Převzetí služeb při selhání a opravy pro Azure Managed Redis (Preview)
Pokud chcete vytvářet odolné a úspěšné klientské aplikace, je důležité pochopit převzetí služeb při selhání ve službě Azure Managed Redis (Preview). Převzetí služeb při selhání může být součástí plánovaných operací správy nebo může být způsobeno neplánovanými chybami hardwaru nebo sítě. Běžné použití převzetí služeb při selhání mezipaměti nastane, když služba pro správu opraví binární soubory Azure Managed Redis.
V tomto článku najdete tyto informace:
- Co je převzetí služeb při selhání?
- Jak dojde k převzetí služeb při selhání během oprav.
- Jak vytvořit odolnou klientskou aplikaci
Co je převzetí služeb při selhání?
Začněme přehledem převzetí služeb při selhání pro Azure Managed Redis.
Rychlý přehled architektury mezipaměti
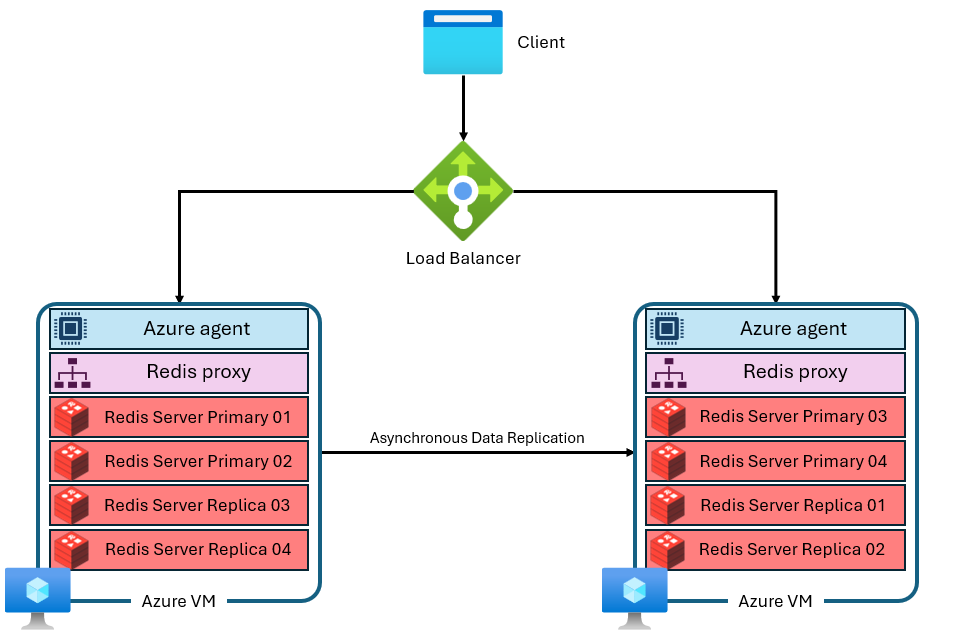
Mezipaměť je vytvořena z několika virtuálních počítačů s samostatnými a privátními IP adresami. Každý virtuální počítač (neboli uzel) spouští paralelně několik procesů serveru Redis (označovaných jako horizontální oddíly). Více horizontálních oddílů umožňuje efektivnější využití virtuálních procesorů na každém virtuálním počítači a vyšší výkon. Ne všechny primární horizontální oddíly Redis jsou na stejném virtuálním počítači nebo uzlu. Místo toho se horizontální oddíly primárních i replik distribuují napříč oběma uzly. Vzhledem k tomu, že primární horizontální oddíly používají více prostředků procesoru než horizontální oddíly replik, tento přístup umožňuje paralelní spouštění více primárních horizontálních oddílů. Každý uzel má vysoce výkonný proces proxy pro správu horizontálních oddílů, zpracování správy připojení a aktivaci samoopravení. Jeden horizontální oddíl může být mimo provoz, zatímco ostatní zůstanou dostupné.
Podrobné informace o architektuře Azure Managed Redis najdete tady.
Vysvětlení převzetí služeb při selhání
Převzetí služeb při selhání nastane, když se jeden nebo více replikovaných horizontálních oddílů prohlásí za primární horizontální oddíl a staré primární horizontální oddíly ukončí stávající připojení. Převzetí služeb při selhání může být plánované nebo neplánované.
Plánované převzetí služeb při selhání probíhá ve dvou různých časech:
- Aktualizace systému, jako je instalace oprav Redis nebo upgradů operačního systému.
- Operace správy, například škálování a restartování
Vzhledem k tomu, že uzly obdrží předběžné oznámení o aktualizaci, mohou spolupracovat na výměně rolí a rychle aktualizovat nástroj pro vyrovnávání zatížení pro změnu. Plánované převzetí služeb při selhání se obvykle dokončí za méně než 1 sekundu.
Neplánované převzetí služeb při selhání může nastat kvůli selhání hardwaru, selhání sítě nebo jiným neočekávaným výpadkům jednoho nebo více uzlů v clusteru. Replikované horizontální oddíly ve zbývajících uzlech se povýší na primární, aby zachovaly dostupnost, ale proces trvá déle. Replikovaný horizontální oddíl musí nejprve zjistit, že jeho primární horizontální oddíl není k dispozici. Teprve poté zahájí proces převzetí služeb při selhání. Replikovaný horizontální oddíl také musí ověřit, že toto neplánované selhání není přechodné nebo místní, aby nedošlo k zbytečnému převzetí služeb při selhání. Toto zpoždění detekce znamená, že neplánované převzetí služeb při selhání se obvykle dokončí do 10 až 15 sekund.
Jak dochází k opravám?
Služba Azure Managed Redis pravidelně aktualizuje vaši mezipaměť nejnovějšími funkcemi a opravami platformy. Pokud chcete opravit mezipaměť, služba se řídí těmito kroky:
- Služba vytvoří nové aktuální virtuální počítače, které nahradí všechny opravené virtuální počítače.
- Pak propaguje jeden z nových virtuálních počítačů jako vedoucího clusteru.
- Jeden po druhém, všechny uzly, které se opravují, se odeberou z clusteru. Všechny horizontální oddíly na těchto virtuálních počítačích budou degradovány a migrovány na jeden z nových virtuálních počítačů.
- Nakonec se odstraní všechny virtuální počítače, které byly nahrazeny.
Každý horizontální oddíl clusterované mezipaměti se opravuje samostatně a nezavírá připojení k jinému horizontálnímu oddílu.
Několik mezipamětí ve stejné skupině prostředků a oblasti se také opraví po jednom. Mezipaměti, které jsou v různých skupinách prostředků nebo v různých oblastech, se můžou opravovat současně.
Vzhledem k tomu, že úplná synchronizace dat proběhne před opakováním procesu, je nepravděpodobné, že dojde ke ztrátě dat pro vaši mezipaměť. Před ztrátou dat můžete dále chránit exportem dat a povolením trvalosti.
Další načtení mezipaměti
Kdykoli dojde k převzetí služeb při selhání, musí mezipaměti replikovat data z jednoho uzlu do druhého. Tato replikace způsobuje zvýšení zatížení paměti i procesoru serveru. Pokud je instance mezipaměti již silně zatížená, mohou klientské aplikace zaznamenat zvýšenou latenci. V extrémních případech může u klientské aplikace dojít k výjimce vypršení časového limitu.
Jaký má převzetí služeb při selhání vliv na klientskou aplikaci?
Klientské aplikace mohou ze své instance Azure Managed Redis obdržet hlášení o chybách. Počet chyb, ke kterým dojde u klientské aplikace, závisí na tom, kolik operací na daném připojení v okamžiku převzetí služeb při selhání čeká na vyřízení. U všech připojení, která jsou směrována přes uzel, ve kterém se ukončí připojení, dojde k chybám.
Mnoho klientských knihoven může při přerušení připojení vyvolat různé typy chyb, mezi které patří:
- Výjimky časového limitu
- Výjimky připojení
- Výjimky soketů
Počet a typ výjimek závisí na tom, kde je požadavek v cestě ke kódu, když mezipaměť ukončí svá připojení. Například u operace, která při převzetí služeb při selhání odešle požadavek, ale neobdrží odpověď, může dojít k výjimce časového limitu. Nové požadavky na objekt uzavřeného připojení přijímají výjimky připojení, dokud nedojde k úspěšnému opětovnému připojení.
Většina klientských knihoven se pokusí znovu připojit k mezipaměti (pokud jsou tak nakonfigurovány). Nepředvídatelné chyby však mohou občas dostat objekty knihovny do neopravitelného stavu. Pokud chyby potrvají déle, než je předkonfigurovaná doba, měl by se objekt připojení znovu vytvořit. V prostředí Microsoft.NET a jiných objektově orientovaných jazycích je možné znovu vytvořit připojení bez restartování aplikace pomocí vzoru ForceReconnect.
Jaké jsou aktualizace zahrnuté v rámci údržby?
Údržba zahrnuje tyto aktualizace:
- Aktualizace Serveru Redis: Všechny aktualizace nebo opravy binárních souborů serveru Redis.
- Aktualizace virtuálního počítače: Všechny aktualizace virtuálního počítače hostujícího službu Redis Aktualizace virtuálních počítačů zahrnují opravy softwarových komponent v hostitelském prostředí pro upgrade síťových komponent nebo vyřazení z provozu.
Zobrazuje se údržba ve stavu služby na webu Azure Portal před opravou?
Ne, údržba se nezobrazuje ve stavu služby na portálu ani na jiném místě.
Změny konfigurace sítě na straně klienta
Některé změny konfigurace sítě na straně klienta můžou aktivovat žádné chyby připojení k dispozici . Tyto změny můžou zahrnovat následující prvky:
- Výměna virtuální IP adresy klientské aplikace mezi připravovanými a produkčními sloty.
- Škálování velikosti nebo počtu instancí aplikace.
Tyto změny můžou způsobit problém s připojením, který obvykle trvá méně než jednu minutu. Vaše klientská aplikace pravděpodobně ztratí připojení k jiným externím síťovým prostředkům, ale také ke službě Azure Managed Redis.
Integrovaná odolnost
Převzetí služeb při selhání se není možné zcela vyhnout. Raději klientské aplikace napište tak, aby byly odolné vůči přerušení připojení a neúspěšným požadavkům. Většina klientských knihoven se automaticky znovu připojí ke koncovému bodu mezipaměti, ale některé z nich se pokusí neúspěšné požadavky opakovat. V závislosti na scénáři aplikace může být vhodné použít logiku opakování se strategií zpomalování.
Jak mám zajistit, aby byla moje aplikace odolná?
Projděte si tyto vzorové návrhy pro vytváření odolných klientů, zejména jističe a vzory opakování:
- Vzory spolehlivosti – Vzory návrhu cloudu
- Pokyny k opakování pro služby Azure – Osvědčené postupy pro cloudové aplikace
- Implementace opakování s exponenciálním backoffem