Co je analytické úložiště Azure Cosmos DB?
PLATÍ PRO: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Skřítek
Skřítek
Důležité
Zrcadlení služby Azure Cosmos DB v Microsoft Fabric je nyní k dispozici pro rozhraní API NoSql. Tato funkce poskytuje všechny možnosti Azure Synapse Linku s lepším analytickým výkonem, schopnost sjednotit svá datová aktiva s Fabric OneLake a otevřít přístup k datům ve formátu Delta Parquet. Pokud uvažujete o Azure Synapse Linku, doporučujeme vyzkoušet zrcadlení, abyste posoudili celkové přizpůsobení vaší organizace. Začněte se zrcadlováním v Microsoft Fabricu.
Pokud chcete začít s Azure Synapse Linkem, přejděte na stránku Začínáme s Azure Synapse Linkem.
Analytické úložiště Azure Cosmos DB je plně izolované úložiště sloupců pro povolení rozsáhlých analýz s provozními daty ve službě Azure Cosmos DB bez jakéhokoli dopadu na transakční úlohy.
Transakční úložiště služby Azure Cosmos DB je nezávislé na schématu a umožňuje iterovat transakční aplikace bez nutnosti zabývat se správou schématu nebo indexu. Na rozdíl od toho je analytické úložiště Azure Cosmos DB schematizované tak, aby optimalizovalo výkon analytických dotazů. Tento článek popisuje podrobné informace o analytickém úložišti.
Problémy s rozsáhlými analýzami provozních dat
Provozní data s více modely v kontejneru Azure Cosmos DB jsou interně uložená v indexovaném úložišti transakčních transakcí založených na řádcích. Formát úložiště řádků je navržený tak, aby umožňoval rychlé transakční čtení a zápisy v době odezvy v řádu milisekund a provozních dotazů. Pokud vaše datová sada roste, složité analytické dotazy můžou být nákladné z hlediska zřízené propustnosti dat uložených v tomto formátu. Vysoká spotřeba zřízené propustnosti má vliv na výkon transakčních úloh používaných vašimi aplikacemi a službami v reálném čase.
Při analýze velkých objemů dat se provozní data tradičně extrahují z transakčního úložiště služby Azure Cosmos DB a ukládají se do samostatné datové vrstvy. Například data jsou uložená v datovém skladu nebo datovém jezeře v vhodném formátu. Tato data se později používají pro rozsáhlé analýzy a analyzované pomocí výpočetních modulů, jako jsou clustery Apache Spark. Oddělení analýzy od provozních dat vede ke zpoždění analytikům, kteří chtějí použít nejnovější data.
Kanály ETL se také stávají složitými při zpracování aktualizací provozních dat ve srovnání s nově přijatými provozními daty.
Analytické úložiště orientované na sloupce
Analytické úložiště Azure Cosmos DB řeší problémy se složitostí a latencí, ke kterým dochází u tradičních kanálů ETL. Analytické úložiště Azure Cosmos DB může automaticky synchronizovat provozní data do samostatného úložiště sloupců. Formát úložiště sloupců je vhodný pro rozsáhlé analytické dotazy, které se mají provádět optimalizovaným způsobem, což vede ke zlepšení latence těchto dotazů.
Pomocí Azure Synapse Linku teď můžete vytvářet řešení HTAP no-ETL tak, že přímo propojíte analytické úložiště Azure Cosmos DB ze služby Azure Synapse Analytics. Umožňuje spouštět téměř v reálném čase rozsáhlé analýzy vašich provozních dat.
Funkce analytického úložiště
Když povolíte analytické úložiště v kontejneru Azure Cosmos DB, vytvoří se nové úložiště sloupců interně na základě provozních dat ve vašem kontejneru. Toto úložiště sloupců se uchovává odděleně od transakčního úložiště orientovaného na řádky pro daný kontejner v účtu úložiště, který je plně spravovaný službou Azure Cosmos DB v interním předplatném. Zákazníci nemusí trávit čas správou úložiště. Vložení, aktualizace a odstranění vašich provozních dat se automaticky synchronizují s analytickým úložištěm. K synchronizaci dat nepotřebujete kanál změn ani ETL.
Úložiště sloupců pro analytické úlohy v provozních datech
Analytické úlohy obvykle zahrnují agregace a sekvenční kontroly vybraných polí. Analytické úložiště dat je uloženo v hlavním pořadí sloupců, což umožňuje serializovat hodnoty jednotlivých polí, pokud je to možné. Tento formát snižuje počet vstupně-výstupních operací za sekundu potřebných ke kontrole nebo výpočtu statistiky v konkrétních polích. Výrazně vylepšuje dobu odezvy dotazů pro prohledávání velkých datových sad.
Pokud jsou například provozní tabulky v následujícím formátu:
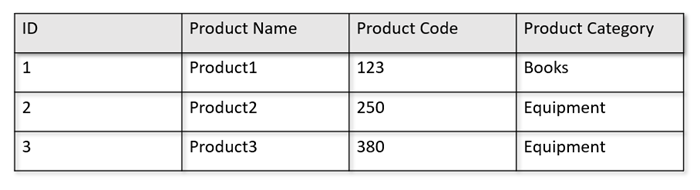
Úložiště řádků uchovává výše uvedená data v serializovaném formátu na každý řádek na disku. Tento formát umožňuje rychlejší transakční čtení, zápisy a provozní dotazy, například "Vrácení informací o produktu 1". S tím, jak se datová sada rozrůstá a chcete na datech spouštět složité analytické dotazy, může být nákladná. Pokud například chcete získat "prodejní trendy pro produkt v kategorii "Vybavení" v různých organizačních jednotkách a měsících, musíte spustit složitý dotaz. Rozsáhlé kontroly této datové sady můžou být nákladné z hlediska zřízené propustnosti a můžou také ovlivnit výkon transakčních úloh, které můžou power vaše aplikace a služby v reálném čase.
Analytické úložiště, což je úložiště sloupců, je vhodnější pro takové dotazy, protože serializuje podobná pole dat dohromady a snižuje počet IOPS disku.
Následující obrázek znázorňuje úložiště transakčních řádků a úložiště analytických sloupců ve službě Azure Cosmos DB:
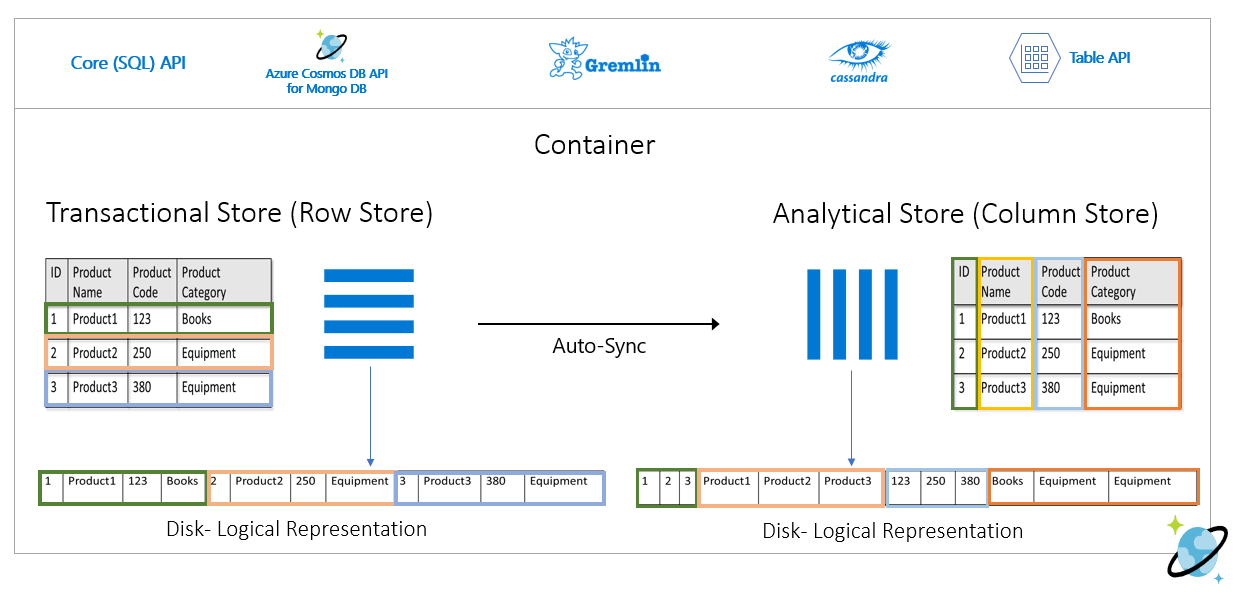
Oddělený výkon analytických úloh
Vzhledem k analytickým dotazům není žádný vliv na výkon transakčních úloh, protože analytické úložiště je oddělené od transakčního úložiště. Analytické úložiště nevyžaduje přidělení samostatných jednotek žádostí (RU).
Automatická synchronizace
Automatická synchronizace odkazuje na plně spravovanou funkci služby Azure Cosmos DB, kde se vkládání, aktualizace, odstranění do provozních dat automaticky synchronizují z transakčního úložiště do analytického úložiště téměř v reálném čase. Latence automatické synchronizace je obvykle do 2 minut. V případě databáze se sdílenou propustností s velkým počtem kontejnerů může být latence automatické synchronizace jednotlivých kontejnerů vyšší a trvat až 5 minut.
Na konci každého spuštění procesu automatické synchronizace budou vaše transakční data okamžitě dostupná pro moduly runtime Azure Synapse Analytics:
Fondy Spark služby Azure Synapse Analytics můžou číst všechna data, včetně nejnovějších aktualizací, prostřednictvím tabulek Sparku, které se aktualizují automaticky, nebo prostřednictvím
spark.readpříkazu, které vždy čtou poslední stav dat.Bezserverové fondy AZURE Synapse Analytics můžou číst všechna data, včetně nejnovějších aktualizací, prostřednictvím zobrazení, která se aktualizují automaticky, nebo prostřednictvím
SELECTpříkazůOPENROWSET, které vždy čte nejnovější stav dat.
Poznámka:
Transakční data se budou synchronizovat do analytického úložiště, i když je hodnota TTL (Transactional Time to Live) menší než 2 minuty.
Poznámka:
Upozorňujeme, že pokud kontejner odstraníte, odstraní se také analytické úložiště.
Škálovatelnost a elasticita
Transakční úložiště Azure Cosmos DB využívá horizontální dělení k elastickému škálování úložiště a propustnosti bez jakýchkoli výpadků. Horizontální dělení v transakčním úložišti poskytuje škálovatelnost a elasticitu v automatické synchronizaci, aby se zajistila synchronizace dat s analytickým úložištěm téměř v reálném čase. K synchronizaci dat dochází bez ohledu na propustnost transakčního provozu, ať už se jedná o 1000 operací za sekundu nebo 1 milion operací za sekundu a nemá vliv na zřízenou propustnost v transakčním úložišti.
Automatické zpracování aktualizací schématu
Transakční úložiště služby Azure Cosmos DB je nezávislé na schématu a umožňuje iterovat transakční aplikace bez nutnosti zabývat se správou schématu nebo indexu. Na rozdíl od toho je analytické úložiště Azure Cosmos DB schematizované tak, aby optimalizovalo výkon analytických dotazů. Díky funkci automatické synchronizace spravuje Služba Azure Cosmos DB odvozování schématu prostřednictvím nejnovějších aktualizací z transakčního úložiště. Spravuje také reprezentaci schématu v analytickém úložišti předem, což zahrnuje zpracování vnořených datových typů.
Jak se vaše schéma vyvíjí a v průběhu času se přidají nové vlastnosti, analytické úložiště automaticky zobrazí sjednocované schéma napříč všemi historickými schématy v transakčním úložišti.
Poznámka:
V kontextu analytického úložiště považujeme za vlastnost následující struktury:
- Json "elements" nebo "string-value pairs separate by a
:". - Objekty JSON, oddělené znakem
{a}. - Pole JSON, oddělená znakem
[a].
Omezení schématu
Následující omezení platí pro provozní data ve službě Azure Cosmos DB, pokud povolíte automatické odvození analytického úložiště a správné znázornění schématu:
Ve schématu dokumentu můžete mít maximálně 1 000 vlastností ve všech vnořených úrovních a maximální hloubku vnoření 127.
- V analytickém úložišti jsou reprezentovány pouze prvních 1 000 vlastností.
- V analytickém úložišti jsou reprezentovány pouze prvních 127 vnořených úrovní.
- První úroveň dokumentu JSON je její
/kořenová úroveň. - Vlastnosti na první úrovni dokumentu budou reprezentovány jako sloupce.
Ukázkové scénáře:
- Pokud má první úroveň dokumentu 2000 vlastností, proces synchronizace bude představovat prvních 1 000 z nich.
- Pokud vaše dokumenty mají v každé z nich pět úrovní s 200 vlastnostmi, bude proces synchronizace představovat všechny vlastnosti.
- Pokud vaše dokumenty mají 10 úrovní s 400 vlastnostmi v každém z nich, proces synchronizace bude plně představovat dvě první úrovně a pouze polovinu třetí úrovně.
Hypotetický dokument níže obsahuje čtyři vlastnosti a tři úrovně.
- Úrovně jsou
root,myArraya vnořená struktura uvnitřmyArray. - Vlastnosti jsou
id,myArray,myArray.nested1amyArray.nested2. - Reprezentace analytického úložiště bude mít dva sloupce,
idamyArray. Pomocí funkcí Spark nebo T-SQL můžete také vystavit vnořené struktury jako sloupce.
- Úrovně jsou
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
Zatímco dokumenty JSON (a kolekce/kontejnery Azure Cosmos DB) rozlišují malá a velká písmena z hlediska jedinečnosti, analytické úložiště není.
- Ve stejném dokumentu: Názvy vlastností na stejné úrovni by měly být v porovnání bez rozlišování velkých a malých písmen jedinečné. Například následující dokument JSON má na stejné úrovni název a název. I když se jedná o platný dokument JSON, nevyhovuje omezení jedinečnosti, a proto nebude plně reprezentován v analytickém úložišti. V tomto příkladu jsou "Name" a "name" stejné při porovnání bez rozlišování malých a velkých písmen. V analytickém úložišti bude reprezentována pouze
"Name": "fred"proto, že se jedná o první výskyt. A"name": "john"nebude vůbec reprezentován.
{"id": 1, "Name": "fred", "name": "john"}- V různých dokumentech: Vlastnosti na stejné úrovni a se stejným názvem, ale v různých případech budou reprezentovány ve stejném sloupci pomocí formátu názvu prvního výskytu. Například následující dokumenty JSON mají
"Name"a"name"mají stejnou úroveň. Vzhledem k tomu, že první formát dokumentu je"Name", toto je to, co se použije k reprezentaci názvu vlastnosti v analytickém úložišti. Jinými slovy, název sloupce v analytickém úložišti bude"Name". Obě"fred"a"john"budou reprezentovány ve sloupci"Name".
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}- Ve stejném dokumentu: Názvy vlastností na stejné úrovni by měly být v porovnání bez rozlišování velkých a malých písmen jedinečné. Například následující dokument JSON má na stejné úrovni název a název. I když se jedná o platný dokument JSON, nevyhovuje omezení jedinečnosti, a proto nebude plně reprezentován v analytickém úložišti. V tomto příkladu jsou "Name" a "name" stejné při porovnání bez rozlišování malých a velkých písmen. V analytickém úložišti bude reprezentována pouze
První dokument kolekce definuje počáteční schéma analytického úložiště.
- Dokumenty s více vlastnostmi, než je počáteční schéma, vygenerují nové sloupce v analytickém úložišti.
- Sloupce nelze odebrat.
- Odstranění všech dokumentů v kolekci neobnovuje schéma analytického úložiště.
- Neexistuje správa verzí schématu. Poslední verze odvozená z transakčního úložiště je to, co uvidíte v analytickém úložišti.
Azure Synapse Spark v současné době nemůže číst vlastnosti, které obsahují některé speciální znaky v jejich názvech, které jsou uvedené níže. Bezserverová služba Azure Synapse SQL není ovlivněná.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
Poznámka:
Prázdné znaky jsou uvedené také v chybové zprávě Sparku, která se vrátí, když dosáhnete tohoto omezení. Přidali jsme ale speciální ošetření prázdných znaků, podívejte se prosím na další podrobnosti v následujících položkách.
- Pokud máte názvy vlastností používající výše uvedené znaky, alternativy jsou:
- Změňte datový model předem, abyste se těmto znakům vyhnuli.
- Vzhledem k tomu, že v současné době nepodporujeme resetování schématu, můžete aplikaci změnit tak, aby přidala redundantní vlastnost s podobným názvem, abyste se těmto znakům vyhnuli.
- Pomocí kanálu změn můžete vytvořit materializované zobrazení kontejneru bez těchto znaků v názvech vlastností.
dropColumnPomocí možnosti Spark můžete ignorovat ovlivněné sloupce a načíst všechny ostatní sloupce do datového rámce. Syntaxe je:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Azure Synapse Spark teď podporuje vlastnosti s prázdnými znaky v jejich názvech. K načtení ovlivněných sloupců do datového rámce je potřeba použít
allowWhiteSpaceInFieldNamesmožnost Sparku a zachovat původní název. Syntaxe je:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
Následující datové typy BSON nejsou podporovány a nebudou reprezentovány v analytickém úložišti:
- Desetinné číslo 128
- Regulární výraz
- Ukazatel databáze
- JavaScript
- Symbol
- MinKey/MaxKey
Při použití řetězců DateTime, které následují standard ISO 8601 UTC, můžete očekávat následující chování:
- Fondy Sparku ve službě Azure Synapse představují tyto sloupce jako
string. - Bezserverové fondy SQL v Azure Synapse představují tyto sloupce jako
varchar(8000).
- Fondy Sparku ve službě Azure Synapse představují tyto sloupce jako
Vlastnosti s
UNIQUEIDENTIFIER (guid)typy jsou reprezentovány jakostringv analytickém úložišti a měly by být převedeny naVARCHARv SQL nebostringve Sparku pro správnou vizualizaci.Bezserverové fondy SQL ve službě Azure Synapse podporují sady výsledků s až 1 000 sloupci a zveřejnění vnořených sloupců se také počítá do tohoto limitu. Je vhodné zvážit tyto informace v architektuře a modelování transakčních dat.
Pokud vlastnost přejmenujete v jednom nebo mnoha dokumentech, bude považována za nový sloupec. Pokud spustíte stejné přejmenování ve všech dokumentech v kolekci, budou všechna data migrována do nového sloupce a starý sloupec bude reprezentován hodnotami
NULL.
Reprezentace schématu
V analytickém úložišti existují dvě metody reprezentace schématu, platné pro všechny kontejnery v databázovém účtu. Mají kompromisy mezi jednoduchostí prostředí dotazů a pohodlím inkluzivnější sloupcové reprezentace pro polymorfní schémata.
- Dobře definovaná reprezentace schématu, výchozí možnost pro účty API pro NoSQL a Gremlin.
- Reprezentace schématu s plnou věrností, výchozí možnost pro účty API pro MongoDB
Dobře definovaná reprezentace schématu
Dobře definovaná reprezentace schématu vytvoří jednoduchou tabulkovou reprezentaci dat, která jsou nezávislá na schématu v transakčním úložišti. Dobře definovaná reprezentace schématu má následující aspekty:
- První dokument definuje základní schéma a vlastnosti musí mít vždy stejný typ ve všech dokumentech. Jedinými výjimkami jsou:
- Z
NULLlibovolného jiného datového typu. První výskyt, který není null, definuje datový typ sloupce. Žádný dokument, který nesleduje první datový typ, který není null, nebude v analytickém úložišti reprezentován. - Od
floatdointeger. Všechny dokumenty jsou reprezentovány v analytickém úložišti. - Od
integerdofloat. Všechny dokumenty jsou reprezentovány v analytickém úložišti. Pokud ale chcete číst tato data pomocí bezserverových fondů Azure Synapse SQL, musíte použít klauzuli WITH k převodu sloupce navarchar. A po tomto počátečním převodu je možné ho znovu převést na číslo. Zkontrolujte následující příklad, kde počáteční hodnota čísla byla celé číslo a druhá hodnota byla plovoucí.
- Z
SELECT CAST (num as float) as num
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
)
WITH (num varchar(100)) AS [IntToFloat]
Vlastnosti, které nedodržují datový typ základního schématu, nebudou reprezentovány v analytickém úložišti. Představte si například následující dokumenty: první definoval základní schéma analytického úložiště. Druhý dokument, kde je , nemá dobře definované schéma, protože vlastnost
"code"je řetězec a první dokument má"code"jako číslo."2"idV tomto případě analytické úložiště zaregistruje datový typ"code"kontejneru pointegercelou dobu života. Druhý dokument bude stále součástí analytického úložiště, ale jeho"code"vlastnost nebude.{"id": "1", "code":123}{"id": "2", "code": "123"}
Poznámka:
Výše uvedená podmínka se nevztahuje na NULL vlastnosti. Například {"a":123} and {"a":NULL} je stále dobře definovaný.
Poznámka:
Výše uvedená podmínka se nezmění, pokud aktualizujete "code" dokument "1" na řetězec v transakčním úložišti. V analytickém úložišti se zachová, "code" protože integer v současné době nepodporujeme resetování schématu.
- Typy polí musí obsahovat jeden opakovaný typ. Například není dobře definované schéma,
{"a": ["str",12]}protože pole obsahuje kombinaci celých čísel a typů řetězců.
Poznámka:
Pokud analytické úložiště Azure Cosmos DB dodržuje jasně definovanou reprezentaci schématu a výše uvedená specifikace je porušena určitými položkami, tyto položky nebudou zahrnuty do analytického úložiště.
Očekáváme různé chování v souvislosti s různými typy v dobře definovaném schématu:
- Fondy Sparku ve službě Azure Synapse představují tyto hodnoty jako
undefined. - Bezserverové fondy SQL v Azure Synapse představují tyto hodnoty jako
NULL.
- Fondy Sparku ve službě Azure Synapse představují tyto hodnoty jako
Očekáváme různé chování v souvislosti s explicitními
NULLhodnotami:- Fondy Sparku ve službě Azure Synapse načtou tyto hodnoty jako
0(nula) aundefinedjakmile sloupec obsahuje nenulovou hodnotu. - Bezserverové fondy SQL ve službě Azure Synapse načtou tyto hodnoty jako
NULL.
- Fondy Sparku ve službě Azure Synapse načtou tyto hodnoty jako
Očekáváme jiné chování v souvislosti s chybějícími sloupci:
- Fondy Sparku ve službě Azure Synapse představují tyto sloupce jako
undefined. - Bezserverové fondy SQL v Azure Synapse představují tyto sloupce jako
NULL.
- Fondy Sparku ve službě Azure Synapse představují tyto sloupce jako
Řešení problémů s reprezentací
Je možné, že se k vytvoření základního schématu analytického úložiště kontejneru použil starý dokument s nesprávným schématem. Na základě všech výše uvedených pravidel můžete při dotazování analytického úložiště pomocí Azure Synapse Linku přijímat NULL určité vlastnosti. Odstranění nebo aktualizace problematických dokumentů nepomůže, protože základní resetování schématu se v současné době nepodporuje. Mezi možná řešení patří:
- Pokud chcete migrovat data do nového kontejneru, ujistěte se, že všechny dokumenty mají správné schéma.
- Pokud chcete opustit vlastnost s nesprávným schématem a přidat nový s jiným názvem, který má ve všech dokumentech správné schéma. Příklad: V kontejneru Orders máte miliardy dokumentů, kde je vlastnost statusu řetězec. První dokument v kontejneru má ale definovaný stav s celočíselnou sadou. Takže jeden dokument bude mít správně reprezentovaný stav a všechny ostatní dokumenty budou mít
NULL. Vlastnost status2 můžete přidat do všech dokumentů a začít ji používat místo původní vlastnosti.
Reprezentace schématu s plnou věrností
Reprezentace schématu s plnou věrností je navržená tak, aby zpracovávala celý rozsah polymorfních schémat v provozních datech, která jsou nezávislá na schématu. V této reprezentaci schématu nejsou z analytického úložiště vynechány žádné položky, a to ani v případě, že jsou porušena dobře definovaná omezení schématu (nejedná se o pole smíšených datových typů ani pole smíšených datových typů).
Toho dosáhnete tak, že přeložíte vlastnosti typu list operačních dat do analytického úložiště jako dvojice JSON key-value , kde datový typ je datový key typ a obsah vlastnosti je value. Tato reprezentace objektů JSON umožňuje dotazy bez nejednoznačnosti a každý datový typ můžete analyzovat jednotlivě.
Jinými slovy, v reprezentaci schématu úplné věrnosti každý datový typ každé vlastnosti každého dokumentu vygeneruje dvojici v objektu JSON pro danou key-valuevlastnost. Každý z nich se počítá jako jeden z 1 000 maximálních limitů vlastností.
Podívejme se například na následující ukázkový dokument v transakčním úložišti:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
Vnořený objekt address je vlastnost v kořenové úrovni dokumentu a bude reprezentována jako sloupec. Každá vlastnost typu list v objektu address bude reprezentována jako objekt JSON: {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}.
Na rozdíl od dobře definované reprezentace schématu umožňuje metoda úplné věrnosti varianty datových typů. Pokud další dokument v této kolekci výše uvedeného příkladu má streetNo jako řetězec, bude reprezentován v analytickém úložišti jako "streetNo":{"string":15850}. V dobře definované metodě schématu by nebyla reprezentována.
Mapa datových typů pro schéma s plnou věrností
Tady je mapa datových typů MongoDB a jejich reprezentace v analytickém úložišti v plné věrnosti reprezentace schématu. Následující mapa není platná pro účty rozhraní API NoSQL.
| Původní datový typ | Přípona | Příklad |
|---|---|---|
| Hodnota s dvojitou přesností | ".float64" | 24.99 |
| Pole | ".array" | ["a", "b"] |
| Binární | ".binary" | 0 |
| Logická hodnota | ".bool" | True |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NULL | ". NULL" | NULL |
| String | ".string" | "ABC" |
| Časové razítko | ".timestamp" | Časové razítko(0, 0) |
| ObjectId | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| Dokument | ".object" | {"a": "a"} |
Očekáváme různé chování v souvislosti s explicitními
NULLhodnotami:- Fondy Sparku ve službě Azure Synapse tyto hodnoty načtou jako
0(nula). - Bezserverové fondy SQL ve službě Azure Synapse tyto hodnoty načtou jako
NULL.
- Fondy Sparku ve službě Azure Synapse tyto hodnoty načtou jako
Očekáváme jiné chování v souvislosti s chybějícími sloupci:
- Fondy Sparku ve službě Azure Synapse budou tyto sloupce reprezentovat jako
undefined. - Bezserverové fondy SQL v Azure Synapse budou tyto sloupce představovat jako
NULL.
- Fondy Sparku ve službě Azure Synapse budou tyto sloupce reprezentovat jako
Očekáváme různé chování v souvislosti s
timestamphodnotami:- Fondy Sparku ve službě Azure Synapse tyto hodnoty načtou jako
TimestampType,DateTypeneboFloat. Závisí na rozsahu a způsobu generování časového razítka. - Bezserverové fondy SQL ve službě Azure Synapse tyto hodnoty načtou v
DATETIME2rozsahu od0001-01-01.9999-12-31Hodnoty nad rámec tohoto rozsahu nejsou podporovány a způsobí selhání spuštění vašich dotazů. Pokud se jedná o váš případ, můžete:- Odeberte sloupec z dotazu. Chcete-li zachovat reprezentaci, můžete vytvořit nové zrcadlení vlastností v daném sloupci, ale v podporovaném rozsahu. A použijte ho ve svých dotazech.
- Pomocí funkce Change Data Capture z analytického úložiště bez nákladů na RU můžete data transformovat a načíst do nového formátu v rámci některého z podporovaných jímek.
- Fondy Sparku ve službě Azure Synapse tyto hodnoty načtou jako
Použití schématu úplné věrnosti se Sparkem
Spark bude spravovat každý datový typ jako sloupec při načítání do objektu DataFrame. Předpokládejme kolekci s následujícími dokumenty.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
Zatímco první dokument má rating číslo a timestamp ve formátu UTC, druhý dokument má rating a timestamp jako řetězce. Za předpokladu, že se tato kolekce načetla DataFrame bez jakékoli transformace dat, je výstupem df.printSchema() :
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
V dobře definované reprezentaci schématu by nebyl reprezentován ani rating timestamp druhý dokument. Ve schématu úplné věrnosti můžete použít následující příklady k individuálnímu přístupu ke každé hodnotě každého datového typu.
V následujícím příkladu můžeme použít PySpark ke spuštění agregace:
df.groupBy(df.item.string).sum().show()
V následujícím příkladu můžeme použít PySQL ke spuštění jiné agregace:
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
Použití schématu s plnou věrností s SQL
Následující příklad syntaxe můžete použít se stejnými dokumenty jako v příkladu Sparku výše:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
Transformace můžete implementovat pomocí castconvert jakékoli jiné funkce T-SQL pro manipulaci s daty. Pomocí zobrazení můžete také skrýt složité struktury datových typů.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
Práce s polem MongoDB _id
Pole MongoDB _id je zásadní pro každou kolekci v MongoDB a původně má šestnáctkové vyjádření. Jak vidíte v tabulce výše, schéma úplné věrnosti zachová jeho charakteristiky a vytvoří výzvu pro vizualizaci ve službě Azure Synapse Analytics. Pro správnou vizualizaci musíte datový typ převést _id následujícím způsobem:
Práce s polem MongoDB _id ve Sparku
Následující příklad funguje ve verzích Spark 2.x a 3.x:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
Práce s polem MongoDB _id v SQL
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
HTAP) WITH (_id VARCHAR(1000)) as HTAP
Práce s polem MongoDB id
Vlastnost id v kontejnerech MongoDB je automaticky přepsána reprezentací base64 vlastnosti "_id" v analytickém úložišti. Pole "ID" je určeno pro interní použití aplikacemi MongoDB. Jediným alternativním řešením je přejmenovat vlastnost ID na jinou vlastnost než ID.
Schéma úplné věrnosti pro účty API pro NoSQL nebo Gremlin
Pro účty API pro NoSQL je možné místo výchozí možnosti použít úplné schéma přesnosti, a to nastavením typu schématu při prvním povolení Synapse Linku v účtu služby Azure Cosmos DB. Tady jsou důležité informace o změně výchozího typu reprezentace schématu:
- Pokud v současné době povolíte Synapse Link ve svém účtu rozhraní NoSQL API pomocí webu Azure Portal, povolí se také definované schéma.
- Pokud chcete v současné době používat schéma úplné věrnosti s účty NoSQL nebo Gremlin API, musíte ho nastavit na úrovni účtu ve stejném rozhraní příkazového řádku nebo powershellovém příkazu, který umožní Synapse Link na úrovni účtu.
- Azure Cosmos DB pro MongoDB v současné době není kompatibilní s touto možností změny reprezentace schématu. Všechny účty MongoDB mají úplný typ reprezentace schématu.
- Mapování datových typů schématu Full Fidelity uvedené výše není platné pro účty rozhraní API NoSQL, které používají datové typy JSON. Například hodnoty
integerjsou reprezentovány jakonumv analytickémfloatúložišti. - Typ reprezentace schématu není možné resetovat z dobře definované na úplnou věrnost nebo naopak.
- V současné době jsou schémata kontejnerů v analytickém úložišti definována při vytváření kontejneru, i když v databázovém účtu nebyla povolena služba Synapse Link.
- Kontejnery nebo grafy vytvořené před povolením synapse Linku s úplným schématem přesnosti na úrovni účtu budou mít dobře definované schéma.
- Kontejnery nebo grafy vytvořené po povolení synapse Linku s úplným schématem přesnosti na úrovni účtu budou mít úplné schéma věrnosti.
Rozhodnutí o typu reprezentace schématu musí být provedeno současně s povoleným Synapse Linkem v účtu pomocí Azure CLI nebo PowerShellu.
Pomocí Azure CLI:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Poznámka:
Ve výše uvedeném příkazu nahraďte create stávajícími update účty.
Pomocí PowerShellu:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Poznámka:
Ve výše uvedeném příkazu nahraďte New-AzCosmosDBAccount stávajícími Update-AzCosmosDBAccount účty.
Hodnota TTL (Analytical Time to Live)
Hodnota TTL (ATTL) značí, jak dlouho se mají uchovávat data v analytickém úložišti pro kontejner.
Analytické úložiště je povoleno, pokud je hodnota ATTL nastavena s jinou hodnotou než NULL a 0. Pokud je tato možnost povolená, vkládání, aktualizace, odstranění do provozních dat, se automaticky synchronizují z transakčního úložiště do analytického úložiště bez ohledu na konfiguraci hodnoty TTL (Transactional TTTL). Uchovávání těchto transakčních dat v analytickém úložišti lze řídit na úrovni kontejneru vlastností AnalyticalStoreTimeToLiveInSeconds .
Možné konfigurace ATTL jsou:
Pokud je hodnota nastavena na
0: analytické úložiště je zakázané a žádná data se nereplikují z transakčního úložiště do analytického úložiště. Otevřete případ podpory a zakažte analytické úložiště v kontejnerech.Pokud pole vynecháte, nic se nestane a předchozí hodnota se zachová.
Pokud je hodnota nastavena na
-1: analytické úložiště uchovává všechna historická data bez ohledu na uchovávání dat v transakčním úložišti. Toto nastavení označuje, že analytické úložiště má nekonečné uchovávání vašich provozních dat.Pokud je hodnota nastavena na libovolné kladné celé
nčíslo: položky vyprší z analytického úložištěnsekund po jejich poslední změně v transakčním úložišti. Toto nastavení můžete využít, pokud chcete uchovávat provozní data po omezenou dobu v analytickém úložišti bez ohledu na uchovávání dat v transakčním úložišti.
Některé body ke zvážení:
- Po povolení analytického úložiště s hodnotou ATTL je možné ho později aktualizovat na jinou platnou hodnotu.
- Hodnota TTTL je sice možné nastavit na úrovni kontejneru nebo položky, ale hodnotu ATTL je možné nastavit pouze na úrovni kontejneru.
- Delší dobu uchovávání provozních dat v analytickém úložišti můžete dosáhnout nastavením hodnoty ATTL = TTTL >na úrovni kontejneru.
- Analytické úložiště lze provést tak, aby zrcadlilo transakční úložiště nastavením HODNOTY ATTL = TTTL.
- Pokud máte hodnotu ATTL větší než hodnota TTTL, v určitém okamžiku budete mít data, která existují jenom v analytickém úložišti. Tato data jsou jen pro čtení.
- V současné době neodstraňovat žádná data z analytického úložiště. Pokud nastavíte hodnotu ATTL na libovolné kladné celé číslo, nebudou data zahrnutá do vašich dotazů a nebudou se vám účtovat. Pokud ale změníte hodnotu ATTL zpátky na
-1, všechna data se znovu zobrazí, začnou se vám účtovat všechny datové svazky.
Povolení analytického úložiště v kontejneru:
Na webu Azure Portal je při zapnutí nastavená možnost ATTL na výchozí hodnotu -1. Tuto hodnotu můžete změnit na n sekund, a to tak, že přejdete do nastavení kontejneru v Průzkumníku dat.
Ze sady SDK pro správu Azure, sad SDK služby Azure Cosmos DB, PowerShellu nebo Azure CLI je možné povolit možnost ATTL nastavením na hodnotu -1 nebo n sekund.
Další informace najdete v tématu konfigurace hodnoty TTL analytického úložiště v kontejneru.
Nákladově efektivní analýza historických dat
Vrstvení dat odkazuje na oddělení dat mezi infrastrukturami úložiště optimalizovanými pro různé scénáře. Tím se zlepší celkový výkon a nákladová efektivita komplexního datového zásobníku. Díky analytickému úložišti teď Azure Cosmos DB podporuje automatické vrstvení dat z transakčního úložiště do analytického úložiště s různými rozloženími dat. S analytickým úložištěm optimalizovaným z hlediska nákladů na úložiště v porovnání s transakčním úložištěm vám umožní uchovávat mnohem delší horizonty provozních dat pro historickou analýzu.
Po povolení analytického úložiště můžete v závislosti na potřebách uchovávání dat transakčních úloh nakonfigurovat transactional TTL vlastnost tak, aby se záznamy automaticky odstranily z transakčního úložiště po určitém časovém období. analytical TTL Podobně umožňuje spravovat životní cyklus dat uchovávaných v analytickém úložišti nezávisle na transakčním úložišti. Povolením analytického úložiště a konfigurací transakčních a analytických TTL vlastností můžete bezproblémově vrstvit a definovat dobu uchovávání dat pro obě úložiště.
Poznámka:
Pokud analytical TTL je nastavená hodnota větší než transactional TTL hodnota, kontejner bude mít data, která existují pouze v analytickém úložišti. Tato data jsou jen pro čtení a v současné době nepodporujeme úroveň TTL dokumentů v analytickém úložišti. Pokud vaše data kontejneru můžou v budoucnu potřebovat aktualizaci nebo odstranění, nepoužívejte analytical TTL větší než transactional TTL. Tato funkce se doporučuje pro data, která nebudou v budoucnu potřebovat aktualizace nebo odstranění.
Poznámka:
Pokud váš scénář nepožaduje fyzické odstranění, můžete využít logický přístup k odstranění nebo aktualizaci. Vložte do transakčního úložiště jinou verzi stejného dokumentu, který existuje pouze v analytickém úložišti, ale potřebuje logické odstranění nebo aktualizaci. Možná s příznakem označujícím, že se jedná o odstranění nebo aktualizaci dokumentu s vypršenou platností. Obě verze stejného dokumentu budou existovat společně v analytickém úložišti a vaše aplikace by měla zvážit pouze poslední.
Odolnost
Analytické úložiště spoléhá na Službu Azure Storage a nabízí následující ochranu před fyzickým selháním:
- Ve výchozím nastavení přidělují účty databáze Azure Cosmos DB analytické úložiště v účtech místně redundantního úložiště (LRS). LRS poskytuje alespoň 99,9999999999 % (11 devítek) stálost objektů za daný rok.
- Pokud je pro zónovou redundanci nakonfigurovaná nějaká geografická oblast databázového účtu, přiděluje se v účtech zónově redundantního úložiště (ZRS). Musíte povolit Zóny dostupnosti v oblasti účtu databáze Azure Cosmos DB, aby měla analytická data této oblasti uložená v zónově redundantním úložišti. ZRS nabízí odolnost prostředků úložiště nejméně 99,9999999999999 % (12 9) za daný rok.
Další informace o odolnosti služby Azure Storage najdete na tomto odkazu.
Backup
I když analytické úložiště má integrovanou ochranu proti fyzickým selháním, zálohování může být nezbytné pro náhodné odstranění nebo aktualizace v transakčním úložišti. V těchto případech můžete obnovit kontejner a použít obnovený kontejner k obnovení dat v původním kontejneru nebo úplné opětovné sestavení analytického úložiště v případě potřeby.
Poznámka:
V současné době se analytické úložiště nezálohuje, proto ho nejde obnovit. Zásady zálohování se na to nedají naplánovat.
Synapse Link a analytické úložiště v důsledku toho má různé úrovně kompatibility s režimy zálohování služby Azure Cosmos DB:
- Režim pravidelného zálohování je plně kompatibilní se službou Synapse Link a tyto 2 funkce je možné použít ve stejném databázovém účtu.
- Synapse Link pro databázové účty využívající režim průběžného zálohování je obecná dostupnost.
- Režim průběžného zálohování pro účty s podporou Synapse Linku je ve verzi Public Preview. V současné době nemůžete migrovat na průběžné zálohování, pokud jste synapse Link zakázali ve všech kolekcích v účtu služby Cosmos DB.
Zásady zálohování
Existují dvě možné zásady zálohování a pochopit, jak je používat, jsou velmi důležité následující podrobnosti o zálohování azure Cosmos DB:
- Původní kontejner se obnoví bez analytického úložiště v obou režimech zálohování.
- Azure Cosmos DB nepodporuje přepsání kontejnerů z obnovení.
Teď se podíváme, jak používat zálohování a obnovení z hlediska analytického úložiště.
Obnovení kontejneru pomocí hodnoty TTTL >= ATTL
Pokud transactional TTL je rovna nebo větší analytical TTL, všechna data v analytickém úložišti stále existují v transakčním úložišti. V případě obnovení máte dvě možné situace:
- Pokud chcete obnovený kontejner použít jako náhradu za původní kontejner. Pokud chcete znovu sestavit analytické úložiště, stačí povolit Synapse Link na úrovni účtu a na úrovni kontejneru.
- Pokud chcete obnovený kontejner použít jako zdroj dat k obnovení nebo aktualizaci dat v původním kontejneru. V tomto případě analytické úložiště automaticky odráží operace s daty.
Obnovení kontejneru pomocí hodnoty TTTL ATTL <
Pokud transactional TTL je menší než analytical TTL, některá data existují pouze v analytickém úložišti a nebudou v obnoveném kontejneru. Opět máte dvě možné situace:
- Pokud chcete obnovený kontejner použít jako náhradu za původní kontejner. Pokud v tomto případě povolíte Synapse Link na úrovni kontejneru, budou v novém analytickém úložišti zahrnuta pouze data, která byla v transakčním úložišti. Mějte ale na paměti, že analytické úložiště původního kontejneru zůstává dostupné pro dotazy, pokud existuje původní kontejner. Aplikaci můžete chtít změnit tak, aby se dotazovat na obojí.
- Použití obnoveného kontejneru jako zdroje dat k obnovení nebo aktualizaci dat v původním kontejneru:
- Analytické úložiště bude automaticky odrážet datové operace pro data, která jsou v transakčním úložišti.
- Pokud znovu vložíte data, která byla dříve odebrána z transakčního úložiště, budou
transactional TTLtato data duplikována v analytickém úložišti.
Příklad:
- Kontejner
OnlineOrdersmá hodnotu TTTL nastavenou na jeden měsíc a hodnotu ATTL nastavenou na jeden rok. - Když ho
OnlineOrdersNewobnovíte a zapnete pro opětovné sestavení analytického úložiště, bude v transakčním i analytickém úložišti pouze jeden měsíc dat. - Původní kontejner
OnlineOrdersse neodstraní a jeho analytické úložiště je stále dostupné. - Nová data se ingestují pouze do
OnlineOrdersNew. - Analytické dotazy budou provádět sjednocení ALL z analytických úložišť, zatímco původní data jsou stále relevantní.
Pokud chcete odstranit původní kontejner, ale nechcete ztratit data analytického úložiště, můžete zachovat analytické úložiště původního kontejneru v jiné datové službě Azure. Synapse Analytics má možnost provádět spojení mezi daty uloženými v různých umístěních. Příklad: Dotaz Synapse Analytics spojuje data analytického úložiště s externími tabulkami umístěnými ve službě Azure Blob Storage, Azure Data Lake Store atd.
Je důležité si uvědomit, že data v analytickém úložišti mají jiné schéma než to, co v transakčním úložišti existuje. I když můžete vygenerovat snímky dat analytického úložiště a exportovat je do jakékoli datové služby Azure bez nákladů na RU, nemůžeme zaručit použití tohoto snímku k back feedu transakčního úložiště. Tento proces není podporován.
Globální distribuce
Pokud máte globálně distribuovaný účet služby Azure Cosmos DB, bude po povolení analytického úložiště pro kontejner dostupný ve všech oblastech tohoto účtu. Všechny změny provozních dat se globálně replikují ve všech oblastech. Analytické dotazy můžete efektivně spouštět proti nejbližší regionální kopii dat ve službě Azure Cosmos DB.
dělení na části
Dělení analytického úložiště je zcela nezávislé na dělení v transakčním úložišti. Ve výchozím nastavení nejsou data v analytickém úložišti rozdělená na oddíly. Pokud vaše analytické dotazy často používají filtry, máte možnost rozdělit oddíly na základě těchto polí, abyste dosáhli lepšího výkonu dotazů. Další informace najdete v úvodu k vlastnímu dělení a postupu při konfiguraci vlastního dělení.
Zabezpečení
Ověřování s analytickým úložištěm je stejné jako transakční úložiště pro danou databázi.
Izolace sítě pomocí privátních koncových bodů – Můžete řídit síťový přístup k datům v transakčních a analytických úložištích nezávisle. Izolace sítě se provádí pomocí samostatných spravovaných privátních koncových bodů pro každé úložiště ve spravovaných virtuálních sítích v pracovních prostorech Azure Synapse. Další informace najdete v článku o konfiguraci privátních koncových bodů pro analytické úložiště .
Šifrování neaktivních uložených dat – Šifrování analytického úložiště je ve výchozím nastavení povolené.
Šifrování dat pomocí klíčů spravovaných zákazníkem – Data můžete bez problémů šifrovat napříč transakčními a analytickými úložišti pomocí stejných klíčů spravovaných zákazníkem automaticky a transparentně. Azure Synapse Link podporuje pouze konfiguraci klíčů spravovaných zákazníkem pomocí spravované identity účtu služby Azure Cosmos DB. Před povolením služby Azure Synapse Link ve vašem účtu musíte ve svých zásadách přístupu ke službě Azure Key Vault nakonfigurovat spravovanou identitu svého účtu. Další informace najdete v článku o konfiguraci klíčů spravovaných zákazníkem pomocí účtů spravované službou Azure Cosmos DB.
Poznámka:
Pokud změníte účet databáze z první strany na identitu přiřazenou systémem nebo uživatelem a povolíte Azure Synapse Link ve svém databázovém účtu, nebudete se moct vrátit k identitě první strany, protože ve svém databázovém účtu nemůžete zakázat Synapse Link.
Podpora více modulů runtime Azure Synapse Analytics
Analytické úložiště je optimalizované pro zajištění škálovatelnosti, elasticity a výkonu analytických úloh bez jakékoli závislosti na výpočetních časech. Technologie úložiště je samoobslužná pro optimalizaci analytických úloh bez ručního úsilí.
Data v analytickém úložišti Azure Cosmos DB je možné dotazovat současně z různých analytických modulů runtime podporovaných službou Azure Synapse Analytics. Azure Synapse Analytics podporuje Apache Spark a bezserverový fond SQL s analytickým úložištěm Azure Cosmos DB.
Poznámka:
Z analytického úložiště můžete číst pouze pomocí modulů runtime Azure Synapse Analytics. A opak je také pravdivý, moduly runtime Azure Synapse Analytics můžou číst pouze z analytického úložiště. Data v analytickém úložišti může měnit pouze proces automatické synchronizace. Data můžete zapisovat zpět do transakčního úložiště Azure Cosmos DB pomocí fondu Spark služby Azure Synapse Analytics pomocí integrované sady AZURE Cosmos DB OLTP SDK.
Ceny
Analytické úložiště se řídí cenovým modelem založeným na spotřebě, za který se účtují poplatky:
Úložiště: objem dat uchovávaných v analytickém úložišti každý měsíc včetně historických dat definovaných analytickým TTL.
Operace analytického zápisu: plně spravovaná synchronizace aktualizací provozních dat do analytického úložiště z transakčního úložiště (automatická synchronizace)
Operace analytického čtení: Operace čtení prováděné s analytickým úložištěm z fondu Spark Azure Synapse Analytics a doby spuštění bezserverového fondu SQL.
Ceny analytického úložiště jsou oddělené od cenového modelu transakčního úložiště. V analytickém úložišti neexistuje žádný koncept zřízených RU. Úplné podrobnosti o cenovém modelu analytického úložiště najdete na stránce s cenami služby Azure Cosmos DB.
K datům v úložišti analýz se dá přistupovat jenom přes Azure Synapse Link, která se provádí v modulech runtime Azure Synapse Analytics: fondy Azure Synapse Apache Spark a bezserverové fondy SQL Azure Synapse. Úplné podrobnosti o cenovém modelu pro přístup k datům v analytickém úložišti najdete na stránce s cenami služby Azure Synapse Analytics.
Pokud chcete získat odhad nákladů vysoké úrovně, abyste umožnili analytické úložiště v kontejneru Azure Cosmos DB, můžete z hlediska analytického úložiště použít Plánovač kapacity služby Azure Cosmos DB a získat odhad nákladů na analytické úložiště a operace zápisu.
Odhady operací čtení analytického úložiště nejsou zahrnuty do kalkulačky nákladů služby Azure Cosmos DB, protože jsou funkcí vaší analytické úlohy. Při odhadu vysoké úrovně ale prohledávání 1 TB dat v analytickém úložišti obvykle vede k 130 000 operacím analytického čtení a výsledkem jsou náklady na 0,065 USD. Pokud jako příklad použijete bezserverové fondy SQL Azure Synapse k provedení této kontroly 1 TB, bude stát 5,00 USD na stránce s cenami služby Azure Synapse Analytics. Konečné celkové náklady na tuto kontrolu 1 TB by byly 5,065 USD.
I když výše uvedený odhad slouží ke kontrole 1 TB dat v analytickém úložišti, použití filtrů snižuje objem kontrolovaných dat a určuje přesný počet analytických operací čtení vzhledem k cenovému modelu spotřeby. Testování konceptu analytické úlohy by poskytovalo podrobnější odhad operací analytického čtení. Tento odhad nezahrnuje náklady na Azure Synapse Analytics.
Další kroky
Další informace najdete v následujících dokumentech: