Zpracování přirozeného jazyka (NLP) má mnoho aplikací, jako je analýza mínění, detekce témat, rozpoznávání jazyka, extrakce klíčových frází a kategorizace dokumentů.
Konkrétně můžete použít NLP k:
- Klasifikujte dokumenty, například jejich označení jako citlivé nebo spamové.
- Provedení následného zpracování nebo hledání s výstupy NLP
- Shrňte text identifikací entit v dokumentu.
- Označte dokumenty klíčovými slovy a s využitím identifikovaných entit.
- Provádění vyhledávání a načítání na základě obsahu prostřednictvím značek
- Shrnutí klíčových témat dokumentu pomocí identifikovaných entit
- Kategorizace dokumentů pro navigaci s využitím zjištěných témat.
- Vytvořte výčet souvisejících dokumentů na základě vybraného tématu.
- Vyhodnoťte mínění v textu, abyste porozuměli jeho pozitivnímu nebo negativnímu tónu.
S pokrokem v technologii lze NLP použít nejen ke kategorizaci a analýze textových dat, ale také k vylepšení interpretovatelných funkcí AI napříč různými doménami. Integrace velkých jazykových modelů (LLM) výrazně vylepšuje možnosti NLP. LLM, jako jsou GPT a BERT, můžou generovat text podobný člověku, kontextově pracující text, což je vysoce efektivní pro složité úlohy zpracování jazyka. Doplňují stávající techniky NLP tím, že zpracovávají širší kognitivní úlohy, které zlepšují konverzační systémy a zapojení zákazníků, zejména u modelů, jako je Databricks' Dolly 2.0.
Vztah a rozdíly mezi jazykovými modely a NLP
NLP je komplexní obor zahrnující různé techniky zpracování lidského jazyka. Naproti tomu jazykové modely jsou v rámci NLP specifickou podmnožinou, která se zaměřuje na hluboké učení pro provádění úloh na vysoké úrovni jazyka. I když jazykové modely vylepšují NLP tím, že poskytují pokročilé generování textu a porozumění funkcím, nejsou synonymem NLP. Místo toho slouží jako výkonné nástroje v rámci širší domény NLP, což umožňuje sofistikovanější zpracování jazyka.
Poznámka
Tento článek se zaměřuje na NLP. Vztah mezi NLP a jazykovými modely ukazuje, že jazykové modely vylepšují procesy NLP prostřednictvím špičkových možností porozumění jazyka a generování.
Apache®, Apache Spark a logo plamene jsou registrované ochranné známky nebo ochranné známky nadace Apache Software Foundation v USA a/nebo v jiných zemích. Použití těchto značek nevyžaduje žádné doporučení Apache Software Foundation.
Potenciální případy použití
Mezi obchodní scénáře, které můžou těžit z vlastního NLP, patří:
- Funkce Document Intelligence pro rukou psané nebo strojově vytvořené dokumenty v oblasti financí, zdravotnictví, maloobchodu, státní správy a dalších sektorů.
- Úlohy NLP nezávislé na oboru pro zpracování textu, jako je rozpoznávání entit názvů (NER), klasifikace, sumarizace a extrakce relací. Tyto úlohy automatizují proces načítání, identifikace a analýzy informací o dokumentech, jako jsou textová a nestrukturovaná data. Mezi příklady těchto úloh patří modely stratifikace rizik, klasifikace ontologie a souhrny maloobchodního prodeje.
- Vytváření sémantických vyhledávání v grafu informací a vytváření znalostních grafů Tato funkce umožňuje vytvářet grafy lékařských znalostí, které podporují zjišťování léků a klinické studie.
- Překlad textu pro konverzační systémy AI v zákaznických aplikacích napříč maloobchodem, financemi, cestováními a dalšími odvětvími
- Mínění a vylepšená emocionální inteligence v analýzách, zejména pro monitorování vnímání značky a analýzy zpětné vazby zákazníků.
- Automatizované generování sestav. Syntetizuje a generuje komplexní textové sestavy ze strukturovaných datových vstupů, které pomáhají sektorům, jako jsou finance a dodržování předpisů, pokud je nutná důkladná dokumentace.
- Hlasově aktivovaná rozhraní pro vylepšení interakcí uživatelů v aplikacích IoT a inteligentních zařízení integrací NLP pro rozpoznávání hlasu a přirozené konverzační funkce.
- Adaptativní jazykové modely pro dynamické úpravy výstupu jazyka tak, aby vyhovovaly různým úrovním porozumění cílové skupině, což je zásadní pro vylepšení vzdělávacího obsahu a přístupnosti.
- Analýza textu kyberbezpečnosti za účelem analýzy komunikačních vzorů a používání jazyka v reálném čase za účelem identifikace potenciálních bezpečnostních hrozeb v digitální komunikaci, což zlepšuje detekci pokusů o útok phishingneboch
Apache Spark jako přizpůsobená architektura NLP
Apache Spark je výkonná architektura paralelního zpracování, která vylepšuje výkon analytických aplikací pro velké objemy dat prostřednictvím zpracování v paměti. azure Synapse Analytics, azure HDInsighta Azure Databricks dál poskytují robustní přístup ke schopnostem zpracování Sparku a zajišťují bezproblémové provádění rozsáhlých operací s daty.
V případě přizpůsobených úloh NLP zůstává Spark NLP efektivní architekturou, která dokáže zpracovat obrovské objemy textu. Tato opensourcová knihovna poskytuje rozsáhlé funkce prostřednictvím knihoven Pythonu, Javy a Scala, které poskytují sofistikovanost v hlavních knihovnách NLP, jako jsou spaCy a NLTK. Spark NLP obsahuje pokročilé funkce, jako je kontrola pravopisu, analýza mínění a klasifikace dokumentů, a konzistentně zajišťuje nejmodernější přesnost a škálovatelnost.
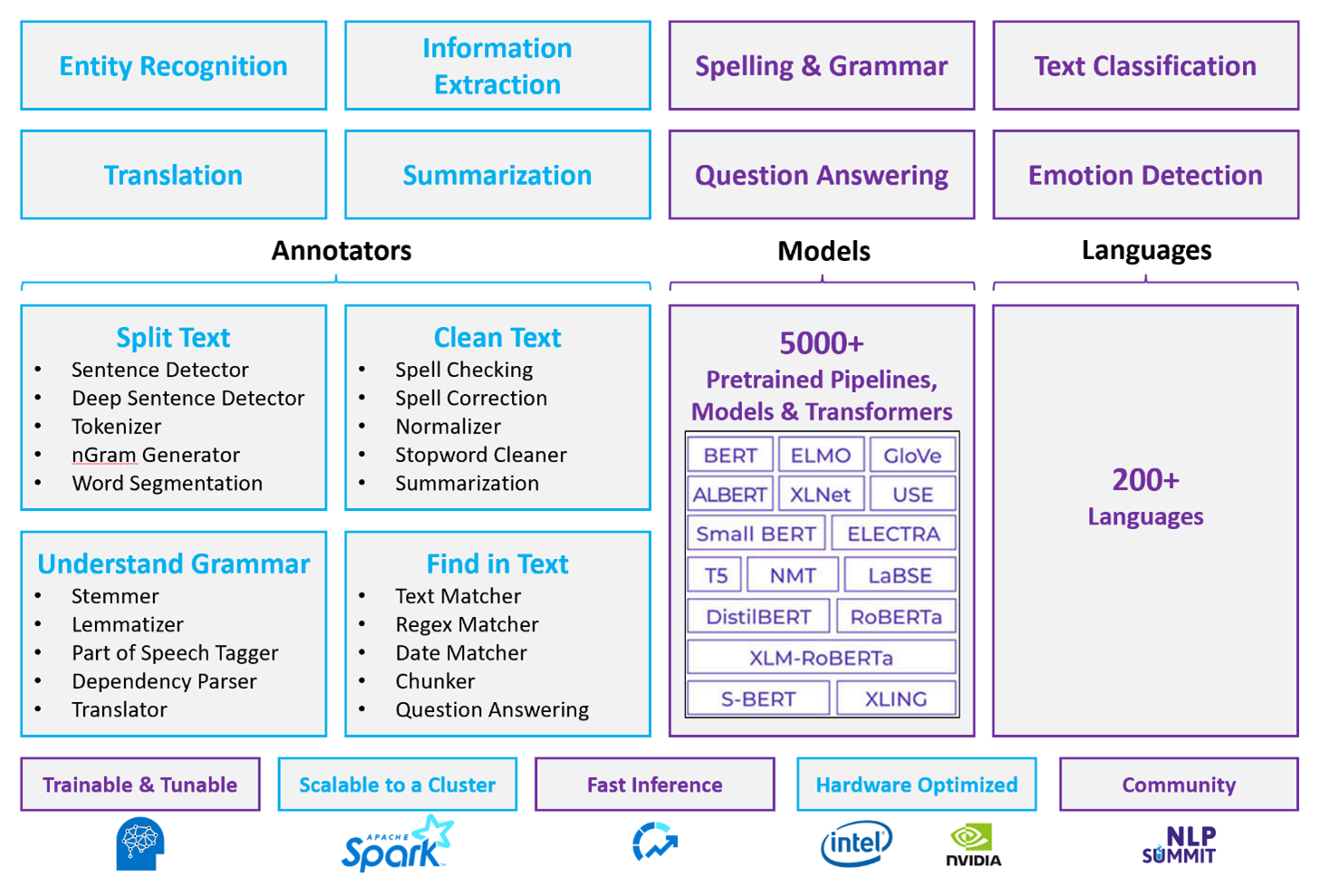
Nedávné veřejné srovnávací testy zvýrazňují výkon Spark NLP, který ukazuje výrazné vylepšení rychlosti u jiných knihoven a současně zachovává srovnatelnou přesnost pro trénování vlastních modelů. Zejména integrace modelů Llama-2 a OpenAI Whisper vylepšuje konverzační rozhraní a vícejazyčné rozpoznávání řeči a označuje významné kroky v optimalizovaných možnostech zpracování.
Spark NLP jednoznačně využívá distribuovaný cluster Spark, který funguje jako nativní rozšíření Spark ML, které funguje přímo na datových rámcích. Tato integrace podporuje vyšší zvýšení výkonu v clusterech, což usnadňuje vytváření sjednocených kanálů NLP a strojového učení pro úlohy, jako je klasifikace dokumentů a predikce rizik. Zavedení vkládání MPNet a rozsáhlá podpora ONNX tyto funkce dále rozšiřuje, což umožňuje přesné zpracování a zpracování s podporou kontextu.
Kromě výhod výkonu přináší Spark NLP nejmodernější přesnost napříč rozšiřujícím se polem úloh NLP. Knihovna obsahuje předem připravené modely hlubokého učení pro rozpoznávání pojmenovaných entit, klasifikaci dokumentů, detekci mínění a další. Jeho návrh s bohatými funkcemi zahrnuje předem vytrénované jazykové modely podporující vkládání slov, bloků dat, vět a dokumentů.
Díky optimalizovaným buildům pro procesory, GPU a nejnovější čipy Intel Xeon je infrastruktura Spark NLP navržená pro škálovatelnost a umožňuje procesy trénování a odvozování pro plné využití clusterů Spark. To zajišťuje efektivní zpracování úloh NLP v různých prostředích a aplikacích a zachovává svou pozici v popředí inovací NLP.
Výzvy
Zpracování prostředků: Zpracování kolekce bezplatných textových dokumentů vyžaduje značné množství výpočetních prostředků a zpracování je také časově náročné. Tento druh zpracování často zahrnuje nasazení výpočetních prostředků GPU. Nedávný pokrok, jako jsou optimalizace v architekturách NLP Sparku, jako je Llama-2, které podporují kvantování, pomáhají zjednodušit tyto náročné úlohy a tím zefektivnit přidělování prostředků.
problémy se standardizací: Bez standardizovaného formátu dokumentu může být obtížné dosáhnout konzistentně přesných výsledků při použití bezplatného zpracování textu k extrahování konkrétních faktů z dokumentu. Například extrakce čísla a data faktury z různých faktur představuje výzvy. Integrace přizpůsobitelných modelů NLP, jako je M2M100, zlepšila přesnost zpracování ve více jazycích a formátech, což usnadňuje větší konzistenci výsledků.
Rozmanitost a složitost dat: Řešení různých struktur dokumentů a lingvistických nuancí zůstává složité. Inovace, jako jsou vkládání MPNet, poskytují lepší kontextové porozumění, které nabízí intuitivnější zpracování různých textových formátů a zlepšení celkové spolehlivosti zpracování dat.
Klíčová kritéria výběru
Služby Sparku, jako jsou Azure Databricks, Microsoft Fabric a Azure HDInsight, poskytují funkce NLP při použití se Spark NLP. Další možností funkcí NLP jsou služby Azure AI. Pokud se chcete rozhodnout, kterou službu použít, zvažte tyto otázky:
Chcete použít předem připravené nebo předem natrénované modely? Pokud ano, zvažte použití rozhraní API, která nabízejí služby Azure AI, nebo si stáhněte svůj model podle výběru prostřednictvím Spark NLP, který teď zahrnuje pokročilé modely, jako je Llama-2 a MPNet, aby se zlepšily možnosti.
Potřebujete trénovat vlastní modely proti velkému korpusu textových dat? Pokud ano, zvažte použití Azure Databricks, Microsoft Fabric nebo Azure HDInsight se Spark NLP. Tyto platformy poskytují výpočetní výkon a flexibilitu potřebnou pro rozsáhlé trénování modelů.
Potřebujete funkce NLP nízké úrovně, jako je tokenizace, stemming, lemmatizace a frekvence/inverzní frekvence dokumentů (TF/IDF)? Pokud ano, zvažte použití Azure Databricks, Microsoft Fabric nebo Azure HDInsight se Spark NLP. Alternativně můžete použít opensourcovou softwarovou knihovnu ve zvoleném nástroji pro zpracování.
Potřebujete jednoduché funkce NLP vysoké úrovně, jako je identifikace entit a záměrů, detekce témat, kontrola pravopisu nebo analýza mínění? Pokud ano, zvažte použití rozhraní API, která nabízí služby Azure AI. Nebo si stáhněte model podle výběru prostřednictvím Spark NLP, abyste pro tyto úlohy využili předem připravené funkce.
Matice schopností
Následující tabulky shrnují klíčové rozdíly ve schopnostech služeb NLP.
Obecné možnosti
| Schopnost | Služba Spark (Azure Databricks, Microsoft Fabric, Azure HDInsight) se Spark NLP | Služby Azure AI |
|---|---|---|
| Poskytuje předem natrénované modely jako službu. | Ano | Ano |
| REST API | Ano | Ano |
| Programovatelnost | Python, Scala | Informace o podporovaných jazycích najdete v tématu Další zdroje informací. |
| Podporuje zpracování sad velkých objemů dat a velkých dokumentů. | Ano | No |
Možnosti NLP nízké úrovně
Funkce anotátorů
| Schopnost | Služba Spark (Azure Databricks, Microsoft Fabric, Azure HDInsight) se Spark NLP | Služby Azure AI |
|---|---|---|
| Detektor vět | Ano | No |
| Detektor hluboké věty | Ano | Ano |
| Tokenizátor | Ano | Ano |
| Generátor N-gram | Ano | No |
| Segmentace slov | Ano | Ano |
| Stemmer | Ano | No |
| Lemmatizer | Ano | No |
| Označování částí řeči | Ano | No |
| Analyzátor závislostí | Ano | No |
| Překlad | Ano | No |
| Čistič stopek | Ano | No |
| Oprava pravopisu | Ano | No |
| Normalizátor | Ano | Ano |
| Text matcher | Ano | No |
| TF/IDF | Ano | No |
| Porovnávání regulárních výrazů | Ano | Vložené v konverzační službě Language Understanding (CLU) |
| Matcher data | Ano | Možné v modulu CLU prostřednictvím rozpoznávatelů dateTime |
| Chunker | Ano | No |
Poznámka
Služba Microsoft Language Understanding (LUIS) bude vyřazena 1. října 2025. Stávající aplikace LUIS se doporučuje migrovat na konverzační službu LANGUAGE Understanding (CLU), což je funkce azure AI Services pro jazyk, která vylepšuje možnosti porozumění jazyku a nabízí nové funkce.
Možnosti NLP vysoké úrovně
| Schopnost | Služba Spark (Azure Databricks, Microsoft Fabric, Azure HDInsight) se Spark NLP | Služby Azure AI |
|---|---|---|
| Kontrolu pravopisu | Ano | No |
| Souhrn | Ano | Ano |
| Odpovídání na dotazy | Ano | Ano |
| rozpoznávání mínění, | Ano | Ano |
| Detekce emocí | Ano | Podporuje dolování názorů |
| Klasifikace tokenů | Ano | Ano, prostřednictvím vlastních modelů |
| Klasifikace textu | Ano | Ano, prostřednictvím vlastních modelů |
| Reprezentace textu | Ano | No |
| NER | Ano | Ano – analýza textu poskytuje sadu NER a vlastní modely jsou v rozpoznávání entit. |
| rozpoznávání entit, | Ano | Ano, prostřednictvím vlastních modelů |
| Rozpoznávání jazyka | Ano | Ano |
| Podporuje jazyky kromě angličtiny. | Ano, podporuje více než 200 jazyků. | Ano, podporuje více než 97 jazyků. |
Nastavení Spark NLP v Azure
Pokud chcete nainstalovat Spark NLP, použijte následující kód, ale nahraďte <version> ho číslem nejnovější verze. Další informace najdete v dokumentaci k NLP sparku.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Vývoj kanálů NLP
Pro pořadí provádění kanálu NLP se Spark NLP řídí stejným konceptem vývoje jako tradiční modely strojového učení Spark ML a používá specializované techniky NLP.
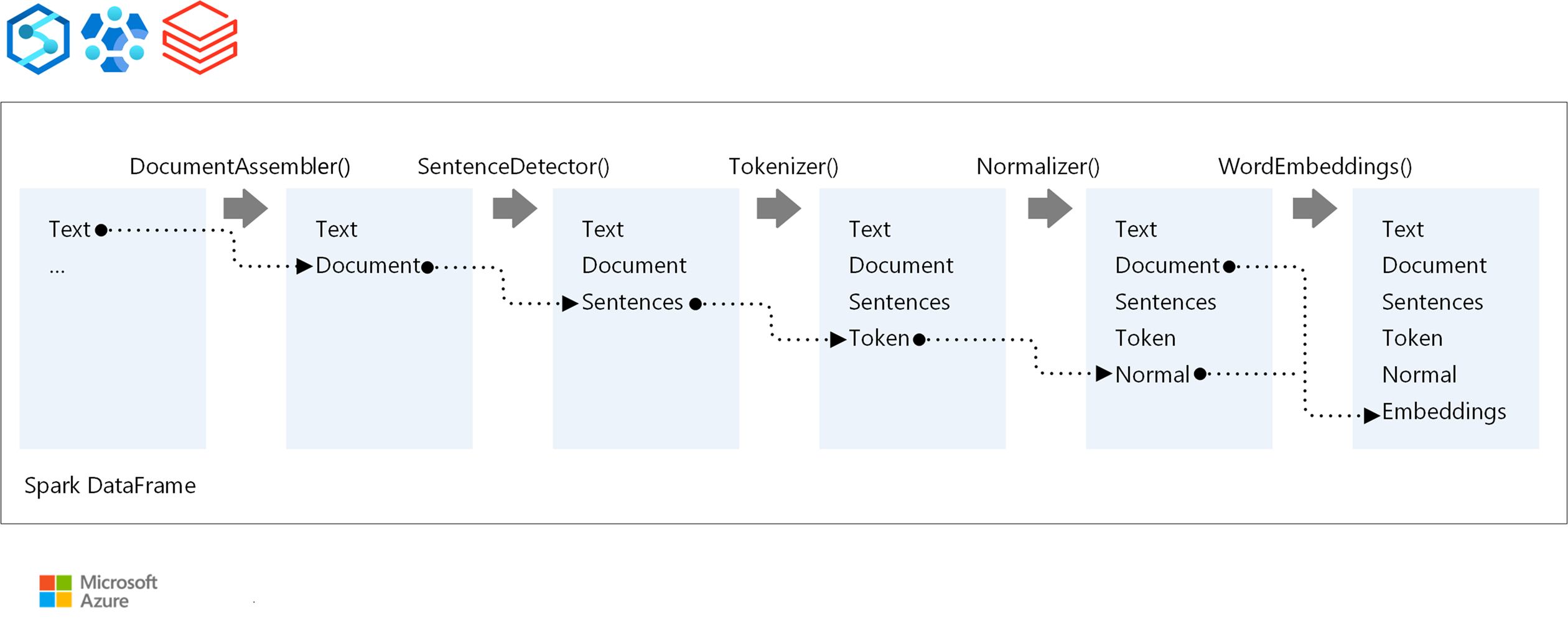
Základní komponenty kanálu Spark NLP jsou:
DocumentAssembler: Transformátor, který připraví data jejich převodem do formátu, který může Spark NLP zpracovat. Tato fáze je vstupním bodem pro každý kanál Spark NLP. DocumentAssembler přečte sloupec
StringneboArray[String]s možnostmi předběžného zpracování textu pomocísetCleanupMode, který je ve výchozím nastavení vypnutý.SentenceDetector: Annotator, který identifikuje hranice vět pomocí předdefinovaných přístupů. Může vrátit každou rozpoznanou větu v
Arraynebo v samostatných řádcích, pokud jeexplodeSentencesnastavena na hodnotu true.tokenizátoru: anotátor, který rozděluje nezpracovaný text na diskrétní tokeny – slova, čísla a symboly – vypíše je jako
TokenizedSentence. Tokenizátor není fitovaný a používá vstupní konfiguraci v rámciRuleFactoryk vytvoření pravidel tokenizace. Vlastní pravidla je možné přidat, pokud nejsou dostatečná výchozí nastavení.normalizátoru : Annotator tasked with refining tokens.Normalizer: Annotator tasked with refining tokens. Normalizer používá regulární výrazy a transformace slovníku k vyčištění textu a odebrání nadbytečných znaků. WordEmbeddings: Vyhledávací anotátory, které mapují tokeny na vektory, což usnadňuje sémantické zpracování. Pomocí
setStoragePathmůžete zadat vlastní vložený slovník, kde každý řádek obsahuje token a jeho vektor oddělený mezerami. Nevyřešené tokeny jsou ve výchozím nastavení nulové vektory.
Spark NLP využívá kanály Spark MLlib s nativní podporou MLflow, opensourcovou platformou, která spravuje životní cyklus strojového učení. Mezi klíčové komponenty MLflow patří:
sledování MLflow: Zaznamenává experimentální spuštění a poskytuje robustní možnosti dotazování pro analýzu výsledků.
projekty MLflow: Umožňuje provádění kódu datových věd na různých platformách, což zvyšuje přenositelnost a reprodukovatelnost.
modely MLflow: Podporuje všestranné nasazení modelu v různých prostředích prostřednictvím konzistentní architektury.
registru modelů: Poskytuje komplexní správu modelů, centrální ukládání verzí pro zjednodušený přístup a nasazení, což usnadňuje připravenost do produkčního prostředí.
MLflow je integrovaný s platformami, jako je Azure Databricks, ale můžete je také nainstalovat v jiných prostředích založených na Sparku pro správu a sledování experimentů. Tato integrace umožňuje použití registru modelů MLflow k zpřístupnění modelů pro produkční účely, a tím ke zjednodušení procesu nasazení a údržbě zásad správného řízení modelu.
Pomocí MLflow společně se Spark NLP můžete zajistit efektivní správu a nasazení kanálů NLP a řešit moderní požadavky na škálovatelnost a integraci a současně podporovat pokročilé techniky, jako jsou vkládání slov a přizpůsobení velkých jazykových modelů.
Přispěvatelé
Tento článek spravuje Microsoft. Původně byla napsána následujícími přispěvateli.
Hlavní autoři:
- Freddy Ayala | Architekt cloudového řešení
- Moritz Steller | Vedoucí architekt cloudových řešení
Další kroky
Dokumentace ke SparkU NLP:
Komponenty Azure:
Zdroje informací: