Fáze generování embeddingů RAG
V předchozích krocích řešení Retrieval-Augmented Generation (RAG) jste dokumenty rozdělili na bloky dat a obohatili je. V tomto kroku vygenerujete vkládání pro tyto bloky dat a všechna pole metadat, na kterých plánujete provádět vektorové vyhledávání.
Tento článek je součástí série. Přečtěte si úvod.
Vložení je matematická reprezentace objektu, například textu. Při trénování neurální sítě se vytvoří mnoho reprezentací objektu. Každá reprezentace má připojení k jiným objektům v síti. Vkládání je důležité, protože zachycuje sémantický význam objektu.
Reprezentace jednoho objektu má připojení k reprezentaci jiných objektů, takže můžete porovnat objekty matematicky. Následující příklad ukazuje, jak vkládání zachycuje sémantický význam a vztahy mezi sebou:
embedding (king) - embedding (man) + embedding (woman) = embedding (queen)
Embeddingy se vzájemně porovnávají pomocí pojmů podobnosti a vzdálenosti. Následující mřížka ukazuje porovnání embedování.

V řešení RAG často vkládáte uživatelský dotaz pomocí stejného modelu vkládání jako bloky dat. Pak ve své databázi vyhledáte relevantní vektory, které vrátí nejvíce sémanticky relevantních bloků dat. Původní text příslušných bloků dat se předá jazykovému modelu jako podkladová data.
Poznámka
Vektory představují sémantický význam textu způsobem, který umožňuje matematické porovnání. Je nutné vyčistit kusy tak, aby matematická vzdálenost mezi vektory přesně odrážela jejich sémantickou významnost.
Důležitost modelu vkládání
Model vkládání, který zvolíte, může výrazně ovlivnit relevantnost výsledků vektorového vyhledávání. Musíte zvážit slovní zásobu modelu vkládání. Každý model vkládání je natrénovaný pomocí určitého slovníku. Například velikost slovníku modelu BERT je asi 30 000 slov.
Slovní zásoba vloženého modelu je důležitá, protože zpracovává slova, která nejsou ve slovníku jedinečným způsobem. Pokud slovo není ve slovníku modelu, vypočítá pro něj vektor. K tomu mnoho modelů rozdělí slova do podsloví. Zachází s podwordy jako s odlišnými tokeny nebo agregují vektory pro podwordy, aby vytvořily jedno vložení.
Například slovo histamin nemusí být ve slovníku vkládacího modelu. Slovo histamin má sémantický význam jako chemická látka, kterou vaše tělo uvolní, což způsobuje příznaky alergie. Model vkládání neobsahuje histaminu. Takže může slovo oddělit do podsloví, které jsou v jeho slovníku, například jeho, taa moje.

Sémantické významy těchto subslov jsou daleko od významu histaminu. Jednotlivé nebo kombinované vektorové hodnoty subwordů vedou k horším vektorovým shodám v porovnání s tím, kdyby histamin byl ve slovníku modelu.
Volba modelu vkládání
Určete správný model vkládání pro váš případ použití. Při výběru zapouštěcího modelu zvažte překrývání slovní zásoby modelu a slov vašeho datového souboru.

Nejprve určete, jestli máte obsah specifický pro doménu. Jsou například vaše dokumenty specifické pro případ použití, vaši organizaci nebo odvětví? Dobrým způsobem, jak určit specificitu domény, je zkontrolovat, jestli v obsahu na internetu najdete entity a klíčová slova. Pokud to dokážete vy, pravděpodobně to dokáže i obecný model pro vkládání.
Obecný nebo nedoménový obsah
Když zvolíte obecný model zabudovávání, začněte na žebříčku Hugging Face . Získejte hodnocení modelů pro vkládání dat up-to. Vyhodnoťte, jak modely pracují s vašimi daty, a začněte modely s nejvyšším hodnocením.
Obsah specifický pro doménu
U obsahu specifického pro doménu určete, jestli můžete použít model specifický pro doménu. Vaše data mohou být například v biomedické doméně, takže můžete použít model BioGPT. Tento jazykový model je předem natrénován na velké kolekci biomedické literatury. Můžete ho použít pro biomedické dolování a generování textu. Pokud jsou modely specifické pro doménu k dispozici, vyhodnoťte, jak tyto modely fungují s vašimi daty.
Pokud nemáte model specifický pro doménu nebo model specifický pro doménu nefunguje dobře, můžete doladit obecný model pro vložení pomocí slovníku specifického pro vaši doménu.
Důležitý
U libovolného modelu, který zvolíte, musíte ověřit, že licence vyhovuje vašim potřebám, a model poskytuje potřebnou jazykový podporu.
Vyhodnocení modelů vkládání
Pokud chcete vyhodnotit model vkládání, vizualizujte vkládání a vyhodnoťte vzdálenost mezi vektory otázek a bloků dat.
Vizualizace vložených objektů
Pomocí knihoven, jako je t-SNE, můžete vykreslit vektory pro bloky dat a otázku v grafu X-Y. Pak můžete určit, jak daleko jsou bloky dat od sebe navzájem a od otázky. Následující graf znázorňuje vektory bloků. Dvě šipky blízko sebe představují dva vektory bloků dat. Druhá šipka představuje vektor otázky. Tuto vizualizaci můžete použít k pochopení, jak daleko je otázka od bloků dat.
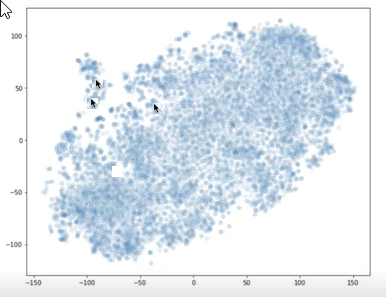
Dvě šipky ukazují na vykreslení bodů blízko sebe a další šipka ukazuje bod grafu daleko od ostatních dvou.
Výpočet vzdáleností vkládání
Pomocí programové metody můžete vyhodnotit, jak dobře váš model vkládání funguje s vašimi dotazy a bloky dat. Vypočítejte vzdálenost mezi vektory otázek a vektory bloků dat. Můžete použít euklidovskou vzdálenost nebo manhattanskou vzdálenost.
Vkládání ekonomie
Když zvolíte model vkládání, musíte přejít na kompromis mezi výkonem a náklady. Velké modely vkládání mají obvykle lepší výkon u srovnávacích datových sad. Zvýšení výkonu ale zvyšuje náklady. Velké vektory vyžadují více místa ve vektorové databázi. Vyžadují také více výpočetních prostředků a času na porovnání embeddingů. Malé modely vkládání mají obvykle nižší výkon na stejných srovnávacích testech. Potřebují méně místa ve vaší vektorové databázi a méně výpočetního výkonu a času pro porovnání embeddování.
Při návrhu systému byste měli zvážit náklady na vkládání z hlediska požadavků na úložiště, výpočetní výkon a výkon. Výkon modelů je nutné ověřit experimentováním. Veřejně dostupné srovnávací testy jsou převážně akademické datové sady a nemusí se přímo vztahovat na obchodní data a případy použití. V závislosti na požadavcích můžete upřednostnit výkon před náklady nebo přijmout kompromis v podobě dostatečně dobrého výkonu za nižší náklady.