Architektura velkých objemů dat je navržená tak, aby zpracovávala příjem, zpracování a analýzu dat, která jsou pro tradiční databázové systémy příliš velká nebo složitá.

Řešení pro velké objemy dat obvykle zahrnují jeden nebo více z následujících typů úloh:
- Dávkové zpracování neaktivních zdrojů velkých objemů dat
- Zpracování velkých objemů dat v reálném čase během pohybu
- Interaktivní zkoumání velkých objemů dat
- Prediktivní analýza a strojové učení
Většina architektur pro velké objemy dat zahrnuje některé nebo všechny následující komponenty:
zdroje dat: Všechna řešení pro velké objemy dat začínají jedním nebo více zdroji dat. Mezi příklady patří:
- Úložiště dat aplikací, jako jsou relační databáze.
- Statické soubory vytvořené aplikacemi, například soubory protokolu webového serveru.
- Zdroje dat v reálném čase, jako jsou zařízení IoT.
úložiště dat: Data pro operace dávkového zpracování jsou obvykle uložená v distribuovaném úložišti souborů, které mohou obsahovat velké objemy velkých souborů v různých formátech. Tento druh úložiště se často nazývá data lake. Mezi možnosti implementace tohoto úložiště patří Azure Data Lake Store nebo kontejnery objektů blob ve službě Azure Storage.
dávkové zpracování: Vzhledem k tomu, že datové sady jsou tak velké, často musí řešení pro velké objemy dat zpracovávat datové soubory pomocí dlouhotrvajících dávkových úloh k filtrování, agregaci a další přípravě dat na analýzu. Tyto úlohy obvykle zahrnují čtení zdrojových souborů, jejich zpracování a zápis výstupu do nových souborů. Mezi možnosti patří použití toků dat, datových kanálů v Microsoft Fabric.
příjem zpráv v reálném čase: Pokud řešení obsahuje zdroje v reálném čase, architektura musí obsahovat způsob, jak zachytit a ukládat zprávy v reálném čase pro zpracování datových proudů. Může se jednat o jednoduché úložiště dat, ve kterém se příchozí zprávy zahodí do složky pro zpracování. Mnoho řešení však potřebuje úložiště pro příjem zpráv, které funguje jako vyrovnávací paměť pro zprávy, a podporuje zpracování horizontálního navýšení kapacity, spolehlivé doručování a další sémantiku řízení front zpráv. Mezi možnosti patří Azure Event Hubs, Azure IoT Hubs a Kafka.
zpracování streamu: Po zachycení zpráv v reálném čase je řešení musí zpracovat filtrováním, agregací a jinak přípravou dat na analýzu. Zpracovaná data datového proudu se pak zapíšou do výstupní jímky. Azure Stream Analytics poskytuje službu spravovaného zpracování datových proudů na základě časově běžících dotazů SQL, které pracují s nevázanými streamy. Další možností je použití inteligentních funkcí v reálném čase v Microsoft Fabric, která umožňuje spouštět dotazy KQL při ingestování dat.
analytického úložiště dat: Mnoho řešení pro velké objemy dat připraví data k analýze a pak zpracovávaná data obsluhuje ve strukturovaném formátu, na který je možné dotazovat pomocí analytických nástrojů. Analytické úložiště dat, které slouží k poskytování těchto dotazů, může být relační datový sklad ve stylu Kimball, jak je vidět ve většině tradičních řešení business intelligence (BI) nebo u jezerahouse s architekturou medailiónu (bronzová, stříbrná a zlatá). Azure Synapse Analytics poskytuje spravovanou službu pro rozsáhlé cloudové datové sklady. Microsoft Fabric také nabízí obě možnosti – sklad i lakehouse – které se dají dotazovat pomocí SQL a Sparku.
analýza a vytváření sestav: Cílem většiny řešení pro velké objemy dat je poskytnout přehled o datech prostřednictvím analýzy a vytváření sestav. Aby uživatelé mohli analyzovat data, může architektura zahrnovat vrstvu modelování dat, jako je multidimenzionální datová krychle OLAP nebo tabulkový datový model ve službě Azure Analysis Services. Může také podporovat samoobslužné funkce BI pomocí technologií modelování a vizualizací v Microsoft Power BI nebo Microsoft Excelu. Analýza a vytváření sestav můžou mít také podobu interaktivního zkoumání dat datovými vědci nebo datovými analytiky. V těchto scénářích poskytuje Microsoft Fabric nástroje, jako jsou poznámkové bloky, ve kterých si uživatel může zvolit JAZYK SQL nebo programovací jazyk podle svého výběru.
orchestrace: Většina řešení pro velké objemy dat se skládá z opakovaných operací zpracování dat, zapouzdřených v pracovních postupech, které transformují zdrojová data, přesouvají data mezi více zdroji a jímky, načítají zpracovávaná data do analytického úložiště dat nebo nasdílí výsledky přímo do sestavy nebo řídicího panelu. K automatizaci těchto pracovních postupů můžete použít technologii orchestrace, jako jsou kanály Azure Data Factory nebo Microsoft Fabric.
Azure zahrnuje mnoho služeb, které je možné použít v architektuře velkých objemů dat. Spadají zhruba do dvou kategorií:
- Spravované služby, včetně Microsoft Fabric, Azure Data Lake Store, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hubs, Azure IoT Hub a Azure Data Factory
- Opensourcové technologie založené na platformě Apache Hadoop, včetně HDFS, HBase, Hive, Sparku a Kafka. Tyto technologie jsou k dispozici v Azure ve službě Azure HDInsight.
Tyto možnosti se vzájemně nevylučují a mnoho řešení kombinuje opensourcové technologie se službami Azure.
Kdy použít tuto architekturu
Tento styl architektury zvažte, pokud potřebujete:
- Ukládání a zpracování dat ve svazcích je příliš velké pro tradiční databázi.
- Transformujte nestrukturovaná data pro analýzu a vytváření sestav.
- Zachytávání, zpracování a analýza nevázaných datových proudů v reálném čase nebo s nízkou latencí
- Použijte Azure Machine Learning nebo Azure Cognitive Services.
Výhody
- technologické volby. V clusterech HDInsight můžete kombinovat a spárovat spravované služby Azure a technologie Apache, abyste mohli využít stávající dovednosti nebo investice do technologií.
- Výkon prostřednictvím paralelismu. Řešení pro velké objemy dat využívají paralelismus a umožňují vysoce výkonná řešení, která se škálují na velké objemy dat.
- elastické škálovací. Všechny komponenty v architektuře pro velké objemy dat podporují zřizování škálování na více instancí, abyste mohli řešení upravit na malé nebo velké úlohy a platit jenom za prostředky, které používáte.
- interoperabilita se stávajícími řešeními. Komponenty architektury velkých objemů dat se také používají pro zpracování IoT a podniková řešení BI, která umožňují vytvořit integrované řešení napříč datovými úlohami.
Výzvy
- složitosti. Řešení pro velké objemy dat můžou být extrémně složitá, s mnoha komponentami pro zpracování příjmu dat z více zdrojů dat. Vytváření, testování a řešení potíží s procesy velkých objemů dat může být náročné. Kromě toho může existovat velký počet nastavení konfigurace v několika systémech, které je potřeba použít k optimalizaci výkonu.
- sady dovedností . Mnoho technologií pro velké objemy dat je vysoce specializované a používají architektury a jazyky, které nejsou typické pro obecnější architektury aplikací. Naproti tomu technologie pro velké objemy dat vyvíjejí nová rozhraní API, která vycházejí z více zavedených jazyků.
- technologická vyspělost. Řada technologií používaných ve velkých objemech dat se vyvíjí. I když se základní technologie Hadoop, jako je Hive a Spark, stabilizovaly, nově vznikající technologie, jako je delta nebo ledovec, přinášejí rozsáhlé změny a vylepšení. Spravované služby, jako je Microsoft Fabric, jsou relativně mladé, ve srovnání s jinými službami Azure a budou se pravděpodobně v průběhu času vyvíjet.
- zabezpečení. Řešení pro velké objemy dat obvykle spoléhají na ukládání všech statických dat v centralizované datové jezeře. Zabezpečení přístupu k datům může být náročné, zejména pokud je potřeba přijímat a využívat více aplikací a platforem.
Osvědčené postupy
Využití paralelismu. Většina technologií zpracování velkých objemů dat distribuuje úlohy napříč několika jednotkami zpracování. To vyžaduje vytvoření a uložení statických datových souborů v rozděleném formátu. Distribuované systémy souborů, jako je HDFS, můžou optimalizovat výkon čtení a zápisu a skutečné zpracování provádí několik uzlů clusteru paralelně, což snižuje celkovou dobu úloh. Použití rozděleného datového formátu se důrazně doporučuje, například Parquet.
Rozdělení dat. Dávkové zpracování obvykle probíhá v opakujícím se plánu – například týdně nebo měsíčně. Rozdělte datové soubory a datové struktury, jako jsou tabulky, na základě časových období, která odpovídají plánu zpracování. To zjednodušuje příjem dat a plánování úloh a usnadňuje řešení potíží se selháními. Také dělení tabulek, které se používají v dotazech Hive, Spark nebo SQL, může výrazně zlepšit výkon dotazů.
Použít sémantiku schématu při čtení. Použití datového jezera umožňuje kombinovat úložiště pro soubory ve více formátech, ať už strukturované, částečně strukturované nebo nestrukturované. Použijte schématu při čtení sémantiku, která při zpracování dat projektuje schéma na data, ne při uložení dat. Tím se do řešení zabuduje flexibilita a brání kritickým bodům během příjmu dat způsobeným ověřením dat a kontrolou typů.
Zpracovávat data na místě. Tradiční řešení BI často používají proces extrakce, transformace a načítání (ETL) k přesunu dat do datového skladu. S většími objemy dat a většími formáty používají řešení pro velké objemy dat obecně varianty ETL, jako je transformace, extrakce a načítání (TEL). Díky tomuto přístupu se data zpracovávají v distribuovaném úložišti dat a před přesunem transformovaných dat do analytického úložiště dat je transformují na požadovanou strukturu.
Náklady na zůstatek a časové náklady. U úloh dávkového zpracování je důležité vzít v úvahu dva faktory: náklady na jednotku výpočetních uzlů a náklady na minutu používání těchto uzlů k dokončení úlohy. Například dávková úloha může trvat osm hodin se čtyřmi uzly clusteru. Může se ale stát, že úloha používá všechny čtyři uzly pouze během prvních dvou hodin a potom se vyžadují jenom dva uzly. V takovém případě by spuštění celé úlohy na dvouuzch V některých obchodních scénářích může být delší doba zpracování vhodnější než vyšší náklady na používání nevyužitých prostředků clusteru.
samostatné prostředky. Pokud je to možné, snažte se oddělit prostředky na základě úloh, abyste se vyhnuli scénářům, jako je jedna úloha, pomocí všech prostředků, zatímco ostatní čekají.
Orchestrace příjmu dat. V některých případech můžou stávající obchodní aplikace zapisovat datové soubory pro dávkové zpracování přímo do kontejnerů objektů blob úložiště Azure, kde je můžou využívat podřízené služby, jako je Microsoft Fabric. Často ale budete muset orchestrovat příjem dat z místních nebo externích zdrojů dat do datového jezera. K dosažení tohoto postupu použijte pracovní postup orchestrace nebo kanál, jako jsou například kanály podporované službou Azure Data Factory nebo Microsoft Fabric, předvídatelným a centrálně spravovatelným způsobem.
v rané fáziscrubovat citlivá data . Pracovní postup příjmu dat by měl v rané fázi procesu vyčistit citlivá data, aby se zabránilo jejich uložení v datovém jezeře.
Architektura IoT
Internet věcí (IoT) je specializovaná podmnožina řešení pro velké objemy dat. Následující diagram znázorňuje možnou logickou architekturu pro IoT. Diagram zdůrazňuje komponenty streamování událostí architektury.
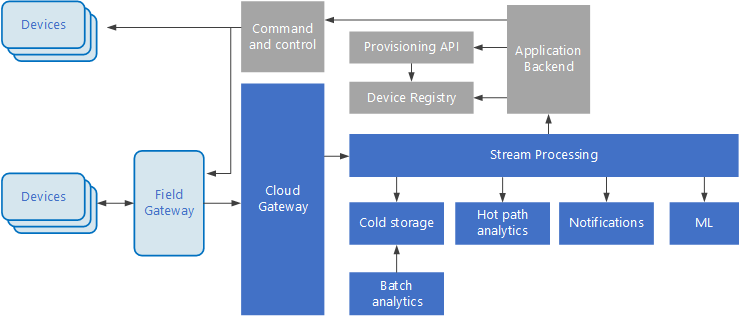
Cloudová brána ingestuje události zařízení na hranici cloudu pomocí spolehlivého systému zasílání zpráv s nízkou latencí.
Zařízení můžou odesílat události přímo do cloudové brány nebo prostřednictvímbrány pole
Po příjmu dat procházejí události jedním nebo několika procesory datových proudů, které mohou směrovat data (například do úložiště) nebo provádět analýzy a jiné zpracování.
Tady jsou některé běžné typy zpracování. (Tento seznam určitě není vyčerpávající.)
Zápis dat událostí do studeného úložiště pro archivaci nebo dávkové analýzy
Analýza horkých cest, analýza datového proudu událostí v (téměř) reálném čase, detekce anomálií, rozpoznávání vzorů v průběhu běhu časových intervalů nebo aktivace upozornění v případě, že se v datovém proudu vyskytuje určitá podmínka.
Zpracování speciálních typů ne telemetrických zpráv ze zařízení, jako jsou oznámení a alarmy.
Strojové učení.
Pole, která jsou vystínovaná šedá, zobrazují komponenty systému IoT, které přímo nesouvisí se streamováním událostí, ale jsou zde zahrnuty pro úplnost.
registru zařízení je databáze zřízených zařízení, včetně ID zařízení a obvykle metadat zařízení, jako je například umístění.
Rozhraní API zřizování je běžné externí rozhraní pro zřizování a registraci nových zařízení.
Některá řešení IoT umožňují odesílat příkazy a řídicí zprávy do zařízení.
Tato část představuje velmi obecný pohled na IoT a existuje mnoho drobných a výzev, které je potřeba vzít v úvahu. Další podrobnosti najdete v tématu architektury IoT.
Další kroky
- Přečtěte si další informace o architekturách velkých objemů dat.
- Přečtěte si další informace o architekturách IoT.