Kurz: Vyhledávání vektorů podobnosti ve službě Azure OpenAI pomocí služby Azure Cache for Redis
V tomto kurzu si projdete základní případ použití hledání podobnosti vektorů. K dotazování na datovou sadu filmů pro vyhledání nejrelevantnější shody použijete vkládání vygenerované službou Azure OpenAI Service a integrované funkce vektorového vyhledávání na podnikové úrovni azure Cache for Redis.
Tento kurz používá datovou sadu Video Plots wikipedie, která obsahuje popisy více než 35 000 filmů z Wikipedie, které pokrývají roky 1901 až 2017. Datová sada obsahuje souhrn vykreslení pro každý film a metadata, jako je rok vydání filmu, režie, hlavního obsazení a žánru. Postupujte podle kroků tohoto kurzu, abyste vygenerovali vkládání na základě souhrnu grafu a použili další metadata ke spouštění hybridních dotazů.
V tomto kurzu se naučíte:
- Vytvoření instance Azure Cache for Redis nakonfigurované pro vektorové vyhledávání
- Nainstalujte Azure OpenAI a další požadované knihovny Pythonu.
- Stáhněte si datovou sadu videa a připravte ji na analýzu.
- K vygenerování vkládání použijte model text-embedding-ada-002 (verze 2).
- Vytvoření vektorového indexu ve službě Azure Cache for Redis
- K řazení výsledků hledání použijte kosinusovou podobnost.
- Funkce hybridního dotazu prostřednictvím RediSearch slouží k předfiltrování dat a zvýraznění vektorového vyhledávání.
Důležité
Tento kurz vás provede vytvořením aplikace Jupyter Notebook. Tento kurz můžete sledovat pomocí souboru kódu Pythonu (.py) a získat podobné výsledky, ale budete muset do souboru přidat všechny bloky kódu v tomto kurzu .py a spustit jednou, abyste viděli výsledky. Jinými slovy, Jupyter Notebooks při provádění buněk poskytují přechodné výsledky, ale při práci v souboru kódu Pythonu byste neměli očekávat toto chování.
Důležité
Pokud chcete pokračovat v dokončeném poznámkovém bloku Jupyter, stáhněte si soubor jupyter notebook s názvem tutorial.ipynb a uložte ho do nové složky redis-vector .
Požadavky
- Předplatné Azure – Vytvoření předplatného zdarma
- Přístup k Azure OpenAI je udělován v požadovaném předplatném Azure. V současné době musíte požádat o přístup k Azure OpenAI. Pokud chcete získat přístup k Azure OpenAI, vyplňte formulář na adrese https://aka.ms/oai/access.
- Python 3.8 nebo novější verze
- Poznámkové bloky Jupyter (volitelné)
- Prostředek Azure OpenAI s nasazeným modelem text-embedding-ada-002 (verze 2). Tento model je aktuálně k dispozici pouze v určitých oblastech. Pokyny k nasazení modelu najdete v průvodci nasazením prostředků.
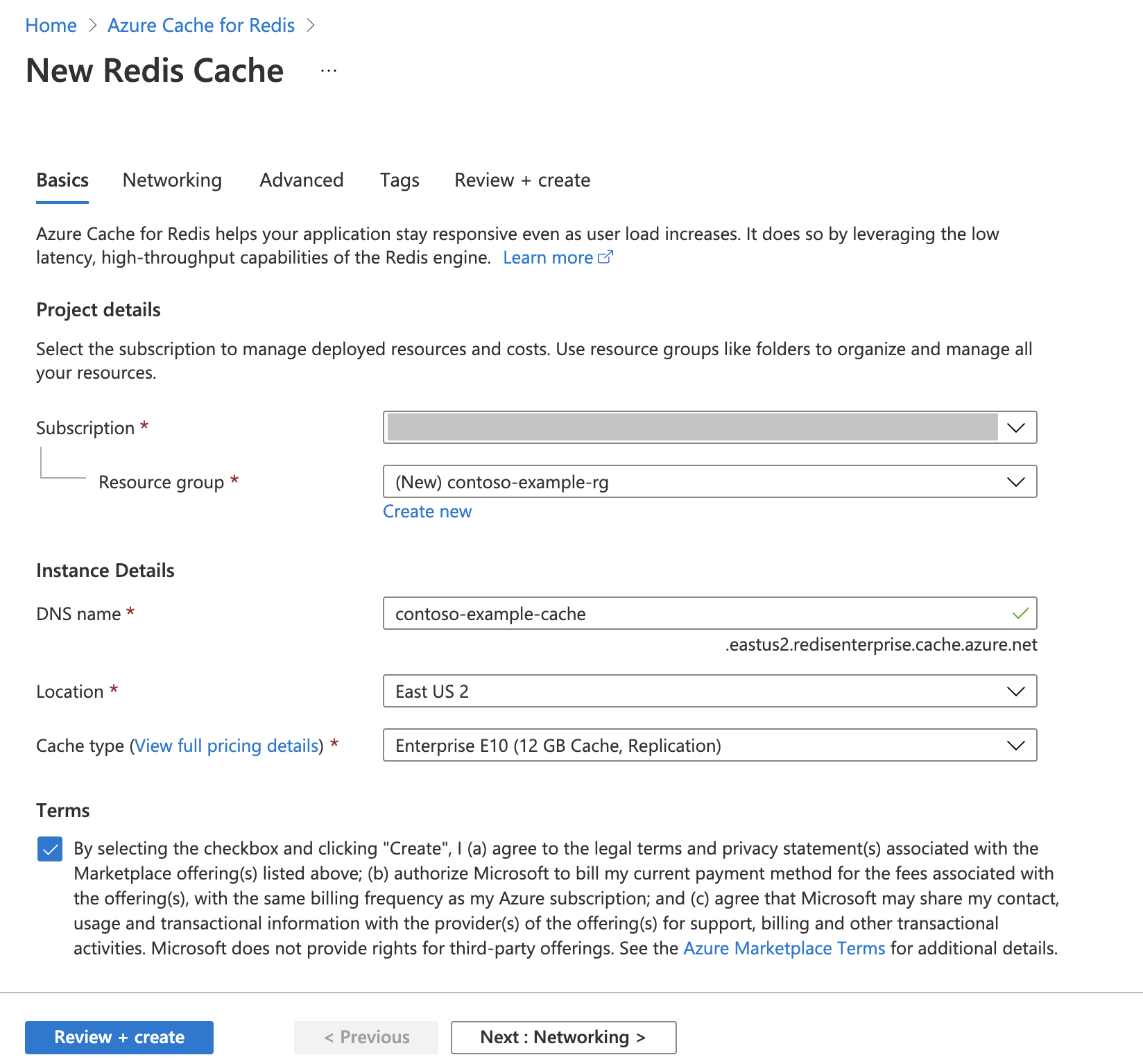
Vytvoření instance Azure Cache for Redis
Postupujte podle rychlého startu : Vytvoření průvodce mezipamětí Redis Enterprise. Na stránce Upřesnit se ujistěte, že jste přidali modul RediSearch a zvolili jste zásady podnikového clusteru. Všechna ostatní nastavení můžou odpovídat výchozímu nastavení popsanému v rychlém startu.
Vytvoření mezipaměti trvá několik minut. Mezitím můžete přejít k dalšímu kroku.
Nastavení vývojového prostředí
V místním počítači vytvořte složku s názvem redis-vector v umístění, kam obvykle ukládáte projekty.
Ve složce vytvořte nový soubor Pythonu (tutorial.py) nebo Jupyter Notebook (tutorial.ipynb).
Nainstalujte požadované balíčky Pythonu:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
Stažení datové sady
Ve webovém prohlížeči přejděte na https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots.
Přihlaste se nebo se zaregistrujte pomocí Kaggle. K stažení souboru se vyžaduje registrace.
Vyberte odkaz Stáhnout na Kaggle a stáhněte archive.zip soubor.
Extrahujte soubor archive.zip a přesuňte wiki_movie_plots_deduped.csv do složky redis-vector.
Import knihoven a nastavení informací o připojení
K úspěšnému volání azure OpenAI potřebujete koncový bod a klíč. Potřebujete také koncový bod a klíč pro připojení ke službě Azure Cache for Redis.
Na webu Azure Portal přejděte k prostředku Azure OpenAI.
V části Správa prostředků vyhledejte koncový bod a klíče. Zkopírujte koncový bod a přístupový klíč, protože budete potřebovat obojí pro ověřování volání rozhraní API. Ukázkový koncový bod je:
https://docs-test-001.openai.azure.com. Použít můžete předponuKEY1neboKEY2.Na webu Azure Portal přejděte na stránku Přehled vašeho prostředku Azure Cache for Redis. Zkopírujte koncový bod.
Vyhledejte přístupové klíče v části Nastavení . Zkopírujte přístupový klíč. Použít můžete předponu
PrimaryneboSecondary.Do nové buňky kódu přidejte následující kód:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"Aktualizujte hodnotu
API_KEYRESOURCE_ENDPOINTklíče a koncového bodu z nasazení Azure OpenAI.DEPLOYMENT_NAMEmělo by být nastaveno na název nasazení pomocítext-embedding-ada-002 (Version 2)modelu vkládání aMODEL_NAMEměl by se jednat o použitý konkrétní model vkládání.REDIS_PASSWORDAktualizujteREDIS_ENDPOINTkoncový bod a hodnotu klíče z instance Azure Cache for Redis.Důležité
Důrazně doporučujeme použít proměnné prostředí nebo správce tajných kódů, jako je Azure Key Vault , a předat tak informace o klíči rozhraní API, koncovém bodu a názvu nasazení. Tyto proměnné jsou zde nastaveny v prostém textu kvůli jednoduchosti.
Spusťte buňku kódu 2.
Import datové sady do knihovny pandas a zpracování dat
Potom soubor CSV přečtete do datového rámce pandas.
Do nové buňky kódu přidejte následující kód:
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfSpusťte buňku kódu 3. Měl by se zobrazit následující výstup:
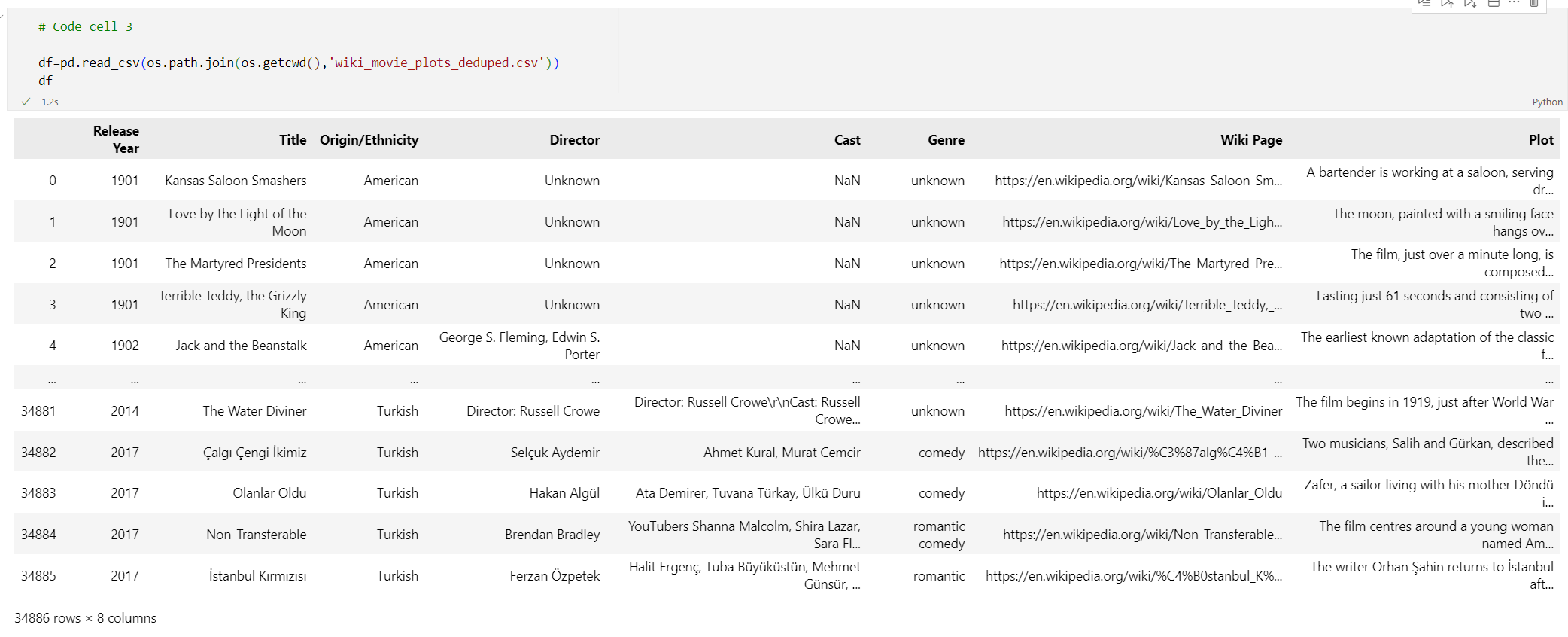
Potom zpracujte data přidáním indexu
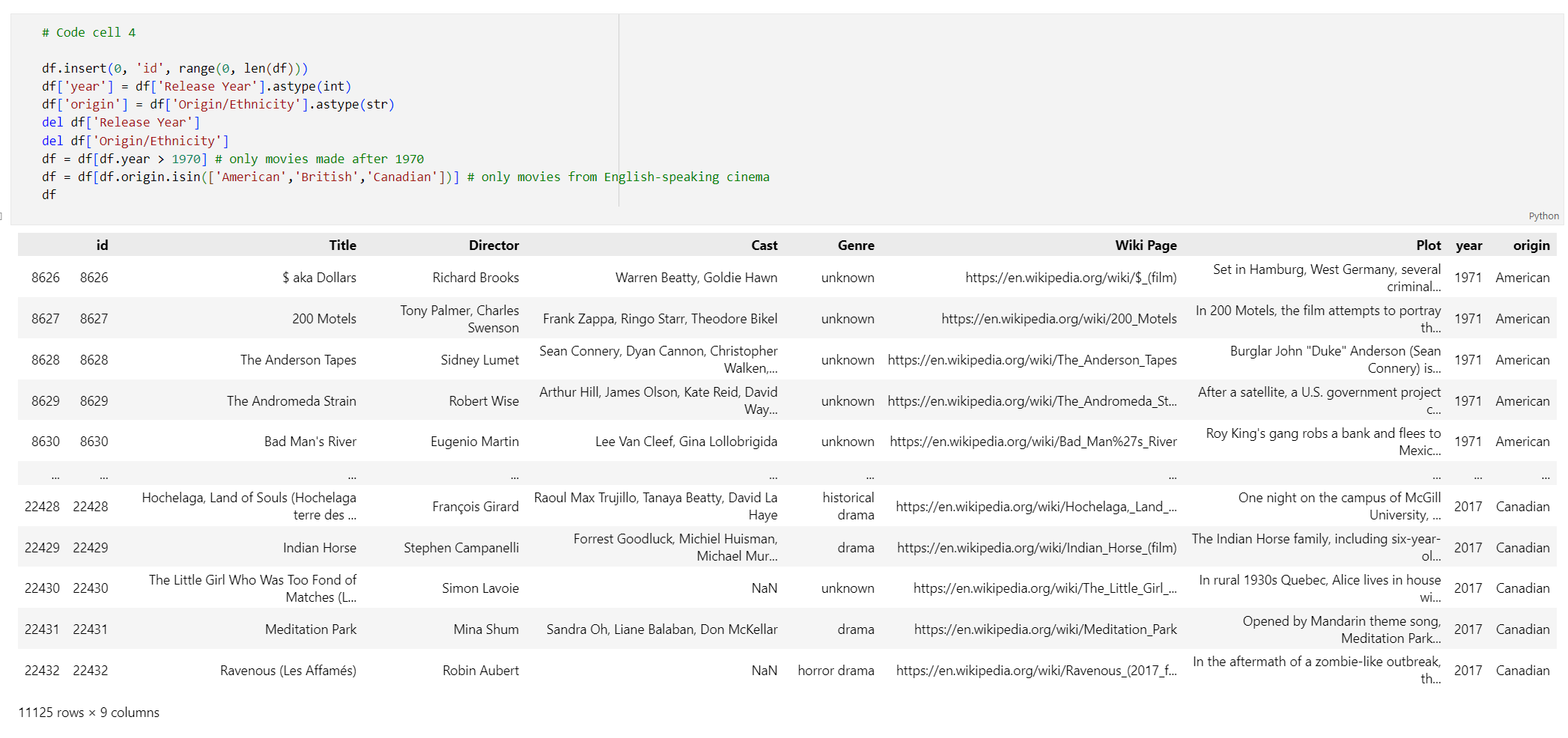
id, odebráním mezer z názvů sloupců a vyfiltrujte filmy tak, aby se po roce 1970 a z anglicky mluvících zemí nebo oblastí chytly jenom filmy vytvořené po roce 1970. Tento krok filtrování snižuje počet filmů v datové sadě, což snižuje náklady a čas potřebný k vygenerování vkládání. Na základě vašich předvoleb můžete parametry filtru změnit nebo odebrat.Pokud chcete data filtrovat, přidejte do nové buňky kódu následující kód:
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfSpusťte buňku kódu 4. Měly by se vám zobrazit následující výsledky:
Vytvořte funkci pro vyčištění dat odebráním prázdných znaků a interpunkce a pak ji použijte pro datový rámec obsahující graf.
Do nové buňky kódu přidejte následující kód a spusťte ho:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))Nakonec odeberte všechny položky, které obsahují popisy grafu, které jsou pro model vkládání příliš dlouhé. (Jinými slovy, vyžadují více tokenů než limit 8192 tokenů.) a pak vypočítejte počet tokenů potřebných k vygenerování vkládání. To má vliv také na ceny pro generování vkládání.
Do nové buňky kódu přidejte následující kód:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))Spusťte buňku kódu 6. Měli byste vidět tento výstup:
Number of movies: 11125 Number of tokens required:7044844Důležité
Projděte si ceny služby Azure OpenAI a vypočítejte náklady na generování vložených objektů na základě požadovaného počtu tokenů.


Načtení datového rámce do jazyka LangChain
Načtěte datový rámec do JazykChain pomocí DataFrameLoader třídy. Jakmile jsou data v dokumentech LangChain, je mnohem jednodušší používat knihovny LangChain ke generování vkládání a provádění vyhledávání podobností. Nastavte vykreslení jako hodnotu page_content_column , aby se v tomto sloupci vygenerovaly vložené hodnoty.
Do nové buňky kódu přidejte následující kód a spusťte ho:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
Generování vkládání a jejich načtení do Redis
Teď, když jsou data filtrovaná a načtená do LangChain, vytvoříte vkládání, abyste se mohli dotazovat na graf pro každý film. Následující kód nakonfiguruje Azure OpenAI, vygeneruje vkládání a načte vektory vkládání do Azure Cache for Redis.
Přidejte následující kód nové buňky kódu:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")Spusťte buňku kódu 8. Dokončení může trvat více než 30 minut. Vygeneruje
redis_schema.yamlse také soubor. Tento soubor je užitečný, pokud se chcete připojit k indexu v instanci Azure Cache for Redis bez opětovného generování vkládání.
Důležité
Rychlost generování vkládání závisí na kvótě dostupné pro model Azure OpenAI. Při kvótě 240 tisíc tokenů za minutu bude zpracování 7M tokenů v sadě dat trvat přibližně 30 minut.
Spouštění vektorových vyhledávacích dotazů
Teď, když máte nastavenou datovou sadu, rozhraní API služby Azure OpenAI a instanci Redis, můžete vyhledávat pomocí vektorů. V tomto příkladu se vrátí prvních 10 výsledků pro daný dotaz.
Do souboru kódu Pythonu přidejte následující kód:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Spusťte buňku kódu 9. Měl by se zobrazit následující výstup:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)Skóre podobnosti se vrátí spolu s pořadovým hodnocením filmů podle podobnosti. Všimněte si, že konkrétnější dotazy mají skóre podobnosti, rychleji se sníží v seznamu.
Hybridní vyhledávání
Vzhledem k tomu, že RediSearch také nabízí bohaté funkce vyhledávání nad vektorovým vyhledáváním, je možné filtrovat výsledky podle metadat v datové sadě, jako je filmový žánr, přetypování, rok vydání nebo režisér. V tomto případě filtr na základě žánru
comedy.Do nové buňky kódu přidejte následující kód:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Spusťte buňku kódu 10. Měl by se zobrazit následující výstup:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Se službou Azure Cache for Redis a Službou Azure OpenAI můžete do své aplikace přidat výkonné funkce vyhledávání pomocí vkládání a vektorové vyhledávání.
Vyčištění prostředků
Pokud chcete dál používat prostředky, které jste vytvořili v tomto článku, ponechte skupinu prostředků.
Jinak pokud jste s prostředky hotovi, můžete odstranit skupinu prostředků Azure, kterou jste vytvořili, abyste se vyhnuli poplatkům.
Důležité
Odstranění skupiny prostředků je nevratné. Při odstranění skupiny prostředků se všechny prostředky, které obsahuje, trvale odstraní. Ujistěte se, že nechtěně neodstraníte nesprávnou skupinu prostředků nebo prostředky. Pokud jste prostředky vytvořili v existující skupině prostředků, která obsahuje prostředky, které chcete zachovat, můžete každý prostředek odstranit jednotlivě místo odstranění skupiny prostředků.
Odstranění skupiny prostředků
Přihlaste se k portálu Azure Portal a potom vyberte Skupiny prostředků.
Vyberte skupinu prostředků, kterou chcete odstranit.
Pokud existuje mnoho skupin prostředků, použijte filtr pro jakékoli pole... zadejte název skupiny prostředků, kterou jste vytvořili pro tento článek. V seznamu výsledků vyberte skupinu prostředků.
Vyberte Odstranit skupinu prostředků.
Zobrazí se výzva k potvrzení odstranění skupiny prostředků. Potvrďte odstranění zadáním názvu vaší skupiny prostředků a vyberte Odstranit.
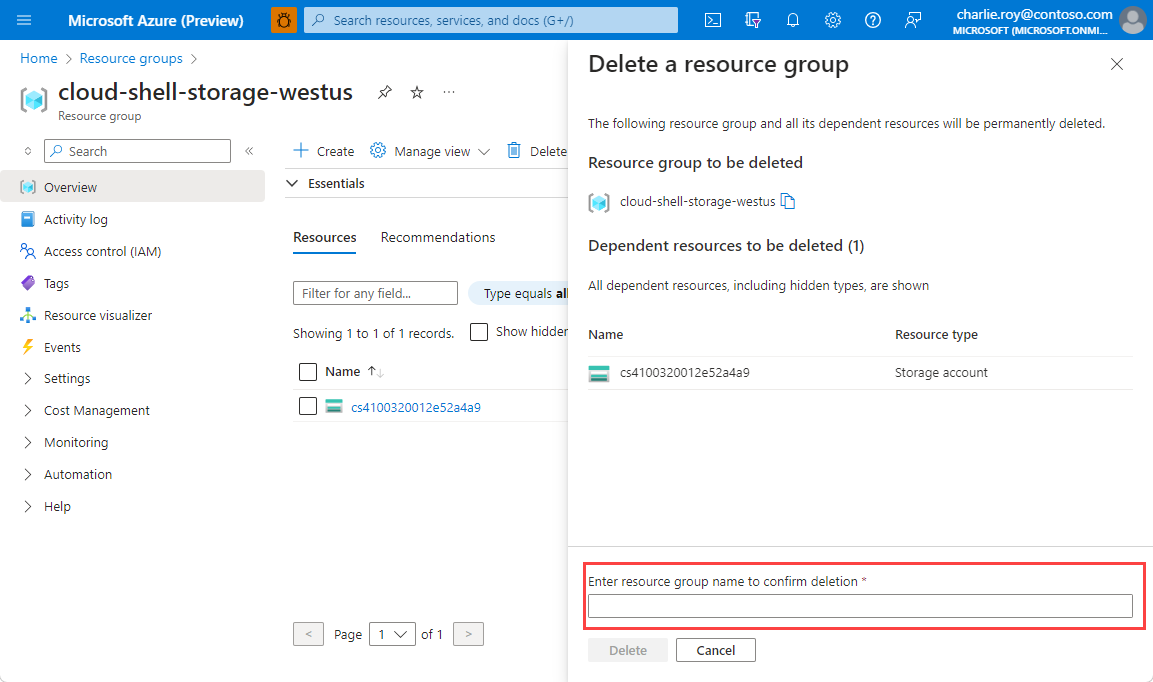
Po chvíli se skupina prostředků včetně všech prostředků, které obsahuje, odstraní.
Související obsah
- Další informace o službě Azure Cache for Redis
- Další informace o možnostech hledání vektorů Azure Cache for Redis
- Další informace o vkládání generovaných službou Azure OpenAI
- Další informace o kosinusové podobnosti
- Přečtěte si, jak vytvořit aplikaci využívající AI pomocí OpenAI a Redisu.
- Vytvoření aplikace Q&A pomocí sémantických odpovědí