Strategie zotavení po havárii pro aplikace využívající elastické fondy Azure SQL Database
Platí pro: ![]() Azure SQL Database
Azure SQL Database
Azure SQL Database poskytuje několik možností, jak zajistit kontinuitu podnikových procesů aplikace v případě katastrofických incidentů. Elastické fondy a izolované databáze podporují stejný druh možností zotavení po havárii (DR). Tento článek popisuje několik strategií zotavení po havárii pro elastické fondy, které využívají tyto funkce provozní kontinuity služby Azure SQL Database.
Tento článek používá následující kanonický model aplikace SaaS ISV:
Moderní cloudová webová aplikace zřídí jednu databázi pro každého koncového uživatele. IsV má mnoho zákazníků a proto používá mnoho databází, označovaných jako databáze tenantů. Vzhledem k tomu, že databáze tenantů obvykle mají nepředvídatelné vzorce aktivity, isV používá elastický fond k tomu, aby náklady na databázi byly velmi předvídatelné v delších časových obdobích. Elastický fond také zjednodušuje správu výkonu při špičkách aktivity uživatelů. Kromě databází tenantů aplikace také používá několik databází ke správě profilů uživatelů, zabezpečení, shromažďování vzorů využití atd. Dostupnost jednotlivých tenantů nemá vliv na dostupnost aplikace jako celek. Dostupnost a výkon databází pro správu je však pro funkci aplikace zásadní a pokud jsou databáze pro správu offline, je celá aplikace offline.
Tento článek popisuje strategie zotavení po havárii zahrnující celou řadu scénářů od aplikací s citlivými na náklady na spouštění až po ty, které mají přísné požadavky na dostupnost.
Poznámka:
Pokud používáte databáze Premium nebo Pro důležité obchodní informace a elastické fondy, můžete je zajistit odolnost vůči oblastním výpadkům tak, že je převedete na zónově redundantní konfiguraci nasazení. Viz zónově redundantní databáze.
1\. scénář: Spuštění citlivé na náklady
Jsem začínající firma a jsem velmi citlivá na náklady. Chci zjednodušit nasazení a správu aplikace a můžu mít omezenou smlouvu SLA pro jednotlivé zákazníky. Ale chci zajistit, aby aplikace jako celek nebyla nikdy offline.
Pokud chcete splnit požadavek na jednoduchost, nasaďte všechny databáze tenantů do jednoho elastického fondu v oblasti Azure podle vašeho výběru a nasaďte databáze pro správu jako geograficky replikované izolované databáze. Pro zotavení po havárii tenantů použijte geografické obnovení, které je bez dalších nákladů. Pokud chcete zajistit dostupnost databází pro správu, geograficky je replikujte do jiné oblasti pomocí skupiny převzetí služeb při selhání (krok 1). Průběžné náklady na konfiguraci zotavení po havárii v tomto scénáři se rovnají celkovým nákladům na sekundární databáze. Tato konfigurace je znázorněna v dalším diagramu.
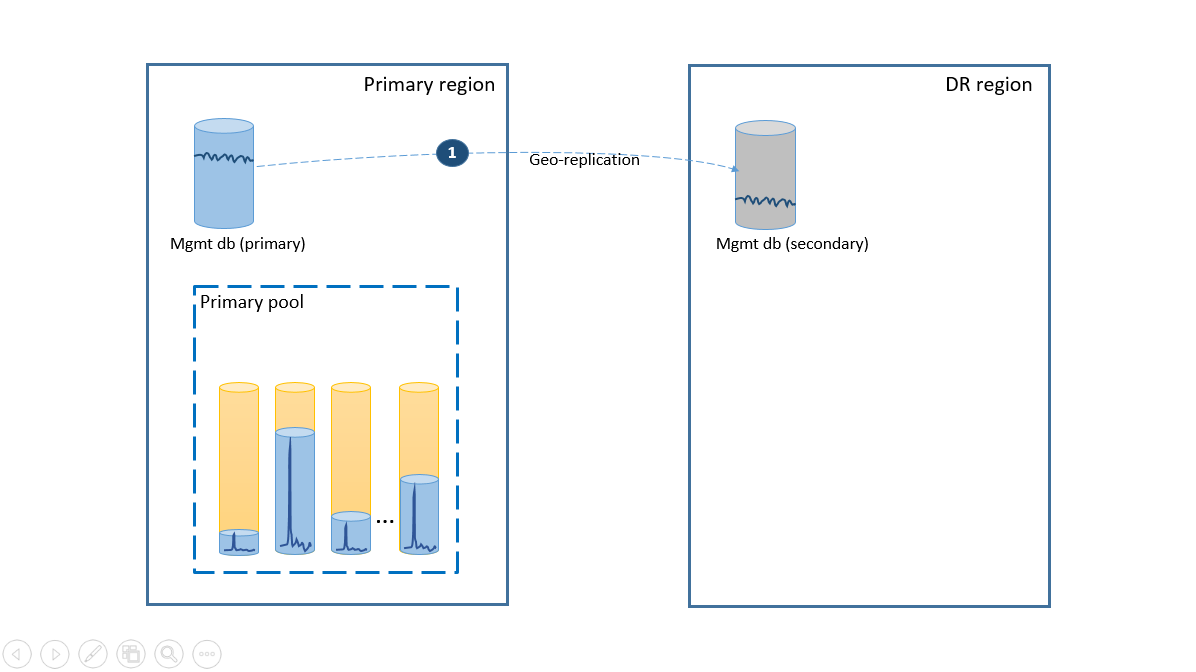
Pokud dojde k výpadku v primární oblasti, kroky obnovení, které aplikaci přenesou do režimu online, znázorňuje další diagram.
- Skupina převzetí služeb při selhání zahájí automatické převzetí služeb při selhání databáze pro správu do oblasti zotavení po havárii. Aplikace se automaticky znovu připojí k nové primární databázi a všechny nové účty a databáze tenantů se vytvoří v oblasti zotavení po havárii. Stávající zákazníci vidí data dočasně nedostupná.
- Vytvořte elastický fond se stejnou konfigurací jako původní fond (2).
- Použití geografického obnovení k vytvoření kopií databází tenantů (3). Můžete zvážit aktivaci jednotlivých obnovení pomocí připojení koncových uživatelů nebo použít jiné schéma priority specifické pro aplikaci.
V tuto chvíli je vaše aplikace opět online v oblasti zotavení po havárii, ale někteří zákazníci mají při přístupu k datům zpoždění.
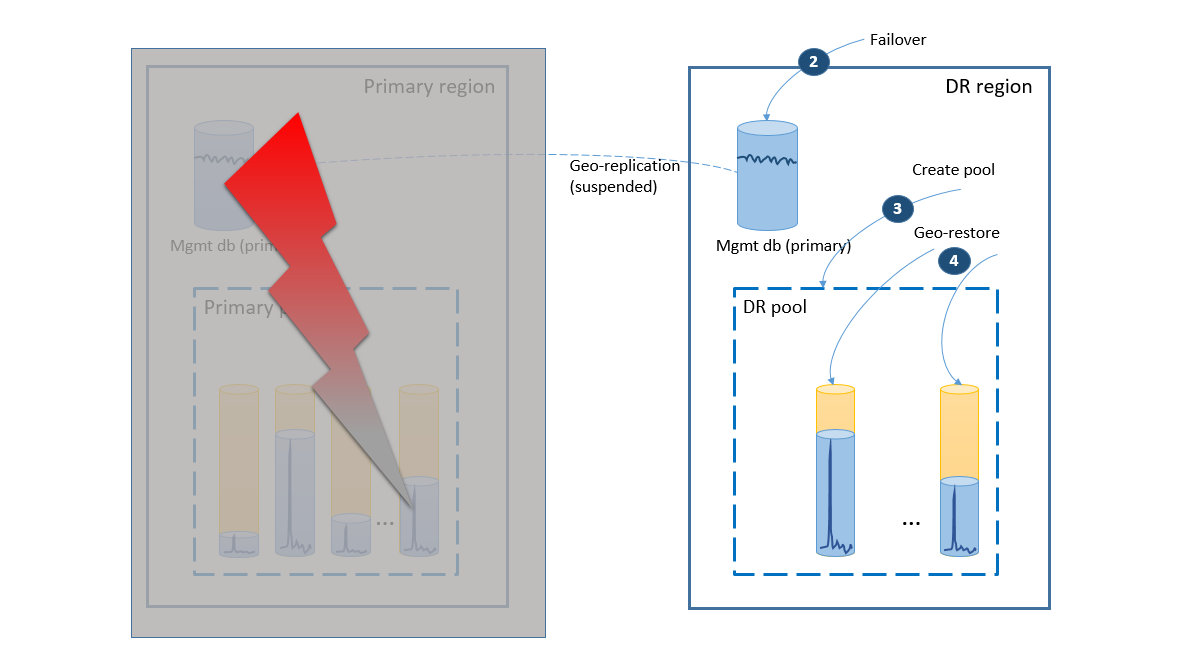
Pokud došlo k dočasnému výpadku, je možné, že Azure obnoví primární oblast před dokončením všech obnovení databáze v oblasti zotavení po havárii. V takovém případě orchestrujte přesun aplikace zpět do primární oblasti. Proces provede kroky znázorněné v dalším diagramu.
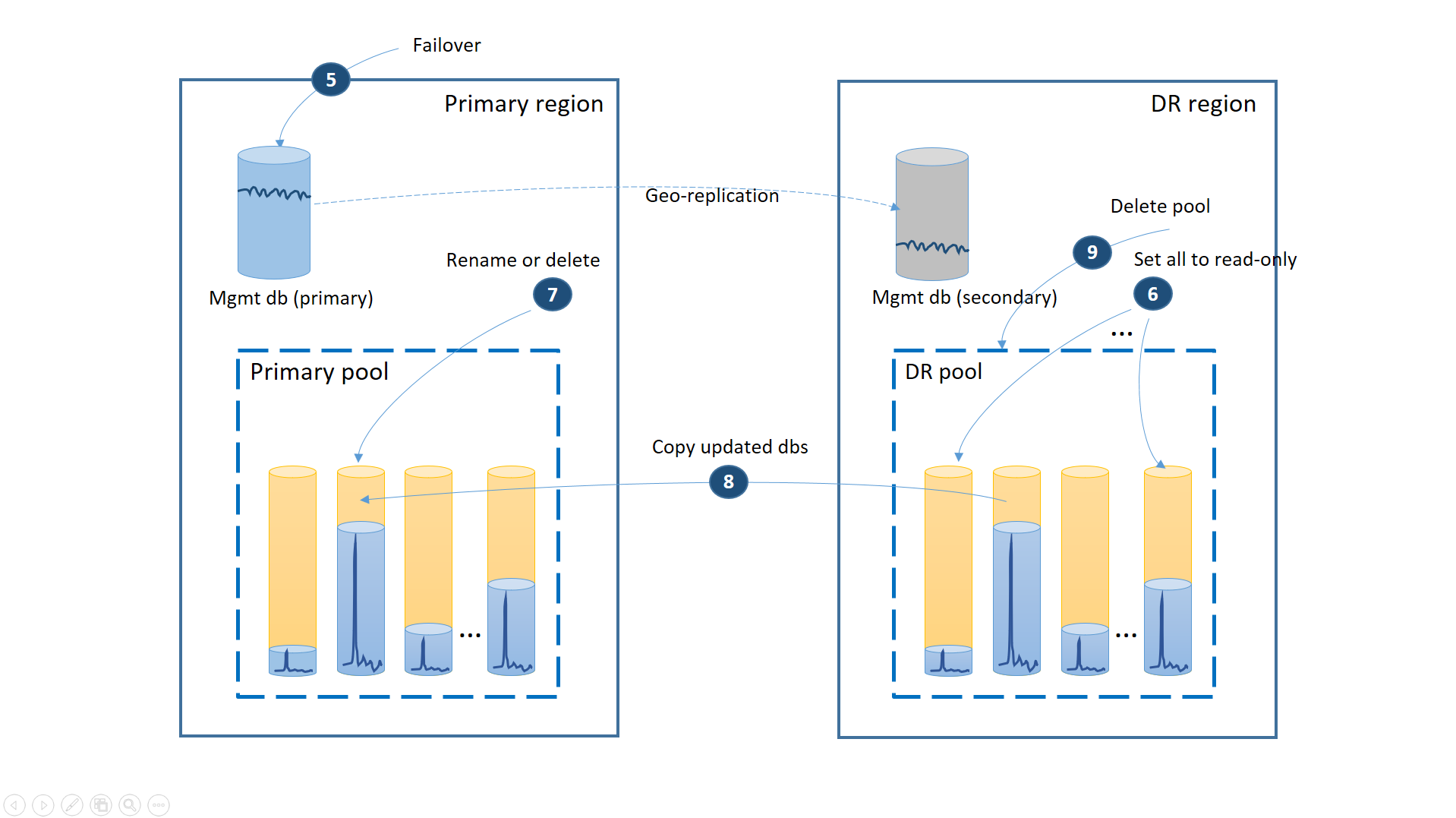
- Zrušte všechny nevyřízených žádostí o geografické obnovení.
- Převzetí služeb při selhání databází správy do primární oblasti (5). Po obnovení regionu se staré primarie automaticky stanou sekundárními. Teď znovu přepnou role.
- Změňte připojovací řetězec aplikace tak, aby odkazovat zpět na primární oblast. Teď se vytvoří všechny nové účty a databáze tenantů v primární oblasti. Někteří stávající zákazníci vidí data dočasně nedostupná.
- Nastavte všechny databáze ve fondu zotavení po havárii na jen pro čtení, abyste zajistili, že je nelze upravit v oblasti zotavení po havárii (6).
- Pro každou databázi ve fondu zotavení po havárii, která se od obnovení změnila, přejmenujte nebo odstraňte odpovídající databáze v primárním fondu (7).
- Zkopírujte aktualizované databáze z fondu zotavení po havárii do primárního fondu (8).
- Odstranění fondu zotavení po havárii (9)
V tuto chvíli je vaše aplikace online v primární oblasti se všemi databázemi tenantů dostupnými v primárním fondu.
Výhoda
Klíčovou výhodou této strategie je nízká průběžná cena za redundanci datové vrstvy. Azure SQL Database automaticky zálohuje databáze bez přepsání aplikace bez dalších nákladů. Náklady se účtují pouze v případech, kdy se obnoví elastické databáze.
Kompromis
Kompromis spočívá v tom, že úplné obnovení všech databází tenantů trvá výrazně dlouho. Doba závisí na celkovém počtu obnovení, které zahájíte v oblasti zotavení po havárii, a celkové velikosti databází tenantů. I když upřednostníte obnovení některých tenantů před ostatními, budete soupeřit se všemi ostatními obnoveními, které jsou zahájeny ve stejné oblasti jako rozhodce služby, a omezení, aby se minimalizoval celkový dopad na databáze stávajících zákazníků. Obnovení databází tenantů se navíc nedá spustit, dokud se nevytvořil nový elastický fond v oblasti zotavení po havárii.
2\. scénář: Vyspělá aplikace s vrstvenou službou
Jsem vyspělá aplikace SaaS s nabídkami vrstvených služeb a různými smlouvami SLA pro zkušební zákazníky a za placení zákazníků. Pro zákazníky se zkušební verzí musím co nejvíce snížit náklady. Zákazníci se zkušební verzí můžou prostojit, ale chci snížit jeho pravděpodobnost. Pro platící zákazníky představuje případný výpadek riziko letu. Chci se ujistit, že platící zákazníci mají vždy přístup ke svým datům.
Pokud chcete tento scénář podporovat, oddělte zkušební tenanty od placených tenantů jejich umístěním do samostatných elastických fondů. Zákazníci zkušební verze mají nižší počet eDTU nebo virtuálních jader na tenanta a nižší smlouvu SLA s delší dobou obnovení. Platící zákazníci jsou ve fondu s vyššími eDTU nebo virtuálními jádry na tenanta a vyšší smlouvou SLA. Aby se zajistilo co nejnižší doba obnovení, replikují se geograficky replikované databáze tenantů platících zákazníků. Tato konfigurace je znázorněna v dalším diagramu.
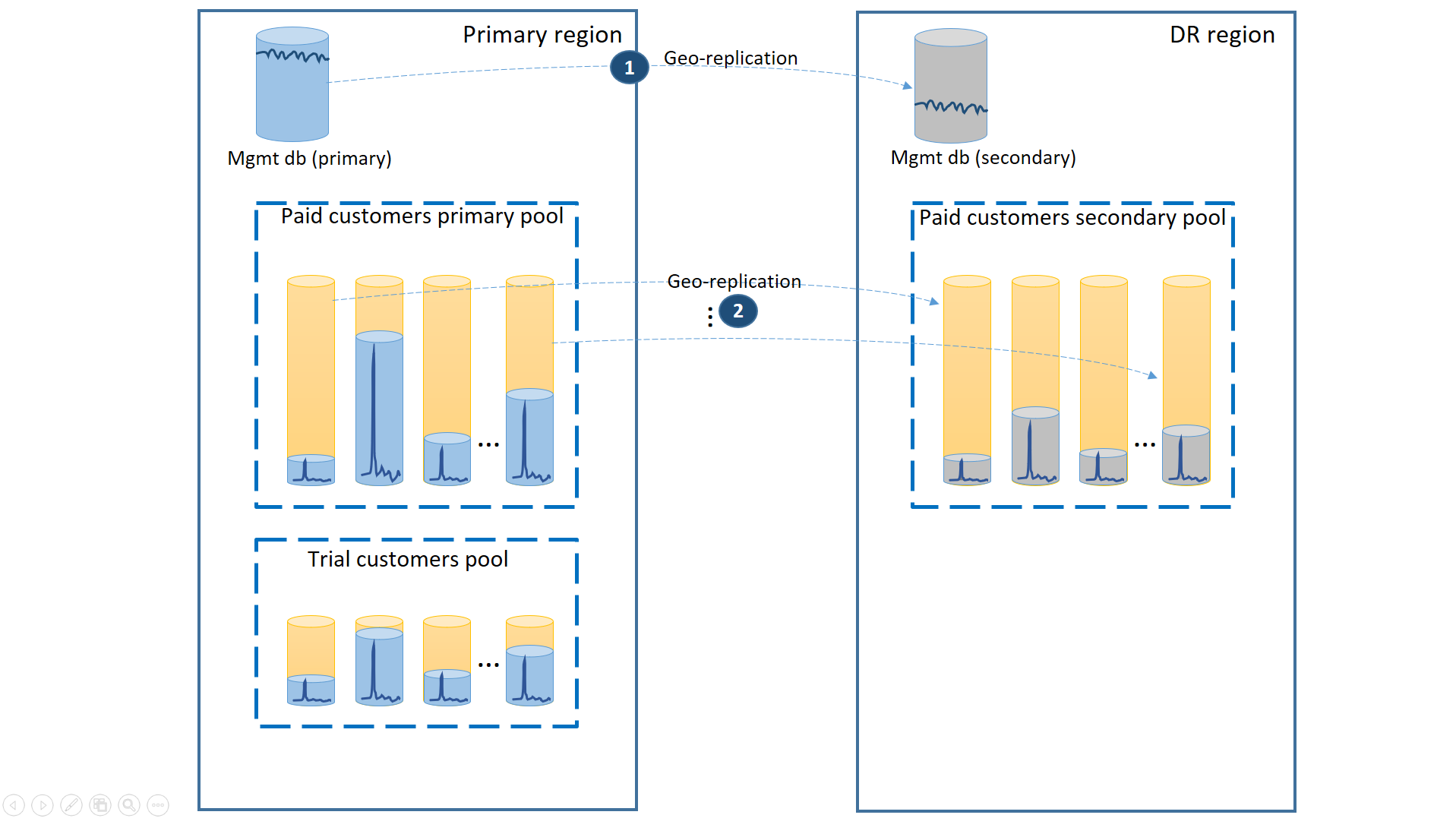
Stejně jako v prvním scénáři jsou databáze pro správu poměrně aktivní, takže pro ni použijete jednu geograficky replikovanou databázi (1). Tím se zajistí předvídatelný výkon pro nová předplatná zákazníků, aktualizace profilů a další operace správy. Oblast, ve které se nacházejí primární servery databází pro správu, je primární oblastí a oblastí, ve které se nacházejí sekundární databáze pro správu, je oblast zotavení po havárii.
Databáze tenantů platících zákazníků mají aktivní databáze v placeném fondu zřízeném v primární oblasti. Zřiďte sekundární fond se stejným názvem v oblasti zotavení po havárii. Každý tenant se geograficky replikuje do sekundárního fondu (2). To umožňuje rychlé obnovení všech databází tenantů pomocí převzetí služeb při selhání.
Pokud dojde k výpadku v primární oblasti, kroky obnovení, které aplikaci přenesou do online režimu, jsou znázorněny v dalším diagramu:
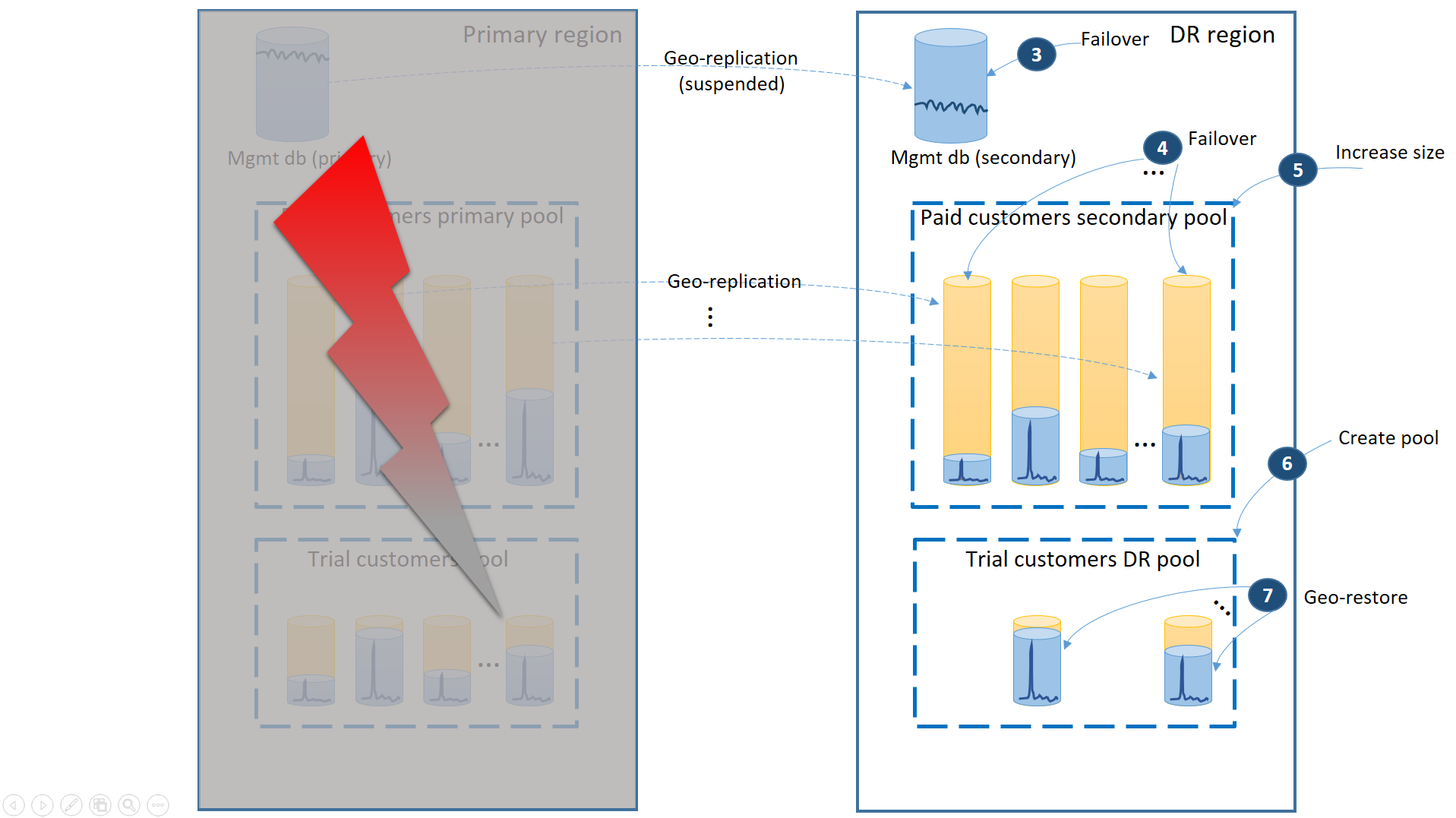
- Okamžitě převezme služby při selhání databází správy do oblasti zotavení po havárii (3).
- Změňte připojovací řetězec aplikace tak, aby odkazovat na oblast zotavení po havárii. Teď se v oblasti zotavení po havárii vytvoří všechny nové účty a databáze tenantů. Stávající zákazníci zkušební verze uvidí data dočasně nedostupná.
- Převzetí služeb při selhání databází placených tenantů do fondu v oblasti zotavení po havárii za účelem okamžitého obnovení dostupnosti (4) Vzhledem k tomu, že převzetí služeb při selhání je rychlá změna na úrovni metadat, zvažte optimalizaci, kdy se jednotlivá převzetí služeb při selhání aktivují na vyžádání připojeními koncových uživatelů.
- Pokud byla velikost eDTU sekundárního fondu nebo hodnota virtuálního jádra nižší než primární, protože sekundární databáze vyžadovaly ke zpracování protokolů změn pouze kapacitu, zatímco se změnily, okamžitě zvyšte kapacitu fondu, aby se přizpůsobila plné úloze všech tenantů (5).
- Vytvořte nový elastický fond se stejným názvem a stejnou konfigurací v oblasti zotavení po havárii pro databáze zkušebních zákazníků (6).
- Po vytvoření fondu zkušebních verzí zákazníka použijte geografické obnovení k obnovení databází jednotlivých zkušebních tenantů do nového fondu (7). Zvažte aktivaci jednotlivých obnovení pomocí připojení koncových uživatelů nebo použijte jiné schéma priority specifické pro aplikaci.
V tuto chvíli je vaše aplikace opět online v oblasti zotavení po havárii. Všichni platící zákazníci mají přístup ke svým datům, zatímco zkušební verze se při přístupu ke svým datům zpozdí.
Když Azure po obnovení aplikace v oblasti zotavení po havárii obnoví primární oblast, můžete pokračovat ve spuštění aplikace v této oblasti nebo se můžete rozhodnout, že se vrátíte do primární oblasti. Pokud se primární oblast obnoví před dokončením procesu převzetí služeb při selhání, zvažte navrácení služeb po obnovení hned. Navrácení služeb po obnovení provede kroky znázorněné v dalším diagramu:
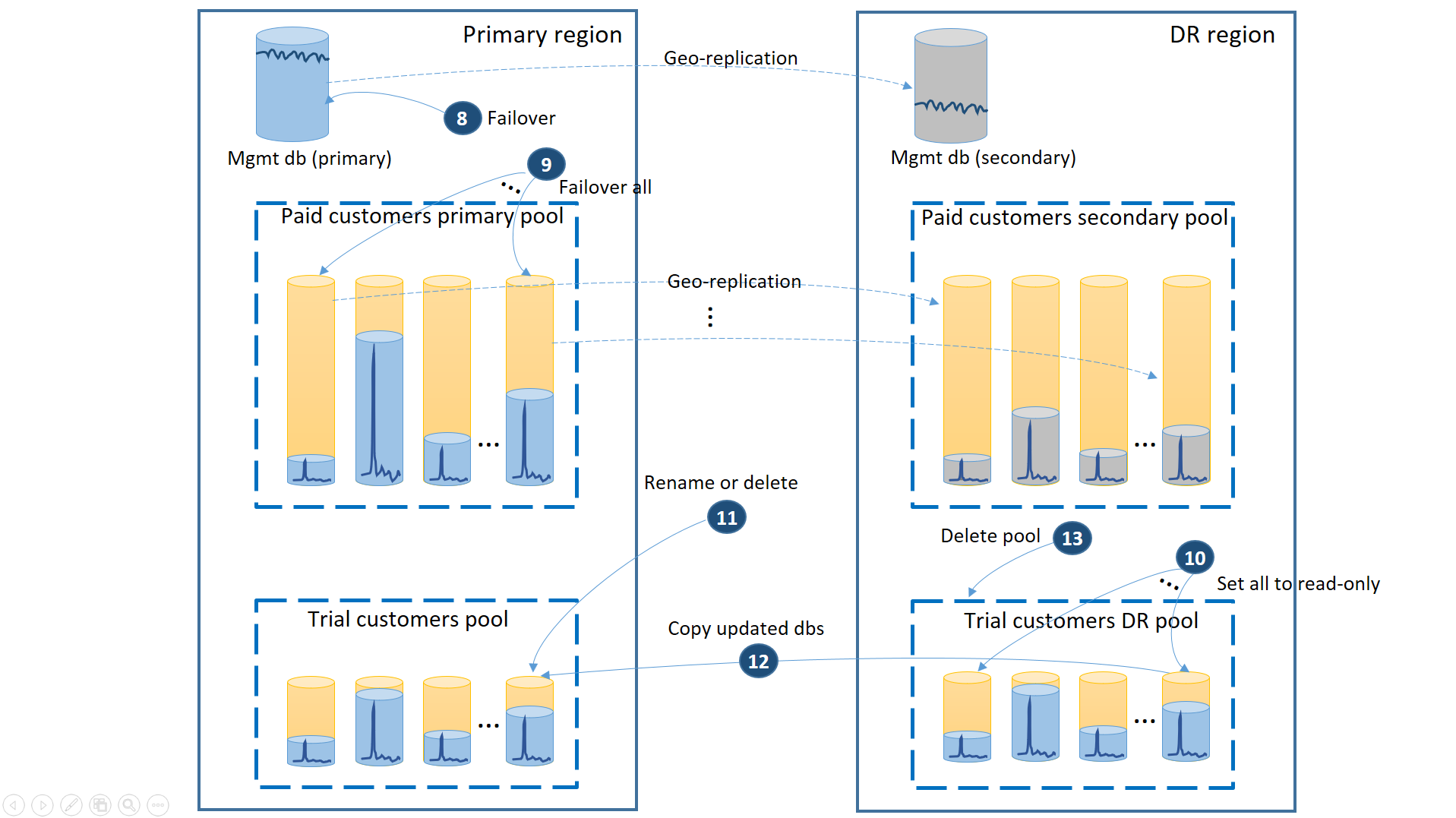
- Zrušte všechny nevyřízených žádostí o geografické obnovení.
- Převzetí služeb při selhání databází pro správu (8) Po obnovení oblasti se stará primární lokalita automaticky stane sekundární. Teď se stane primárním.
- Převzetí služeb při selhání placených databází tenantů (9) Podobně po obnovení regionu se staré primarie automaticky stanou sekundárními. Teď se znovu stanou primariemi.
- Nastavte obnovené zkušební databáze, které se změnily v oblasti zotavení po havárii na jen pro čtení (10).
- Pro každou databázi ve fondu zotavení po havárii zákazníků se zkušebními verzemi, které se od obnovení změnily, přejmenujte nebo odstraňte odpovídající databázi v primárním fondu zkušebních zákazníků (11).
- Zkopírujte aktualizované databáze z fondu zotavení po havárii do primárního fondu (12).
- Odstraňte fond zotavení po havárii (13).
Poznámka:
Operace převzetí služeb při selhání je asynchronní. Abyste minimalizovali dobu obnovení, je důležité spustit příkaz převzetí služeb při selhání databáze tenantů v dávkách nejméně 20 databází.
Výhoda
Klíčovou výhodou této strategie je, že poskytuje nejvyšší smlouvu SLA pro platící zákazníky. Zároveň zaručuje, že nové zkušební verze se odblokují hned po vytvoření fondu zkušebních zotavení po havárii.
Kompromis
Kompromisem je, že toto nastavení zvyšuje celkové náklady na databáze tenantů o náklady na sekundární fond zotavení po havárii pro placené zákazníky. Kromě toho platí, že pokud má sekundární fond jinou velikost, dochází k nižšímu výkonu po převzetí služeb při selhání, dokud se upgrade fondu v oblasti zotavení po havárii nedokončí.
Scénář 3. Geograficky distribuovaná aplikace s vrstvenou službou
Mám vyspělou aplikaci SaaS s nabídkami vrstvených služeb. Chci svým placeným zákazníkům nabídnout velmi agresivní smlouvu SLA a minimalizovat riziko dopadu výpadků, protože dokonce i krátké přerušení může způsobit nespokojení zákazníků. Je důležité, aby platební zákazníci měli vždy přístup ke svým datům. Zkušební verze jsou bezplatné a během zkušebního období se nenabízí smlouva SLA.
Pro podporu tohoto scénáře použijte tři samostatné elastické fondy. Zřiďte dva fondy se stejnou velikostí s velkými eDTU nebo virtuálními jádry na databázi ve dvou různých oblastech, aby obsahovaly databáze tenantů placených zákazníků. Třetí fond obsahující zkušební tenanty může mít nižší počet eDTU nebo virtuálních jader na databázi a zřídit ho v jedné ze dvou oblastí.
Aby se zajistilo nejnižší doba obnovení během výpadků, databáze tenantů platících zákazníků se geograficky replikují s 50 % primárních databází v každé ze dvou oblastí. Podobně má každá oblast 50 % sekundárních databází. Pokud je oblast offline, ovlivní se to jenom 50 % databází placených zákazníků a musí převzít služby při selhání. Ostatní databáze zůstanou nedotčené. Tato konfigurace je znázorněna v následujícím diagramu:
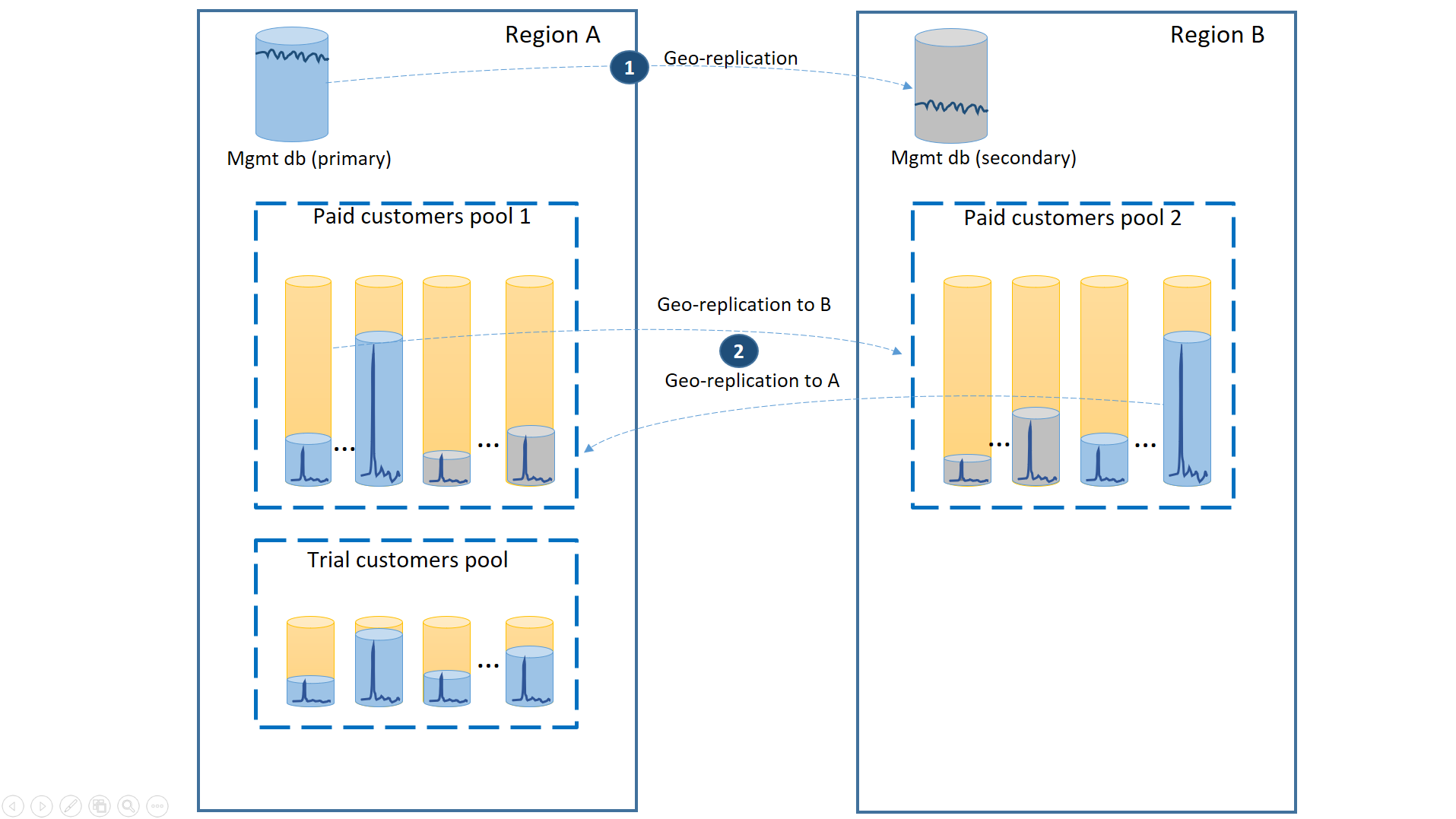
Stejně jako v předchozích scénářích jsou databáze pro správu poměrně aktivní, takže je nakonfigurujte jako izolované geograficky replikované databáze (1). Tím zajistíte předvídatelný výkon nových zákaznických předplatných, aktualizací profilu a dalších operací správy. Oblast A je primární oblastí pro databáze pro správu a oblast B se používá k obnovení databází pro správu.
Databáze tenantů platících zákazníků se také geograficky replikují, ale s primárními a sekundárními databázemi rozdělenými mezi oblast A a oblastí B (2). Primární databáze tenanta ovlivněné výpadkem tak můžou převzít služby při selhání do jiné oblasti a být dostupné. Na druhou polovinu databází tenantů to vůbec nemá vliv.
Následující diagram znázorňuje kroky obnovení, které se mají provést, pokud dojde k výpadku v oblasti A.
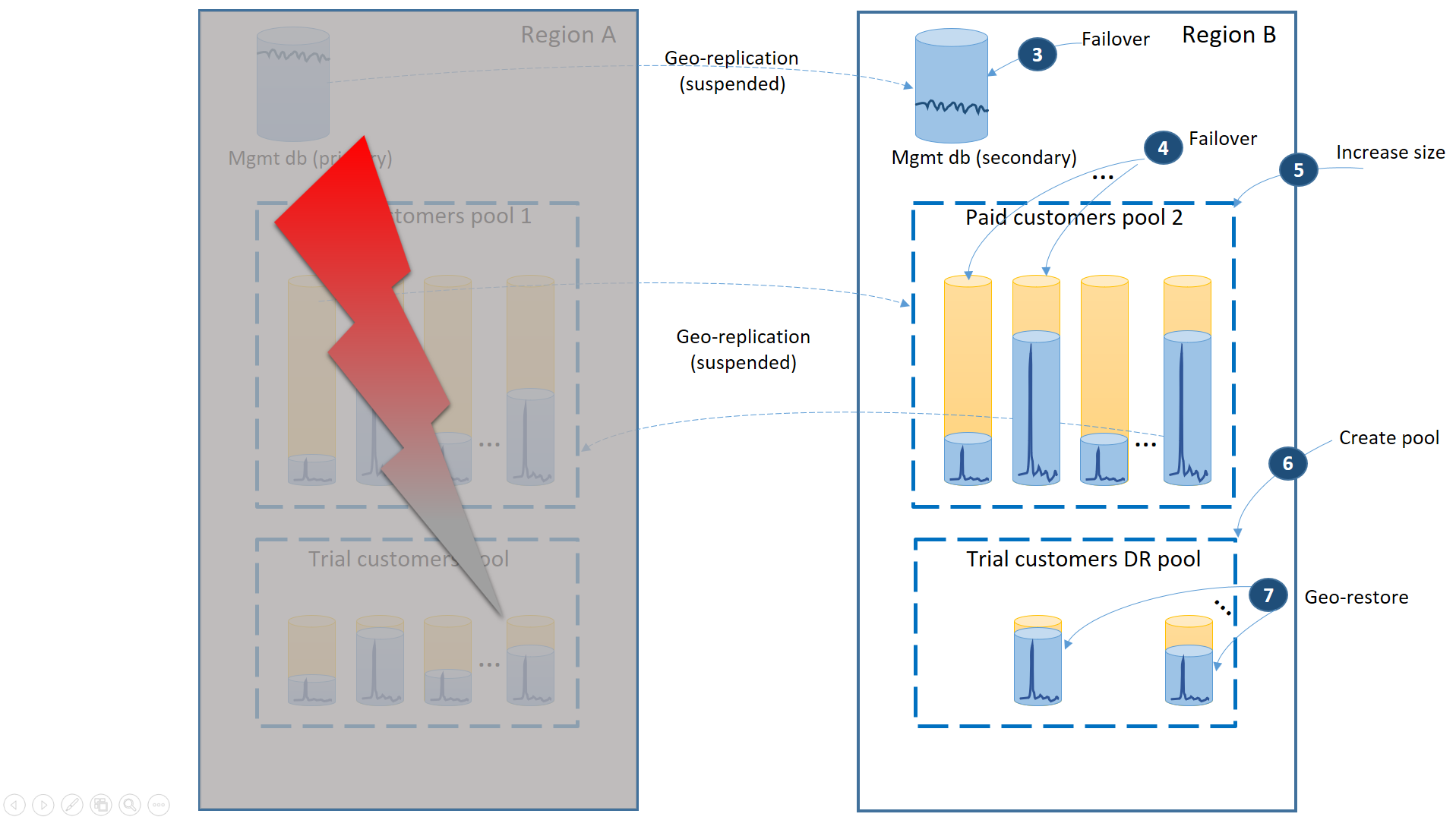
- Okamžitě převezme služby při selhání databází pro správu do oblasti B (3).
- Změňte připojovací řetězec aplikace tak, aby odkazovat na databáze pro správu v oblasti B. Upravte databáze pro správu, aby se zajistilo, že se v oblasti B vytvoří nové účty a databáze tenantů a také existující databáze tenantů. Stávající zákazníci zkušební verze uvidí data dočasně nedostupná.
- Převzetí služeb při selhání databází placeného tenanta do fondu 2 v oblasti B, aby se okamžitě obnovila jejich dostupnost (4). Vzhledem k tomu, že převzetí služeb při selhání je rychlá změna na úrovni metadat, můžete zvážit optimalizaci, kdy se jednotlivá převzetí služeb při selhání aktivují na vyžádání připojeními koncových uživatelů.
- Vzhledem k tomu, že fond 2 obsahuje pouze primární databáze, celková úloha ve fondu se zvyšuje a může okamžitě zvýšit velikost eDTU (5) nebo počet virtuálních jader.
- Vytvořte nový elastický fond se stejným názvem a stejnou konfigurací v oblasti B pro databáze zkušebních zákazníků (6).
- Po vytvoření fondu pomocí geografického obnovení obnovte databázi individuálního zkušebního tenanta do fondu (7). Můžete zvážit aktivaci jednotlivých obnovení pomocí připojení koncových uživatelů nebo použít jiné schéma priority specifické pro aplikaci.
Poznámka:
Operace převzetí služeb při selhání je asynchronní. Pokud chcete minimalizovat dobu obnovení, je důležité spustit příkaz převzetí služeb při selhání databází tenantů v dávkách nejméně 20 databází.
V tuto chvíli je vaše aplikace opět online v oblasti B. Všichni platící zákazníci mají přístup ke svým datům, zatímco zkušební verze se při přístupu ke svým datům zpozdí.
Když je oblast A obnovena, musíte se rozhodnout, jestli chcete použít oblast B pro zkušební zákazníky nebo navrácení služeb po obnovení k používání fondu zkušebních zákazníků v oblasti A. Jedním z kritérií může být % zkušebních databází tenantů upravených od obnovení. Bez ohledu na toto rozhodnutí je potřeba znovu vyvážit placené tenanty mezi dvěma fondy. Následující diagram znázorňuje proces, kdy se zkušební databáze tenantů vrátí do oblasti A.
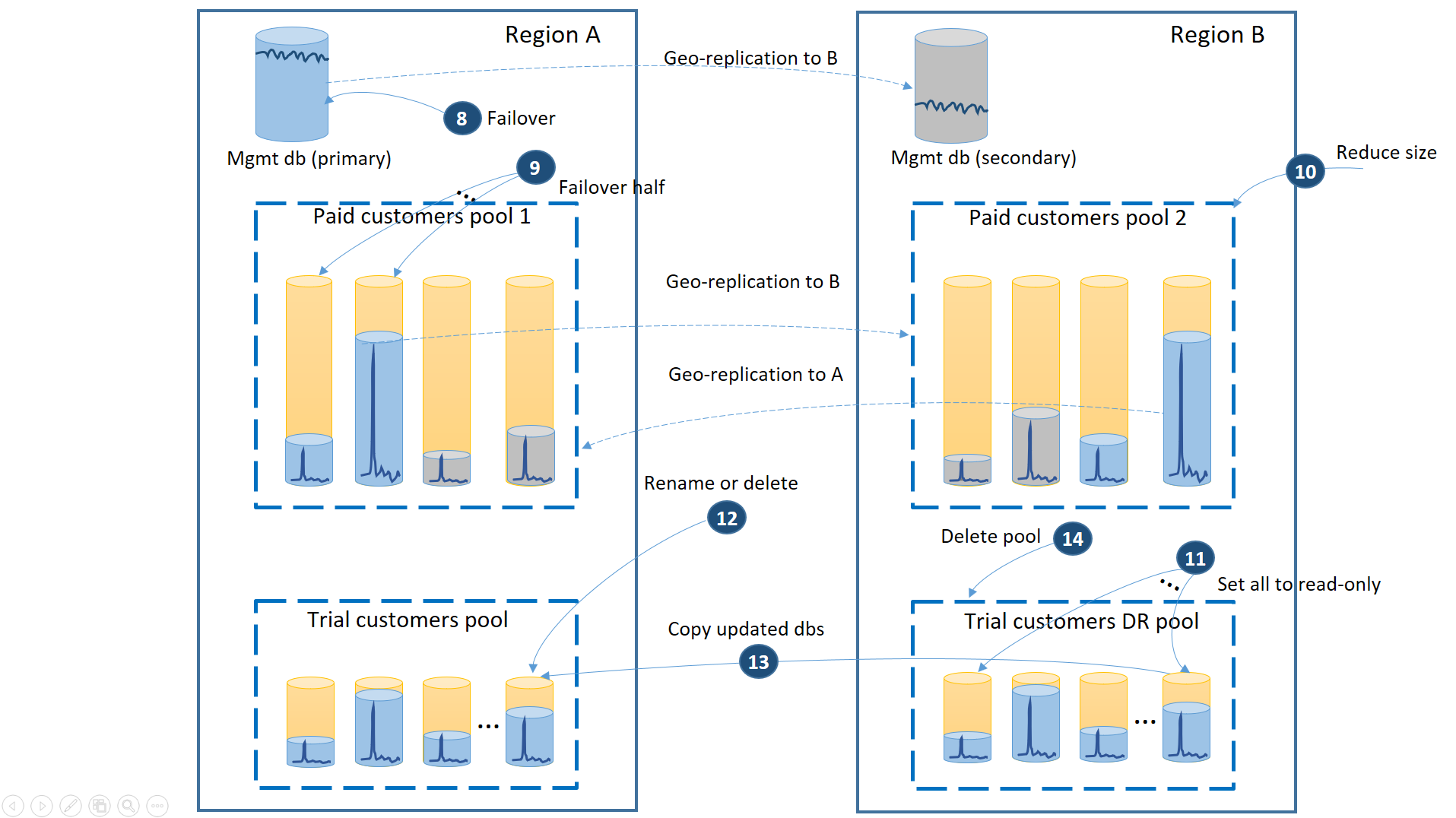
- Zrušte všechny nevyřízených žádostí o geografické obnovení do fondu zotavení po havárii.
- Převzetí služeb při selhání databáze pro správu (8) Po obnovení oblasti se původní primární server automaticky stal sekundárním. Teď se stane primárním.
- Vyberte, které placené databáze tenantů po obnovení do fondu 1, a zahájí převzetí služeb při selhání do sekundárních databází (9). Po obnovení oblasti se všechny databáze ve fondu 1 automaticky staly sekundárními. Nyní se 50 % z nich stává znovu primariemi.
- Zmenšete velikost fondu 2 na původní eDTU (10) nebo počet virtuálních jader.
- Nastavte všechny obnovené zkušební databáze v oblasti B na jen pro čtení (11).
- Pro každou databázi ve fondu zkušebních zotavení po havárii, která se od obnovení změnila, přejmenujte nebo odstraňte odpovídající databázi v primárním fondu zkušební verze (12).
- Zkopírujte aktualizované databáze z fondu zotavení po havárii do primárního fondu (13).
- Odstraňte fond zotavení po havárii (14).
Výhoda
Mezi klíčové výhody této strategie patří:
- Podporuje nejagresivnější smlouvu SLA pro platící zákazníky, protože zajišťuje, že výpadek nemůže ovlivnit více než 50 % databází tenantů.
- Zaručuje, že nové zkušební verze se odblokují, jakmile se během obnovení vytvoří fond zotavení po havárii na konci.
- Umožňuje efektivnější využití kapacity fondu jako 50 % sekundárních databází ve fondu 1 a fondu 2 je zaručeno, že budou méně aktivní než primární databáze.
Kompromisy
Hlavní kompromisy jsou:
- Operace CRUD s databázemi pro správu mají nižší latenci pro koncové uživatele připojené k oblasti A než u koncových uživatelů připojených k oblasti B při jejich provádění v primární databázi pro správu.
- Vyžaduje složitější návrh databáze pro správu. Každý záznam tenanta má například značku umístění, kterou je potřeba změnit při převzetí služeb při selhání a navrácení služeb po obnovení.
- Platící zákazníci můžou dosáhnout nižšího výkonu než obvykle, dokud se upgrade fondu v oblasti B nedokončil.
Shrnutí
Tento článek se zaměřuje na strategie zotavení po havárii pro databázovou vrstvu používanou víceklientské aplikace SaaS ISV. Strategie, kterou zvolíte, vychází z potřeb aplikace, jako je obchodní model, smlouva SLA, kterou chcete zákazníkům nabídnout, omezení rozpočtu atd. Každá popsaná strategie popisuje výhody a kompromisy, takže byste mohli učinit informované rozhodnutí. Vaše konkrétní aplikace pravděpodobně zahrnuje i další komponenty Azure. Proto si prohlédnete pokyny k provozní kontinuitě a orchestrujete obnovení databázové vrstvy s nimi. Další informace o správě obnovení databázových aplikací v Azure najdete v tématu Návrh cloudových řešení pro zotavení po havárii.
Další kroky
- Informace o automatizovaných zálohách služby Azure SQL Database najdete v tématu Automatizované zálohy služby Azure SQL Database.
- Přehled a scénáře provozní kontinuity najdete v přehledu provozní kontinuity.
- Další informace o používání automatizovaných záloh pro obnovení najdete v tématu obnovení databáze ze záloh iniciovaných službou.
- Další informace o rychlejších možnostech obnovení najdete v tématu Aktivní geografická replikace a skupiny převzetí služeb při selhání.
- Další informace o použití automatizovaných záloh pro archivaci najdete v tématu Kopírování databáze.