Modul pro příjem dat nezávislý na datech
Tento článek vysvětluje, jak můžete implementovat scénáře modulu pro příjem dat, které jsou nezávislé na příjmu dat, a to pomocí kombinace úloh kopírování založených na PowerApps, Azure Logic Apps a metadatech ve službě Azure Data Factory.
Scénáře modulu pro příjem dat nezávislého na typu dat se obvykle zaměřují na to, aby uživatelé, kteří nejsou technickými odborníky (datoví inženýři), publikovali datové prostředky do Data Lake pro další zpracování. Pokud chcete tento scénář implementovat, musíte mít možnosti onboardingu, které umožňují:
- Registrace datového aktiva
- Zachytávání metadat a zřizování pracovních postupů
- Plánování příjmu dat
Uvidíte, jak tyto funkce komunikují:
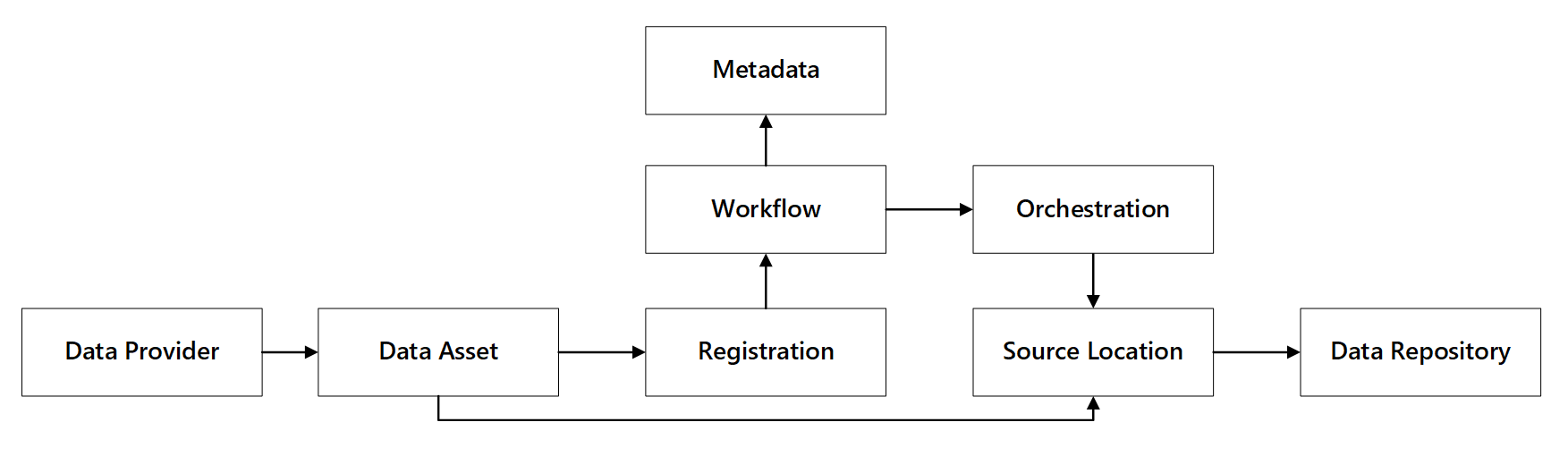
Obrázek 1: Interakce ohledně schopností registrace dat
Následující diagram ukazuje, jak tento proces implementovat pomocí kombinace služeb Azure:
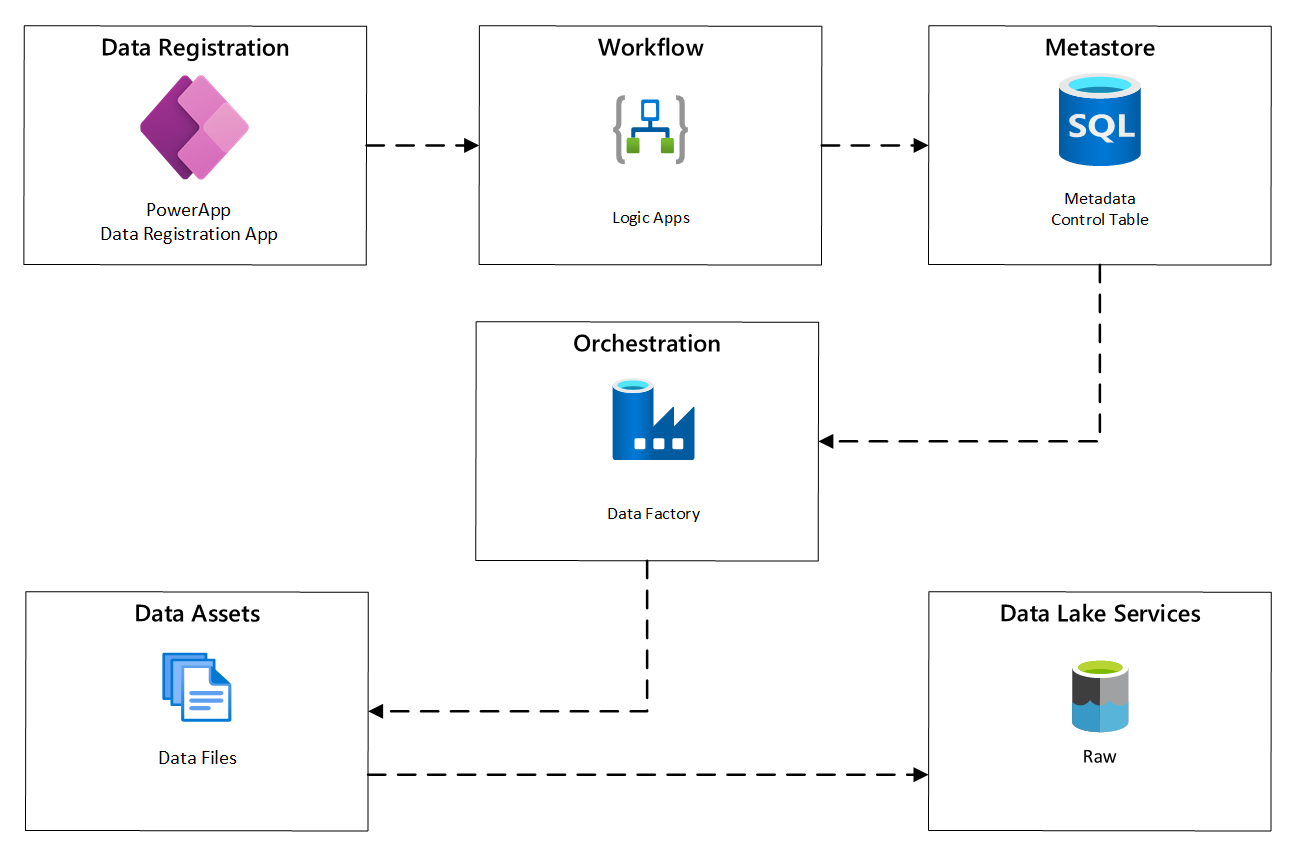
Obrázek 2: Automatizovaný proces příjmu dat
Registrace datového aktiva
Pro poskytnutí metadat používaných k řízení automatizovaného příjmu dat potřebujete registraci datového zdroje. Zachycené informace obsahují:
- Technické informace: název datového prostředku, zdrojový systém, typ, formát a četnost.
- Informace o správě: vlastník, správci, viditelnost (pro účely vyhledávání) a citlivost.
PowerApps se používá k zachycení metadat popisujících jednotlivé datové prostředky. Pomocí modelem řízené aplikace zadejte informace, které se zachovají do vlastní tabulky Dataverse. Když se metadata vytvoří nebo aktualizuje v rámci služby Dataverse, aktivuje tok automatizovaného cloudu, který vyvolá další kroky zpracování.
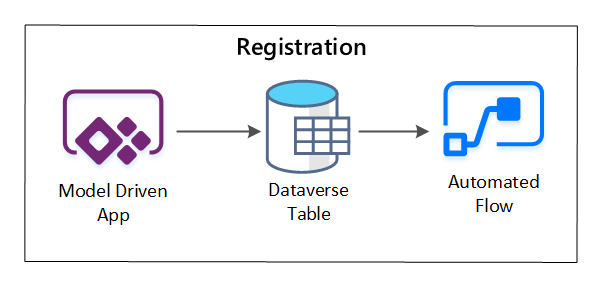
Obrázek 3: Registrace datového zdroje
Pracovní postup nastavení / zachycení metadat
Ve fázi pracovního postupu zřizování ověříte a uložíte data shromážděná ve fázi registrace do metastore. Provádí se postup technického i obchodního ověření, včetně následujících:
- Ověření vstupního datového kanálu
- Aktivace pracovního postupu schválení
- Proces zpracování logiky pro zajištění trvalého ukládání metadat do úložiště metadat
- Auditování aktivit
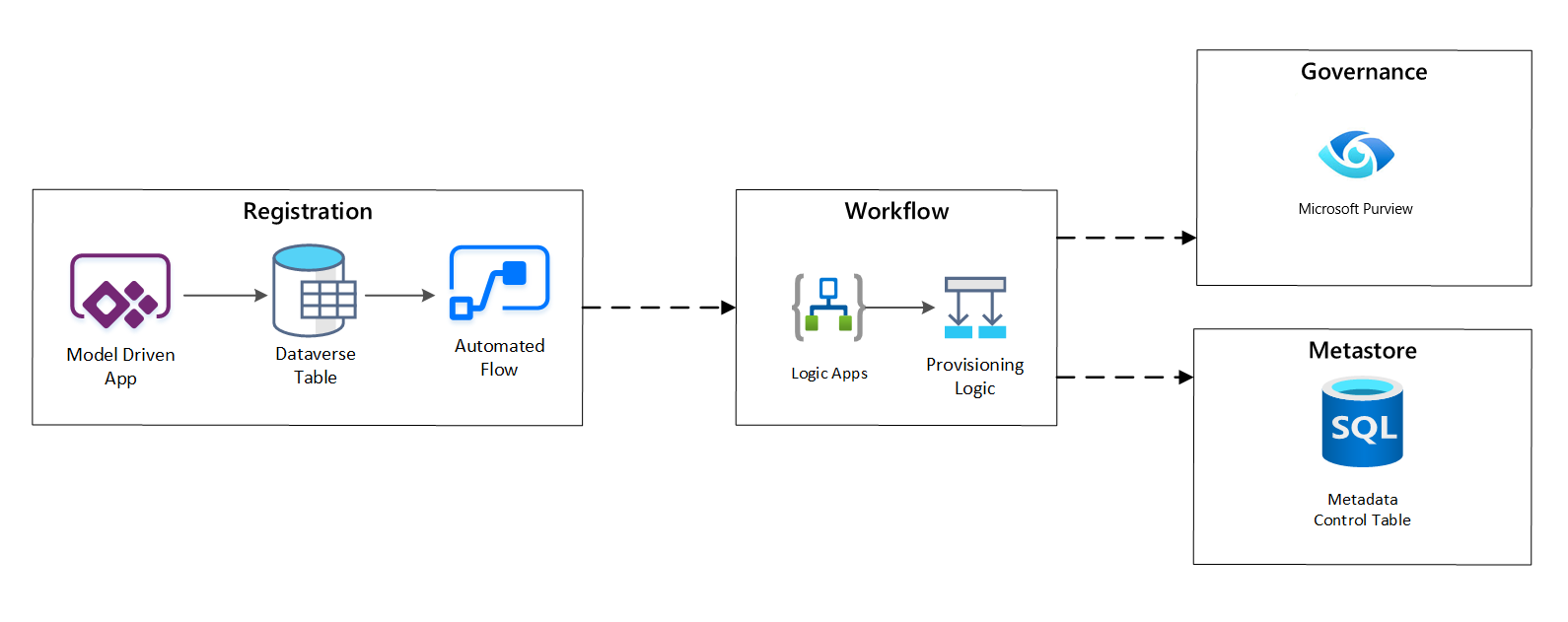
Obrázek 4: Pracovní postup registrace
Po schválení žádostí o příjem dat pracovní postup použije rozhraní REST API Microsoft Purview k vložení zdrojů do Microsoft Purview.
Podrobný pracovní postup pro zavádění datových produktů
diagram 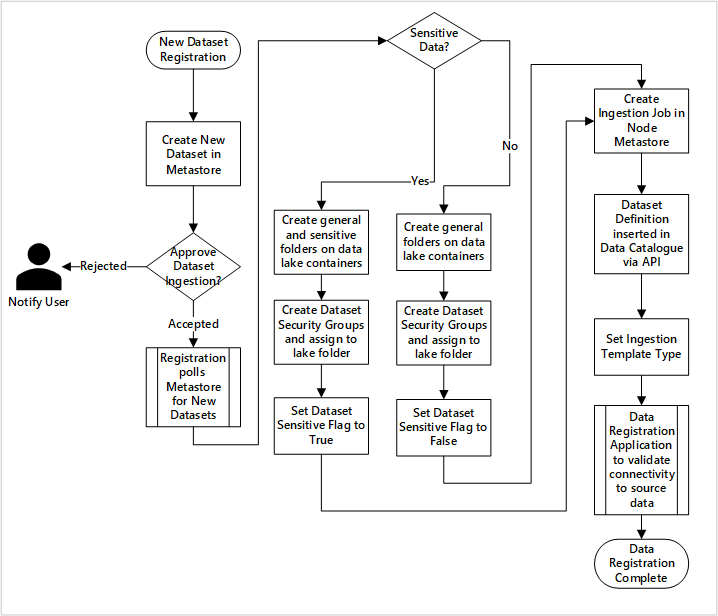
Obrázek 5: Jak se ingestují (automatizované) nové datové sady
Obrázek 5 ukazuje podrobný proces registrace pro automatizaci příjmu nových zdrojů dat:
- Podrobnosti o zdroji se registrují, včetně produkčního prostředí a prostředí datové továrny.
- Jsou zachycena omezení tvaru, formátu a kvality dat.
- Týmy datových aplikací by měly indikovat, jestli jsou data citlivá (osobní data) Tato klasifikace řídí proces vytváření složek Data Lake za účelem ingestování nezpracovaných, obohacených a kurátorovaných dat. Zdrojové názvy nezpracovaných a obohacených dat a názvy produktů dat kurátorované.
- Služební principál a skupiny zabezpečení se vytvářejí pro ingestování a udělování přístupu k datové sadě.
- Úloha ingestování je vytvořena v metastoru Data Factory v datové přistávací zóně.
- Rozhraní API vkládá definici dat do Microsoft Purview.
- V souladu s ověřením zdroje dat a schválením provozním týmem se podrobnosti publikují do metastoru služby Data Factory.
Plánování příjmu dat
Ve službě Azure Data Factory úlohy kopírování řízené metadaty poskytují funkce, které umožňují řídit kanály orchestrace pomocí řádků v řídicí tabulce uložené ve službě Azure SQL Database. Nástroj pro kopírování dat můžete použít k předběžnému vytvoření kanálů řízených metadaty.
Po vytvoření potrubí proces zřizování přidá položky do řídící tabulky, aby podporoval příjem dat ze zdrojů identifikovaných metadaty registrace datového prvku. Kanály Azure Data Factory a Azure SQL Database obsahující metastore řídicí tabulky mohou existovat v rámci každé cílové zóny dat, aby se vytvořily nové zdroje dat a ingestovaly je do cílových zón dat.
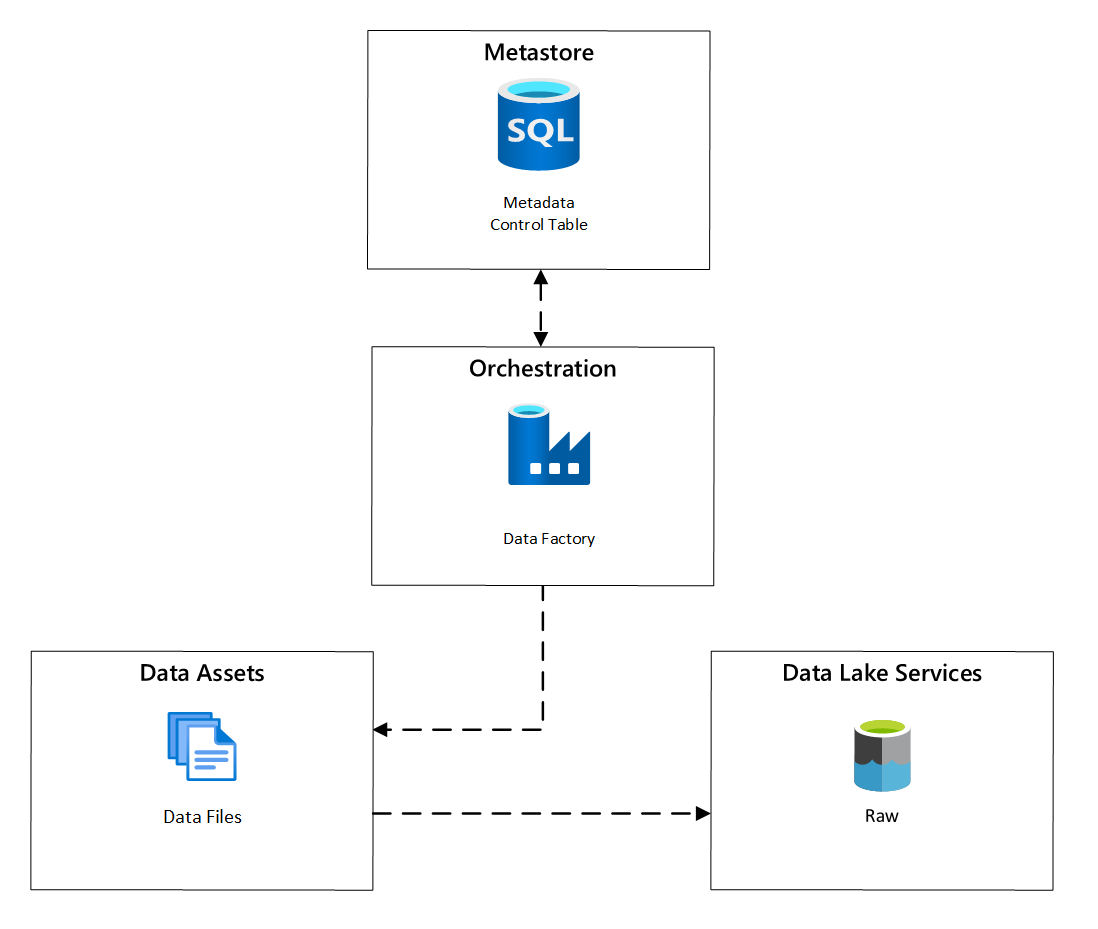
Obrázek 6: Plánování zpracování datových prvků
Podrobný pracovní postup pro příjem nových zdrojů dat
Následující diagram ukazuje, jak načíst registrované zdroje dat v metastoru služby Data Factory SQL Database a jak se data nejprve ingestují:
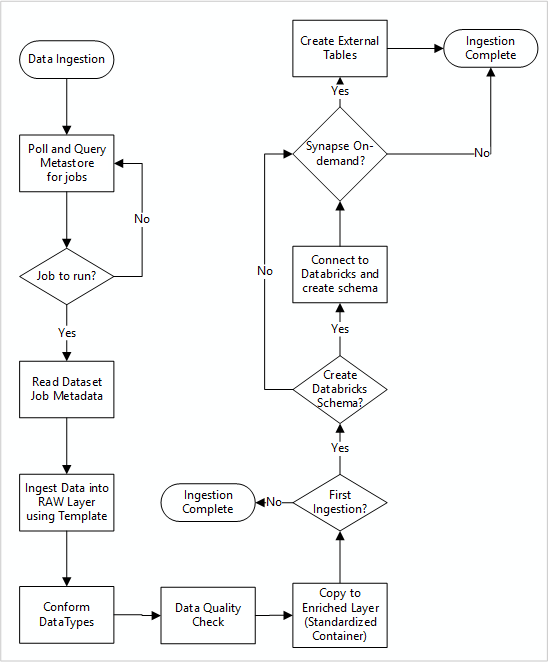
Hlavní kanál příjmu dat služby Data Factory načítá konfigurace z metastoru služby Data Factory SQL Database a pak provádí iterativní spuštění se správnými parametry. Data se přesunou ze zdroje do nezpracované vrstvy v Azure Data Lake beze změny. Struktura dat se ověřuje podle metastoru služby Data Factory. Formáty souborů se převedou na formáty Apache Parquet nebo Avro a pak se zkopírují do rozšířené vrstvy.
Ingestované data se připojují k pracovnímu prostoru datové vědy a inženýrství Azure Databricks a definice dat se vytvoří v rámci metastoru Apache Hive cílové zóny dat.
Pokud potřebujete k zpřístupnění dat využít bezserverový fond SQL Azure Synapse, mělo by vaše vlastní řešení vytvářet zobrazení nad daty v datovém jezeře.
Pokud požadujete šifrování na úrovni řádků nebo sloupců, vaše vlastní řešení by mělo uložit data do vašeho datového jezera, pak data přímo importovat do interních tabulek v SQL fondech a nastavit příslušné zabezpečení výpočetních prostředků v SQL fondech.
Zachycená metadata
Při použití automatizovaného příjmu dat můžete prověřovat přidružená metadata a vytvořit řídicí panely pro:
- Sledujte úlohy a nejnovější časové razítko načítání dat pro datové produkty související s jejich funkcemi.
- Sledování dostupných datových produktů
- Zvětšujte objemy dat.
- Získejte aktualizace v reálném čase týkající se selhání úloh.
Provozní metadata je možné použít ke sledování:
- Úlohy, kroky úloh a jejich závislosti
- Výkon úlohy a historie výkonu
- Objem dat se zvětšuje.
- Selhání úloh.
- Změny zdrojových metadat
- Obchodní funkce, které závisí na datových produktech.
Zjišťování dat pomocí rozhraní REST API služby Microsoft Purview
Rozhraní REST API služby Microsoft Purview by se měla použít k registraci dat během počátečního příjmu dat. Pomocí rozhraní API můžete odesílat data do katalogu dat brzy po jejich ingestování.
Další informace najdete v tématu , jak používat rozhraní REST API služby Microsoft Purview.
Registrace zdrojů dat
K registraci nových zdrojů dat použijte následující volání rozhraní API:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}
parametry identifikátoru URI pro zdroj dat:
| Jméno | Povinné | Typ | Popis |
|---|---|---|---|
accountName |
Pravda | Řetězec | Název účtu Microsoft Purview |
dataSourceName |
Pravda | Řetězec | Název zdroje dat |
Použití rozhraní REST API služby Microsoft Purview k registraci
Následující příklady ukazují, jak pomocí rozhraní REST API Microsoft Purview zaregistrovat zdroje dat s datovými částmi:
registrace zdroje dat Azure Data Lake Storage Gen2:
{
"kind":"AdlsGen2",
"name":"<source-name> (for example, My-AzureDataLakeStorage)",
"properties":{
"endpoint":"<endpoint> (for example, https://adls-account.dfs.core.windows.net/)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Registrace zdroje dat služby SQL Database:
{
"kind":"<source-kind> (for example, AdlsGen2)",
"name":"<source-name> (for example, My-AzureSQLDatabase)",
"properties":{
"serverEndpoint":"<server-endpoint> (for example, sqlservername.database.windows.net)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Poznámka
<collection-name>je aktuální kolekce, která existuje v účtu Microsoft Purview.
Vytvořit sken
Zjistěte, jak můžete vytvořit přihlašovací údaje k ověřování zdrojů v Microsoft Purview před nastavením a spuštěním kontroly.
Ke kontrole zdrojů dat použijte následující volání rozhraní API:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/
parametry identifikátoru URI pro skenování:
| Jméno | Požadovaný | Typ | Popis |
|---|---|---|---|
accountName |
Pravda | Řetězec | Název účtu Microsoft Purview |
dataSourceName |
Pravda | Řetězec | Název zdroje dat |
newScanName |
Pravda | Řetězec | Název nové kontroly |
Použijte rozhraní REST API služby Microsoft Purview pro skenování
Následující příklady ukazují, jak můžete pomocí Microsoft Purview REST API skenovat zdroje dat s datovými částmi:
Naskenujte zdroj dat Azure Data Lake Storage Gen2:
{
"name":"<scan-name>",
"kind":"AdlsGen2Msi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AdlsGen2"
}
}
Kontrola zdroje dat služby SQL Database:
{
"name":"<scan-name>",
"kind":"AzureSqlDatabaseMsi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AzureSqlDatabase",
"databaseName": "<database-name>",
"serverEndpoint": "<server-endpoint> (for example, sqlservername.database.windows.net)"
}
}
Ke kontrole zdrojů dat použijte následující volání rozhraní API:
POST https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/run