Zvýšení odolnosti replikací pracovního prostoru služby Log Analytics napříč oblastmi (Preview)
Replikace pracovního prostoru služby Log Analytics napříč oblastmi zvyšuje odolnost tím, že umožňuje přepnout do replikovaného pracovního prostoru a pokračovat v operacích, pokud dojde k selhání oblasti. Tento článek vysvětluje, jak funguje replikace pracovního prostoru služby Log Analytics, jak replikovat pracovní prostor, jak přepnout a zpět a jak se rozhodnout, kdy mezi replikovanými pracovními prostory přepínat.
Tady je video, které poskytuje rychlý přehled toho, jak funguje replikace pracovního prostoru služby Log Analytics:
Důležité
I když někdy používáme termín převzetí služeb při selhání, například ve volání rozhraní API, převzetí služeb při selhání se často používá i k popisu automatického procesu. Proto tento článek používá přechod termínu k zdůraznění, že přepnutí do replikovaného pracovního prostoru je akce, kterou aktivujete ručně.
Jak funguje replikace pracovního prostoru služby Log Analytics
Váš původní pracovní prostor a oblast se označují jako primární. Replikovaný pracovní prostor a alternativní oblast se označují jako sekundární.
Proces replikace pracovního prostoru vytvoří instanci vašeho pracovního prostoru v sekundární oblasti. Tento proces vytvoří sekundární pracovní prostor se stejnou konfigurací jako primární pracovní prostor a Azure Monitor automaticky aktualizuje sekundární pracovní prostor všemi budoucími změnami, které provedete v konfiguraci primárního pracovního prostoru.
Sekundární pracovní prostor je "stínový" pracovní prostor pouze pro účely odolnosti. Sekundární pracovní prostor se na webu Azure Portal nezobrazuje a nemůžete k němu přímo přistupovat.
Když povolíte replikaci pracovního prostoru, Azure Monitor odesílá nové protokoly ingestované do primárního pracovního prostoru také do sekundární oblasti. Protokoly, které ingestujete do pracovního prostoru, než povolíte replikaci pracovního prostoru, se nezkopírují.
Pokud výpadek ovlivní vaši primární oblast, můžete přepnout a přesměrovat všechny požadavky na příjem dat a dotazy do sekundární oblasti. Jakmile Azure zmírní výpadek a váš primární pracovní prostor bude znovu v pořádku, můžete přepnout zpět do primární oblasti.
Když přepnete, sekundární pracovní prostor se aktivuje a primární pracovní prostor bude neaktivní. Azure Monitor pak ingestuje nová data prostřednictvím kanálu příjmu dat ve vaší sekundární oblasti, nikoli primární oblasti. Když přepnete do sekundární oblasti, Azure Monitor replikuje všechna data, která ingestujete ze sekundární oblasti do primární oblasti. Proces je asynchronní a nemá vliv na latenci příjmu dat.
Poznámka:
Pokud primární oblast nemůže zpracovávat příchozí data protokolu, Azure Monitor po přepnutí na sekundární oblast do vyrovnávací paměti data v sekundární oblasti po dobu až 11 dnů. Během prvních čtyř dnů se Azure Monitor automaticky znovu pokusí replikovat data pravidelně.

Ochrana před ztrátou přenášených dat během regionálního selhání
Azure Monitor má několik mechanismů, které zajišťují, aby se při selhání v primární oblasti neztratila přenášená data.
Azure Monitor chrání data, která dosáhnou koncového bodu příjmu primární oblasti, když kanál primární oblasti není k dispozici ke zpracování dat. Jakmile bude kanál dostupný, bude dál zpracovávat přenášená data a Azure Monitor ingestuje a replikuje data do sekundární oblasti.
Pokud koncový bod příjmu primární oblasti není dostupný, agent služby Azure Monitor pravidelně opakuje odesílání dat protokolu do koncového bodu. Koncový bod příjmu dat v sekundární oblasti začne přijímat data z agentů několik minut po aktivaci přechodu.
Pokud napíšete vlastního klienta pro odesílání dat protokolů do pracovního prostoru služby Log Analytics, ujistěte se, že klient zpracovává neúspěšné žádosti o příjem dat.
Aspekty nasazení
Replikace pracovních prostorů služby Log Analytics propojených s vyhrazeným clusterem se v současné době nepodporuje.
Operace vymazání, která odstraní záznamy z pracovního prostoru, odebere relevantní záznamy z primárního i sekundárního pracovního prostoru. Pokud jedna z instancí pracovního prostoru není dostupná, operace vyprázdnění selže.
Azure Monitor podporuje dotazování neaktivní oblasti. Upozornění založená na dotazech budou dál fungovat, když přepnete mezi oblastmi, pokud služba Upozornění v aktivní oblasti nefunguje správně nebo nejsou dostupná pravidla upozornění. Replikace pravidel upozornění napříč oblastmi se v současné době nepodporuje.
Když povolíte replikaci pro pracovní prostory, které pracují se službou Sentinel, může úplné replikace dat sledovacího seznamu a analýzy hrozeb do sekundárního pracovního prostoru trvat až 12 dnů.
Během přechodu nejde zahájit operace správy pracovních prostorů, včetně následujících:
- Změna uchovávání pracovních prostorů, cenové úrovně, denního limitu atd.
- Změna nastavení sítě
- Změna schématu prostřednictvím nových vlastních protokolů nebo připojení protokolů platformy od nových poskytovatelů prostředků, jako je odesílání diagnostických protokolů z nového typu prostředku
Funkce cílení na řešení starší verze agenta Log Analytics se během přechodu nepodporuje. Během přechodu se data řešení ingestují ze všech agentů.
Proces převzetí služeb při selhání aktualizuje záznamy DNS (Domain Name System), aby se všechny požadavky na příjem dat přesměrovály do sekundární oblasti pro zpracování. Někteří klienti HTTP mají "sticky connections" a může trvat déle, než převezme aktualizovaný DNS DNS. Během přechodu se tito klienti můžou po nějakou dobu pokusit ingestovat protokoly prostřednictvím primární oblasti. Protokoly můžete ingestovat do primárního pracovního prostoru pomocí různých klientů, včetně starší verze agenta Log Analytics, agenta služby Azure Monitor, kódu (pomocí rozhraní API pro příjem protokolů nebo starší verze rozhraní API pro shromažďování dat HTTP) a dalších služeb, jako je Microsoft Sentinel.
Tyto funkce se v současné době nepodporují nebo pouze částečně podporují:
Funkce Technická podpora Pomocné plány tabulek Nepodporováno Azure Monitor nereplikuje data v tabulkách s plánem pomocných protokolů do sekundárního pracovního prostoru. Tato data proto nejsou chráněná před ztrátou dat v případě selhání oblasti a nejsou dostupná, když přepnete do sekundárního pracovního prostoru. Úlohy hledání, obnovení Částečně podporovaná – Operace vyhledávání a obnovení vytvářejí tabulky a naplňují je výsledky hledání nebo obnovenými daty. Po povolení replikace pracovního prostoru se nové tabulky vytvořené pro tyto operace replikují do sekundárního pracovního prostoru. Tabulky vyplněné před povolením replikace se nereplikují. Pokud tyto operace probíhají při přepnutí, výsledek je neočekávaný. Může se úspěšně dokončit, ale ne replikovat nebo může selhat v závislosti na stavu vašeho pracovního prostoru a přesném načasování. Application Insights přes pracovní prostory Log Analytics Nepodporováno Přehledy virtuálních počítačů Nepodporováno Container Insights Nepodporováno Privátní propojení Nepodporuje se při převzetí služeb při selhání.
Podporované oblasti
Replikace pracovního prostoru se v současné době podporuje pro pracovní prostory v omezené sadě oblastí uspořádaných podle skupin oblastí (skupiny geograficky sousedních oblastí). Když povolíte replikaci, vyberte sekundární umístění ze seznamu podporovaných oblastí ve stejné skupině oblastí jako primární umístění pracovního prostoru. Například pracovní prostor v oblasti Západní Evropa se dá replikovat v oblasti Severní Evropa, ale ne v oblasti USA – západ 2, protože tyto oblasti jsou v různých skupinách oblastí.
V současné době se podporují tyto skupiny oblastí a oblasti:
| Skupina oblastí | Oblasti | Notes | ||
|---|---|---|---|---|
| Severní Amerika | USA – východ | USA – východ nemůže replikovat do oblastí USA – východ 2 a USA – středojižní. | ||
| USA – východ 2 | USA – východ 2 se nedají replikovat do oblastí USA – východ a USA – středojiž. | |||
| USA – západ | ||||
| Západní USA 2 | ||||
| USA – střed | ||||
| Středojižní USA | USA – středojiž se nedají replikovat do oblastí USA – východ a USA – východ 2. | |||
| Střední Kanada | ||||
| Evropě | Západní Evropa | |||
| Severní Evropa | ||||
| Velká Británie – jih | ||||
| Velká Británie – západ | ||||
| Německo – středozápad | ||||
| Francie – střed |
Požadavky na rezidenci dat
Různí zákazníci mají různé požadavky na rezidenci dat, takže je důležité řídit, kam se data ukládají. Azure Monitor zpracovává a ukládá protokoly v primárních a sekundárních oblastech, které zvolíte. Další informace najdete v tématu Podporované oblasti.
Podpora pro Microsoft Sentinel a další služby
Různé služby a funkce, které používají pracovní prostory služby Log Analytics, jsou kompatibilní s replikací a přepnutím pracovního prostoru. Tyto služby a funkce budou dál fungovat, když přepnete do sekundárního pracovního prostoru.
Například problémy s regionální sítí, které způsobují latenci příjmu protokolů, můžou mít vliv na zákazníky Microsoft Sentinelu. Zákazníci, kteří používají replikované pracovní prostory, můžou přejít do sekundární oblasti a pokračovat v práci s pracovním prostorem služby Log Analytics a službou Sentinel. Pokud ale problém se sítí ovlivňuje stav služby Sentinel, přepnutí do jiné oblasti problém nezmírní.
Některá prostředí Azure Monitoru, včetně Application Insights a VM Insights, jsou v současné době pouze částečně kompatibilní s replikací a přepnutím pracovního prostoru. Úplný seznam najdete v tématu Důležité informace o nasazení.
Cenový model
Když povolíte replikaci pracovního prostoru, budou se vám účtovat replikace všech dat, která ingestujete do svého pracovního prostoru.
Důležité
Pokud odesíláte data do pracovního prostoru pomocí agenta služby Azure Monitor, rozhraní API pro příjem protokolů, služby Azure Event Hubs nebo jiných zdrojů dat, které používají pravidla shromažďování dat, nezapomeňte svá pravidla shromažďování dat přidružit ke koncovému bodu shromažďování dat vašeho pracovního prostoru. Toto přidružení zajišťuje, že se data, která ingestujete, replikují do sekundárního pracovního prostoru. Pokud nepřidružíte pravidla shromažďování dat ke koncovému bodu shromažďování dat pracovního prostoru, budou se vám stále účtovat všechna data, která ingestujete do pracovního prostoru, i když se data nereplikují.
Požadována oprávnění
| Akce | Požadována oprávnění |
|---|---|
| Povolení replikace pracovního prostoru |
Microsoft.OperationalInsights/workspaces/write a Microsoft.Insights/dataCollectionEndpoints/write oprávnění, která poskytuje předdefinovaná role Přispěvatel monitorování, například |
| Přepnutí zpět a přepnutí zpět (aktivace převzetí služeb při selhání a navrácení služeb po obnovení) |
Microsoft.OperationalInsights/locations/workspaces/failover, Microsoft.OperationalInsights/workspaces/failback, Microsoft.Insights/dataCollectionEndpoints/triggerFailover/actiona Microsoft.Insights/dataCollectionEndpoints/triggerFailback/action oprávnění, jak poskytuje předdefinovaná role Přispěvatel monitorování, například |
| Kontrola stavu pracovního prostoru |
Microsoft.OperationalInsights/workspaces/read oprávnění k pracovnímu prostoru služby Log Analytics, jak poskytuje předdefinovaná role Přispěvatel monitorování, například |
Povolení a zakázání replikace pracovního prostoru
Replikaci pracovního prostoru povolíte a zakážete pomocí příkazu REST. Příkaz aktivuje dlouho běžící operaci, což znamená, že použití nového nastavení může trvat několik minut. Po povolení replikace může trvat až jednu hodinu, než se začnou replikovat všechny tabulky (datové typy) a některé datové typy můžou začít replikovat před ostatními. Změny schémat tabulek po povolení replikace pracovního prostoru – například nové vlastní tabulky protokolů nebo vlastní pole, která vytvoříte, nebo diagnostické protokoly nastavené pro nové typy prostředků – můžou trvat až hodinu, než začne replikace.
Povolení replikace pracovního prostoru
Pokud chcete povolit replikaci v pracovním prostoru služby Log Analytics, použijte tento PUT příkaz:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
Kde:
-
<subscription_id>: ID předplatného související s vaším pracovním prostorem. -
<resourcegroup_name>: Skupina prostředků, která obsahuje váš prostředek pracovního prostoru služby Log Analytics. -
<workspace_name>: Název pracovního prostoru. -
<primary_region>: Primární oblast pracovního prostoru služby Log Analytics. -
<secondary_region>: Oblast, ve které Azure Monitor vytvoří sekundární pracovní prostor.
location Podporované hodnoty najdete v tématu Podporované oblasti.
Příkaz PUT je dlouhotrvající operace, která může nějakou dobu trvat. Úspěšné volání vrátí stavový 200 kód. Stav zřizování žádosti můžete sledovat, jak je popsáno v části Kontrola stavu zřizování požadavků.
Kontrola stavu zřizování požadavků
Pokud chcete zkontrolovat stav zřizování požadavku, spusťte tento GET příkaz:
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
Kde:
-
<subscription_id>: ID předplatného související s vaším pracovním prostorem. -
<resourcegroup_name>: Skupina prostředků, která obsahuje váš prostředek pracovního prostoru služby Log Analytics. -
<workspace_name>: Název pracovního prostoru služby Log Analytics.
GET Pomocí příkazu ověřte, že se stav zřizování pracovního prostoru změní z Updating hodnoty na Succeededa že sekundární oblast je nastavená podle očekávání.
Poznámka:
Když povolíte replikaci pro pracovní prostory, které pracují se službou Sentinel, může úplné replikace dat sledovacího seznamu a analýzy hrozeb do sekundárního pracovního prostoru trvat až 12 dnů.
Přidružení pravidel shromažďování dat ke koncovému bodu shromažďování dat pracovního prostoru
Agent Služby Azure Monitor, rozhraní API pro příjem protokolů a Azure Event Hubs shromažďují data a odesílají je do cíle, který určíte podle toho, jak jste nastavili pravidla shromažďování dat (DCR).
Pokud máte pravidla shromažďování dat, která odesílají data do primárního pracovního prostoru, musíte tato pravidla přidružit ke koncovému bodu shromažďování systémových dat (DCE), který Azure Monitor vytvoří, když povolíte replikaci pracovního prostoru. Název koncového bodu shromažďování dat pracovního prostoru je shodný s ID vašeho pracovního prostoru. Replikaci a přepnutí umožňují pouze pravidla shromažďování dat, která přidružíte ke koncovému bodu shromažďování dat pracovního prostoru. Toto chování umožňuje určit sadu datových proudů protokolů, které se mají replikovat, což vám pomůže řídit náklady na replikaci.
Pokud chcete replikovat data, která shromažďujete pomocí pravidel shromažďování dat, přidružte pravidla shromažďování dat k koncovému bodu shromažďování dat pracovního prostoru:
Na webu Azure Portal vyberte pravidla shromažďování dat.
Na obrazovce Pravidla shromažďování dat vyberte pravidlo shromažďování dat, které odesílá data do vašeho primárního pracovního prostoru služby Log Analytics.
Na stránce Přehled pravidla shromažďování dat vyberte Konfigurovat DCE a v seznamu dostupných položek vyberte koncový bod shromažďování dat pracovního prostoru:
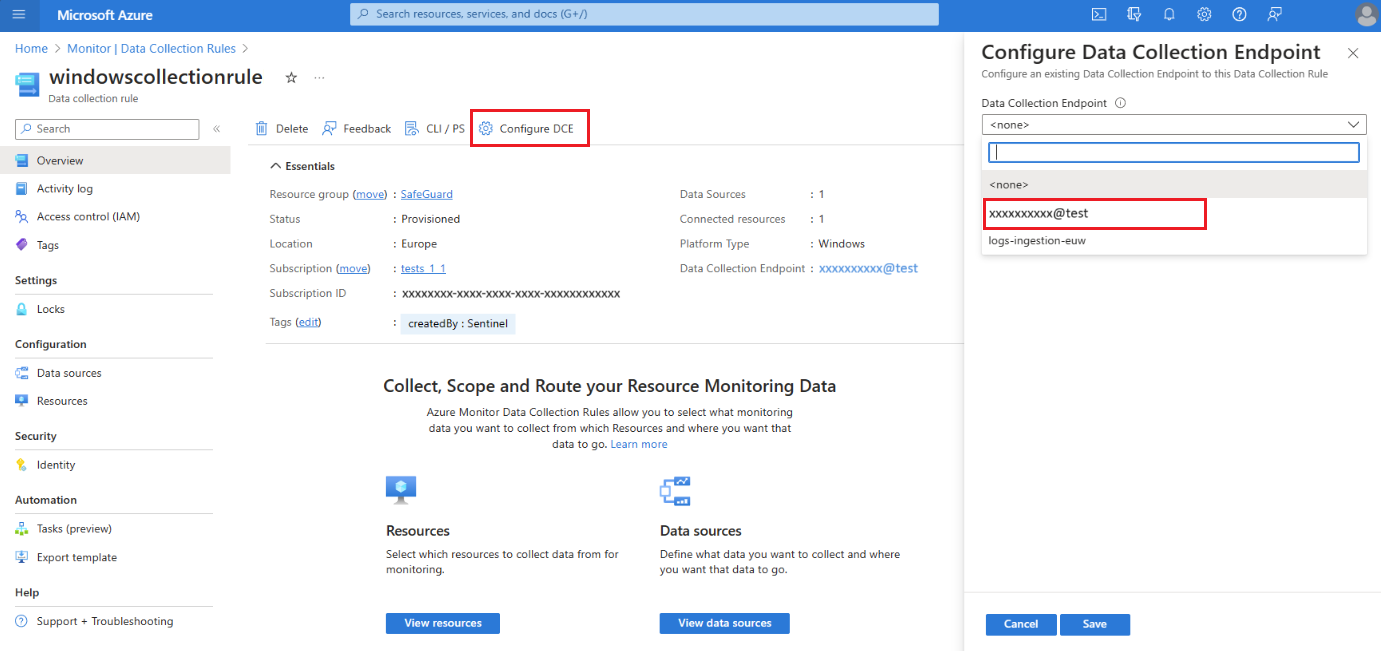 Podrobnosti o systémové DCE zkontrolujte vlastnosti objektu pracovního prostoru.
Podrobnosti o systémové DCE zkontrolujte vlastnosti objektu pracovního prostoru.

Důležité
Pravidla shromažďování dat připojená ke koncovému bodu shromažďování dat pracovního prostoru můžou cílit pouze na tento konkrétní pracovní prostor. Pravidla shromažďování dat nesmí cílit na jiné cíle, jako jsou jiné pracovní prostory nebo účty Azure Storage.
Zakázání replikace pracovního prostoru
Pokud chcete zakázat replikaci pracovního prostoru, použijte tento PUT příkaz:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
Kde:
-
<subscription_id>: ID předplatného související s vaším pracovním prostorem. -
<resourcegroup_name>: Skupina prostředků, která obsahuje váš prostředek pracovního prostoru. -
<workspace_name>: Název pracovního prostoru. -
<primary_region>: Primární oblast vašeho pracovního prostoru.
Příkaz PUT je dlouhotrvající operace, která může nějakou dobu trvat. Úspěšné volání vrátí stavový 200 kód. Stav zřizování žádosti můžete sledovat, jak je popsáno v části Kontrola stavu zřizování požadavků.
Monitorování stavu pracovního prostoru a služby
Latence příjmu dat nebo selhání dotazů jsou příklady problémů, které je často možné zpracovat převzetím služeb při selhání sekundární oblasti. Tyto problémy je možné zjistit pomocí oznámení služby Service Health a dotazů na protokoly.
Oznámení služby Service Health jsou užitečná pro problémy související se službami. K identifikaci problémů ovlivňujících váš konkrétní pracovní prostor (a pravděpodobně ne celou službu) můžete použít jiné míry:
- Vytváření upozornění na základě stavu prostředků pracovního prostoru
- Nastavení vlastních prahových hodnot pro metriky stavu pracovního prostoru
- Vytvořte vlastní monitorovací dotazy, které budou sloužit jako vlastní indikátory stavu pro váš pracovní prostor, jak je popsáno v tématu Monitorování výkonu pracovního prostoru pomocí dotazů:
- Měření latence příjmu dat na tabulku
- Zjistěte, jestli zdrojem latence jsou agenti kolekce nebo kanál příjmu dat.
- Monitorování anomálií objemu příjmu dat na tabulku a prostředek
- Monitorování úspěšnosti dotazů na tabulku, uživatele nebo prostředek
- Vytváření upozornění na základě vašich dotazů
Poznámka:
K monitorování sekundárního pracovního prostoru můžete použít také dotazy protokolu, ale mějte na paměti, že replikace protokolů probíhá v dávkových operacích. Měřená latence může kolísat a neznačí žádný problém se stavem vašeho sekundárního pracovního prostoru. Další informace najdete v tématu Audit neaktivního pracovního prostoru.
Přepnutí do sekundárního pracovního prostoru
Při přechodu funguje většina operací stejně jako při použití primárního pracovního prostoru a oblasti. Některé operace ale mají trochu jiné chování nebo jsou blokované. Další informace najdete v tématu Aspekty nasazení.
Kdy mám přepnout?
Rozhodnete se, kdy přepnout do sekundárního pracovního prostoru, a přepnout zpět na primární pracovní prostor na základě průběžného monitorování výkonu a stavu a standardů a požadavků na systém.
V plánu přechodu je potřeba zvážit několik bodů, jak je popsáno v následujících pododdílech.
Typ a rozsah problému
Proces přechodu směruje příjem dat a požadavky na dotazy do sekundární oblasti, což obvykle obchází všechny vadné komponenty, které způsobují latenci nebo selhání ve vaší primární oblasti. V důsledku toho přepnutí pravděpodobně nepomůže, pokud:
- U podkladového prostředku došlo k problému mezi oblastmi. Pokud například stejné typy prostředků v primární i sekundární oblasti selžou.
- Dochází k problému souvisejícímu se správou pracovních prostorů, jako je změna uchovávání pracovních prostorů. Operace správy pracovních prostorů se vždy zpracovávají ve vaší primární oblasti. Během přechodu se zablokují operace správy pracovního prostoru.
Doba trvání problému
Přepnutí není okamžité. Proces přesměrování požadavků závisí na aktualizacích DNS, které někteří klienti vyzvednou během několika minut, zatímco jiné můžou trvat déle. Proto je užitečné pochopit, jestli se problém dá vyřešit během několika minut. Pokud je zjištěný problém konzistentní nebo nepřetržitý, nečekejte na přepnutí. Několik příkladů:
Příjem dat: Problémy s kanálem příjmu dat ve vaší primární oblasti můžou mít vliv na replikaci dat do sekundárního pracovního prostoru. Během přechodu se protokoly posílají do kanálu příjmu dat v sekundární oblasti.
Dotaz: Pokud dotazy v primárním pracovním prostoru selžou nebo dojde k vypršení časového limitu, můžou se to týkat upozornění prohledávání protokolů. V tomto scénáři přepněte do sekundárního pracovního prostoru, abyste měli jistotu, že se všechna upozornění aktivují správně.
Data sekundárního pracovního prostoru
Protokoly ingestované do primárního pracovního prostoru před povolením replikace se nezkopírují do sekundárního pracovního prostoru. Pokud jste povolili replikaci pracovního prostoru před třemi hodinami a teď přepnete do sekundárního pracovního prostoru, můžou dotazy vracet pouze data z posledních tří hodin.
Než během přechodu přepnete oblasti, musí sekundární pracovní prostor obsahovat užitečný svazek protokolů. Doporučujeme počkat alespoň jeden týden po povolení replikace, než aktivujete přepnutí. Sedm dnů umožňuje, aby byla v sekundární oblasti k dispozici dostatečná data.
Přepnutí triggeru
Než přepnete, ověřte, že se operace replikace pracovního prostoru úspěšně dokončila. Přepnutí proběhne úspěšně pouze při správné konfiguraci sekundárního pracovního prostoru.
Pokud chcete přepnout do sekundárního pracovního prostoru, použijte tento POST příkaz:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/locations/<secondary_region>/workspaces/<workspace_name>/failover?api-version=2023-01-01-preview
Kde:
-
<subscription_id>: ID předplatného související s vaším pracovním prostorem. -
<resourcegroup_name>: Skupina prostředků, která obsahuje váš prostředek pracovního prostoru. -
<secondary_region>: Oblast, na které se má přepnout během přechodu. -
<workspace_name>: Název pracovního prostoru, na který se má přepnout během přechodu.
Příkaz POST je dlouhotrvající operace, která může nějakou dobu trvat. Úspěšné volání vrátí stavový 202 kód. Stav zřizování žádosti můžete sledovat, jak je popsáno v části Kontrola stavu zřizování požadavků.
Přepnutí zpět do primárního pracovního prostoru
Proces přepnutí zpět zruší přesměrování dotazů a požadavků na příjem protokolů do sekundárního pracovního prostoru. Když přepnete zpět, Azure Monitor se vrátí ke směrování dotazů a žádostí o příjem protokolů do vašeho primárního pracovního prostoru.
Když přepnete do sekundární oblasti, Azure Monitor replikuje protokoly ze sekundárního pracovního prostoru do primárního pracovního prostoru. Pokud má výpadek vliv na proces příjmu protokolů v primární oblasti, může to chvíli trvat, než Azure Monitor dokončí příjem replikovaných protokolů do vašeho primárního pracovního prostoru.
Kdy mám přepnout zpět?
V plánu pro přechod zpět je potřeba zvážit několik bodů, jak je popsáno v následujících pododdílech.
Stav replikace protokolu
Před přepnutím zpět ověřte, že Azure Monitor dokončil replikaci všech protokolů přijatých během přechodu do primární oblasti. Pokud přepnete zpět před replikací všech protokolů do primárního pracovního prostoru, můžou vaše dotazy vrátit částečné výsledky, dokud se příjem dat protokolu neskončí.
Primární pracovní prostor můžete dotazovat na webu Azure Portal pro neaktivní oblast, jak je popsáno v části Audit neaktivního pracovního prostoru.
Stav primárního pracovního prostoru
Existují dvě důležité položky stavu, které je potřeba zkontrolovat při přípravě na přepnutí do primárního pracovního prostoru:
- Ověřte, že pro primární pracovní prostor a oblast nejsou k dispozici žádná oznámení služby Service Health.
- Ověřte, že váš primární pracovní prostor ingestuje protokoly a zpracovává dotazy podle očekávání.
Příklady, jak zadat dotaz na primární pracovní prostor, když je sekundární pracovní prostor aktivní a obejít přesměrování požadavků do sekundárního pracovního prostoru, najdete v tématu Audit neaktivního pracovního prostoru.
Zpětný přepínač aktivační události
Před přepnutím zpět potvrďte stav primárního pracovního prostoru a dokončete replikaci protokolů.
Proces zpětného přepnutí aktualizuje vaše záznamy DNS. Po aktualizaci záznamů DNS může trvat dlouho, než všichni klienti dostanou aktualizovaná nastavení DNS a obnoví směrování do primárního pracovního prostoru.
Pokud chcete přepnout zpět do primárního pracovního prostoru, použijte tento POST příkaz:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>/failback?api-version=2023-01-01-preview
Kde:
-
<subscription_id>: ID předplatného související s vaším pracovním prostorem. -
<resourcegroup_name>: Skupina prostředků, která obsahuje váš prostředek pracovního prostoru. -
<workspace_name>: Název pracovního prostoru, na který se má přepnout během přepínání.
Příkaz POST je dlouhotrvající operace, která může nějakou dobu trvat. Úspěšné volání vrátí stavový 202 kód. Stav zřizování žádosti můžete sledovat, jak je popsáno v části Kontrola stavu zřizování požadavků.
Auditování neaktivního pracovního prostoru
Ve výchozím nastavení je aktivní oblastí vašeho pracovního prostoru oblast, ve které pracovní prostor vytváříte, a neaktivní oblastí je sekundární oblast, kde Azure Monitor vytvoří replikovaný pracovní prostor.
Když aktivujete převzetí služeb při selhání, aktivuje se sekundární oblast a primární oblast bude neaktivní. Říkáme, že je neaktivní, protože to není přímý cíl příjmu protokolů a požadavků na dotazy.
Před přepnutím mezi oblastmi a ověřením, že pracovní prostor v neaktivní oblasti obsahuje protokoly, které očekáváte, že se tam zobrazí, je užitečné dotazovat neaktivní oblast.
Dotazování neaktivní oblasti
Pokud chcete dotazovat data protokolu v neaktivní oblasti, použijte tento příkaz GET:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=<query>×pan=<timespan-in-ISO8601-format>&overrideWorkspaceRegion=<primary|secondary>
Pokud chcete například spustit jednoduchý dotaz, například Perf | count za poslední den v sekundární oblasti, použijte:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=Perf%20|%20count×pan=P1D&overrideWorkspaceRegion=secondary
Pokud chcete ověřit, že Azure Monitor spouští dotaz v zamýšlené oblasti, zkontrolujte tato pole v LAQueryLogs tabulce, která se vytvoří při povolení auditování dotazů v pracovním prostoru služby Log Analytics:
-
isWorkspaceInFailover: Určuje, jestli byl pracovní prostor během dotazu v režimu přechodu. Datový typ je logická hodnota (True, False). -
workspaceRegion: Oblast pracovního prostoru, na který dotaz cílí. Datový typ je String.
Monitorování výkonu pracovního prostoru pomocí dotazů
Doporučujeme použít dotazy v této části k vytvoření pravidel upozornění, která vás upozorní na možné problémy se stavem nebo výkonem pracovního prostoru. Rozhodnutí o přechodu ale vyžaduje pečlivé zvážení a nemělo by se provádět automaticky.
V pravidle dotazu můžete definovat podmínku, která se má po zadaném počtu porušení přepnout do sekundárního pracovního prostoru. Další informace najdete v tématu Vytvoření nebo úprava pravidla upozornění prohledávání protokolu.
Mezi dvě významná měření výkonu pracovního prostoru patří latence příjmu dat a objem příjmu dat. V následujících částech najdete tyto možnosti monitorování.
Monitorování celkové latence příjmu dat
Latence příjmu dat měří dobu potřebnou k příjmu protokolů do pracovního prostoru. Měření času začíná, když dojde k počáteční protokolované události a končí, když je protokol uložen ve vašem pracovním prostoru. Celková latence příjmu dat se skládá ze dvou částí:
- Latence agenta: Doba potřebná agentem k nahlášení události.
- Latence kanálu příjmu dat (back-end): Doba potřebná ke zpracování protokolů kanálu příjmu dat a jejich zápis do pracovního prostoru.
Různé datové typy mají různou latenci příjmu dat. Pro každý datový typ můžete měřit příjem dat samostatně nebo můžete vytvořit obecný dotaz pro všechny typy a jemněji odstupňovaný dotaz pro konkrétní typy, které jsou pro vás důležitější. Doporučujeme změřit 90. percentil latence příjmu dat, který je citlivější na změnu než průměr nebo 50. percentil (medián).
Následující části ukazují, jak pomocí dotazů zkontrolovat latenci příjmu dat pro váš pracovní prostor.
Vyhodnocení latence příjmu dat podle směrného plánu konkrétních tabulek
Začněte určením základní latence konkrétních tabulek za několik dnů.
Tento ukázkový dotaz vytvoří graf 90. percentilu latence příjmu dat v tabulce Výkon:
// Assess the ingestion latency baseline for a specific data type
Perf
| where TimeGenerated > ago(3d)
| project TimeGenerated,
IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h)
| render timechart
Po spuštění dotazu zkontrolujte výsledky a vykreslený graf a určete očekávanou latenci dané tabulky.
Monitorování a upozornění na aktuální latenci příjmu dat
Po vytvoření standardní latence příjmu dat pro konkrétní tabulku vytvořte pravidlo upozornění prohledávání protokolu pro tabulku na základě změn latence za krátkou dobu.
Tento dotaz vypočítá latenci příjmu dat za posledních 20 minut:
// Track the recent ingestion latency (in seconds) of a specific table
Perf
| where TimeGenerated > ago(20m)
| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90)
Vzhledem k tomu, že můžete očekávat určité výkyvy, vytvořte podmínku pravidla upozornění, která zkontroluje, jestli dotaz vrací hodnotu výrazně větší než směrný plán.
Určení zdroje latence příjmu dat
Když zjistíte, že dochází k celkové latenci příjmu dat, můžete pomocí dotazů zjistit, jestli zdrojem latence jsou agenti nebo kanál příjmu dat.
Tento dotaz grafuje latenci 90. percentilu agentů a kanálu samostatně:
// Assess agent and pipeline (backend) latency
Perf
| where TimeGenerated > ago(1h)
| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s,
PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s
| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m)
| render columnchart
Poznámka:
I když graf zobrazuje 90. percentilová data jako skládané sloupce, součet dat v těchto dvou grafech se nerovná celkovému 90. percentilu příjmu dat.
Monitorování objemu příjmu dat
Měření objemu příjmu dat můžou pomoct identifikovat neočekávané změny celkového nebo objemu příjmu dat specifického pro tabulku pro váš pracovní prostor. Měření objemu dotazů vám může pomoct identifikovat problémy s výkonem při příjmu protokolů. Mezi užitečné měření objemu patří:
- Celkový objem příjmu dat na tabulku
- Objem konstantního příjmu dat (stojan)
- Anomálie příjmu dat – špičky a poklesy objemu příjmu dat
Následující části ukazují, jak pomocí dotazů zkontrolovat objem příjmu dat pro váš pracovní prostor.
Monitorování celkového objemu příjmu dat na tabulku
Můžete definovat dotaz pro monitorování objemu příjmu dat na tabulku v pracovním prostoru. Dotaz může obsahovat upozornění, které kontroluje neočekávané změny celkových svazků nebo svazků specifických pro tabulky.
Tento dotaz vypočítá celkový objem příjmu dat za poslední hodinu na tabulku v megabajtech za sekundu (MB):
// Calculate total ingestion volume over the past hour per table
Usage
| where TimeGenerated > ago(1h)
| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType
Kontrola zastavení příjmu dat
Pokud ingestujete protokoly prostřednictvím agentů, můžete k detekci připojení použít prezenční signál agenta. Prezenční signál může odhalit zastavení příjmu protokolů do vašeho pracovního prostoru. Když data dotazu odhalí zastavení příjmu dat, můžete definovat podmínku, která aktivuje požadovanou odpověď.
Následující dotaz zkontroluje prezenční signál agenta a zjistí problémy s připojením:
// Count agent heartbeats in the last ten minutes
Heartbeat
| where TimeGenerated>ago(10m)
| count
Monitorování anomálií příjmu dat
Špičky a propady v objemech objemu dat pracovního prostoru můžete identifikovat různými způsoby. Pomocí funkce series_decompose_anomalies() extrahujte anomálie ze svazků příjmu dat, které monitorujete ve svém pracovním prostoru, nebo vytvořte vlastní detektor anomálií pro podporu jedinečných scénářů pracovního prostoru.
Identifikace anomálií pomocí series_decompose_anomalies
Funkce series_decompose_anomalies() identifikuje anomálie v řadě datových hodnot. Tento dotaz vypočítá hodinový objem příjmu dat každé tabulky v pracovním prostoru služby Log Analytics a používá series_decompose_anomalies() k identifikaci anomálií:
// Calculate hourly ingestion volume per table and identify anomalies
Usage
| where TimeGenerated > ago(24h)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| summarize
Timestamp=make_list(TimeGenerated),
IngestionVolumeMB=make_list(IngestionVolumeMB)
by DataType
| extend series_decompose_anomalies(IngestionVolumeMB)
| mv-expand
Timestamp,
IngestionVolumeMB,
series_decompose_anomalies_IngestionVolumeMB_ad_flag,
series_decompose_anomalies_IngestionVolumeMB_ad_score,
series_decompose_anomalies_IngestionVolumeMB_baseline
| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0
Další informace o použití series_decompose_anomalies() k detekci anomálií v datech protokolu najdete v tématu Detekce a analýza anomálií pomocí funkcí strojového učení KQL ve službě Azure Monitor.
Vytvoření vlastního detektoru anomálií
Můžete vytvořit vlastní detektor anomálií, který bude podporovat požadavky na scénář pro konfiguraci pracovního prostoru. Tato část obsahuje příklad pro předvedení procesu.
Následující dotaz vypočítá:
- Očekávaný objem příjmu dat: každou hodinu podle tabulky (na základě mediánu mediánů mediánů, ale logiku můžete přizpůsobit)
- Skutečný objem příjmu dat: za hodinu podle tabulky
Pokud chcete odfiltrovat nevýznamné rozdíly mezi očekávaným a skutečným objemem příjmu dat, použije dotaz dva filtry:
- Četnost změn: Více než 150 % nebo méně než 66 % očekávaného objemu na tabulku
- Objem změn: Označuje, jestli je větší nebo nižší objem větší než 0,1 % měsíčního objemu této tabulky.
// Calculate expected vs actual hourly ingestion per table
let TimeRange=24h;
let MonthlyIngestionByType=
Usage
| where TimeGenerated > ago(30d)
| summarize MonthlyIngestionMB=sum(Quantity) by DataType;
// Calculate the expected ingestion volume by median of hourly medians
let ExpectedIngestionVolumeByType=
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType
| summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType;
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| join kind=inner (ExpectedIngestionVolumeByType) on DataType
| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2)
| where GapVolumeMB != 0
| extend Trend=iff(GapVolumeMB > 0, "Up", "Down")
| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2)
| join kind=inner (MonthlyIngestionByType) on DataType
| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2)
| project-away DataType1, DataType2
// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type
| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66
// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace
| where GapAsPercentOfMonthlyIngestion > 0.1
| project
Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'),
Trend,
IngestionVolumeMB,
ExpectedIngestionVolumeMB,
IngestedVsExpectedAsPercent,
GapAsPercentOfMonthlyIngestion
Monitorování úspěšnosti a selhání dotazu
Každý dotaz vrátí kód odpovědi, který označuje úspěch nebo selhání. Pokud dotaz selže, odpověď obsahuje také typy chyb. Vysoká nárůst chyb může znamenat problém s dostupností pracovního prostoru nebo výkonem služby.
Tento dotaz spočítá, kolik dotazů vrátil kód chyby serveru:
// Count query errors
LAQueryLogs
| where ResponseCode>=500 and ResponseCode<600
| count