Správa prostředků ve službě Azure SQL Database
Platí pro:![]() Azure SQL Database
Azure SQL Database
Tento článek obsahuje přehled správy prostředků ve službě Azure SQL Database. Poskytuje informace o tom, co se stane, když dojde k dosažení limitů prostředků, a popisuje mechanismy zásad správného řízení prostředků, které se používají k vynucení těchto limitů.
Konkrétní limity prostředků na cenovou úroveň pro izolované databáze najdete v těchto tématu:
- Limity prostředků jednoúčelové databáze založené na DTU
- Omezení prostředků jednoúčelové databáze založené na virtuálních jádrech
Informace o omezeních prostředků elastického fondu najdete v těchto tématu:
- Limity prostředků elastického fondu založené na DTU
- Limity prostředků elastického fondu založené na virtuálních jádrech
Omezení vyhrazeného fondu SQL služby Azure Synapse Analytics najdete v následujících tématu:
- Omezení kapacity
- Limity paměti a souběžnosti
Omezení počtu virtuálních jader předplatného na oblast
Od března 2024 mají předplatná následující omezení virtuálních jader pro každou oblast na předplatné:
| Typ předplatného | Výchozí limity virtuálních jader |
|---|---|
| Smlouva Enterprise (EA) | 2000 |
| Bezplatné zkušební verze | 10 |
| Microsoft pro startupy | 100 |
| MSDN / MPN / Imagine / AzurePass / Azure for Students | 40 |
| Průběžné platby (PAYG) | 150 |
Zvažte použití těchto zdrojů:
- Tato omezení platí pro nová a stávající předplatná.
- Databáze a elastické fondy zřízené pomocí nákupního modelu DTU se počítají do kvóty virtuálních jader a naopak. Každé spotřebované virtuální jádro se považuje za ekvivalentní 100 DTU spotřebovaných pro kvótu na úrovni serveru.
- Mezi výchozí limity patří virtuální jádra nakonfigurovaná pro zřízené výpočetní databáze nebo elastické fondy a maximální počet virtuálních jader nakonfigurovaná pro bezserverové databáze.
- Můžete použít využití předplatného – Získání volání rozhraní REST API k určení aktuálního využití virtuálních jader pro vaše předplatné.
- Pokud chcete požádat o vyšší kvótu virtuálních jader než výchozí, odešlete novou žádost o podporu na webu Azure Portal. Další informace najdete v tématu Zvýšení kvóty žádostí pro službu Azure SQL Database a službu SQL Managed Instance.
Omezení logického serveru
| Prostředek | Omezení |
|---|---|
| Databáze na logický server | 5000 |
| Výchozí počet logických serverů na předplatné v oblasti | 250 |
| Maximální počet logických serverů na předplatné v oblasti | 250 |
| Maximální počet elastických fondů na logický server | Omezeno počtem DTU nebo virtuálních jader. Pokud je například každý fond 1000 DTU, může server podporovat 54 fondů. |
Důležité
Vzhledem k tomu, že počet databází se blíží limitu na logický server, může dojít k následujícímu:
- Zvýšení latence při spouštění dotazů v
masterdatabázi. To zahrnuje zobrazení statistik využití prostředků, napříkladsys.resource_stats. - Zvýšení latence operací správy a vykreslovacích bodů portálu, které zahrnují výčet databází na serveru.
Co se stane, když dojde k dosažení limitů prostředků
Výpočetní procesor
Když se využití procesoru výpočetního procesoru databáze zvýší, zvýší se latence dotazů a dotazy můžou dokonce časového limitu časového limitu. Za těchto podmínek mohou být dotazy zařazeny do fronty službou a poskytují prostředky ke spuštění, jakmile se prostředky uvolní.
Pokud zjistíte vysoké využití výpočetních prostředků, mezi možnosti omezení rizik patří:
- Zvětšením výpočetní velikosti databáze nebo elastického fondu zajistíte databázi více výpočetních prostředků. Viz Škálování prostředků izolované databáze a škálování prostředků elastického fondu.
- Optimalizace dotazů za účelem snížení využití prostředků procesoru jednotlivých dotazů Další informace najdete v části Ladění dotazů a pomocné parametry.
Úložiště
Když využitý datový prostor dosáhne maximálního limitu velikosti dat, a to buď na úrovni databáze, nebo na úrovni elastického fondu, vloží a aktualizuje, které zvětší velikost dat, selže a klienti obdrží chybovou zprávu. Příkazy SELECT a DELETE zůstávají nedotčené.
V úrovních služeb Premium a Pro důležité obchodní informace se klientům zobrazí také chybová zpráva, pokud kombinovaná spotřeba úložiště podle dat, transakčního protokolu a tempdb pro jednu databázi nebo elastický fond překročí maximální velikost místního úložiště. Další informace najdete v tématu Zásady správného řízení prostoru úložiště.
Pokud zjistíte vysoké využití prostoru úložiště, mezi možnosti omezení rizik patří:
- Zvyšte maximální velikost dat databáze nebo elastického fondu nebo vertikálně navyšte kapacitu cíle služby s vyšším limitem maximální velikosti dat. Viz Škálování prostředků izolované databáze a škálování prostředků elastického fondu.
- Pokud je databáze v elastickém fondu, můžete databázi přesunout mimo fond, aby se jeho prostor úložiště nesdílel s jinými databázemi.
- Zmenšete databázi, aby se uvolnilo nevyužité místo. Další informace najdete v tématu Správa prostoru souborů pro databáze.
- V elastických fondech poskytuje zmenšení databáze větší úložiště pro ostatní databáze ve fondu.
- Zkontrolujte, jestli je vysoké využití místa způsobené špičkou velikosti úložiště trvalých verzí (PVS). PVS je součástí každé databáze a používá se k implementaci zrychleného obnovení databáze. Pokud chcete zjistit aktuální velikost PVS, přečtěte si Řešení potíží s akcelerovaným obnovením databáze. Běžným důvodem velké velikosti PVS je transakce, která je otevřená po dlouhou dobu (hodiny), což brání vyčištění řádků starších verzí v PVS.
- U databází a elastických fondů v úrovních služeb Premium a Pro důležité obchodní informace, které spotřebovávají velké objemy úložiště, může dojít k chybě, která je mimo mezeru, i když využité místo v databázi nebo elastickém fondu je nižší než maximální limit velikosti dat. K tomu může dojít v případě, že
tempdbsoubory transakčních protokolů spotřebovávají velké množství úložiště směrem k maximálnímu limitu místního úložiště. Převzetí služeb při selhání databáze nebo elastického fondu pro resetovánítempdbpočáteční menší velikosti nebo zmenšení transakčního protokolu, aby se snížila spotřeba místního úložiště.
Relace, pracovní procesy a žádosti
Relace, pracovní procesy a požadavky jsou definovány takto:
- Relace představuje proces připojený k databázovému stroji.
- Požadavek je logické vyjádření dotazu nebo dávky. Požadavek vydá klient připojený k relaci. V průběhu času může být ve stejné relaci vydáno více požadavků.
- Pracovní vlákno, označované také jako pracovní nebo vlákno, je logické vyjádření vlákna operačního systému. Požadavek může mít mnoho pracovních procesů při spuštění s plánem paralelního provádění dotazu nebo jeden pracovní proces při spuštění se sériovým plánem provádění (s jedním vláknem). Pracovní procesy jsou také vyžadovány pro podporu aktivit mimo požadavky: Například pracovní proces se vyžaduje ke zpracování žádosti o přihlášení při připojení relace.
Další informace o těchto konceptech najdete v průvodci architekturou vláken a úloh.
Maximální počet pracovních procesů je určen úrovní služby a velikostí výpočetních prostředků. Po dosažení limitů relací nebo pracovních procesů jsou nové požadavky odmítnuty a klientům se zobrazí chybová zpráva. I když je možné řídit počet připojení aplikací, je často obtížnější odhadnout a řídit počet souběžných pracovních procesů. To platí zejména během období načítání ve špičce, kdy dojde k dosažení limitů prostředků databáze a pracovní procesy se hromadí kvůli delším spuštěným dotazům, velkým blokovacím řetězcům nebo nadměrnému paralelismu dotazů.
Poznámka:
Počáteční nabídka služby Azure SQL Database podporovala pouze dotazy s jedním vláknem. V té době byl počet žádostí vždy ekvivalentní počtu pracovníků. Chybová zpráva 10928 ve službě Azure SQL Database obsahuje pouze formulaci The request limit for the database is *N* and has been reached pro účely zpětné kompatibility. Dosažený limit ve skutečnosti představuje počet pracovních procesů.
Pokud je nastavení maximálního stupně paralelismu (MAXDOP) rovno nule nebo je větší než jedna, může být počet pracovních procesů mnohem vyšší než počet požadavků a limit může být mnohem dříve, než když se hodnota MAXDOP rovná jednomu.
- Přečtěte si další informace o chybě 10928 v chybách zásad správného řízení prostředků.
- Přečtěte si další informace o vyčerpání limitů požadavků v chybách 10928 a 10936.
Přístup nebo dosažení limitů pracovních procesů nebo relací můžete zmírnit pomocí následujících možností:
- Zvýšení úrovně služby nebo velikosti výpočetních prostředků databáze nebo elastického fondu Viz Škálování prostředků izolované databáze a škálování prostředků elastického fondu.
- Optimalizace dotazů za účelem snížení využití prostředků v případě, že příčinou zvýšeného počtu pracovních procesů je kolize výpočetních prostředků. Další informace najdete v části Ladění dotazů a pomocné parametry.
- Optimalizace úlohy dotazu, aby se snížil počet výskytů a doba trvání blokování dotazů. Další informace najdete v tématu Vysvětlení a řešení blokujících problémů.
- Pokud je to vhodné, snižte nastavení MAXDOP .
Vyhledejte limity pracovních procesů a relací pro Azure SQL Database podle úrovně služby a velikosti výpočetních prostředků:
- Limity prostředků pro jednoúčelové databáze využívající nákupní model založený na virtuálních jádrech
- Limity prostředků pro elastické fondy využívající nákupní model založený na virtuálních jádrech
- Limity prostředků pro jednoúčelové databáze využívající nákupní model založený na jednotkách DTU
- limity prostředků pro elastické fondy s využitím nákupního modelu DTU
Přečtěte si další informace o řešení konkrétních chyb pro limity relací nebo pracovních procesů v chybách zásad správného řízení prostředků.
Externí připojení
Počet souběžných připojení k externím koncovým bodům provedeným prostřednictvím sp_invoke_external_rest_endpoint je omezený na 10 % pracovních vláken s pevným limitem maximálně 150 pracovních procesů.
Memory (Paměť)
Na rozdíl od jiných prostředků (procesor, pracovní procesy, úložiště) nedosahuje limitu paměti negativní vliv na výkon dotazů a nezpůsobí chyby a selhání. Jak je podrobně popsáno v průvodci architekturou správy paměti , databázový stroj často záměrně používá veškerou dostupnou paměť. Paměť se používá především pro ukládání dat do mezipaměti, aby se zabránilo pomalejšímu přístupu k úložišti. Proto vyšší využití paměti obvykle zlepšuje výkon dotazů kvůli rychlejšímu čtení z paměti, na rozdíl od pomalejšího čtení z úložiště.
Po spuštění databázového stroje, protože úloha začne číst data z úložiště, databázový stroj agresivně ukládá data do mezipaměti v paměti. Po tomto počátečním počátečním období se běžně a očekává se, že uvidíte avg_memory_usage_percent sloupce avg_instance_memory_percent a sloupce v sys.dm_db_resource_stats a sql_instance_memory_percent metrika služby Azure Monitor se blíží 100 %, zejména pro databáze, které nejsou nečinné, a plně se nevejdou do paměti.
Poznámka:
Metrika sql_instance_memory_percent odráží celkovou spotřebu paměti databázovým strojem. Tato metrika nemusí dosáhnout 100 % ani v případě, že běží úlohy s vysokou intenzitou. Důvodem je to, že malá část dostupné paměti je vyhrazena pro přidělení kritické paměti kromě mezipaměti dat, jako jsou zásobníky vláken a spustitelné moduly.
Kromě mezipaměti dat se paměť používá i v dalších součástech databázového stroje. Když mezipaměť dat vyžaduje paměť a veškerou dostupnou paměť, databázový stroj zmenší velikost mezipaměti dat, aby byl paměť k dispozici pro jiné komponenty, a dynamicky roste mezipaměť dat, když ostatní komponenty uvolní paměť.
Ve výjimečných případech může dostatečně náročná úloha způsobit nedostatek paměti, což vede k chybám nedostatku paměti. K chybám nedostatku paměti může dojít na jakékoli úrovni využití paměti mezi 0 % a 100 %. Chyby nedostatku paměti se s větší pravděpodobností vyskytují u menších velikostí výpočetních prostředků, které mají proporcionálně menší limity paměti, nebo u úloh využívajících více paměti pro zpracování dotazů, například v hustých elastických fondech.
Pokud dojde k chybám kvůli nedostatku paměti, mezi možnosti omezení rizik patří:
- Projděte si podrobnosti o podmínce OOM v sys.dm_os_out_of_memory_events.
- Zvýšení úrovně služby nebo velikosti výpočetních prostředků databáze nebo elastického fondu Viz Škálování prostředků izolované databáze a škálování prostředků elastického fondu.
- Optimalizace dotazů a konfigurace za účelem snížení využití paměti Běžná řešení jsou popsaná v následující tabulce.
| Řešení | Popis |
|---|---|
| Zmenšení velikosti přidělení paměti | Další informace o grantech paměti najdete v blogovém příspěvku o principech paměti SQL Serveru. Běžným řešením, aby nedocházelo k nadměrnému množství grantů paměti, je udržovat statistiky aktuální. Výsledkem jsou přesnější odhady spotřeby paměti v dotazovacím modulu, aby nedocházelo k velkým grantům paměti. Ve výchozím nastavení může databázový stroj v databázích s úrovní kompatibility 140 a vyšší automaticky upravit velikost přidělení paměti pomocí zpětné vazby k udělení paměti v režimu Batch. Podobně v databázích používajících úroveň kompatibility 150 a vyšší používá databázový stroj také zpětnou vazbu k udělení paměti v režimu řádků pro častější dotazy v režimu řádků. Tato integrovaná funkce pomáhá vyhnout se chybám způsobeným nedostatkem paměti kvůli velkým přidělením paměti. |
| Zmenšení velikosti mezipaměti plánů dotazů | Databázový stroj ukládá plány dotazů do mezipaměti, aby se zabránilo kompilaci plánu dotazu pro každé spuštění dotazu. Abyste se vyhnuli blokování mezipaměti plánu dotazů způsobené plány ukládání do mezipaměti, které se používají pouze jednou, ujistěte se, že používáte parametrizované dotazy a zvažte povolení konfigurace v oboru databáze OPTIMIZE_FOR_AD_HOC_WORKLOADS. |
| Zmenšení velikosti paměti zámku | Databázový stroj používá paměť pro zámky. Pokud je to možné, vyhněte se velkým transakcím, které by mohly získat velký počet zámků a způsobit vysokou spotřebu paměti zámku. |
Spotřeba prostředků podle uživatelských úloh a interních procesů
Azure SQL Database vyžaduje výpočetní prostředky k implementaci základních funkcí služby, jako je vysoká dostupnost a zotavení po havárii, zálohování a obnovení databáze, monitorování, úložiště dotazů, automatické ladění atd. Systém vyhradí omezenou část celkových prostředků pro tyto interní procesy pomocí mechanismů zásad správného řízení prostředků a zpřístupní zbytek prostředků pro uživatelské úlohy. V době, kdy interní procesy nepoužívají výpočetní prostředky, systém je zpřístupní uživatelským úlohám.
Celková spotřeba procesoru a paměti podle uživatelských úloh a interních procesů se v sys.dm_db_resource_statsavg_instance_memory_percent. Tato data se také hlásí prostřednictvím sql_instance_cpu_percent metrik a sql_instance_memory_percent metrik Azure Monitoru pro izolované databáze a elastické fondy na úrovni fondu.
Poznámka:
Metriky sql_instance_cpu_percent služby sql_instance_memory_percent Azure Monitor jsou k dispozici od července 2023. Plně odpovídají dříve dostupným sqlserver_process_core_percent metrikám a sqlserver_process_memory_percent metrikám. Tyto dvě metriky zůstanou dostupné, ale v budoucnu se odeberou. Abyste se vyhnuli přerušení monitorování databáze, nepoužívejte starší metriky.
Tyto metriky nejsou dostupné pro databáze používající cíle služby Basic, S1 a S2. Stejná data jsou k dispozici v následujících zobrazeních dynamické správy.
Využití procesoru a paměti podle uživatelských úloh v jednotlivých databázích je hlášeno v sys.dm_db_resource_stats a sys.resource_stats zobrazeních avg_cpu_percent a avg_memory_usage_percent sloupcích. U elastických fondů se spotřeba prostředků na úrovni fondu hlásí v zobrazení sys.elastic_pool_resource_stats (pro historické scénáře vytváření sestav) a v sys.dm_elastic_pool_resource_stats pro monitorování v reálném čase. Využití procesoru úloh uživatelů se také hlásí prostřednictvím cpu_percent metriky Služby Azure Monitor pro izolované databáze a elastické fondy na úrovni fondu.
Podrobnější rozpis nedávné spotřeby prostředků podle uživatelských úloh a interních procesů se hlásí v zobrazeních sys.dm_resource_governor_resource_pools_history_ex a sys.dm_resource_governor_workload_groups_history_ex . Podrobnosti o fondech prostředků a skupinách úloh odkazovaných v těchto zobrazeních najdete v tématu Zásady správného řízení prostředků. Tato zobrazení zobrazuje sestavu o využití prostředků podle uživatelských úloh a konkrétních interních procesů v přidružených fondech prostředků a skupinách úloh.
Tip
Při monitorování nebo řešení potíží s výkonem úloh je důležité zvážit spotřebu procesoru uživatelů (avg_cpu_percent, cpu_percent) i celkovou spotřebu procesoru podle uživatelských úloh a interních procesů (avg_instance_cpu_percent,sql_instance_cpu_percent). Výkon může být výrazně ovlivněný, pokud je některé z těchto metrik v rozsahu 70–100 %.
Spotřeba procesoru uživatele je definována jako procento směrem k limitu procesoru úloh uživatelů v jednotlivých cílech služby. Stejně tak se celková spotřeba procesoru definuje jako procento směrem k limitu procesoru pro všechny úlohy. Vzhledem k tomu, že se tyto dvě limity liší, měří se uživatel a celková spotřeba procesoru na různých škálách a nejsou přímo srovnatelné s ostatními.
Pokud spotřeba procesoru uživatele dosáhne 100 %, znamená to, že úloha uživatele plně využívá dostupnou kapacitu procesoru ve vybraném cíli služby, i když celková spotřeba procesoru zůstává nižší než 100 %.
Když celková spotřeba procesoru dosáhne rozsahu 70–100 %, je možné zjistit, že propustnost úloh uživatele zploštěla a latence dotazů se zvyšuje, i když využití procesoru uživatele výrazně klesne pod 100 %. K tomu může dojít při použití menších cílů služby s mírným přidělováním výpočetních prostředků, ale relativně intenzivním uživatelským úlohám, jako jsou zhuštěné elastické fondy. K tomu může dojít také s menšími cíli služby, když interní procesy dočasně vyžadují více prostředků, například při vytváření nové repliky databáze nebo zálohování databáze.
Podobně platí, že když využití procesoru uživatelů dosáhne rozsahu 70–100%, zvýší se propustnost úloh uživatelů a latence dotazů, i když celková spotřeba procesoru je dobře nižší než jeho limit.
Pokud je spotřeba procesoru uživatele nebo celková spotřeba procesoru vysoká, možnosti omezení rizik jsou stejné jako možnosti uvedené v části Výpočetní procesor a zahrnují zvýšení cíle služby nebo optimalizaci úloh uživatelů.
Poznámka:
I u zcela nečinné databáze nebo elastického fondu není celková spotřeba procesoru nikdy nulová kvůli aktivitám databázového stroje na pozadí. Může kolísat v širokém rozsahu v závislosti na konkrétních aktivitách na pozadí, velikosti výpočetních prostředků a předchozí úloze uživatele.
Zásady správného řízení prostředků
K vynucování limitů prostředků používá Azure SQL Database implementaci zásad správného řízení prostředků, která je založená na správci prostředků SQL Serveru, upravená a rozšířená tak, aby běžela v cloudu. Ve službě SQL Database poskytuje několik fondů prostředků a skupin úloh s omezeními prostředků nastavenými na úrovni fondu i skupin vyváženou databázi jako službu. Uživatelské úlohy a interní úlohy jsou klasifikovány do samostatných fondů prostředků a skupin úloh. Uživatelské úlohy na primárních a čitelných sekundárních replikách, včetně geografických replik, jsou klasifikovány do SloSharedPool1 fondu prostředků a UserPrimaryGroup.DBId[N] skupin úloh, kde [N] je zkratka pro hodnotu ID databáze. Kromě toho existuje více fondů zdrojů a skupin úloh pro různé interní úlohy.
Kromě použití Správce prostředků k řízení prostředků v rámci databázového stroje používá Azure SQL Database také objekty úloh Systému Windows k řízení prostředků na úrovni procesu a Správce prostředků souborového serveru (FSRM) pro správu kvót úložiště.
Zásady správného řízení prostředků Azure SQL Database jsou hierarchické v podstatě. Shora dolů se limity vynucují na úrovni operačního systému a na úrovni svazku úložiště pomocí mechanismů zásad správného řízení prostředků operačního systému a správce prostředků, pak na úrovni fondu prostředků pomocí Správce prostředků a pak na úrovni skupiny úloh pomocí Správce prostředků. Omezení zásad správného řízení prostředků platná pro aktuální databázi nebo elastický fond se hlásí v zobrazení sys.dm_user_db_resource_governance .
Zásady správného řízení vstupně-výstupních operací dat
Zásady správného řízení vstupně-výstupních operací dat jsou procesem ve službě Azure SQL Database, který omezuje fyzické vstupně-výstupní operace čtení i zápisu proti datovým souborům databáze. Limity IOPS jsou nastavené pro každou úroveň služby, aby se minimalizoval účinek "hlučného souseda", aby bylo možné zajistit spravedlivé přidělování prostředků ve víceklientské službě a zůstat v rámci možností základního hardwaru a úložiště.
U jednoúčelových databází se limity skupin úloh použijí na všechny vstupně-výstupní operace úložiště pro databázi. U elastických fondů platí omezení skupin úloh pro každou databázi ve fondu. Kromě toho se limit fondu zdrojů navíc vztahuje na kumulativní vstupně-výstupní operace elastického fondu. Vstupně-výstupní tempdboperace podléhají omezením skupin úloh s výjimkou úrovně služby Basic, Standard a Pro obecné účely, kde platí vyšší tempdb limity vstupně-výstupních operací. Obecně platí, že limity fondu zdrojů nemusí být dosažitelné úlohou u databáze (buď s jednou nebo ve fondu), protože limity skupin úloh jsou nižší než limity fondu prostředků a dříve omezovaly vstupně-výstupní operace za sekundu a propustnost. Limity fondů ale mohou být dosaženy kombinovanou úlohou vůči více databázím ve stejném fondu.
Pokud například dotaz vygeneruje 1 000 IOPS bez jakýchkoli zásad správného řízení prostředků vstupně-výstupních operací, ale maximální limit IOPS skupiny úloh je nastavený na 900 IOPS, dotaz nemůže vygenerovat více než 900 IOPS. Pokud je však maximální limit IOPS fondu zdrojů nastavený na 1500 IOPS a celkový počet vstupně-výstupních operací ze všech skupin úloh přidružených k fondu zdrojů překračuje 1500 IOPS, může se vstupně-výstupní operace stejného dotazu snížit pod limit 900 IOPS pracovní skupiny.
Maximální hodnoty vstupně-výstupních operací za sekundu a propustnosti vrácené sys.dm_user_db_resource_governance fungují jako limity a limity, ne jako záruky. Zásady správného řízení prostředků navíc nezaručí žádnou konkrétní latenci úložiště. Nejlepší dosažitelná latence, IOPS a propustnost pro danou úlohu uživatele závisí nejen na omezeních zásad správného řízení vstupně-výstupních prostředků, ale také na kombinaci použitých velikostí vstupně-výstupních operací a možností základního úložiště. SQL Database používá vstupně-výstupní operace, které se liší velikostí mezi 512 bajty a 4 MB. Pro účely vynucování limitů IOPS se všechny vstupně-výstupní operace zohlední bez ohledu na velikost, s výjimkou databází s datovými soubory ve službě Azure Storage. V takovém případě se IOs větší než 256 kB započítávají jako více 256 kB vstupně-výstupních operací, aby bylo v souladu s účtováním vstupně-výstupních operací Azure Storage.
Pro databáze Basic, Standard a Pro obecné účely, které používají datové soubory ve službě Azure Storage, nemusí být hodnota dosažitelná, primary_group_max_io pokud databáze nemá dostatek datových souborů k kumulativnímu poskytnutí tohoto počtu vstupně-výstupních operací za sekundu nebo pokud data nejsou rovnoměrně distribuována mezi soubory nebo pokud úroveň výkonu podkladových objektů blob omezuje počet IOPS/propustnost pod limity zásad správného řízení prostředků. Podobně s malými vstupně-výstupními operacemi protokolu generovanými častými potvrzeními primary_max_log_rate transakcí nemusí být hodnota dosažitelná úlohou kvůli limitu IOPS souvisejícího objektu blob služby Azure Storage. Pro databáze využívající Azure Premium Storage používá Azure SQL Database dostatečně velké objekty blob úložiště k získání potřebných vstupně-výstupních operací za sekundu a propustnosti bez ohledu na velikost databáze. U větších databází se vytvoří několik datových souborů, aby se zvýšila celková kapacita vstupně-výstupních operací za sekundu a propustnosti.
Hodnoty využití prostředků, jako avg_data_io_percent jsou například a avg_log_write_percent, hlášené v sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_stats a sys.elastic_pool_resource_stats zobrazení, se počítají jako procento maximálních limitů zásad správného řízení prostředků. Proto když faktory jiné než zásady správného řízení prostředků omezují vstupně-výstupní operace za sekundu a propustnost, je možné zjistit, že počet vstupně-výstupních operací za sekundu a latence se zvyšuje, i když hlášené využití prostředků zůstává nižší než 100 %.
Pokud chcete monitorovat vstupně-výstupní operace čtení a zápisu, propustnost a latenci pro každý databázový soubor, použijte funkci sys.dm_io_virtual_file_stats(). Tato funkce zobrazí všechny vstupně-výstupní operace vůči databázi, včetně vstupně-výstupních operací na pozadí, které se nezapočítávají do avg_data_io_percentprostředí , ale využívá IOPS a propustnost základního úložiště a může mít vliv na latenci úložiště. Funkce hlásí další latenci, kterou můžou zavést zásady správného řízení prostředků vstupně-výstupních operací pro čtení a zápisy v io_stall_queued_read_ms příslušných sloupcích a io_stall_queued_write_ms sloupcích.
Zásady správného řízení rychlosti transakčních protokolů
Zásady správného řízení rychlosti transakčních protokolů jsou procesem ve službě Azure SQL Database, který se používá k omezení vysoké míry příjmu pro úlohy, jako jsou hromadné vkládání, SELECT INTO a sestavení indexu. Tato omezení se sledují a vynucují na úrovni podsekundy na rychlost generování záznamů protokolu a omezují propustnost bez ohledu na to, kolik IO může být vydáno u datových souborů. Míra generování transakčních protokolů se v současné době lineárně škáluje až do bodu, který je závislý na hardwaru a na úrovni služby.
Sazby protokolů jsou nastaveny tak, aby bylo možné je dosáhnout a udržovat v různých scénářích, zatímco celkový systém může udržovat své funkce s minimalizovaným dopadem na zatížení uživatele. Zásady správného řízení rychlosti protokolů zajišťují, aby zálohy transakčních protokolů zůstaly v rámci publikovaných smluv SLA pro obnovení. Tyto zásady správného řízení také brání nadměrnému backlogu na sekundárních replikách, které by jinak mohly vést k delšímu, než očekávanému výpadku během převzetí služeb při selhání.
Skutečné fyzické IOs pro soubory transakčních protokolů nejsou řízeny ani omezeny. Při generování záznamů protokolu se každá operace vyhodnocuje a posuzuje, jestli by měla být zpožděná, aby se zachovala maximální požadovaná rychlost protokolů (MB/s za sekundu). Zpoždění se nepřidávají, když se záznamy protokolu vyprázdní do úložiště, ale zásady správného řízení rychlosti protokolů se použijí během samotného generování přenosové rychlosti protokolů.
Skutečné míry generování protokolů uložené v době běhu jsou také ovlivněny mechanismy zpětné vazby, což dočasně snižuje povolené rychlosti protokolů, aby se systém mohl stabilizovat. Správa prostoru souborů protokolu, aby nedocházelo k problémům s místem protokolu a mechanismům replikace dat, může dočasně snížit celkové systémové limity.
Tvarování provozu správce rychlosti protokolů se zobrazuje pomocí následujících typů čekání (vystavených v zobrazeních sys.dm_exec_requests a sys.dm_os_wait_stats ):
| Typ čekání | Notes |
|---|---|
LOG_RATE_GOVERNOR |
Omezení databáze |
POOL_LOG_RATE_GOVERNOR |
Omezení fondu |
INSTANCE_LOG_RATE_GOVERNOR |
Omezení úrovně instance |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
Kontrola zpětné vazby, fyzická replikace skupiny dostupnosti v Premium/Pro důležité obchodní informace nedrží krok |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
Kontrola zpětné vazby, omezení rychlosti, aby se zabránilo výpadku místa v protokolu |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
Kontrola zpětné vazby geografické replikace, omezení rychlosti protokolů, aby se zabránilo vysoké latenci dat a nedostupnosti geografických sekundárních dat |
Při výskytu limitu rychlosti protokolu, který brání požadované škálovatelnosti, zvažte následující možnosti:
- Vertikálně navyšte kapacitu na vyšší úroveň služby, abyste získali maximální rychlost protokolu úrovně služby nebo přešli na jinou úroveň služby. Úroveň služby Hyperscale poskytuje rychlost protokolů 100 MB/s na databázi a 125 MB/s na elastický fond bez ohledu na zvolenou úroveň služby. Rychlost generování protokolů 150 MB/s je dostupná jako funkce opt-in Preview. Další informace a výslovný souhlas s 150 MB/s najdete v blogu: Vylepšení hyperškálování z listopadu 2024.
- Pokud jsou načtená data přechodná, například pracovní data v procesu ETL, je možné je načíst do databáze
tempdb(která se protokoluje minimálně). - V případě analytických scénářů načítejte do clusterované tabulky clusterovaného columnstore nebo do tabulky s indexy, které využívají kompresi dat. Tím se sníží požadovaná míra protokolování. Tato technika zvyšuje využití procesoru a dá se využít jenom pro datové sady, které využívají clusterované indexy columnstore nebo kompresi dat.
Zásady správného řízení prostoru úložiště
V úrovních služeb Premium a Pro důležité obchodní informace se zákaznická data, včetně datových souborů, souborů transakčních protokolů a tempdb souborů, ukládají v místním úložišti SSD počítače, který je hostitelem databáze nebo elastického fondu. Místní úložiště SSD poskytuje vysoké IOPS a propustnost a nízkou latenci vstupně-výstupních operací. Kromězákaznických
Velikost místního úložiště je omezená a závisí na hardwarových možnostech, které určují maximální limit místního úložiště nebo místní úložiště vyhrazené pro zákaznická data. Toto omezení je nastavené tak, aby maximalizovalo úložiště zákaznických dat a současně zajišťuje bezpečnou a spolehlivou systémovou operaci. Pokud chcete najít maximální hodnotu místního úložiště pro každý cíl služby, projděte si dokumentaci k limitům prostředků pro izolované databáze a elastické fondy.
Tuto hodnotu a množství místního úložiště aktuálně používaného danou databází nebo elastickým fondem můžete najít pomocí následujícího dotazu:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Sloupec | Popis |
|---|---|
server_name |
Název logického serveru |
database_name |
Název databáze |
slo_name |
Název cíle služby, včetně generování hardwaru |
user_data_directory_space_quota_mb |
Maximální místní úložiště v MB |
user_data_directory_space_usage_mb |
Aktuální využití místního úložiště datovými soubory, soubory transakčních protokolů a tempdb soubory v MB. Aktualizováno každých pět minut. |
Tento dotaz by se měl spustit v uživatelské databázi, ne v master databázi. U elastických fondů je možné dotaz spustit v jakékoli databázi ve fondu. Hlášené hodnoty platí pro celý fond.
Důležité
Pokud se úloha v úrovních služeb Premium a Pro důležité obchodní informace pokusí zvýšit kombinovanou spotřebu místního úložiště datovými soubory, soubory transakčních protokolů a tempdb soubory nad maximálním limitem místního úložiště, dojde k chybě nedostatek místa. K tomu dojde i v případě, že využité místo v databázovém souboru nedosáhlo maximální velikosti souboru.
Místní úložiště SSD také používají databáze v jiných úrovních služeb než Premium a Pro důležité obchodní informace pro tempdb databázi a mezipaměť Hyperscale RBPEX. Vzhledem k tomu, že se databáze vytvářejí, odstraňují a zvětšují nebo zmenšují, celková spotřeba místního úložiště v počítači v průběhu času kolísá. Pokud systém zjistí, že dostupné místní úložiště na počítači je nízké a databáze nebo elastický fond jsou ohroženy nedostatkem místa, přesune databázi nebo elastický fond do jiného počítače s dostatečným místním úložištěm.
K tomuto přesunu dochází online způsobem, podobně jako operace škálování databáze, a má podobný dopad, včetně krátkého (sekundového) převzetí služeb při selhání na konci operace. Toto převzetí služeb při selhání ukončí otevřená připojení a vrátí zpět transakce, což může mít vliv na aplikace využívající databázi.
Vzhledem k tomu, že se všechna data kopírují do místních svazků úložiště na různých počítačích, může přesun větších databází v úrovních služeb Premium a Pro důležité obchodní informace vyžadovat značnou dobu. Pokud během této doby spotřeba místního prostoru databáze nebo elastického fondu nebo tempdb databáze rychle roste, zvyšuje se riziko, že dojde k výpadku místa. Systém zahájí přesun databáze vyváženým způsobem, aby minimalizoval chyby při výpadku místa a současně se vyhnul zbytečným převzetím služeb při selhání.
tempdb velikosti
Omezení velikosti pro tempdb službu Azure SQL Database závisí na modelu nákupu a nasazení.
Další informace najdete v následujících omezeních tempdb velikosti:
- Nákupní model virtuálních jader: izolované databáze, databáze ve fondu
- Nákupní model DTU: izolované databáze, databáze ve fondu.
Dříve dostupný hardware
Tato část obsahuje podrobnosti o dříve dostupném hardwaru.
- Hardware Gen4 je vyřazený a není k dispozici pro zřizování, škálování nebo snížení kapacity. Migrujte databázi na podporovanou generaci hardwaru pro širší škálu škálovatelnosti virtuálních jader a úložiště, akcelerované síťové služby, nejlepší výkon vstupně-výstupních operací a minimální latenci. Další informace najdete v tématu Podpora pro hardware Gen 4 ve službě Azure SQL Database.
Pomocí Azure Resource Graph Exploreru můžete identifikovat všechny prostředky Azure SQL Database, které aktuálně používají hardware Gen4, nebo můžete zkontrolovat hardware používaný prostředky pro konkrétní logický server na webu Azure Portal.
Abyste mohli zobrazit výsledky v Azure Resource Graph Exploreru, musíte mít alespoň read oprávnění k objektu nebo skupině objektů Azure.
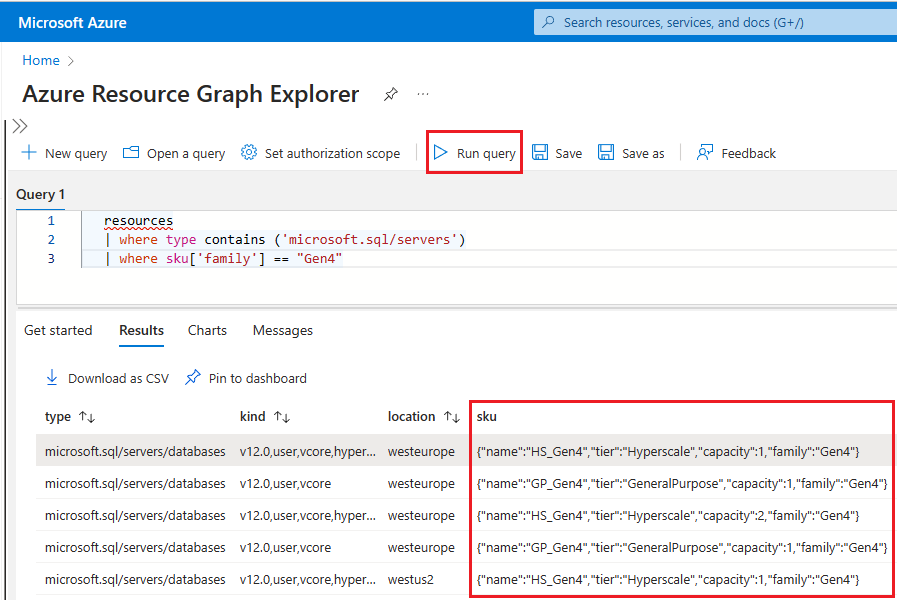
Pokud chcete pomocí Resource Graph Exploreru identifikovat prostředky Azure SQL, které stále používají hardware Gen4, postupujte takto:
Přejděte na Azure Portal.
Vyhledejte
Resource graphve vyhledávacím poli službu Resource Graph Explorer a ve výsledcích hledání zvolte službu Resource Graph Explorer .V okně dotazu zadejte následující dotaz a pak vyberte Spustit dotaz:
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"V podokně Výsledky se zobrazí všechny aktuálně nasazené prostředky v Azure, které používají hardware Gen4.
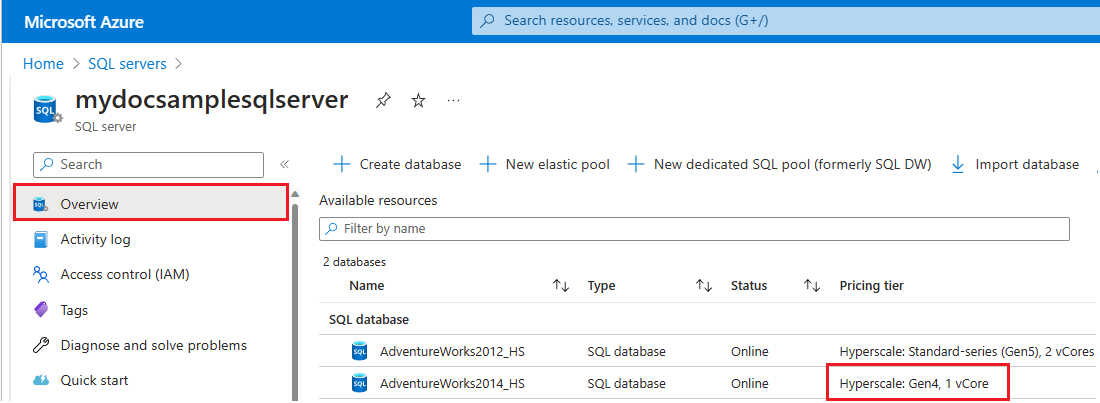
Pokud chcete zkontrolovat hardware používaný prostředky pro konkrétní logický server v Azure, postupujte takto:
- Přejděte na Azure Portal.
- Vyhledejte
SQL serversve vyhledávacím poli a zvolte SERVERY SQL z výsledků hledání, aby se otevřela stránka sql serverů a zobrazily se všechny servery pro vybraná předplatná. - Výběrem serveru, který má zájem, otevřete stránku Přehled pro server.
- Posuňte se dolů k dostupným prostředkům a zkontrolujte sloupec Cenová úroveň pro prostředky, které používají hardware Gen4.
Pokud chcete migrovat prostředky na hardware řady Standard, přečtěte si téma Změna hardwaru.
Související obsah
- Informace oobecnýchch
- Informace o DTU a eDTU najdete v tématu DTU a eDTU.
- Informace o limitech velikosti najdete v
tempdbtématu Databáze s jedním virtuálním jádrem, databáze virtuálních jader ve fondu, izolované databáze DTU a databáze DTU ve fondu.