Nasazení a testování důležitých úloh v Azure
Nasazení a testování klíčového prostředí je zásadní součástí celkové referenční architektury. Razítka jednotlivých aplikací se nasazují pomocí infrastruktury jako kódu z úložiště zdrojového kódu. Aktualizace do infrastruktury a aplikace by měla být nasazena s nulovým výpadkem aplikace. Kanál kontinuální integrace DevOps se doporučuje načíst zdrojový kód z úložiště a nasadit jednotlivé kolky v Azure.
Nasazení a aktualizace jsou ústředním procesem architektury. Aktualizace související s infrastrukturou a aplikacemi by se měly nasadit na plně nezávislé razítka. Kolky sdílí pouze globální komponenty infrastruktury v architektuře. Stávající razítka v infrastruktuře se nedotknou. Aktualizace infrastruktury se nasadí jenom do těchto nových razítek. Stejně tak se nová verze aplikace nasadí jenom do těchto nových razítek.
Nové razítka se přidají do služby Azure Front Door. Provoz se postupně přesouvá do nových razítek. Když zjistíte, že se provoz obsluhuje z nových kolků bez problému, předchozí razítka se odstraní.
Pro nasazené prostředí se doporučuje penetrace, chaos a zátěžové testování. Proaktivní testování infrastruktury zjistí slabé stránky a chování nasazené aplikace, pokud dojde k selhání.
Nasazení
Nasazení infrastruktury v referenční architektuře závisí na následujících procesech a komponentách:
DevOps – zdrojový kód z GitHubu a kanálů pro infrastrukturu.
Aktualizace nulového výpadku – Aktualizace a upgrady se nasazují do prostředí s nulovými výpadky nasazené aplikace.
Prostředí – krátkodobá a trvalá prostředí používaná pro architekturu.
Sdílené a vyhrazené prostředky – prostředky Azure, které jsou vyhrazené a sdílené s kolky a celkovou infrastrukturou.
Další informace najdete v tématu Nasazení a testování důležitých úloh v Azure: Aspekty návrhu
Nasazení: DevOps
Komponenty DevOps poskytují úložiště zdrojového kódu a kanály CI/CD pro nasazení infrastruktury a aktualizací. Jako komponenty byly vybrány GitHub a Azure Pipelines.
GitHub – Obsahuje úložiště zdrojového kódu pro aplikaci a infrastrukturu.
Azure Pipelines – Kanály používané architekturou pro všechny úlohy sestavení, testování a vydání.
Další komponentou v návrhu použitém pro nasazení jsou agenti sestavení. Agenti sestavení hostovaní Microsoftem se používají jako součást služby Azure Pipelines k nasazení infrastruktury a aktualizací. Použití agentů sestavení hostovaných Microsoftem eliminuje zatížení správy vývojářům při údržbě a aktualizaci agenta sestavení.
Další informace o Službě Azure Pipelines najdete v tématu Co je Azure DevOps Services?.

Další informace najdete v tématu Nasazení a testování důležitých úloh v Azure: Nasazení infrastruktury jako kódu
Nasazení: Aktualizace nulového výpadku
Strategie aktualizace nulového výpadku v referenční architektuře je centrální pro celkovou kritickou aplikaci. Metodologie nahrazení místo upgradu kolků zajišťuje čerstvou instalaci aplikace do razítka infrastruktury. Referenční architektura využívá modrý/zelený přístup a umožňuje samostatné testovací a vývojové prostředí.
Referenční architektura má dvě hlavní komponenty:
Infrastruktura – služby a prostředky Azure Nasazeno pomocí Terraformu a přidružené konfigurace.
Aplikace – hostovaná služba nebo aplikace, která obsluhuje uživatele. Na základě kontejnerů Dockeru a integrovaných artefaktů npm v HTML a JavaScriptu pro uživatelské rozhraní jednostránkové aplikace (SPA).
V mnoha systémech předpokládáme, že aktualizace aplikací budou častější než aktualizace infrastruktury. V důsledku toho se pro každý z nich vyvíjejí různé postupy aktualizace. S infrastrukturou veřejného cloudu se změny můžou provádět rychleji. Byl vybrán jeden proces nasazení pro aktualizace aplikací a aktualizace infrastruktury. Jedním z přístupů je, že se infrastruktura a aktualizace aplikací vždy synchronizují. Tento přístup umožňuje:
Jeden konzistentní proces – méně šancí na chyby v případě, že se aktualizace infrastruktury a aplikací směšují ve vydané verzi, úmyslně nebo ne.
Povolí nasazení Blue/Green – Každá aktualizace se nasadí s využitím postupné migrace provozu do nové verze.
Jednodušší nasazení a ladění aplikace – celé razítko nebude nikdy hostovat více verzí aplikace vedle sebe.
Jednoduché vrácení zpět – Provoz se dá přepnout zpět na razítka, která spouští předchozí verzi, pokud dojde k chybám nebo problémům.
Eliminace ručních změn a posunu konfigurace – Každé prostředí je nové nasazení.
Další informace najdete v tématu Nasazení a testování důležitých úloh v Azure: Dočasné modré/zelené nasazení
Strategie větvení
Základem strategie aktualizace je použití větví v úložišti Git. Referenční architektura používá tři typy větví:
| Pobočka | Popis |
|---|---|
feature/* a fix/* |
Vstupní body pro všechny změny. Tyto větve vytvářejí vývojáři a měly by mít popisný název, například feature/catalog-update nebo fix/worker-timeout-bug. Jakmile jsou změny připravené ke sloučení, vytvoří se žádost o přijetí změn (PR) vůči main větvi. Každé žádosti o přijetí změn musí schválit alespoň jeden kontrolor. S omezenými výjimkami musí každá změna navržená v žádosti o přijetí změn probíhat prostřednictvím kompletního ověřovacího kanálu (E2E). Kanál E2E by vývojáři měli používat k testování a ladění změn v kompletním prostředí. |
main |
Průběžný pohyb a stabilní větev. Většinou se používá k testování integrace. main Změny se provádějí jenom prostřednictvím žádostí o přijetí změn. Zásada větve zakazuje přímé zápisy. Noční vydané verze pro trvalé integration (int) prostředí se automaticky spustí z main větve. Větev je považována main za stabilní. V každém okamžiku by mělo být bezpečné předpokládat, že se z ní dá vytvořit verze. |
release/* |
Větve vydané verze se vytvářejí jenom z main větve. Větve se řídí formátem release/2021.7.X. Zásady větví se používají, aby větve mohli vytvářet release/* jenom správci úložiště. K nasazení do prod prostředí se používají pouze tyto větve. |
Další informace najdete v tématu Nasazení a testování důležitých úloh v Azure: Strategie větvení
Opravy hotfix
Pokud je oprava hotfix naléhavě nutná kvůli chybě nebo jinému problému a nemůže projít běžným procesem vydání, je k dispozici cesta opravy hotfix. Důležité aktualizace zabezpečení a opravy uživatelského prostředí, které nebyly zjištěny během počátečního testování, se považují za platné příklady oprav hotfix.
Oprava hotfix musí být vytvořena v nové fix větvi a poté sloučena s main použitím pravidelné žádosti o přijetí změn. Místo vytvoření nové větve vydané verze je oprava hotfix "cherry-picked" do existující větve vydané verze. Tato větev je už nasazená do prod prostředí. Kanál CI/CD, který původně nasadil větev verze se všemi testy, se znovu spustí a nyní nasadí opravu hotfix jako součást kanálu.
Aby nedocházelo k velkým problémům, je důležité, aby oprava hotfix obsahovala několik izolovaných potvrzení, která lze snadno vybrat a integrovat do větve vydané verze. Pokud se izolované potvrzení nedají vybrat, aby se integrovaly do větve vydané verze, znamená to, že změna není opravná jako oprava hotfix. Tato změna by se měla nasadit jako úplná nová verze a potenciálně se zkombinovat se zpětným vrácením do dřívější stabilní verze, dokud nebude možné novou verzi nasadit.
Nasazení: Prostředí
Referenční architektura používá pro infrastrukturu dva typy prostředí:
Krátkodobý – kanál ověřování E2E se používá k nasazení krátkodobých prostředí. Krátkodobá prostředí se používají k čistému ověřování nebo ladění prostředí pro vývojáře. Ověřovací prostředí je možné vytvořit z
feature/*větve, podléhat testům a poté zničit, pokud byly všechny testy úspěšné. Ladicí prostředí se nasazují stejným způsobem jako ověřování, ale neničí se okamžitě. Tato prostředí by neměla existovat déle než několik dní a měla by být odstraněna při sloučení odpovídající žádosti o přijetí změn větve funkcí.Trvalé – V trvalých prostředích existují
integration (int)aproduction (prod)verze. Tato prostředí jsou nepřetržitě aktivní a nezničí se. Prostředí používají pevné názvy domén, napříkladint.mission-critical.app. V reálné implementaci referenční architekturystagingby se mělo přidat (předem připravené) prostředí. Prostředístagingse používá k nasazení a ověřeníreleasevětví se stejným procesem aktualizace jakoprod(modré/zelené nasazení).Integrace (int) – Verze
intse nasadí v noci zmainvětve se stejným procesem jakoprod. Přechod provozu je rychlejší než předchozí jednotka vydané verze. Místo postupného přepínání provozu během několika dnů, jako je tomu vprodpřípadě, že se procesintdokončí během několika minut nebo hodin. Tento rychlejší přechod zajišťuje, že aktualizované prostředí bude připravené příští ráno. Pokud jsou všechny testy v kanálu úspěšné, staré razítka se automaticky odstraní.Produkční (prod) – Verze
prodse nasazuje jenom zrelease/*větví. Přepnutí provozu používá podrobnější kroky. Brána ručního schvalování je mezi jednotlivými kroky. Každá verze vytvoří nové regionální razítka a nasadí novou verzi aplikace do kolků. Stávající razítka se v procesu nedotknou. Nejdůležitějším aspektemprodje, že by měla být vždy zapnutá. K žádnému plánovanému nebo neplánovanému výpadku by nikdy nemělo dojít. Jedinou výjimkou jsou základní změny databázové vrstvy. Může být potřeba časové období plánované údržby.
Nasazení: Sdílené a vyhrazené prostředky
Trvalá prostředí (int a prod) v referenční architektuře mají různé typy prostředků v závislosti na tom, jestli jsou sdílená s celou infrastrukturou nebo vyhrazená pro jednotlivý kolek. Prostředky můžou být vyhrazené pro konkrétní verzi a existují pouze do převzetí další lekce verze.
Jednotky vydaných verzí
Jednotka vydání je několik regionálních kolků na konkrétní verzi verze. Razítka obsahují všechny prostředky, které nejsou sdíleny s ostatními razítky. Tyto prostředky jsou virtuální sítě, cluster Azure Kubernetes Service, Event Hubs a Azure Key Vault. Azure Cosmos DB a ACR jsou nakonfigurované se zdroji dat Terraformu.
Globálně sdílené prostředky
Všechny prostředky sdílené mezi jednotkami vydaných verzí jsou definovány v nezávislé šabloně Terraformu. Tyto prostředky jsou Front Door, Azure Cosmos DB, Container Registry (ACR) a pracovní prostory služby Log Analytics a další prostředky související s monitorováním. Tyto prostředky se nasadí před nasazením prvního místního razítka jednotky vydané verze. Na prostředky se odkazuje v šablonách Terraformu pro razítka.
Front Door
Front Door je globálně sdílený prostředek napříč kolky, ale jeho konfigurace se mírně liší od ostatních globálních prostředků. Po nasazení nového razítka musí být služba Front Door znovu nakonfigurovaná. Front Door musí být překonfigurovaný tak, aby postupně přepínal provoz na nové kolky.
Konfiguraci back-endu služby Front Door není možné přímo definovat v šabloně Terraformu. Konfigurace se vloží s proměnnými Terraformu. Hodnoty proměnných se vytvářejí před spuštěním nasazení Terraformu.
Konfigurace jednotlivých komponent pro nasazení služby Front Door je definována takto:
Front-end – Spřažení relace je nakonfigurované tak, aby uživatelé během jedné relace nepřepínali mezi různými verzemi uživatelského rozhraní.
Původy – Služba Front Door je nakonfigurovaná se dvěma typy skupin původu:
Skupina původu pro statické úložiště, která obsluhuje uživatelské rozhraní. Skupina obsahuje účty úložiště webu ze všech aktuálně aktivních jednotek vydaných verzí. Různé váhy lze přiřadit k původu z různých jednotek vydávání, aby se provoz postupně přesunul na novější jednotku. Každý původ z jednotky uvolnění by měl mít přiřazenou stejnou hmotnost.
Skupina původu pro rozhraní API, která je hostovaná v AKS. Pokud existují jednotky vydaných verzí s různými verzemi rozhraní API, existuje skupina původu rozhraní API pro každou jednotku vydané verze. Pokud všechny jednotky vydaných verzí nabízejí stejné kompatibilní rozhraní API, všechny zdroje se přidají do stejné skupiny a přiřadí se různé váhy.
Pravidla směrování – Existují dva typy pravidel směrování:
Pravidlo směrování pro uživatelské rozhraní propojené se skupinou původu úložiště uživatelského rozhraní.
Pravidlo směrování pro každé rozhraní API aktuálně podporované zdroji Například:
/api/1.0/*a/api/2.0/*
Pokud verze zavádí novou verzi back-endových rozhraní API, změny se projeví v uživatelském rozhraní, které je nasazené v rámci vydání. Konkrétní verze uživatelského rozhraní bude vždy volat konkrétní verzi adresy URL rozhraní API. Uživatelé obsluhovaní verzí uživatelského rozhraní automaticky použijí příslušné back-endové rozhraní API. Pro různé instance verze rozhraní API jsou potřeba konkrétní pravidla směrování. Tato pravidla jsou propojená s odpovídajícími skupinami původu. Pokud nové rozhraní API nebylo zavedeno, všechna pravidla směrování související s rozhraním API odkazují na jednu skupinu původu. V tomto případě nezáleží na tom, jestli se uživateli obsluhuje uživatelské rozhraní z jiné verze než rozhraní API.
Nasazení: Proces nasazení
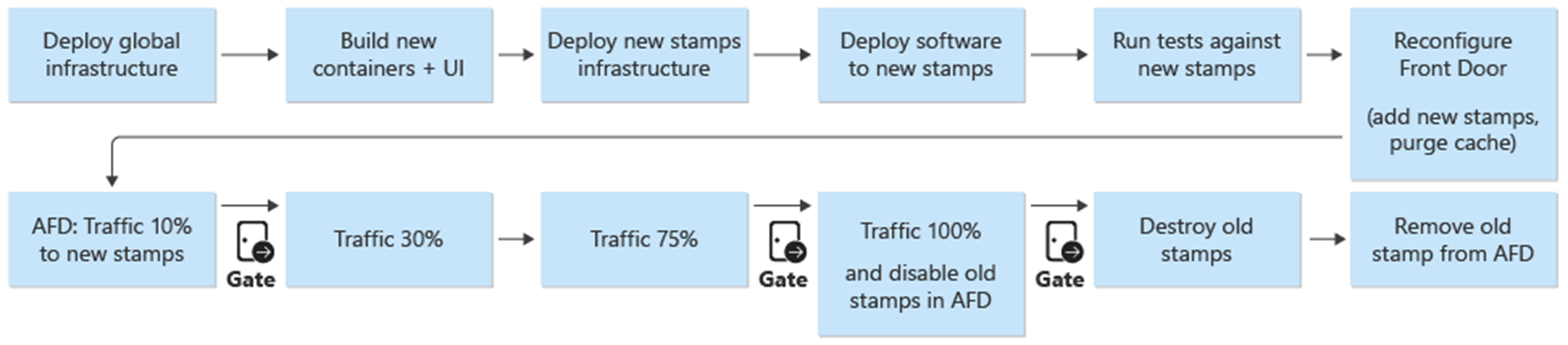
Modré/zelené nasazení je cílem procesu nasazení. Do prostředí se nasadí prod nová verze z release/* větve. Uživatelský provoz se postupně přesouvá na razítka nové verze.
Jako první krok v procesu nasazení nové verze se s Terraformem nasadí infrastruktura pro novou jednotku verze. Spuštění kanálu nasazení infrastruktury nasadí novou infrastrukturu z vybrané větve verze. Souběžně se zřizováním infrastruktury se image kontejnerů sestavují nebo importují a odesílají do globálně sdíleného registru kontejneru (ACR). Po dokončení předchozích procesů se aplikace nasadí do kolků. Z hlediska implementace je to jeden kanál s několika závislými fázemi. Stejný kanál lze znovu spustit pro nasazení oprav hotfix.
Po nasazení a ověření nové lekce vydané verze se přidá do služby Front Door, aby přijímala uživatelský provoz.
Přepínač/parametr, který rozlišuje mezi verzemi, které dělají a nezavádějí novou verzi rozhraní API, by se měl naplánovat. Na základě toho, jestli verze zavádí novou verzi rozhraní API, je potřeba vytvořit novou skupinu původu s back-endy rozhraní API. Alternativně je možné nové back-endy rozhraní API přidat do existující skupiny původu. Nové účty úložiště uživatelského rozhraní se přidají do odpovídající existující skupiny původu. Váhy pro nové původy by měly být nastaveny podle požadovaného rozdělení provozu. Je nutné vytvořit nové pravidlo směrování, jak je popsáno výše, které odpovídá příslušné skupině původu.
V rámci přidání nové jednotky vydávání verzí by měly být váhy nových zdrojů nastaveny na požadovaný minimální uživatelský provoz. Pokud se nezjistí žádné problémy, mělo by se během časového období zvýšit množství provozu uživatelů na novou skupinu původu. Pokud chcete upravit parametry hmotnosti, měli byste stejný postup nasazení provést znovu s požadovanými hodnotami.
Uvolnění jednotek
V rámci kanálu nasazení pro jednotku verze existuje fáze zničení, která odebere všechna razítka, jakmile už jednotku verze nepotřebujete. Veškerý provoz se přesune do nové verze vydané verze. Tato fáze zahrnuje odebrání odkazů na jednotky vydané verze ze služby Front Door. Toto odebrání je důležité pro povolení vydání nové verze později. Front Door musí odkazovat na jednu jednotku vydání, aby bylo možné připravit na další verzi v budoucnu.
Kontrolní seznamy
V rámci četnosti vydávání verzí by se měl použít kontrolní seznam předběžného a po vydání. Následující příklad je položek, které by měly být v libovolném kontrolním seznamu minimálně.
Kontrolní seznam před vydáním – Před zahájením verze zkontrolujte následující:
Ujistěte se, že se v prostředí úspěšně nasadil a otestoval
intnejnovější stavmainvětve.Aktualizujte soubor protokolu změn prostřednictvím žádosti o přijetí změn ve
mainvětvi.Vytvořte
release/větev zmainvětve.
Kontrolní seznam po vydání – Před zničením starých razítek a jejich odkazy se ze služby Front Door odeberou, zkontrolujte, že:
Clustery už nedostávají příchozí provoz.
Event Hubs a jiné fronty zpráv neobsahují žádné nezpracované zprávy.
Nasazení: Omezení a rizika strategie aktualizace
Strategie aktualizací popsaná v této referenční architektuře má určitá omezení a rizika, která by se měla zmínit:
Vyšší náklady – při vydávání aktualizací je mnoho komponent infrastruktury aktivních dvakrát po dobu vydání.
Složitost služby Front Door – Proces aktualizace ve službě Front Door je složitý pro implementaci a údržbu. Schopnost spouštět efektivní modrá/zelená nasazení s nulovými výpadky závisí na tom, že funguje správně.
Malé změny časově náročné – proces aktualizace vede k delšímu procesu vydávání malých změn. Toto omezení lze částečně zmírnit procesem opravy hotfix popsaným v předchozí části.
Nasazení: Aspekty kompatibility předávání dat aplikací
Strategie aktualizace může podporovat více verzí rozhraní API a pracovních komponent spuštěných souběžně. Vzhledem k tomu, že se služba Azure Cosmos DB sdílí mezi dvěma nebo více verzemi, je možné, že datové prvky změněné jednou verzí nemusí vždy odpovídat verzi rozhraní API nebo pracovních procesů, které ho využívají. Vrstvy rozhraní API a pracovní procesy musí implementovat návrh kompatibility vpřed. Starší verze rozhraní API nebo pracovních komponent zpracovávají data vložená novější verzí rozhraní API nebo součásti pracovního procesu. Ignoruje části, kterým nerozumí.
Testování
Referenční architektura obsahuje různé testy používané v různých fázích v rámci implementace testování.
Mezi tyto testy patří:
Testy jednotek – tyto testy ověřují, že obchodní logika aplikace funguje podle očekávání. Referenční architektura obsahuje ukázkovou sadu testů jednotek spouštěných automaticky před každým sestavením kontejneru službou Azure Pipelines. Pokud některý test selže, kanál se zastaví. Sestavení a nasazení nebude pokračovat.
Zátěžové testy – tyto testy pomáhají vyhodnotit kapacitu, škálovatelnost a potenciální kritické body pro danou úlohu nebo zásobník. Referenční implementace obsahuje generátor zatížení uživatele k vytvoření syntetických vzorů zatížení, které lze použít k simulaci skutečného provozu. Generátor zatížení lze použít také nezávisle na referenční implementaci.
Orientační testy – tyto testy identifikují, jestli je infrastruktura a úloha k dispozici, a fungují podle očekávání. Orientační testy se spouští jako součást každého nasazení.
Testy uživatelského rozhraní – Tyto testy ověřují, že uživatelské rozhraní bylo nasazeno a funguje podle očekávání. Aktuální implementace zachytává snímky obrazovek několika stránek po nasazení bez skutečného testování.
Testy injektáže selhání – Tyto testy je možné automatizovat nebo spouštět ručně. Automatizované testování v architektuře integruje Azure Chaos Studio jako součást kanálů nasazení.
Další informace najdete v tématu Nasazení a testování důležitých úloh v Azure: Průběžné ověřování a testování
Testování: Architektury
Online referenční implementace existující testovací funkce a architektury kdykoli je to možné.
| Framework | Test | Popis |
|---|---|---|
| NUnit | Unit | Tato architektura se používá k testování částí implementace v .NET Core. Testy jednotek se spouští automaticky službou Azure Pipelines před sestaveními kontejnerů. |
| JMeter s využitím zátěžového testování Azure | Načítání | Azure Load Testing je spravovaná služba používaná ke spouštění definic zátěžových testů Apache JMeter . |
| Locust | Načítání | Python je opensourcová architektura zátěžového testování napsaná v Pythonu. |
| Dramatik | Uživatelské rozhraní a kouř | Playwright je opensourcová knihovna Node.js pro automatizaci Chromium, Firefoxu a WebKitu pomocí jednoho rozhraní API. Definici testu Playwright lze použít také nezávisle na referenční implementaci. |
| Azure Chaos Studio | Injektáž selhání | Referenční implementace používá Azure Chaos Studio jako volitelný krok v kanálu ověřování E2E k vložení selhání pro ověření odolnosti. |
Testování: Testování injektáže selhání a chaos engineering
Distribuované aplikace by měly být odolné vůči výpadkům služeb a komponent. Testování injektáže selhání (označované také jako injektáž chyb nebo chaos engineering) je praxe, kdy se aplikace a služby zabývají skutečnými stresy a selháními.
Odolnost je vlastnost celého systému a vkládání chyb pomáhá najít problémy v aplikaci. Řešení těchto problémů pomáhá ověřit odolnost aplikací vůči nespolehlivým podmínkám, chybějícím závislostem a dalším chybám.
Ruční a automatické testy je možné spouštět na infrastruktuře, aby se zjistily chyby a problémy v implementaci.
Automatic (Automaticky)
Referenční architektura integruje Azure Chaos Studio k nasazení a spuštění sady experimentů Azure Chaos Studio pro vkládání různých chyb na úrovni kolku. Experimenty chaosu je možné spustit jako volitelnou součást kanálu nasazení E2E. Při provádění testů se volitelný zátěžový test vždy spustí paralelně. Zátěžový test se používá k vytvoření zatížení clusteru k ověření účinku vloženého selhání.
Ruční
Testování ručního injektáže selhání by mělo být provedeno v ověřovacím prostředí E2E. Toto prostředí zajišťuje úplné reprezentativní testy bez rizika zásahu z jiných prostředí. Většinu selhání vygenerovaných pomocí testů je možné pozorovat přímo v zobrazení metrik Aplikace Přehledy Live. Zbývající chyby jsou k dispozici v zobrazení Selhání a odpovídajících tabulkách protokolu. Jiná selhání vyžadují hlubší ladění, například použití kubectl k sledování chování uvnitř AKS.
Mezi dva příklady testů injektáže selhání provedených v referenční architektuře patří:
Injektáž selhání založená na DNS – testovací případ, který dokáže simulovat více problémů. Selhání překladu DNS kvůli selhání serveru DNS nebo Azure DNS. Testování založené na DNS může pomoct simulovat obecné problémy s připojením mezi klientem a službou, například když se BackgroundProcessor nemůže připojit k Event Hubs.
Ve scénářích s jedním hostitelem můžete místní soubor upravit
hoststak, aby přepsal překlad DNS. Ve větším prostředí s několika dynamickými servery, jako je AKS,hostsnení soubor proveditelný. Zóny Azure Privátní DNS je možné použít jako alternativu ke scénářům selhání testů.Azure Event Hubs a Azure Cosmos DB jsou dvě služby Azure používané v rámci referenční implementace, které je možné použít k vkládání selhání založených na DNS. Překlad DNS služby Event Hubs je možné manipulovat s zónou Azure Privátní DNS svázanou s virtuální sítí jednoho z kolků. Azure Cosmos DB je globálně replikovaná služba s konkrétními regionálními koncovými body. Manipulace se záznamy DNS pro tyto koncové body může simulovat selhání pro konkrétní oblast a otestovat převzetí služeb při selhání klientů.
Blokování brány firewall – Většina služeb Azure podporuje omezení přístupu k bráně firewall na základě virtuálních sítí nebo IP adres. V referenční infrastruktuře se tato omezení používají k omezení přístupu ke službě Azure Cosmos DB nebo event Hubs. Jednoduchým postupem je odebrat existující pravidla Povolit nebo přidat nová pravidla blokování . Tento postup může simulovat chybné konfigurace brány firewall nebo výpadky služeb.
Následující ukázkové služby v referenční implementaci je možné testovat pomocí testu brány firewall:
Služba Výsledek Key Vault Když je přístup ke službě Key Vault zablokovaný, nejpřímějším účinkem bylo selhání nových podů, které se mají vytvořit. Ovladač CSI služby Key Vault, který načítá tajné kódy při spuštění podu, nemůže provádět své úlohy a brání spuštění podu. Odpovídající chybové zprávy lze pozorovat s kubectl describe po CatalogService-deploy-my-new-pod -n workload. Stávající pody budou i nadále fungovat, i když se zobrazí stejná chybová zpráva. Chybová zpráva se generuje výsledky pravidelné kontroly aktualizací tajných kódů. I když není testovaný, předpokládá se, že spuštění nasazení nebude fungovat, když je služba Key Vault nepřístupná. Úlohy Terraformu a Azure CLI v rámci spuštění kanálu zpřístupňuje požadavky do služby Key Vault.Event Hubs Pokud je přístup ke službě Event Hubs zablokovaný, nové zprávy odeslané službou CatalogService a HealthService selžou. Načítání zpráv pomocí BackgroundProcess pomalu selže s celkovým selháním během několika minut. Azure Cosmos DB Odebrání stávajících zásad brány firewall pro virtuální síť způsobí, že služba Health Service začne selhávat s minimální prodlevou. Tento postup simuluje pouze konkrétní případ, celý výpadek služby Azure Cosmos DB. Většina případů selhání, ke kterým dochází na regionální úrovni, by se měla zmírnit automaticky transparentním převzetím služeb při selhání klienta do jiné oblasti Služby Azure Cosmos DB. Dříve popsané testování injektáže selhání založené na DNS je smysluplnější test pro službu Azure Cosmos DB. Container Registry (ACR) Když je přístup k ACR zablokovaný, vytváření nových podů, které byly načítané a uložené dříve v mezipaměti na uzlu AKS, bude fungovat i nadále. Vytvoření stále funguje kvůli příznaku pullPolicy=IfNotPresentnasazení k8s . Uzly, které image nepřetáhly a ukládaly do mezipaměti předtím, než blok nemůže vytvořit nový pod a okamžitě selže s chybamiErrImagePull.kubectl describe podzobrazí odpovídající403 Forbiddenzprávu.Load Balancer příchozího přenosu dat AKS Změna příchozích pravidel pro http(S) (porty 80 a 443) ve skupině zabezpečení sítě spravované službou AKS (NSG) na Odepření způsobí, že se provoz sondy stavu uživatele nebo sondy stavu nedosahne do clusteru. Test tohoto selhání je obtížné určit původní příčinu, která byla simulována jako blokování mezi síťovou cestou služby Front Door a regionálním razítkem. Front Door okamžitě zjistí toto selhání a vytáhl razítko z rotace.