Zprovoznění datové sítě pro přípravu funkcí řízených doménou AI/ML
Datová síť pomáhá organizacím přecházet z centralizovaného datového jezera nebo datového skladu na decentralizaci datové analýzy na základě čtyř principů: vlastnictví dat v rámci domén, data jako produkt, samoobslužná datová platforma a federované výpočetní řízení. data mesh poskytuje výhody distribuovaného vlastnictví dat a lepší kvalitu, správu a řízení dat, což urychluje podnikání a zkracuje čas k dosažení hodnoty pro organizace.
Implementace datové sítě
Typická implementace datové sítě zahrnuje doménové týmy s datovými inženýry, kteří vytvářejí datové kanály. Tým udržuje provozní a analytické úložiště dat, jako jsou datová jezera, datové sklady nebo datové jezera. Kanály uvolní datových produktů pro jiné doménové týmy nebo týmy datových věd, které budou využívat. Ostatní týmy využívají datové produkty pomocí centrální platformy zásad správného řízení dat, jak je znázorněno v následujícím diagramu.
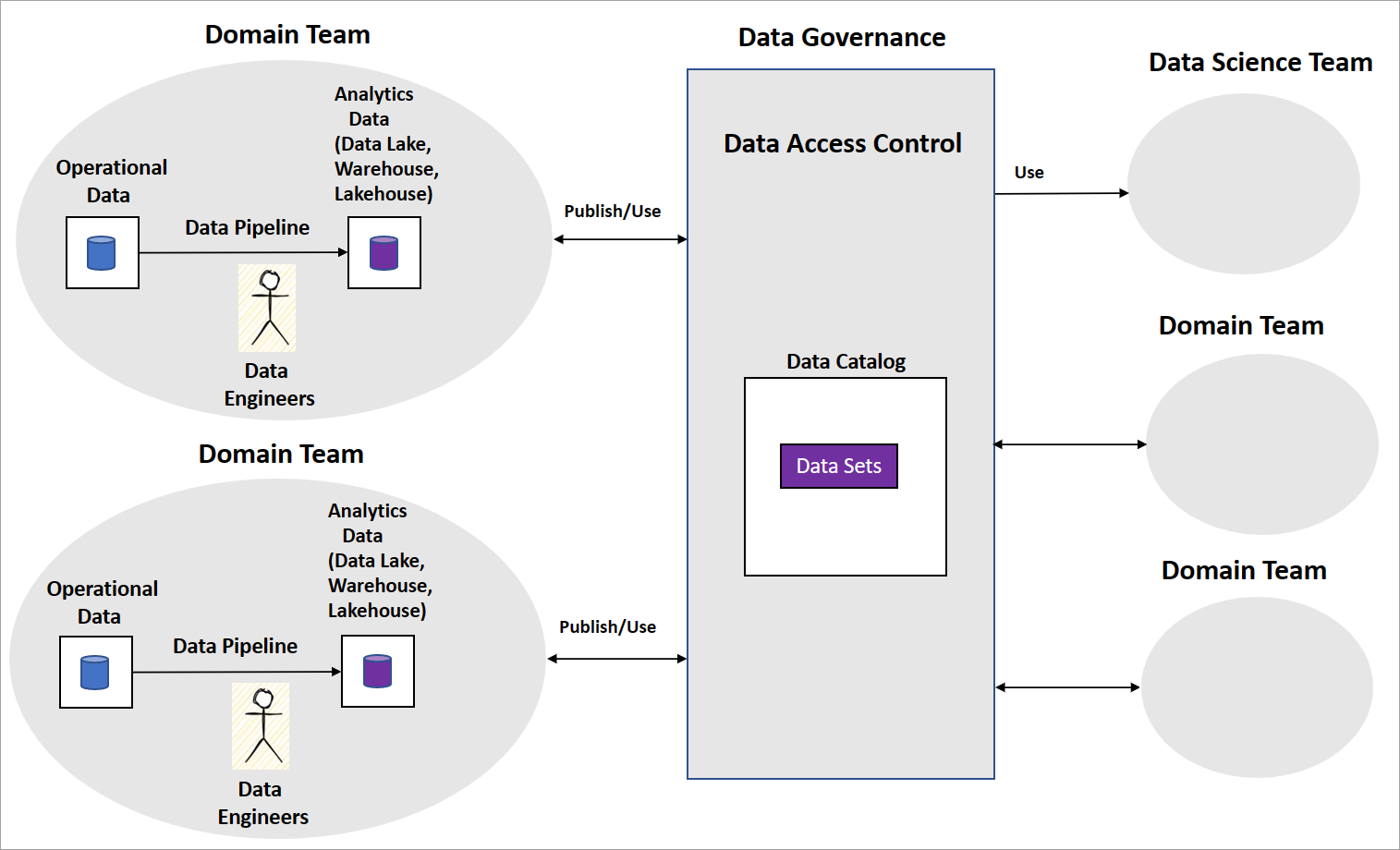
Data mesh je jasný v tom, jak datové produkty slouží transformovanými a agregovanými datovými sadami pro business intelligence. Nejedná se ale o explicitní přístup, který by organizace měly použít k vytváření modelů AI/ML. Neexistují ani pokyny, jak strukturovat týmy datových věd, zásady správného řízení modelu AI/ML a jak sdílet modely AI/ML nebo funkce mezi doménovým týmem.
Následující část popisuje několik strategií, které mohou organizace použít k vývoji funkcí AI/ML v rámci datové sítě. A uvidíte návrh strategie týkající se inženýrství funkcí řízených doménou nebo mesh funkcí.
Strategie AI/ML pro datovou síť
Jednou z běžných strategií je, aby organizace přijala týmy datové vědy jako spotřebitele dat. Tyto týmy přistupují k různým datovým produktům domény v datové síti podle případu použití. Provádějí zkoumání dat a přípravu funkcí pro vývoj a vytváření modelů AI/ML. V některých případech doménové týmy také vyvíjejí vlastní modely AI/ML pomocí svých dat a datových produktů jiných týmů k rozšíření a odvození nových funkcí.
Feature engineering je základem tvorby modelů a obvykle je složitý a vyžaduje odborné znalosti. Tato strategie může být časově náročná, protože týmy datových věd potřebují analyzovat různé datové produkty. Nemusí mít úplné znalosti domény pro vytváření vysoce kvalitních funkcí. Nedostatek znalostí o doméně může vést k duplicitnímu technickému úsilí o funkce mezi doménovými týmy. Problémy, jako je reprodukovatelnost modelu AI/ML, jsou také způsobené nekonzistentními sadami funkcí napříč týmy. Datové vědy nebo doménové týmy musí průběžně aktualizovat funkce, protože se vydávají nové verze datových produktů.
Další strategií je, aby doménové týmy vydály modely AI/ML ve formátu, jako je Open Neural Network Exchange (ONNX), ale tyto výsledky jsou černá pole a kombinování modelů AI/ML nebo funkcí napříč doménami by bylo obtížné.
Existuje způsob, jak decentralizovat vytváření modelů AI/ML napříč týmy pro datovou vědu a odborné oblasti, aby se řešily problémy? Navržená strategie přípravy funkcí řízených doménou nebo sítě funkcí je možnost.
Doménově řízené inženýrství funkcí nebo pavučina funkcí
Strategie vytváření funkcí řízených doménou nebo sítě funkcí nabízí decentralizovaný přístup k vytváření modelů AI/ML v nastavení datové sítě. Následující diagram znázorňuje strategii a způsob, jakým řeší čtyři hlavní principy datových sítí.
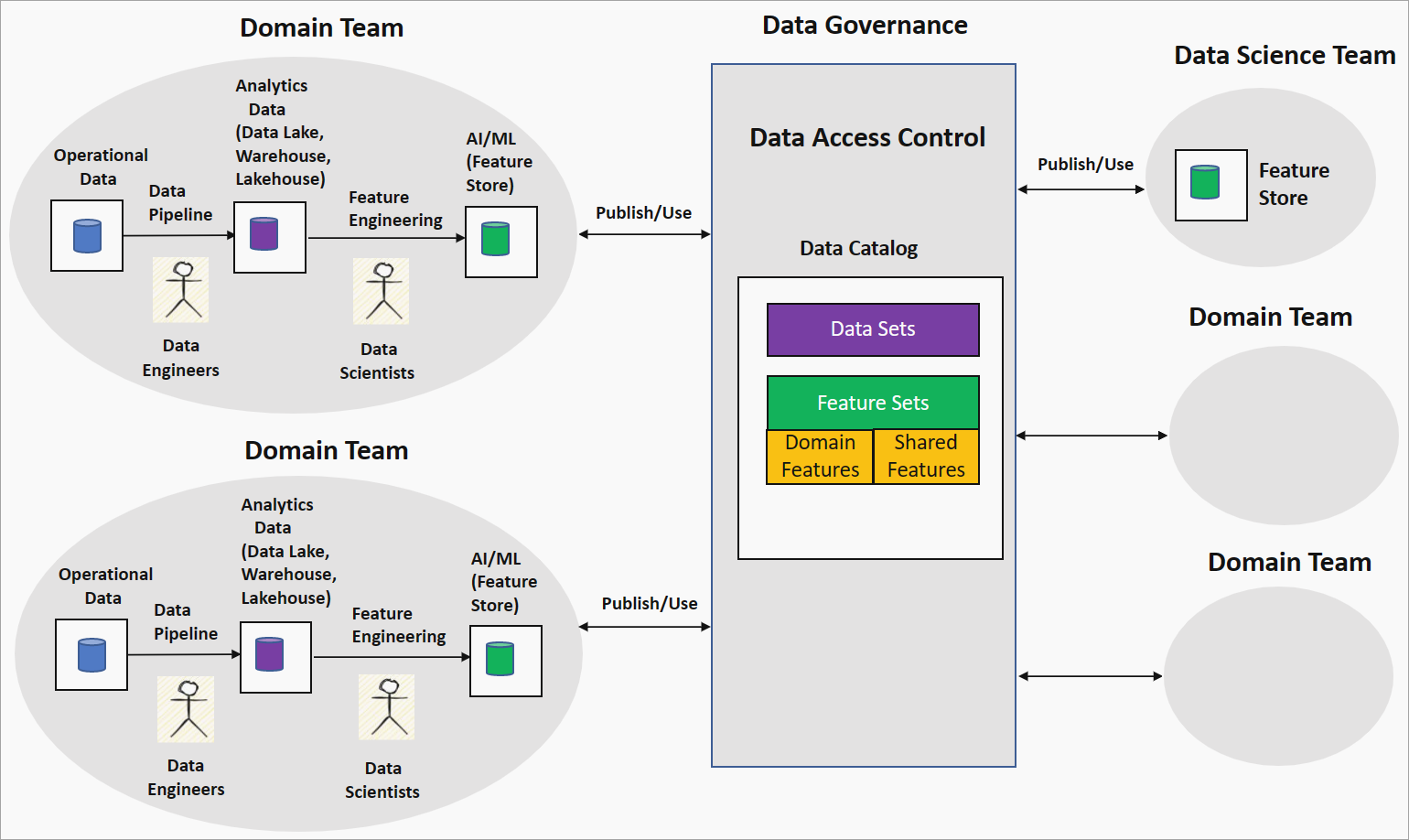
Tvorba charakteristik vlastnictví domén doménovými týmy
V této strategii organizace spáruje datové vědce s datovými inženýry v doménovém týmu, aby spustila zkoumání dat na čistých a transformovaných datech, například v datovém jezeře. Inženýr generuje funkce, které se ukládají v úložišti funkcí. Úložiště funkcí je úložiště dat, které poskytuje funkce pro trénování a odvozování a pomáhá sledovat verze funkcí, metadata a statistiky. Tato funkce umožňuje datovým vědcům v doménovém týmu úzce spolupracovat s odborníky na domény a udržovat funkce aktualizované při změnách dat v doméně.
Data jako produkt: Sady funkcí
Funkce vygenerované týmem domény, označované jako doména nebo místní funkce, se publikují do katalogu dat v platformě zásad správného řízení dat jako sady funkcí. Tyto sady funkcí využívají týmy datových věd nebo jiné doménové týmy pro vytváření modelů AI/ML. Během vývoje modelů AI/ML můžou týmy datových věd nebo domén zkombinovat funkce domény a vytvářet nové funkce označované jako sdílené nebo globální funkce. Tyto sdílené funkce se publikují zpět do katalogu sad funkcí pro spotřebu.
Samoobslužná datová platforma a zásady správného řízení federovaných výpočtů: Standardizace funkcí a kvalita
Tato strategie může vést k přijetí jiné technologické sady pro procesy modelování funkcí a k nekonzistentním definicím funkcí mezi doménovými týmy. Principy samoobslužné datové platformy zajišťují, aby doménové týmy používaly společnou infrastrukturu a nástroje k vytváření kanálů přípravy funkcí a vynucování řízení přístupu. Princip zásad správného řízení federovaných výpočetních prostředků zajišťuje interoperabilitu sad funkcí prostřednictvím globální standardizace a kontrol kvality funkcí.
Použití strategie vytváření funkcí řízených doménou nebo sítí funkcí nabízí decentralizovaný přístup k vytváření modelů AI/ML pro organizace, které pomáhají zkrátit dobu vývoje modelů AI/ML. Tato strategie pomáhá udržovat funkce konzistentní napříč doménovými týmy. Vyhne se duplikaci úsilí a vede k vysoce kvalitním funkcím pro přesnější modely AI/ML, které zvyšují hodnotu pro firmu.
Implementace datové sítě v Azure
Tento článek popisuje koncepty zprovoznění AI/ML v datové síti a nezabývá se nástroji ani architekturami pro sestavování těchto strategií. Azure nabízí úložiště funkcí, jako je úložiště funkcí Azure Databricks a Feathr od LinkedInu. Můžete vyvíjet Microsoft Purview vlastní konektory pro správu a řízení datových úložišť funkcí.