Poznatky a zkušenosti
- Ujistěte se, že všechny zúčastněné strany chápou rozdíl mezi vysokou dostupností (HA) a zotavením po havárii (DR): Běžnou chybou je zmást tyto dva koncepty a neshoda řešení spojených s nimi.
- Prodiskutujte s obchodními účastníky o svých očekáváních ohledně následujících aspektů definování cílů bodu obnovení (RPO) a časových cílů obnovení (RTO):
- Kolik výpadků mohou tolerovat, mějte na paměti, že obvykle, rychlejší obnovení, vyšší náklady.
- Typ incidentů, před nimiž chcete být chráněni, uveďte související pravděpodobnost takové události. Například pravděpodobnost výpadku serveru je vyšší než přírodní katastrofa, která ovlivňuje všechna datacentra v celé oblasti.
- Jaký vliv má systém nedostupný na svou firmu?
- Rozpočet provozních výdajů (OPEX) pro řešení, které se posune dál.
- Zvažte, jaké možnosti degradované služby můžou koncoví uživatelé přijmout. Mezi ně může patřit:
- Stále máte přístup k řídicím panelům vizualizací i bez nejaktuálnějších dat, to znamená, že pokud kanály příjmu dat nefungují, budou mít koncoví uživatelé stále přístup ke svým datům.
- Přístup pro čtení, ale bez přístupu k zápisu
- Metriky cíle RTO a cíle bodu obnovení můžou definovat, jakou strategii zotavení po havárii zvolíte pro implementaci:
- Aktivní/aktivní.
- Aktivní/pasivní.
- Aktivní/opětovné nasazení při havárii
- Zvažte vlastní cíl úrovně služeb (SLO), který umožňuje zohlednit přípustné výpadky.
- Ujistěte se, že rozumíte všem komponentám, které můžou ovlivnit dostupnost vašich systémů, například:
- Správa identit.
- Síťová topologie.
- Správa tajných klíčů nebo klíčů
- Zdroje dat.
- Automatizace nebo plánovač úloh.
- Zdrojové úložiště a kanály nasazení (GitHub, Azure DevOps).
- Včasné zjišťování výpadků je také způsob, jak výrazně snížit hodnoty RTO a RPO. Tady je několik aspektů, které by se měly probít:
- Definujte, co je výpadek a jak se mapuje na definici výpadku Od Microsoftu. Definice Microsoftu je k dispozici na stránce smlouvy o úrovni služeb (SLA) Azure na úrovni produktu nebo služby.
- Efektivní systém monitorování a upozorňování s zodpovědnými týmy, které tyto metriky a výstrahy kontrolují včas, pomáhá splnit cíl.
- Pokud jde o návrh předplatného, může být další infrastruktura pro zotavení po havárii uložena v původním předplatném. Služby paaS (platforma jako služba), jako je Azure Data Lake Storage Gen2 nebo Azure Data Factory, mají obvykle nativní funkce, které umožňují převzetí služeb při selhání sekundárním instancím v jiných oblastech při zachování v původním předplatném. Někteří zákazníci můžou chtít zvážit použití vyhrazené skupiny prostředků pro prostředky používané pouze ve scénářích zotavení po havárii pro účely nákladů.
- Je třeba poznamenat, že limity předplatného mohou pro tento přístup fungovat jako omezení.
- Mezi další omezení může patřit složitost návrhu a ovládací prvky správy, aby se zajistilo, že se skupiny prostředků zotavení po havárii nepoužívají pro pracovní postupy bau (business-as-usual).
- Navrhujte pracovní postup zotavení po havárii na základě závažnosti a závislostí řešení. Nepokoušejte se například před spuštěním datového skladu znovu sestavit instanci služby Azure Analysis Services, protože aktivuje chybu. Vývojová testovací prostředí ponechte později v procesu a nejprve obnovte základní podniková řešení.
- Pokuste se identifikovat úlohy obnovení, které je možné paralelizovat napříč řešeními, což snižuje celkovou rto.
- Pokud se služba Azure Data Factory používá v rámci řešení, nezapomeňte do oboru zahrnout místní prostředí Integration Runtime. Azure Site Recovery je ideální pro tyto počítače.
- Ruční operace by měly být co nejvíce automatizované, aby se zabránilo lidským chybám, zejména pokud jsou pod tlakem. Doporučuje se:
- Osvojte zřizování prostředků prostřednictvím bicep, šablon ARM nebo skriptů PowerShellu.
- Přijměte správu verzí zdrojového kódu a konfigurace prostředků.
- Používejte kanály verze CI/CD místo technologie Click-Ops.
- Vzhledem k tomu, že máte plán převzetí služeb při selhání, měli byste zvážit postupy pro navrácení služeb při selhání do primárních instancí.
- Definujte jasné indikátory a metriky, abyste ověřili, že převzetí služeb při selhání proběhlo úspěšně a řešení je spuštěné nebo že situace je zpět v normálu (označuje se také jako primární funkční).
- Rozhodněte se, jestli vaše smlouvy o úrovni služeb (SLA) po převzetí služeb při selhání zůstanou stejné nebo jestli povolíte degradovanou službu.
- Toto rozhodnutí bude výrazně záviset na podporovaném procesu obchodních služeb. Například převzetí služeb při selhání systému pro rezervaci místností bude vypadat mnohem jinak než základní operační systém.
- Definice RTO/RPO by měla být založena na konkrétních scénářích uživatelů, nikoli na úrovni infrastruktury. Tím získáte podrobnější přehled o tom, jaké procesy a komponenty by se měly obnovit, pokud dojde k výpadku nebo havárii.
- Před přechodem k převzetí služeb při selhání nezapomeňte zahrnout kontroly kapacity do cílové oblasti: Pokud dojde k závažné havárii, mějte na paměti, že se mnoho zákazníků pokusí provést převzetí služeb při selhání do stejné spárované oblasti současně, což může způsobit zpoždění nebo kolize při zřizování prostředků.
- Pokud jsou tato rizika nepřijatelná, je třeba zvážit strategii aktivní/aktivní/pasivní zotavení po havárii.
- Plán zotavení po havárii by se měl vytvořit a udržovat, aby bylo možné zdokumentovat proces obnovení a vlastníky akcí. Vezměte také v úvahu, že lidé mohou být na dovolené, takže nezapomeňte zahrnout sekundární kontakty.
- Pravidelné postupy zotavení po havárii by se měly provést k ověření pracovního postupu plánu zotavení po havárii, splnění požadovaných rto/RPO a k trénování zodpovědných týmů.
- Zálohy dat a konfigurace by se také měly pravidelně testovat, aby se zajistilo, že jsou vhodné pro účely podpory všech aktivit obnovení.
- Časná spolupráce s týmy zodpovědnými za vytváření sítí, identit a prostředků zajistí dohodu o nejoptimálnějším řešení:
- Jak přesměrovat uživatele a provoz z primární lokality do sekundární lokality Je možné vyhodnotit koncepty, jako je přesměrování DNS nebo použití konkrétních nástrojů, jako je Azure Traffic Manager .
- Jak zajistit přístup a práva k sekundární lokalitě včas a bezpečně.
- Během havárie je účinná komunikace mezi zúčastněnými stranami klíčem k efektivnímu a rychlému provádění plánu. Týmy můžou zahrnovat:
- Rozhodovací pracovníci.
- Tým reakce na incidenty.
- Ovlivnění interních uživatelů a týmů
- Externí týmy.
- Orchestrace různých prostředků ve správný čas zajistí efektivitu při provádění plánu zotavení po havárii.
Důležité informace
Antipatterny
- Kopírování/vložení této série článků Tato série článků je určená k poskytování pokynů zákazníkům, kteří hledají další úroveň podrobností pro proces zotavení po havárii specifické pro Azure. Proto je založená na obecných architekturách IP adres a referenčních architektur Microsoftu, nikoli na implementaci Azure specifické pro jednotlivé zákazníky.
I když poskytnutý detail pomůže podpořit solidní základní znalosti, zákazníci musí před získáním strategie a procesu zotavení po havárii použít vlastní specifický kontext, implementaci a požadavky.
Nakládání s zotavením po havárii jako s technickými účastníky hrají důležitou roli při definování požadavků na zotavení po havárii a dokončení kroků pro ověření podniku potřebných k potvrzení obnovení služby. Zajištění zapojení obchodních účastníků napříč všemi aktivitami zotavení po havárii zajistí proces zotavení po havárii, který je "vhodný pro účel", představuje obchodní hodnotu a je spustitelný.
Plány zotavení po havárii "Set and forget" Azure se neustále vyvíjejí, stejně jako využití různých komponent a služeb jednotlivých zákazníků. Proces zotavení po havárii se musí s nimi vyvíjet "vhodný pro účel". Prostřednictvím procesu životního cyklu vývoje softwaru (SDLC) nebo pravidelných kontrol by se zákazníci měli pravidelně znovu vrátit ke svému plánu zotavení po havárii. Cílem je zajistit platnost plánu obnovení služby a zohlednit všechny rozdíly mezi komponentami, službami nebo řešeními.
Hodnocení založená na papíře, zatímco kompletní simulace události zotavení po havárii bude v rámci moderního ekologického systému dat obtížná, měli byste se snažit co nejblíže k úplné simulaci napříč ovlivněnými komponentami. Pravidelné naplánované postupy vytvoří "svalovou paměť" potřebnou organizací, aby mohla s jistotou provést plán zotavení po havárii.
Spoléháme se na Microsoft, aby to udělal všechno ve službách Microsoft Azure, je jasné rozdělení odpovědnosti, které je ukotvené na úrovni cloudové služby:
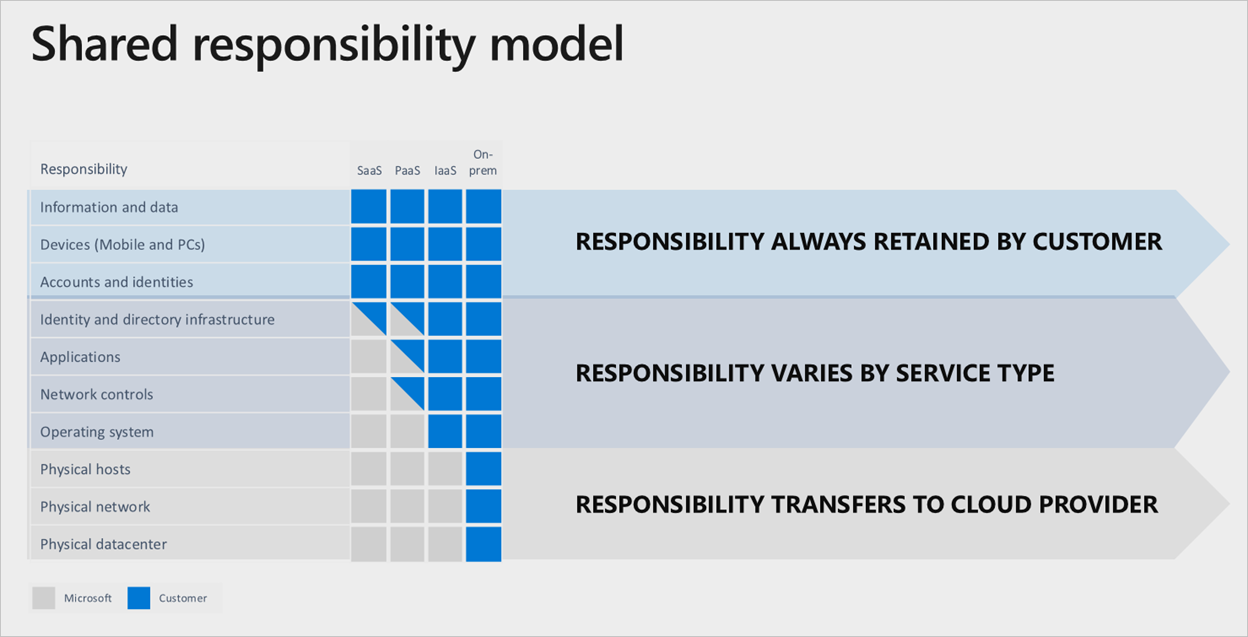 I když se používá kompletní zásobník softwaru jako služby (SaaS), zákazník si stále zachová odpovědnost, aby zajistil, že účty, identity a data jsou správné/aktuální, spolu se zařízeními používanými k interakci se službami Azure.
I když se používá kompletní zásobník softwaru jako služby (SaaS), zákazník si stále zachová odpovědnost, aby zajistil, že účty, identity a data jsou správné/aktuální, spolu se zařízeními používanými k interakci se službami Azure.
Rozsah a strategie událostí
Rozsah událostí havárie
Různé události budou mít jiný rozsah dopadu, a proto i jinou odpověď. Následující diagram znázorňuje událost havárie: 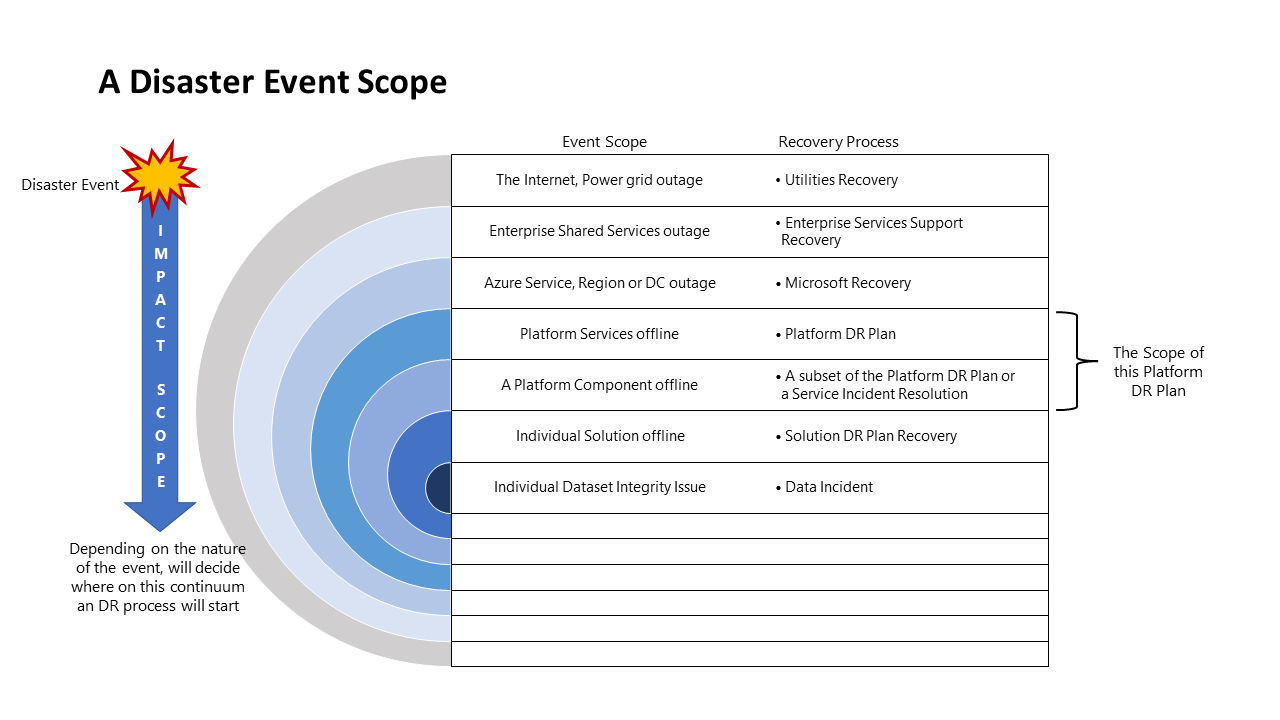
Možnosti strategie havárie
Pro strategii zotavení po havárii existují čtyři základní možnosti:
- Počkejte na Microsoft – jak název napovídá, řešení je offline, dokud microsoft neskončí obnovení služeb v ovlivněné oblasti. Po obnovení se řešení ověří zákazníkem a pak se aktualizuje kvůli obnovení služby.
- Opětovné nasazení při havárii – Řešení se znovu nasadí ručně do dostupné oblasti od začátku po havárii.
- Warm Spare (Aktivní/Pasivní) – Sekundární hostované řešení se vytvoří v alternativní oblasti a komponenty se nasadí za účelem zajištění minimální kapacity, ale komponenty nedostávají provozní provoz. Sekundární služby v alternativní oblasti můžou být "vypnuté" nebo spuštěné na nižší úrovni výkonu, dokud nedojde k události zotavení po havárii.
- Hot Spare (Aktivní/Aktivní) – Řešení je hostované v nastavení aktivní/aktivní napříč několika oblastmi. Sekundární hostované řešení přijímá, zpracovává a obsluhuje data jako součást většího systému.
Dopady strategie zotavení po havárii
I když provozní náklady spojené s vyšší úrovní odolnosti služeb často dominují klíčovým rozhodnutím o návrhu (KDD) pro strategii zotavení po havárii. Existují další důležité aspekty.
Poznámka:
Optimalizace nákladů je jedním z pěti pilířů špičkové architektury s architekturou Azure Well-Architected Framework. Jejím cílem je snížit zbytečné výdaje a zlepšit efektivitu provozu.
Scénář zotavení po havárii pro tento příklad je úplný regionální výpadek Azure, který přímo ovlivňuje primární oblast, která je hostitelem datové platformy Contoso.
Pro tento scénář výpadku je relativní dopad na čtyři strategie zotavení po havárii vysoké úrovně: 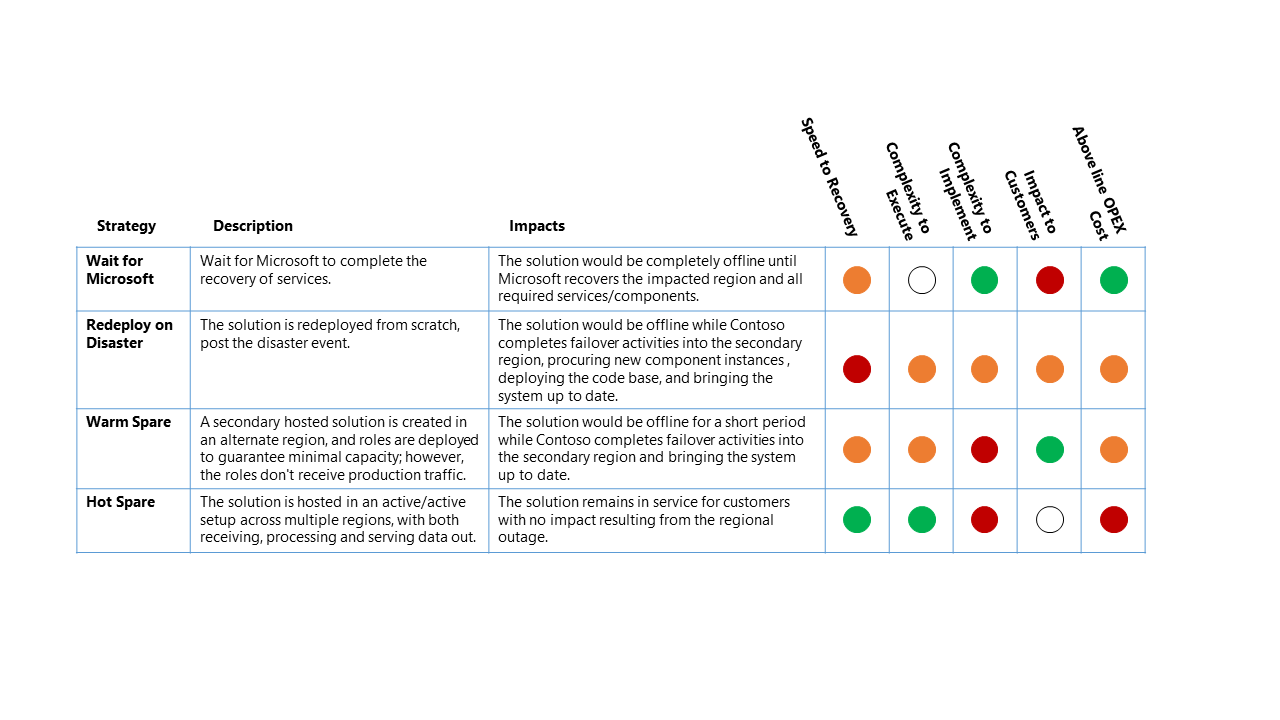
Klasifikační klíč
- Cíl doby obnovení (RTO): Očekávaný uplynulý čas od události havárie až po obnovení služby platformy.
- Složitost provádění: Složitost, která organizaci umožňuje provádět aktivity obnovení.
- Složitost implementace: Složitost implementace organizace pro implementaci strategie zotavení po havárii.
- Dopad na zákazníky: Přímý dopad na zákazníky služby datové platformy ze strategie zotavení po havárii.
- Nadřádové náklady na OPEX: Od implementace této strategie se očekávají dodatečné náklady, jako je zvýšení měsíční fakturace za Azure pro další komponenty a další prostředky potřebné k podpoře.
Poznámka:
Výše uvedená tabulka by se měla číst jako porovnání mezi možnostmi – strategie se zeleným indikátorem je pro tuto klasifikaci lepší než jiná strategie se žlutým nebo červeným indikátorem.
Další kroky
Teď, když jste se seznámili s doporučeními souvisejícími se scénářem, se dozvíte, jak tento scénář nasadit.