Inteligentní aplikace
Platí pro:![]() Azure SQL Database SQL Database
Azure SQL Database SQL Database![]() v prostředcích infrastruktury
v prostředcích infrastruktury
Tento článek obsahuje přehled použití možností umělé inteligence (AI), jako jsou OpenAI a vektory, k vytváření inteligentních aplikací s azure SQL Database a databází SQL Fabric, které sdílí řadu těchto funkcí služby Azure SQL Database.
Ukázky a příklady najdete v úložišti ukázek AI SQL.
Podívejte se na toto video v sérii základy Azure SQL Database, kde najdete stručný přehled o vytvoření aplikace připravené pro AI:
Přehled
Velké jazykové modely (LLM) umožňují vývojářům vytvářet aplikace využívající AI se známým uživatelským prostředím.
Použití LLM v aplikacích přináší větší hodnotu a vylepšené uživatelské prostředí, když modely můžou přistupovat ke správným datům ve správný čas z databáze vaší aplikace. Tento proces se označuje jako načítání rozšířené generace (RAG) a databáze Azure SQL Database a Fabric SQL má mnoho funkcí, které tento nový model podporují, takže je skvělou databází pro vytváření inteligentních aplikací.
Následující odkazy poskytují vzorový kód různých možností pro vytváření inteligentních aplikací:
| Možnost AI | Popis |
|---|---|
| Azure OpenAI | Generování vkládání pro RAG a integrace s libovolným modelem podporovaným platformou Azure OpenAI |
| Vektory | Naučte se ukládat vektory databáze a dotazovat je. |
| Azure AI Search | Využijte databázi společně se službou Azure AI Search k trénování LLM na vašich datech. |
| Inteligentní aplikace | Zjistěte, jak vytvořit komplexní řešení pomocí běžného vzoru, který je možné replikovat v libovolném scénáři. |
| Zkopírované dovednosti ve službě Azure SQL Database | Seznamte se se sadou prostředí s asistencí umělé inteligence navrženou tak, aby zjednodušila návrh, provoz, optimalizaci a stav aplikací řízených službou Azure SQL Database. |
| Kopírované dovednosti v databázi SQL Fabric | Seznamte se se sadou prostředí s asistencí umělé inteligence navrženou tak, aby zjednodušila návrh, provoz, optimalizaci a stav databázových aplikací řízených prostředky Infrastruktury SQL. |
Klíčové koncepty implementace RAG s využitím Azure OpenAI
Tato část obsahuje klíčové koncepty, které jsou důležité pro implementaci RAG s Azure OpenAI ve službě Azure SQL Database nebo v databázi SQL Fabric.
Načítání rozšířené generace (RAG)
RAG je technika, která zlepšuje schopnost LLM vytvářet relevantní a informativní odpovědi načtením dalších dat z externích zdrojů. RAG může například dotazovat články nebo dokumenty, které obsahují znalosti specifické pro doménu související s dotazem nebo výzvou uživatele. LLM pak může tato načtená data použít jako referenci při generování odpovědi. Například jednoduchý vzor RAG s využitím Azure SQL Database může být:
- Vloží data do tabulky.
- Propojte Azure SQL Database s Azure AI Search.
- Vytvořte model Azure OpenAI GPT4 a připojte ho ke službě Azure AI Search.
- Chatujte a ptejte se na data pomocí natrénovaného modelu Azure OpenAI z vaší aplikace a azure SQL Database.
Model RAG s výzvou technikou slouží k vylepšení kvality odezvy tím, že model nabízí více kontextových informací. RAG umožňuje modelu použít širší znalostní bázi začleněním relevantních externích zdrojů do procesu generování, což vede k komplexnějším a informovanějším odpovědím. Další informace o uzemnění LLM naleznete v tématu Grounding LLMs - Microsoft Community Hub.
Výzvy a výzva k technickému zpracování
Výzva odkazuje na konkrétní text nebo informace, které slouží jako instrukce pro LLM, nebo jako kontextová data, na kterých může LLM vycházet. Výzva může mít různé formy, například otázku, příkaz nebo dokonce fragment kódu.
Ukázkové výzvy, které je možné použít k vygenerování odpovědi z LLM:
- Pokyny: poskytnutí direktiv pro LLM
- Primární obsah: poskytuje informace LLM ke zpracování.
- Příklady: Podmínka nápovědy modelu k určitému úkolu nebo procesu
- Upozornění: směrujte výstup LLM správným směrem.
- Podpůrný obsah: představuje doplňující informace, které LLM může použít k vygenerování výstupu.
Proces vytváření vhodných výzev pro scénář se nazývá prompt engineering. Další informace o výzev a osvědčených postupech pro přípravu výzev najdete v tématu Azure OpenAI Service.
Tokeny
Tokeny jsou malé bloky textu vygenerované rozdělením vstupního textu na menší segmenty. Tyto segmenty můžou být slova nebo skupiny znaků, které se liší délkou od jednoho znaku po celé slovo. Například slovo hamburger by bylo rozděleno na tokeny, jako hamje , bura ger zatímco krátké a běžné slovo jako pear by bylo považováno za jeden token.
V Azure OpenAI se vstupní text zadaný do rozhraní API změní na tokeny (tokenizované). Počet tokenů zpracovaných v každém požadavku rozhraní API závisí na faktorech, jako je délka vstupu, výstupu a parametrů požadavku. Množství zpracovávaných tokenů má vliv také na dobu odezvy a propustnost modelů. Počet tokenů, které každý model může přijmout v jednom požadavku nebo odpovědi z Azure OpenAI, existuje omezení. Další informace najdete v tématu Kvóty a omezení služby Azure OpenAI.
Vektory
Vektory jsou uspořádaná pole čísel (obvykle float), která mohou představovat informace o některých datech. Obrázek může být například reprezentován jako vektor hodnot pixelů nebo řetězec textu může být reprezentován jako vektor nebo hodnoty ASCII. Proces převodu dat na vektor se nazývá vektorizace. Další informace naleznete v tématu Vektory.
Vkládání
Vkládání jsou vektory, které představují důležité funkce dat. Vkládání se často učí pomocí modelu hlubokého učení a modely strojového učení a AI je využívají jako funkce. Vkládání může také zachytit sémantickou podobnost mezi podobnými koncepty. Například při generování vkládání pro slova person a humanbychom očekávali, že jejich vkládání (reprezentace vektorů) bude podobné hodnotě, protože slova jsou také sémanticky podobná.
Azure OpenAI nabízí modely pro vytváření vložených dat z textových dat. Služba rozdělí text na tokeny a vygeneruje vkládání pomocí modelů předem natrénovaných metodou OpenAI. Další informace najdete v tématu Vytváření vložených objektů pomocí Azure OpenAI.
Vektorové vyhledávání
Vektorové vyhledávání odkazuje na proces hledání všech vektorů v datové sadě, které jsou sémanticky podobné konkrétnímu vektoru dotazu. Proto vektor dotazu pro slovo human hledá v celém slovníku sémanticky podobná slova a měl by najít slovo person jako blízkou shodu. Tato blízkost nebo vzdálenost se měří pomocí metriky podobnosti, jako je kosinus podobnost. Bližší vektory jsou v podobnosti, menší je vzdálenost mezi nimi.
Představte si scénář, ve kterém spustíte dotaz na miliony dokumentů, abyste našli ty nejpodobnější dokumenty ve vašich datech. Vkládání dat a dotazování dokumentů můžete vytvářet pomocí Azure OpenAI. Pak můžete pomocí vektorového vyhledávání najít ty nejpodobnější dokumenty z vaší datové sady. Provedení vektorového vyhledávání v několika příkladech je ale triviální. Provádění tohoto stejného hledání napříč tisíci nebo miliony datových bodů je náročné. Existují také kompromisy mezi vyčerpávajícími metodami vyhledávání a přibližným nejbližším sousedem (ANN), včetně latence, propustnosti, přesnosti a nákladů, z nichž všechny závisí na požadavcích vaší aplikace.
Vektory ve službě Azure SQL Database je možné efektivně ukládat a dotazovat, jak je popsáno v dalších částech, což umožňuje přesné hledání nejbližších sousedů s velkým výkonem. Nemusíte se rozhodovat mezi přesností a rychlostí: můžete mít obojí. Ukládání vektorových vkládání společně s daty v integrovaném řešení minimalizuje potřebu správy synchronizace dat a zrychluje váš čas na trh vývoje aplikací AI.
Azure OpenAI
Vkládání je proces reprezentace skutečného světa jako dat. Text, obrázky nebo zvuky se dají převést na vkládání. Modely Azure OpenAI umožňují transformovat skutečné informace na vkládání. Modely jsou k dispozici jako koncové body REST, takže je možné snadno využívat ze služby Azure SQL Database pomocí sp_invoke_external_rest_endpoint systémové uložené procedury:
DECLARE @retval INT, @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX);
SET @payload = JSON_OBJECT('input': @text);
EXEC @retval = sp_invoke_external_rest_endpoint @url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
SELECT CAST([key] AS INT) AS [vector_value_id],
CAST([value] AS FLOAT) AS [vector_value]
FROM OPENJSON(JSON_QUERY(@response, '$.result.data[0].embedding'));
Volání služby REST pro získání vkládání je jen jednou z možností integrace, které máte při práci se službou SQL Database a OpenAI. K datům uloženým ve službě Azure SQL Database můžete přistupovat libovolný z dostupných modelů , abyste vytvořili řešení, ve kterých můžou uživatelé s daty pracovat, například v následujícím příkladu.
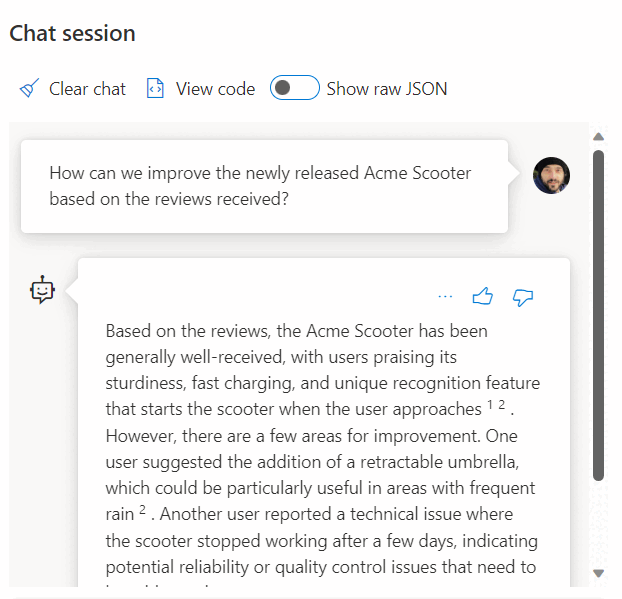
Další příklady použití služby SQL Database a OpenAI najdete v následujících článcích:
- Generování imagí pomocí služby Azure OpenAI (DALL-E) a Azure SQL Database
- Použití koncových bodů REST OpenAI se službou Azure SQL Database
Vektory
Datový typ vektoru
V listopadu 2024 byl v Azure SQL Database zaveden nový datový typ vektoru .
Vyhrazený typ vektoru umožňuje efektivní a optimalizované ukládání vektorových dat a dodává se se sadou funkcí, které vývojářům pomáhají zjednodušit implementaci vektoru a podobnosti hledání. Výpočet vzdálenosti mezi dvěma vektory lze provádět v jednom řádku kódu pomocí nové VECTOR_DISTANCE funkce. Další informace o datovém typu vektoru a souvisejících funkcích naleznete v tématu Přehled vektorů v databázovém stroji SQL.
Příklad:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[embedding] [vector](1536) NOT NULL,
)
GO
SELECT TOP(10)
*
FROM
[dbo].[wikipedia_articles_embeddings_titles_vector]
ORDER BY
VECTOR_DISTANCE('cosine', @my_reference_vector, embedding)
Vektory ve starších verzích SQL Serveru
I když starší verze modulu SQL Serveru, až do a včetně SQL Serveru 2022, nemají nativní typ vektoru , vektor není nic víc než seřazená řazená řazená kolekce členů a relační databáze jsou skvělé při správě řazených kolekcí členů. Řazenou kolekci členů si můžete představit jako formální termín pro řádek v tabulce.
Azure SQL Database podporuje také indexy columnstore a spouštění dávkového režimu. Přístup založený na vektorech se používá ke zpracování dávkového režimu, což znamená, že každý sloupec v dávce má své vlastní umístění paměti, kde je uložený jako vektor. To umožňuje rychlejší a efektivnější zpracování dat v dávkách.
Následující příklad ukazuje, jak lze vektor uložit ve službě SQL Database:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[vector_value_id] [int] NOT NULL,
[vector_value] [float] NOT NULL
)
GO
CREATE CLUSTERED COLUMNSTORE INDEX ixc
ON dbo.wikipedia_articles_embeddings_titles_vector
ORDER (article_id);
GO
Příklad, který používá společnou podmnožinu článků Wikipedie s vloženými už vygenerovanými pomocí OpenAI, najdete v tématu Hledání vektorové podobnosti se službou Azure SQL Database a OpenAI.
Další možností využití služby Vector Search v databázi Azure SQL je integrace s Azure AI s využitím integrovaných funkcí vektorizace: Vector Search se službou Azure SQL Database a Azure AI Search.
Azure AI Vyhledávač
Implementujte vzory RAG ve službě Azure SQL Database a Azure AI Search. Podporované modely chatu můžete spouštět na datech uložených ve službě Azure SQL Database, aniž byste museli trénovat nebo doladit modely díky integraci služby Azure AI Search s Azure OpenAI a Azure SQL Database. Spouštění modelů na datech umožňuje chatovat nad daty a analyzovat data s větší přesností a rychlostí.
- Azure OpenAI na vašich datech
- Načítání rozšířené generace (RAG) ve službě Azure AI Search
- Vektorové vyhledávání s využitím Azure SQL Database a Azure AI Search
Inteligentní aplikace
Azure SQL Database se dá použít k vytváření inteligentních aplikací, které zahrnují funkce AI, jako jsou doporučovací nástroje, a načítání rozšířené generace (RAG), jak ukazuje následující diagram:

Kompletní ukázku pro sestavení aplikace s podporou AI s využitím relací abstraktních jako ukázkové datové sady najdete tady:
- Jak jsem pomocí OpenAI vytvořil(a) doporučovací nástroj relace za 1 hodinu.
- Vytvoření pomocníka pro relace konference pomocí rozšířené generace načítání
Integrace jazyka LangChain
LangChain je dobře známá architektura pro vývoj aplikací využívajících jazykové modely. Příklady, které ukazují, jak se dá LangChain použít k vytvoření chatovacího robota na vlastních datech, najdete tady:
- langchain-sqlserver balíček PyPI
Několik ukázek použití Azure SQL s jazykem LangChain:
Kompletní příklady:
- Vytvořte chatovacího robota na vlastních datech za 1 hodinu pomocí Azure SQL, Langchain a Chainlit: Vytvořte chatovacího robota pomocí vzoru RAG na vlastních datech pomocí Langchainu pro orchestraci volání LLM a Chainlit pro uživatelské rozhraní.
- Vytvoření vlastního objektu Copilot pro Azure SQL pomocí Azure OpenAI GPT-4: Vytvořte prostředí podobné kopírování pro dotazování databází pomocí přirozeného jazyka.
Sémantická integrace jádra
Sémantické jádro je opensourcová sada SDK , která umožňuje snadno vytvářet agenty, kteří můžou volat váš existující kód. Jako vysoce rozšiřitelná sada SDK můžete použít sémantické jádro s modely z OpenAI, Azure OpenAI, Hugging Face a dalších. Kombinací stávajícího kódu C#, Pythonu a Javy s těmito modely můžete vytvářet agenty, kteří zodpovídají na otázky a automatizují procesy.
Tady je příklad, jak snadné sémantické jádro pomáhá sestavovat řešení s podporou AI:
- Konečný chatovací robot?: Vytvořte chatovacího robota na vlastních datech pomocí vzorů NL2SQL i RAG pro dokonalé uživatelské prostředí.
Dovednosti Microsoft Copilotu ve službě Azure SQL Database
Dovednosti Microsoft Copilotu ve službě Azure SQL Database (Preview) jsou sada prostředí s asistencí umělé inteligence navržená tak, aby zjednodušila návrh, provoz, optimalizaci a stav aplikací řízených službou Azure SQL Database. Copilot může zvýšit produktivitu tím, že nabízí přirozený jazyk pro převod SQL a samoobslužnou podporu pro správu databáze.
Copilot poskytuje relevantní odpovědi na dotazy uživatelů, zjednodušení správy databází díky využití kontextu databáze, dokumentace, zobrazení dynamické správy, úložiště dotazů a dalších zdrojů znalostí. Příklad:
- Správci databází můžou nezávisle spravovat databáze a řešit problémy nebo získat další informace o výkonu a možnostech databáze.
- Vývojáři se můžou ptát na svá data stejně jako v textu nebo konverzaci, aby vygenerovali dotaz T-SQL. Vývojáři se také můžou naučit psát dotazy rychleji prostřednictvím podrobných vysvětlení vygenerovaného dotazu.
Poznámka:
Dovednosti Microsoft Copilotu ve službě Azure SQL Database jsou v současné době ve verzi Preview pro omezený počet počátečních osvojujících. Pokud se chcete zaregistrovat k tomuto programu, přejděte na žádost o přístup ke copilotu ve službě Azure SQL Database: Preview.
Verze Preview copilotu pro Azure SQL Database zahrnuje dvě prostředí webu Azure Portal:
| Umístění portálu | Prostředí |
|---|---|
| Editor Power Query webu Azure Portal | Přirozený jazyk SQL: Toto prostředí v editoru dotazů webu Azure Portal pro Azure SQL Database překládá dotazy přirozeného jazyka do SQL, což usnadňuje intuitivnější interakci s databázemi. Pro kurz a příklady schopností převodu přirozeného jazyka na SQL se podívejte na sekci Přirozený jazyk na SQL v editoru dotazů portálu Azure (preview). |
| Microsoft Copilot pro Azure | Integrace Azure Copilotu: Toto prostředí přidává dovednosti Azure SQL do Microsoft Copilotu pro Azure, poskytuje zákazníkům samoobslužnou pomoc a umožňuje jim spravovat své databáze a řešit problémy nezávisle. |
Další informace najdete v tématu Nejčastější dotazy týkající se dovedností Microsoft Copilotu ve službě Azure SQL Database (Preview).
Dovednosti Microsoft Copilotu v databázi SQL Fabric (Preview)
Copilot pro databázi SQL v Microsoft Fabric (Preview) zahrnuje integrovanou pomoc s AI s následujícími funkcemi:
Dokončování kódu: Začněte psát T-SQL v editoru dotazů SQL a Copilot automaticky vygeneruje návrh kódu, který vám pomůže dokončit dotaz. Klávesa Tab přijme návrh kódu nebo ho pořád píše, aby návrh ignoroval.
Rychlé akce: Na pásu karet editoru dotazů SQL jsou možnosti Opravit a Vysvětlit rychlé akce. Zvýrazněte dotaz SQL podle svého výběru a vyberte jedno z tlačítek rychlých akcí k provedení vybrané akce s dotazem.
Oprava: Copilot může opravit chyby v kódu při vzniku chybových zpráv. Chybové scénáře můžou zahrnovat nesprávný nebo nepodporovaný kód T-SQL, nesprávné pravopisy a další. Copilot také poskytne komentáře, které vysvětlují změny a navrhují osvědčené postupy SQL.
Vysvětlení: Copilot může poskytovat vysvětlení schématu dotazů a databází SQL ve formátu komentářů.
Podokno chatu: Pomocí podokna chatu můžete klást otázky na Copilot prostřednictvím přirozeného jazyka. Copilot odpoví vygenerovaným dotazem SQL nebo přirozeným jazykem na základě položené otázky.
Přirozený jazyk SQL: Vygenerujte kód T-SQL z požadavků na prostý text a získejte návrhy otázek, které se mají zeptat, aby se urychlil pracovní postup.
Otázka založená na dokumentech: Ptejte se na obecné možnosti databáze SQL a odpovídá v přirozeném jazyce. Copilot také pomáhá najít dokumentaci související s vaší žádostí.
Copilot pro databázi SQL využívá názvy tabulek a zobrazení, názvy sloupců, primární klíč a metadata cizího klíče k vygenerování kódu T-SQL. Copilot pro databázi SQL nepoužívá data v tabulkách k vygenerování návrhů T-SQL.