Diagnostika v Durable Functions v Azure
Existuje několik možností pro diagnostiku problémů s Durable Functions. Některé z těchto možností jsou stejné pro normální funkce a některé jsou jedinečné pro Durable Functions.
Application Insights
Application Insights je doporučený způsob, jak provádět diagnostiku a monitorování ve službě Azure Functions. Totéž platí pro Durable Functions. Přehled využití Application Insights v aplikaci funkcí najdete v tématu Monitorování Azure Functions.
Rozšíření Durable Extension služby Azure Functions také generuje události sledování, které umožňují trasovat komplexní provádění orchestrace. Tyto události sledování lze najít a dotazovat pomocí nástroje Application Insights Analytics na webu Azure Portal.
Sledování dat
Každá událost životního cyklu instance orchestrace způsobí zápis události sledování do kolekce trasování v Application Insights. Tato událost obsahuje vlastní datovou částDimensions s několika poli. Názvy polí jsou předem odděleny prop__.
- hubName: Název centra úloh, ve kterém jsou vaše orchestrace spuštěné.
- appName: Název aplikace funkcí. Toto pole je užitečné, když máte více aplikací funkcí, které sdílejí stejnou instanci Application Insights.
- slotName: Slot nasazení, ve kterém je spuštěná aktuální aplikace funkcí. Toto pole je užitečné při použití slotů nasazení k verzi orchestrací.
- functionName: Název orchestrátoru nebo funkce aktivity.
- functionType: Typ funkce, například Orchestrator nebo Activity.
- instanceId: Jedinečné ID instance orchestrace.
- state: Stav provádění životního cyklu instance. Mezi platné hodnoty patří:
- Naplánované: Funkce byla naplánována pro spuštění, ale ještě nebyla spuštěna.
- Spuštěno: Funkce se spustila, ale ještě nečekala ani nedokončila.
- Čeká se: Orchestrátor naplánoval nějakou práci a čeká na dokončení.
- Naslouchání: Orchestrátor naslouchá oznámení o externí události.
- Dokončeno: Funkce byla úspěšně dokončena.
- Selhalo: Funkce selhala s chybou.
- důvod: Další data přidružená k události sledování. Pokud například instance čeká na oznámení o externí události, toto pole označuje název události, na které čeká. Pokud funkce selhala, bude toto pole obsahovat podrobnosti o chybě.
- isReplay: Logická hodnota označující, zda je událost sledování pro přehrání spuštění.
- extensionVersion: Verze rozšíření Durable Task. Informace o verzi jsou obzvláště důležitá data při hlášení možných chyb v rozšíření. Dlouhotrvající instance můžou hlásit více verzí, pokud dojde k aktualizaci, když je spuštěná.
- sequenceNumber: Pořadové číslo spuštění pro událost. Kombinace s časovým razítkem pomáhá uspořádat události podle času spuštění. Všimněte si, že toto číslo se resetuje na nulu, pokud se hostitel restartuje, když je instance spuštěná, takže je důležité nejprve řadit podle časového razítka a potom sequenceNumber.
Podrobnosti sledování dat generovaných do Application Insights je možné nakonfigurovat v logger části host.json (Functions 1.x) nebo logging (Functions 2.0) souboru.
Funkce 1.0
{
"logger": {
"categoryFilter": {
"categoryLevels": {
"Host.Triggers.DurableTask": "Information"
}
}
}
}
Funkce 2.0
{
"logging": {
"logLevel": {
"Host.Triggers.DurableTask": "Information",
},
}
}
Ve výchozím nastavení se vygenerují všechny události sledování, které se nepřehrávají . Objem dat je možné snížit nastavením Host.Triggers.DurableTask "Warning" nebo "Error" v takovém případě se sledování událostí vygeneruje pouze v výjimečných situacích. Pokud chcete povolit generování podrobných událostí replay orchestrace, nastavte logReplayEvents hodnotu v true konfiguračním souboru host.json .
Poznámka:
Ve výchozím nastavení se telemetrie Application Insights vzorkuje modulem runtime Azure Functions, aby se zabránilo příliš častému generování dat. To může způsobit ztrátu informací o sledování, když v krátkém časovém období dojde k mnoha událostem životního cyklu. Článek monitorování služby Azure Functions vysvětluje, jak toto chování nakonfigurovat.
Vstupy a výstupy orchestrátoru, aktivity a funkcí entit nejsou ve výchozím nastavení protokolovány. Toto výchozí chování se doporučuje, protože vstupy a výstupy protokolování můžou zvýšit náklady na Application Insights. Vstupní a výstupní datové části funkce mohou také obsahovat citlivé informace. Místo toho se počet bajtů pro vstupy a výstupy funkcí zaprotokoluje místo skutečných datových částí ve výchozím nastavení. Pokud chcete, aby rozšíření Durable Functions protokolovat úplné vstupní a výstupní datové části, nastavte traceInputsAndOutputs vlastnost do true host.json konfiguračního souboru.
Dotaz na jednu instanci
Následující dotaz ukazuje historická data sledování pro jednu instanci orchestrace funkce Hello Sequence . Je napsaný pomocí dotazovací jazyk Kusto. Filtruje provádění přehrání tak, aby se zobrazila pouze logická cesta spuštění. Události lze řadit podle řazení timestamp a sequenceNumber jak je znázorněno v následujícím dotazu:
let targetInstanceId = "ddd1aaa685034059b545eb004b15d4eb";
let start = datetime(2018-03-25T09:20:00);
traces
| where timestamp > start and timestamp < start + 30m
| where customDimensions.Category == "Host.Triggers.DurableTask"
| extend functionName = customDimensions["prop__functionName"]
| extend instanceId = customDimensions["prop__instanceId"]
| extend state = customDimensions["prop__state"]
| extend isReplay = tobool(tolower(customDimensions["prop__isReplay"]))
| extend sequenceNumber = tolong(customDimensions["prop__sequenceNumber"])
| where isReplay != true
| where instanceId == targetInstanceId
| sort by timestamp asc, sequenceNumber asc
| project timestamp, functionName, state, instanceId, sequenceNumber, appName = cloud_RoleName
Výsledkem je seznam sledování událostí, které zobrazují cestu provádění orchestrace, včetně všech funkcí aktivit seřazených podle času provádění ve vzestupném pořadí.
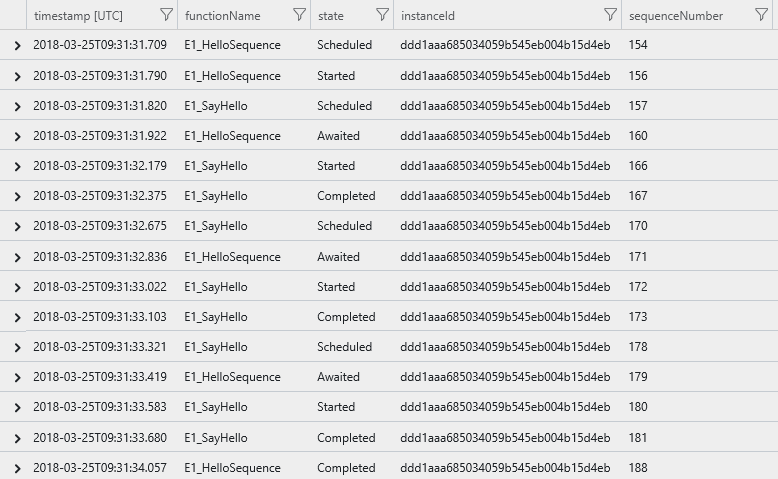
Souhrnný dotaz instance
Následující dotaz zobrazí stav všech instancí orchestrace, které byly spuštěny v zadaném časovém rozsahu.
let start = datetime(2017-09-30T04:30:00);
traces
| where timestamp > start and timestamp < start + 1h
| where customDimensions.Category == "Host.Triggers.DurableTask"
| extend functionName = tostring(customDimensions["prop__functionName"])
| extend instanceId = tostring(customDimensions["prop__instanceId"])
| extend state = tostring(customDimensions["prop__state"])
| extend isReplay = tobool(tolower(customDimensions["prop__isReplay"]))
| extend output = tostring(customDimensions["prop__output"])
| where isReplay != true
| summarize arg_max(timestamp, *) by instanceId
| project timestamp, instanceId, functionName, state, output, appName = cloud_RoleName
| order by timestamp asc
Výsledkem je seznam ID instancí a jejich aktuální stav modulu runtime.
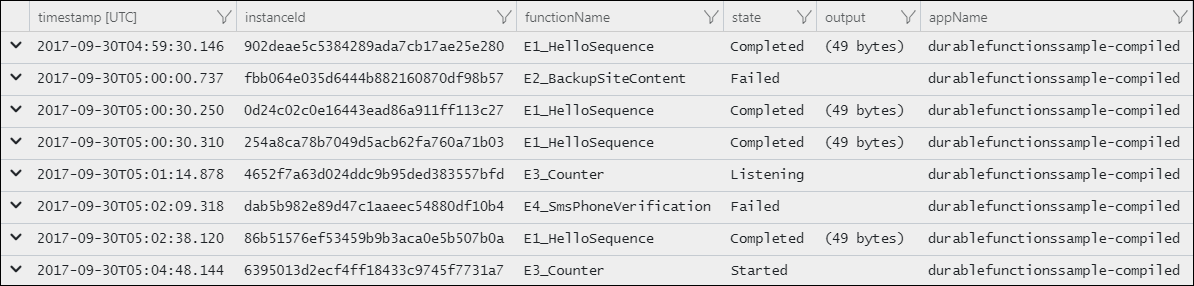
Protokolování architektury trvalých úloh
Protokoly rozšíření Durable jsou užitečné pro pochopení chování logiky orchestrace. Tyto protokoly ale vždy neobsahují dostatek informací pro ladění problémů s výkonem a spolehlivostí na úrovni architektury. Od verze 2.3.0 rozšíření Durable jsou protokoly generované podkladovou architekturou Durable Task Framework (DTFx) také k dispozici pro kolekci.
Při pohledu na protokoly generované DTFx je důležité pochopit, že modul DTFx se skládá ze dvou komponent: základního dispečerského modulu (DurableTask.Core) a jednoho z mnoha podporovaných poskytovatelů úložiště (Durable Functions ve výchozím nastavení používá DurableTask.AzureStorage Durable Functions, ale jsou k dispozici další možnosti).
- DurableTask.Core: Spouštění základní orchestrace a protokoly a telemetrie na nízké úrovni.
- DurableTask.AzureStorage: Protokoly back-endu specifické pro poskytovatele stavu služby Azure Storage. Mezi tyto protokoly patří podrobné interakce s interními frontami, objekty blob a tabulkami úložiště sloužícími k ukládání a načítání interního stavu orchestrace.
- DurableTask.Netherite: Back-end protokoly specifické pro poskytovatele úložiště Netherite, pokud je povoleno.
- DurableTask.SqlServer: Protokoly back-endu specifické pro poskytovatele úložiště Microsoft SQL (MSSQL), pokud je povoleno.
Tyto protokoly můžete povolit aktualizací logging/logLevel části souboru host.json vaší aplikace funkcí. Následující příklad ukazuje, jak povolit upozornění a protokoly chyb z obou DurableTask.Core a DurableTask.AzureStorage:
{
"version": "2.0",
"logging": {
"logLevel": {
"DurableTask.AzureStorage": "Warning",
"DurableTask.Core": "Warning"
}
}
}
Pokud máte službu Application Insights povolenou, tyto protokoly se automaticky přidají do trace kolekce. Můžete je prohledávat stejným způsobem, jakým hledáte jiné trace protokoly pomocí dotazů Kusto.
Poznámka:
U produkčních aplikací se doporučuje povolit DurableTask.Core protokoly s použitím "Warning" filtru a příslušného poskytovatele úložiště (napřDurableTask.AzureStorage. ). Vyšší filtry podrobností, jako "Information" jsou například velmi užitečné pro ladění problémů s výkonem. Tyto události protokolu ale můžou být velké a můžou výrazně zvýšit náklady na úložiště dat Application Insights.
Následující dotaz Kusto ukazuje, jak dotazovat na protokoly DTFx. Nejdůležitější součástí dotazu je where customerDimensions.Category startswith "DurableTask" to, že výsledky filtruje na protokoly v jednotlivých DurableTask.Core kategoriích.DurableTask.AzureStorage
traces
| where customDimensions.Category startswith "DurableTask"
| project
timestamp,
severityLevel,
Category = customDimensions.Category,
EventId = customDimensions.EventId,
message,
customDimensions
| order by timestamp asc
Výsledkem je sada protokolů napsaných poskytovateli protokolů Durable Task Framework.
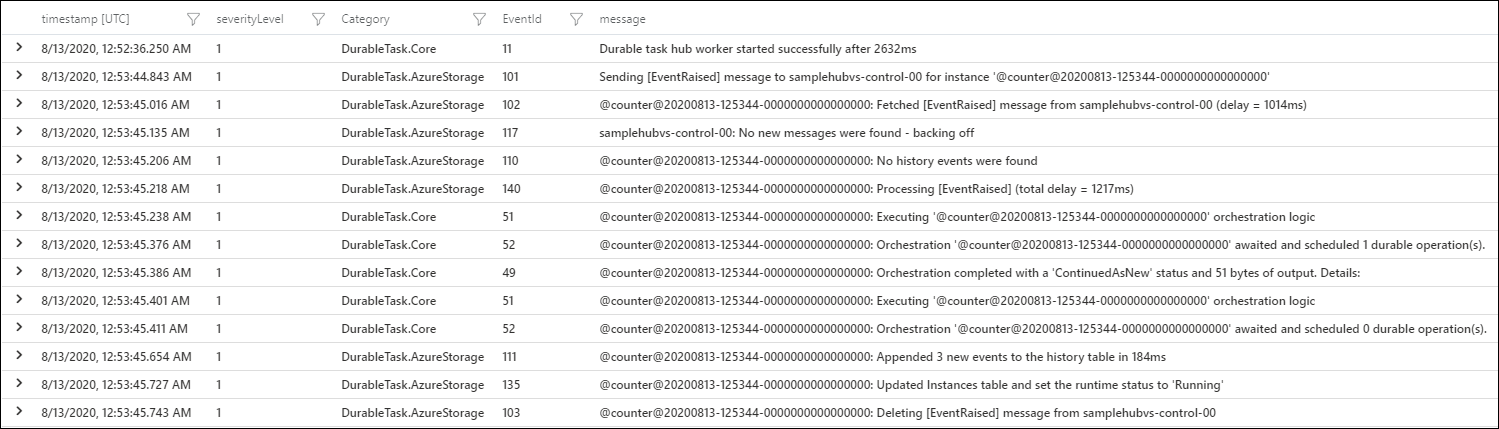
Další informace o dostupných událostech protokolu najdete v dokumentaci strukturovaného protokolování architektury Durable Task Framework na GitHubu.
Protokolování aplikace
Při zápisu protokolů přímo z funkce orchestrátoru je důležité mít na paměti chování orchestrátoru přehrání. Představte si například následující funkci orchestrátoru:
[FunctionName("FunctionChain")]
public static async Task Run(
[OrchestrationTrigger] IDurableOrchestrationContext context,
ILogger log)
{
log.LogInformation("Calling F1.");
await context.CallActivityAsync("F1");
log.LogInformation("Calling F2.");
await context.CallActivityAsync("F2");
log.LogInformation("Calling F3");
await context.CallActivityAsync("F3");
log.LogInformation("Done!");
}
Výsledná data protokolu budou vypadat přibližně jako v následujícím příkladu výstupu:
Calling F1.
Calling F1.
Calling F2.
Calling F1.
Calling F2.
Calling F3.
Calling F1.
Calling F2.
Calling F3.
Done!
Poznámka:
Mějte na paměti, že zatímco deklarace identity protokolů, která se má volat F1, F2 a F3, tyto funkce se ve skutečnosti volají pouze při prvním zobrazení. Následná volání, ke kterým dojde během přehrávání, se přeskočí a výstupy se přehrají do logiky orchestrátoru.
Pokud chcete zapisovat pouze protokoly při provádění bez přehrání, můžete napsat podmíněný výraz, který se má protokolovat pouze v případě, že příznak "replaying" je false. Podívejte se na výše uvedený příklad, ale tentokrát s kontrolami přehrávání.
[FunctionName("FunctionChain")]
public static async Task Run(
[OrchestrationTrigger] IDurableOrchestrationContext context,
ILogger log)
{
if (!context.IsReplaying) log.LogInformation("Calling F1.");
await context.CallActivityAsync("F1");
if (!context.IsReplaying) log.LogInformation("Calling F2.");
await context.CallActivityAsync("F2");
if (!context.IsReplaying) log.LogInformation("Calling F3");
await context.CallActivityAsync("F3");
log.LogInformation("Done!");
}
Počínaje Durable Functions 2.0 mají funkce orchestrátoru .NET také možnost vytvořit ILogger příkazy protokolu automaticky vyfiltrovat během přehrávání. Toto automatické filtrování se provádí pomocí rozhraní API IDurableOrchestrationContext.CreateReplaySafeLogger(ILogger).
[FunctionName("FunctionChain")]
public static async Task Run(
[OrchestrationTrigger] IDurableOrchestrationContext context,
ILogger log)
{
log = context.CreateReplaySafeLogger(log);
log.LogInformation("Calling F1.");
await context.CallActivityAsync("F1");
log.LogInformation("Calling F2.");
await context.CallActivityAsync("F2");
log.LogInformation("Calling F3");
await context.CallActivityAsync("F3");
log.LogInformation("Done!");
}
Poznámka:
Předchozí příklady jazyka C# jsou pro Durable Functions 2.x. Pro Durable Functions 1.x je nutné použít DurableOrchestrationContext místo IDurableOrchestrationContext. Další informace o rozdílech mezi verzemi najdete v článku o verzích Durable Functions.
Při dříve zmíněných změnách je výstup protokolu následující:
Calling F1.
Calling F2.
Calling F3.
Done!
Vlastní stav
Stav vlastní orchestrace umožňuje nastavit vlastní hodnotu stavu pro funkci orchestrátoru. Tento vlastní stav se pak zobrazí externím klientům prostřednictvím rozhraní API pro dotazy na stav HTTP nebo volání rozhraní API specifického pro jazyk. Stav vlastní orchestrace umožňuje rozsáhlejší monitorování funkcí orchestrátoru. Kód funkce orchestrátoru může například vyvolat rozhraní API pro nastavení vlastního stavu, které aktualizuje průběh dlouhotrvající operace. Klient, jako je webová stránka nebo jiný externí systém, by pak mohl pravidelně dotazovat rozhraní API stavového dotazu HTTP na podrobnější informace o průběhu. Ukázkový kód pro nastavení vlastní hodnoty stavu ve funkci orchestrátoru je uvedený níže:
[FunctionName("SetStatusTest")]
public static async Task SetStatusTest([OrchestrationTrigger] IDurableOrchestrationContext context)
{
// ...do work...
// update the status of the orchestration with some arbitrary data
var customStatus = new { completionPercentage = 90.0, status = "Updating database records" };
context.SetCustomStatus(customStatus);
// ...do more work...
}
Poznámka:
Předchozí příklad jazyka C# je pro Durable Functions 2.x. Pro Durable Functions 1.x je nutné použít DurableOrchestrationContext místo IDurableOrchestrationContext. Další informace o rozdílech mezi verzemi najdete v článku o verzích Durable Functions.
Když je orchestrace spuštěná, můžou externí klienti načíst tento vlastní stav:
GET /runtime/webhooks/durabletask/instances/instance123?code=XYZ
Klienti obdrží následující odpověď:
{
"runtimeStatus": "Running",
"input": null,
"customStatus": { "completionPercentage": 90.0, "status": "Updating database records" },
"output": null,
"createdTime": "2017-10-06T18:30:24Z",
"lastUpdatedTime": "2017-10-06T19:40:30Z"
}
Upozorňující
Datová část vlastního stavu je omezená na 16 kB textu JSON UTF-16, protože se musí vejde do sloupce Azure Table Storage. Pokud potřebujete větší datovou část, můžete použít externí úložiště.
Distribuované trasování
Distribuované trasování sleduje požadavky a ukazuje, jak mezi sebou vzájemně spolupracují různé služby. V Durable Functions také koreluje orchestrace a aktivity společně. To je užitečné k pochopení, kolik časových kroků orchestrace se provádí vzhledem k celé orchestraci. Je také užitečné pochopit, kde aplikace má problém nebo kdy došlo k výjimce. Tato funkce je podporovaná pro všechny jazyky a poskytovatele úložiště.
Poznámka:
Distribuované trasování verze 2 vyžaduje Durable Functions verze 2.12.0 nebo vyšší. Distribuované trasování V2 je také ve stavu Preview, a proto nejsou instrumentovány některé vzory Durable Functions. Například operace Durable Entities nejsou instrumentované a trasování se v Application Insights nezobrazí.
Nastavení distribuovaného trasování
Pokud chcete nastavit distribuované trasování, aktualizujte host.json a nastavte prostředek Application Insights.
host.json
"durableTask": {
"tracing": {
"distributedTracingEnabled": true,
"Version": "V2"
}
}
Application Insights
Pokud aplikace funkcí není nakonfigurovaná s prostředkem Application Insights, nakonfigurujte ji podle zde uvedených pokynů.
Kontrola trasování
V prostředku Application Insights přejděte do vyhledávání transakcí. Ve výsledcích zkontrolujte Request a Dependency události, které začínají konkrétními předponami Durable Functions (např. orchestration:, activity:atd.). Výběrem jedné z těchto událostí se otevře Ganttův diagram, který zobrazí konec distribuovaného trasování.

Řešení problému
Pokud trasování v Application Insights nevidíte, počkejte asi pět minut po spuštění aplikace, abyste zajistili, že se všechna data rozšíří do prostředku Application Insights.
Ladění
Azure Functions podporuje ladění kódu funkce přímo a stejná podpora se přenese do Durable Functions bez ohledu na to, jestli běží v Azure nebo místně. Při ladění je však potřeba si uvědomit několik chování:
- Přehrání: Funkce Orchestratoru pravidelně přehrávají při přijetí nových vstupů. Toto chování znamená, že jedno logické spuštění funkce orchestrátoru může vést k vícenásobnému dosažení stejné zarážky, zejména pokud je nastavena dříve v kódu funkce.
- Await: Vždy, když je ve funkci orchestrátoru zjištěna,
awaitvrátí řízení zpět dispečeru Durable Task Framework. Pokud dojde k prvnímu zobrazení konkrétníhoawaitúkolu, přidružený úkol se nikdy neobnoví . Vzhledem k tomu, že úloha nikdy neobnoví, není možné krokovat přes operátor await (F10 v sadě Visual Studio). Krokování funguje jenom při přehrání úkolu. - Vypršení časového limitu zasílání zpráv: Durable Functions interně používá zprávy fronty k řízení provádění orchestratoru, aktivit a funkcí entit. V prostředí s více virtuálními počítači může přerušení ladění po delší dobu způsobit, že se zpráva vyzvedne jiným virtuálním počítačem, což vede k duplicitnímu spuštění. Toto chování existuje také pro běžné funkce triggeru fronty, ale je důležité zdůraznit v tomto kontextu, protože fronty jsou podrobnosti implementace.
- Zastavení a spuštění: Zprávy v trvalých funkcích se uchovávají mezi relacemi ladění. Pokud zastavíte ladění a ukončíte místní hostitelský proces, když je spuštěna odolná funkce, může se tato funkce v budoucí ladicí relaci znovu spustit automaticky. Toto chování může být matoucí, pokud se neočekává. Použití nového centra úloh nebo vymazání obsahu centra úloh mezi ladicí relace je jednou z technik, jak se vyhnout tomuto chování.
Tip
Když nastavujete zarážky ve funkcích orchestrátoru, pokud chcete přerušit pouze při provádění bez přehrání, můžete nastavit podmíněnou zarážku, která se přeruší jenom v případě, že hodnota "replaying" je false.
Úložiště
Durable Functions ve výchozím nastavení ukládá stav ve službě Azure Storage. Toto chování znamená, že pomocí nástrojů, jako je Průzkumník služby Microsoft Azure Storage, můžete zkontrolovat stav orchestrací.
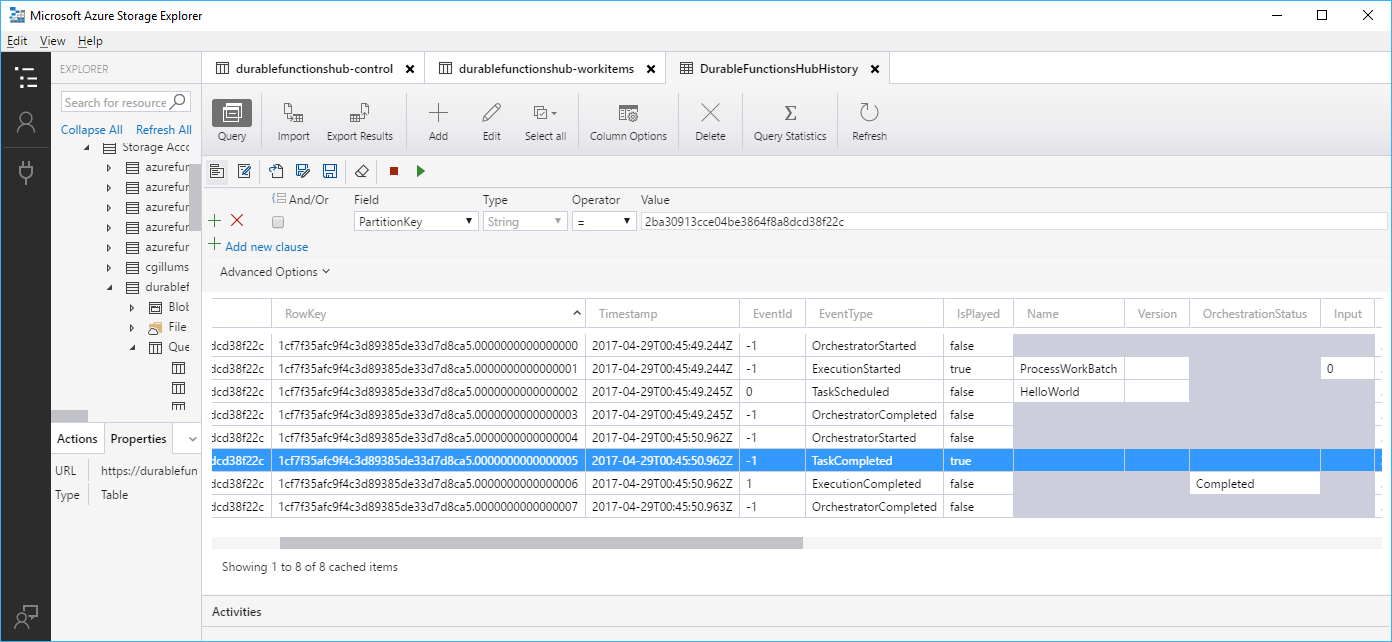
To je užitečné pro ladění, protože vidíte přesně, v jakém stavu může být orchestrace. Zprávy ve frontách můžete také prozkoumat a zjistit, co je čeká na práci (nebo se v některých případech zasekne).
Upozorňující
I když je vhodné vidět historii spouštění v úložišti tabulek, vyhněte se závislostem na této tabulce. S vývojem rozšíření Durable Functions se může změnit.
Poznámka:
Jiné poskytovatele úložiště je možné nakonfigurovat místo výchozího poskytovatele azure Storage. V závislosti na poskytovateli úložiště nakonfigurovaném pro vaši aplikaci možná budete muset ke kontrole základního stavu použít různé nástroje. Další informace najdete v dokumentaci k poskytovatelům úložiště Durable Functions.
Durable Functions Monitor
Durable Functions Monitor je grafický nástroj pro monitorování, správu a ladění orchestrace a instancí entit. Je k dispozici jako rozšíření editoru Visual Studio Code nebo samostatná aplikace. Informace o nastavení a seznamu funkcí najdete na tomto wikiwebu.
Průvodce odstraňováním potíží s Durable Functions
Pokud chcete vyřešit běžné příznaky problémů, jako je zablokování orchestrací, selhání spuštění, pomalé spuštění atd., projděte si tohoto průvodce odstraňováním potíží.