /centrála/zaměstnanci | 250 | 0 |
Invertovaný index má dva důležité atributy:
- Pro danou cestu jsou hodnoty seřazeny vzestupně. Proto může dotazovací modul snadno sloužit
ORDER BYz indexu. - Pro danou cestu může dotazovací modul prohledávat odlišnou sadu možných hodnot a identifikovat stránky indexu, ve kterých jsou výsledky.
Dotazovací stroj může invertovaný index využívat čtyřmi různými způsoby:
Hledání indexu
Představte si následující dotaz:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
Predikát dotazu (filtrování položek, ve kterých má každé umístění "Francie" jako zemi nebo oblast), by odpovídalo cestě zvýrazněné v tomto diagramu:
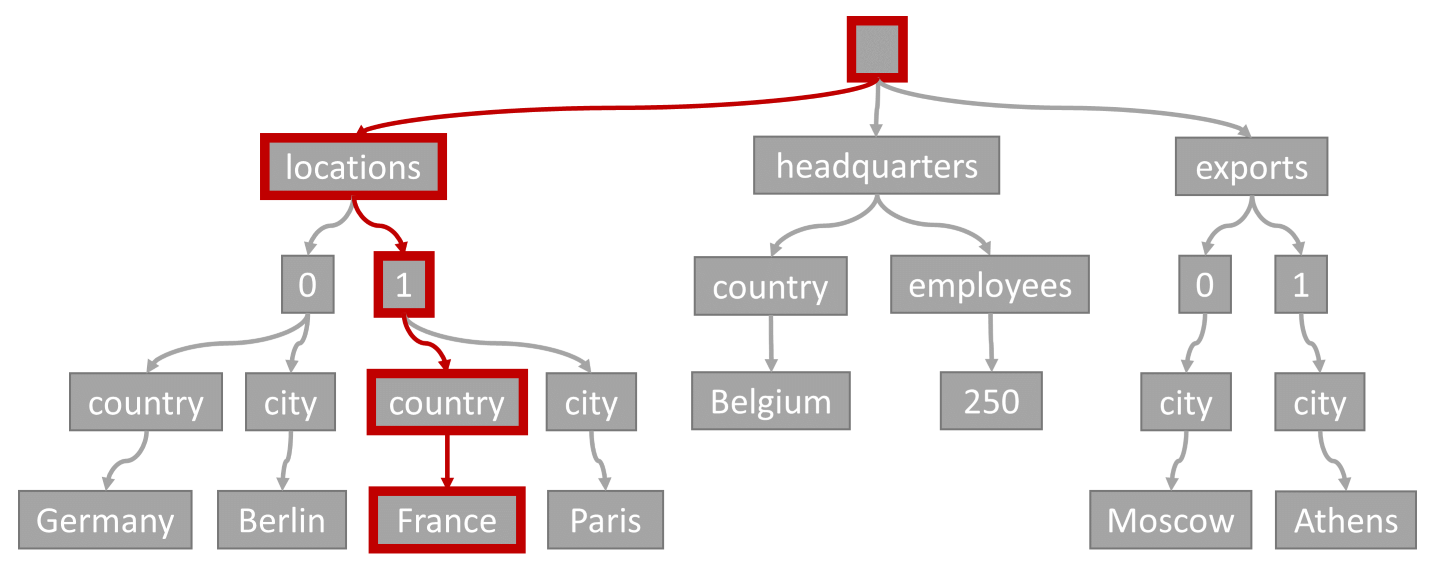
Vzhledem k tomu, že tento dotaz má filtr rovnosti, můžeme po procházení tohoto stromu rychle identifikovat indexové stránky, které obsahují výsledky dotazu. V tomto případě by dotazovací modul četl indexové stránky, které obsahují položku 1. Hledání indexu je nejúčinnější způsob použití indexu. Při hledání indexu čteme pouze potřebné indexové stránky a načítáme pouze položky ve výsledcích dotazu. Proto je doba vyhledávání indexu a poplatky za RU z vyhledávání indexu neuvěřitelně nízké bez ohledu na celkový objem dat.
Přesná kontrola indexu
Představte si následující dotaz:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
Predikát dotazu (filtrování položek, u kterých je více než 200 zaměstnanců), je možné vyhodnotit přesným prohledáváním indexu headquarters/employees cesty. Když provádíte přesnou kontrolu indexu, dotazovací modul začne binárním vyhledáváním odlišné sady možných hodnot a vyhledá umístění hodnoty 200 headquarters/employees cesty. Vzhledem k tomu, že hodnoty pro každou cestu jsou seřazené vzestupně, je snadné, aby dotazovací modul udělal binární vyhledávání. Jakmile dotazovací modul najde hodnotu 200, začne číst všechny zbývající indexové stránky (ve vzestupném směru).
Vzhledem k tomu, že dotazovací modul může provádět binární vyhledávání, aby se zabránilo prohledávání nepotřebných indexových stránek, mají přesné prohledávání indexů tendenci mít srovnatelnou latenci a poplatky za RU pro operace vyhledávání indexů.
Rozšířené prohledávání indexu
Představte si následující dotaz:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
Predikát dotazu (filtrování položek, které mají centrálu v umístění, které začínají nerozlišujícími malá a velká písmena "United") lze vyhodnotit pomocí rozšířené kontroly indexu headquarters/country cesty. Operace, které provádějí rozšířené prohledávání indexů, mají optimalizace, které vám můžou pomoct vyhnout se prohledávání každé stránky indexu, ale jsou o něco dražší než přesné prohledávání binárního vyhledávání indexu.
Například při vyhodnocování nerozlišující malá StartsWitha velká písmena dotazovací modul zkontroluje index pro různé možné kombinace velkých a malých písmen. Tato optimalizace umožňuje dotazovacímu stroji zabránit čtení většiny indexových stránek. Různé systémové funkce mají různé optimalizace, které můžou použít, aby se zabránilo čtení každé indexové stránky, takže jsou široce kategorizovány jako rozšířené prohledávání indexu.
Úplná kontrola indexu
Představte si následující dotaz:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Predikát dotazu (filtrování položek, které mají ústředí v umístění, které obsahuje "United") je možné vyhodnotit pomocí prohledávání cesty indexem headquarters/country . Na rozdíl od přesného prohledávání indexu prohledává úplná kontrola indexu vždy odlišnou sadu možných hodnot, aby identifikovala stránky indexu, ve kterých jsou výsledky. V tomto případě Contains se spustí na indexu. Doba vyhledávání indexu a poplatky za RU pro vyhledávání indexů se s rostoucí kardinalitou cesty zvyšují. Jinými slovy, čím více možných jedinečných hodnot musí dotazovací modul prohledávat, tím vyšší je latence a poplatky za RU spojené s prováděním úplné kontroly indexu.
Představte si například dvě vlastnosti: town a country. Kardinalita města je 5 000 a kardinalita country je 200. Tady jsou dva příklady dotazů, které mají každou systémovou funkci Obsahuje , která provede úplnou kontrolu indexu vlastnosti town . První dotaz používá více RU než druhý dotaz, protože kardinalita města je vyšší než country.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
Úplná kontrola
V některých případech nemusí dotazovací modul pomocí indexu vyhodnotit filtr dotazu. V tomto případě musí dotazovací modul načíst všechny položky z transakčního úložiště, aby se vyhodnotil filtr dotazu. Úplné kontroly nepoužívají index a mají poplatky za RU, které se lineárně zvyšují s celkovou velikostí dat. Operace vyžadující úplné kontroly jsou naštěstí vzácné.
Vektorové vyhledávací dotazy bez definovaného vektorového indexu
Pokud nedefinujete zásadu vektorového indexu VectorDistance a použijete systémovou ORDER BY funkci v klauzuli, výsledkem bude úplná kontrola a vyšší poplatek za RU, než když jste definovali zásadu indexu vektoru. Podobnost, pokud použijete VectorDistance s logickou hodnotou hrubou silou nastavenou na truehodnotu , a nemáte flat index definovaný pro vektorovou cestu, dojde k úplné kontrole.
Dotazy s komplexními výrazy filtru
V předchozích příkladech jsme považovali pouze dotazy, které obsahovaly jednoduché výrazy filtru (například dotazy s pouze jedním filtrem rovnosti nebo rozsahu). Ve skutečnosti má většina dotazů mnohem složitější výrazy filtru.
Představte si následující dotaz:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
Chcete-li tento dotaz spustit, musí dotazovací modul provést vyhledávání headquarters/employees indexu a úplné prohledávání indexu .headquarters/country Dotazovací modul má interní heuristiku, kterou používá k co nejefektivnějšímu vyhodnocení výrazu filtru dotazu. V takovém případě by dotazovací modul nemusel číst nepotřebné indexové stránky tím, že nejprve hledá index. Pokud by například filtr rovnosti odpovídal pouze 50 položek, dotazovací modul by se měl vyhodnotit Contains jenom na stránkách indexu, které obsahovaly tyto 50 položek. Úplná kontrola indexu celého kontejneru by nebyla nutná.
Využití indexu pro skalární agregační funkce
Dotazy s agregačními funkcemi musí záviset výhradně na indexu, aby je bylo možné použít.
V některých případech může index vrátit falešně pozitivní výsledky. Například při vyhodnocování Contains indexu může počet shod v indexu překročit počet výsledků dotazu. Dotazovací modul načte všechny shody indexů, vyhodnotí filtr načtených položek a vrátí pouze správné výsledky.
U většiny dotazů nemá načítání falešně pozitivních indexů žádný znatelný vliv na využití indexu.
Zvažte například následující dotaz:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Contains Systémová funkce může vrátit některé falešně pozitivní shody, takže dotazovací modul musí ověřit, jestli každá načtená položka odpovídá výrazu filtru. V tomto příkladu může dotazovací modul načíst jenom několik dalších položek, takže vliv na využití indexu a poplatky ZA RU je minimální.
Dotazy s agregačními funkcemi se ale musí spoléhat výhradně na index, aby je bylo možné použít. Představte si například následující dotaz s agregací Count :
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Stejně jako v prvním příkladu Contains může systémová funkce vrátit některé falešně pozitivní shody. SELECT * Na rozdíl od dotazu ale Count dotaz nemůže vyhodnotit výraz filtru u načtených položek, aby ověřil všechny shody indexu. Dotaz Count se musí spoléhat výhradně na index, takže pokud existuje šance, že výraz filtru vrátí falešně pozitivní shody, dotazovací modul se uchýlí k úplnému prohledávání.
Dotazy s následujícími agregačními funkcemi musí záviset výhradně na indexu, takže vyhodnocení některých systémových funkcí vyžaduje úplnou kontrolu.
Další kroky
Další informace o indexování najdete v následujících článcích: