Metriky pro Službu Application Gateway
Application Gateway publikuje datové body do služby Azure Monitor pro výkon instancí služby Application Gateway a back-end. Tyto datové body se nazývají metriky a jsou číselné hodnoty v seřazené sadě dat časových řad. Metriky popisují určitý aspekt služby Application Gateway v určitém okamžiku. Pokud se požadavky procházejí službou Application Gateway, měří a odesílají metriky v 60sekundových intervalech. Pokud nejsou žádné požadavky procházející službou Application Gateway nebo žádná data pro metriku, metrika se nenahlásí. Další informace najdete v tématu Metriky služby Azure Monitor.
Metriky podporované skladovou jednotkou Application Gateway V2
Poznámka:
Informace související s proxy protokolem TLS/TCP najdete v referenčních informacích k datům.
Metriky časování
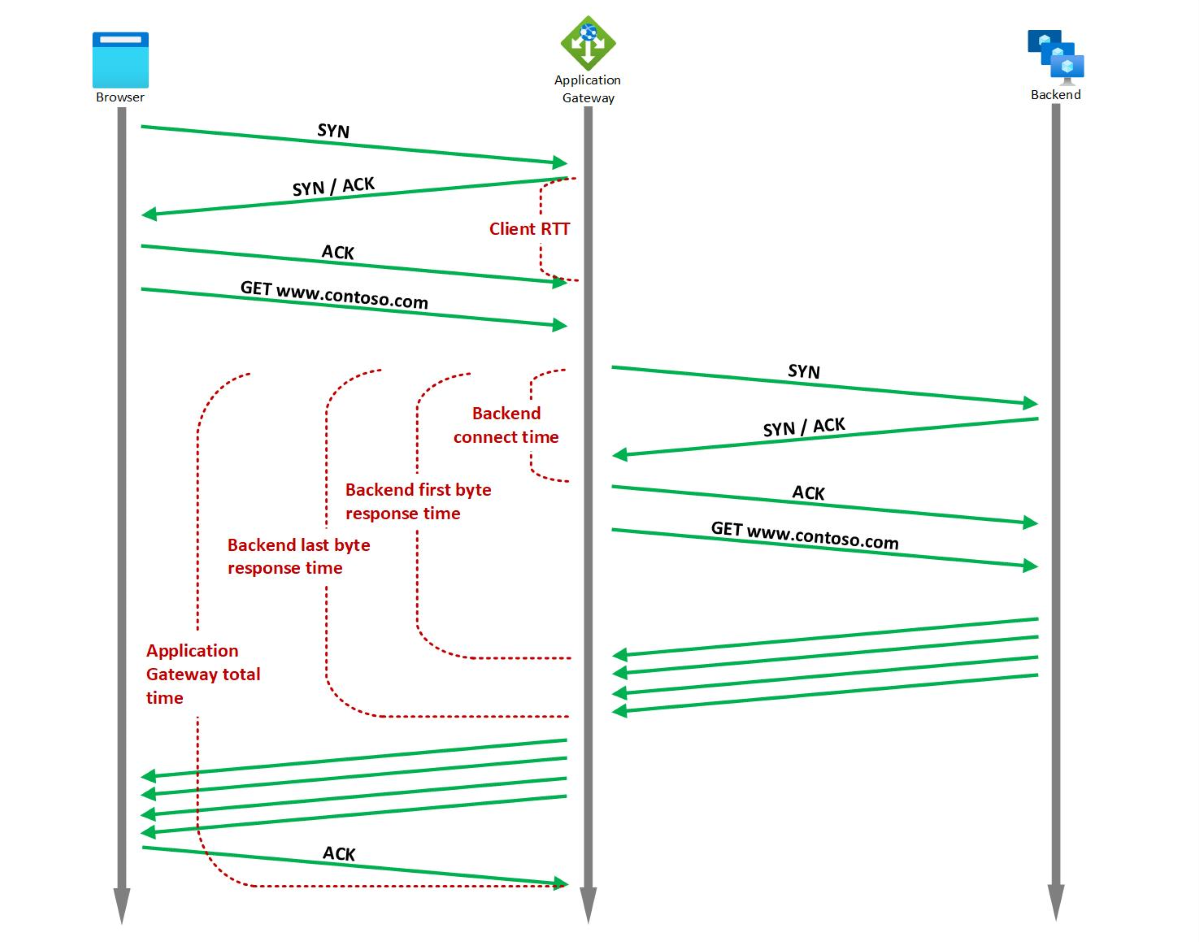
Application Gateway poskytuje několik předdefinovaných metrik časování souvisejících s požadavkem a odpovědí, které se měří v milisekundách.
Poznámka:
Pokud je ve službě Application Gateway více než jeden naslouchací proces, vždy filtrujte podle dimenze naslouchacího procesu a porovnejte různé metriky latence, abyste získali smysluplné odvození.
Poznámka:
Latence se může v datech metrik sledovat, protože všechny metriky se agregují v minutových intervalech. Tato latence se u různých instancí aplikační brány může lišit v závislosti na čase spuštění metriky.
Pomocí metrik časování můžete určit, jestli je pozorované zpomalení způsobené klientskou sítí, výkonem služby Application Gateway, back-endovou sítí a sytostí zásobníku tcp back-endového serveru, výkonem back-endové aplikace nebo velkými soubory. Další informace najdete v tématu Metriky časování.
Pokud je například špička v trendu doby odezvy prvního bajtu back-endu, ale trend doby připojení back-endu je stabilní, můžete odvodit, že aplikační brána na back-endovou latenci a doba potřebná k navázání připojení je stabilní. Špička je způsobena nárůstem doby odezvy back-endové aplikace. Pokud je na druhé straně špička v době odezvy prvního bajtu back-endu přidružená k odpovídajícímu prudkému nárůstu doby připojení back-endu, můžete zjistit, že síť mezi službou Application Gateway a back-endovým serverem nebo zásobník tcp back-endového serveru je nasycený.
Pokud si všimnete špičky v době odezvy posledního bajtu back-endu, ale doba odezvy prvního bajtu back-endu je stabilní, můžete odvodit, že špička je způsobená větším požadovaným souborem.
Podobně platí, že pokud má celková doba služby Application Gateway špičku, ale doba odezvy posledního bajtu back-endu je stabilní, může to být příznak kritických bodů výkonu ve službě Application Gateway nebo kritický bod v síti mezi klientem a službou Application Gateway. Pokud má klient RTT také odpovídající špičku, znamená to, že snížení výkonu je způsobené sítí mezi klientem a službou Application Gateway.
Metriky služby Application Gateway
Pro Službu Application Gateway je k dispozici několik metrik. Seznam najdete v tématu Metriky služby Application Gateway.
Metriky back-endu
Pro Službu Application Gateway je k dispozici několik metrik back-endu. Seznam najdete v tématu Metriky back-endu.
Metriky firewallu webových aplikací (WAF)
Informace o monitorování WAF najdete v tématu Metriky WAF v2 a metriky WAF v1.
Vizualizace metrik
Přejděte do aplikační brány v části Monitorování vyberte Metriky. Chcete-li zobrazit dostupné hodnoty, vyberte rozevírací seznam METRIKA.
Na následujícím obrázku vidíte příklad se třemi metrikami zobrazenými za posledních 30 minut:

Aktuální seznam metrik najdete v tématu Podporované metriky ve službě Azure Monitor.
Pravidla upozornění na metriky
Pravidla upozornění můžete spustit na základě metrik pro prostředek. Výstraha může například volat webhook nebo poslat správci e-mail, pokud je propustnost aplikační brány vyšší, nižší nebo s prahovou hodnotou pro zadané období.
Následující příklad vás provede vytvořením pravidla upozornění, které pošle správci e-mail po porušení prahové hodnoty propustnosti:
Výběrem možnosti Přidat upozornění na metriku otevřete stránku Přidat pravidlo . Na tuto stránku se můžete také dostat ze stránky metrik.
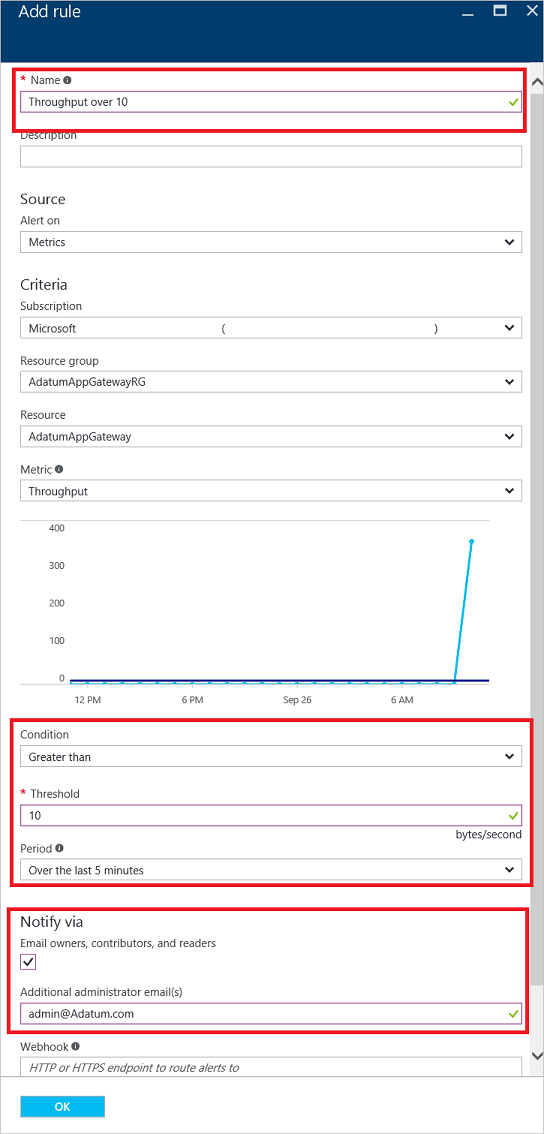
Na stránce Přidat pravidlo vyplňte název, podmínku a upozorněte oddíly a vyberte OK.
V selektoru podmínky vyberte jednu ze čtyř hodnot: Větší než, Větší než nebo Rovno, Menší než nebo Menší než nebo Rovno.
V selektoru období vyberte období od pěti minut do šesti hodin.
Pokud vyberete vlastníky e-mailu, přispěvatele a čtenáře, může být e-mail dynamický na základě uživatelů, kteří mají k danému prostředku přístup. V opačném případě můžete do pole Další e-maily správce zadat seznam uživatelů oddělený čárkami.
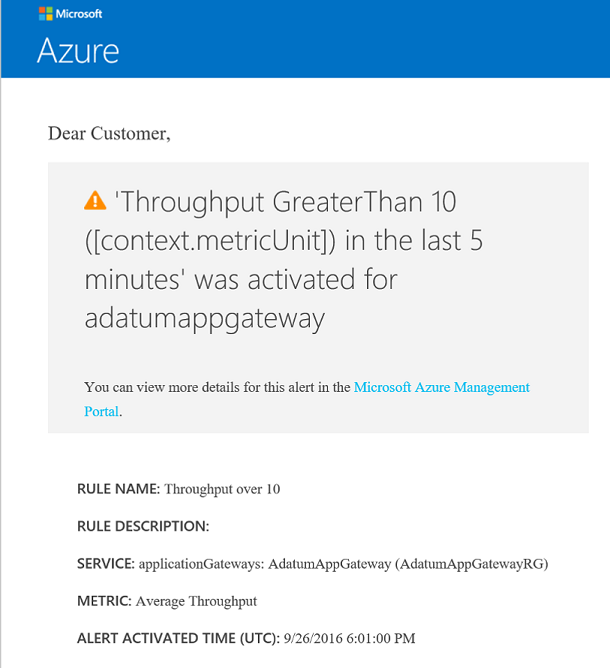
Pokud dojde k porušení prahové hodnoty, přijde e-mail podobný té na následujícím obrázku:
Po vytvoření upozornění na metriku se zobrazí seznam upozornění. Poskytuje přehled všech pravidel upozornění.
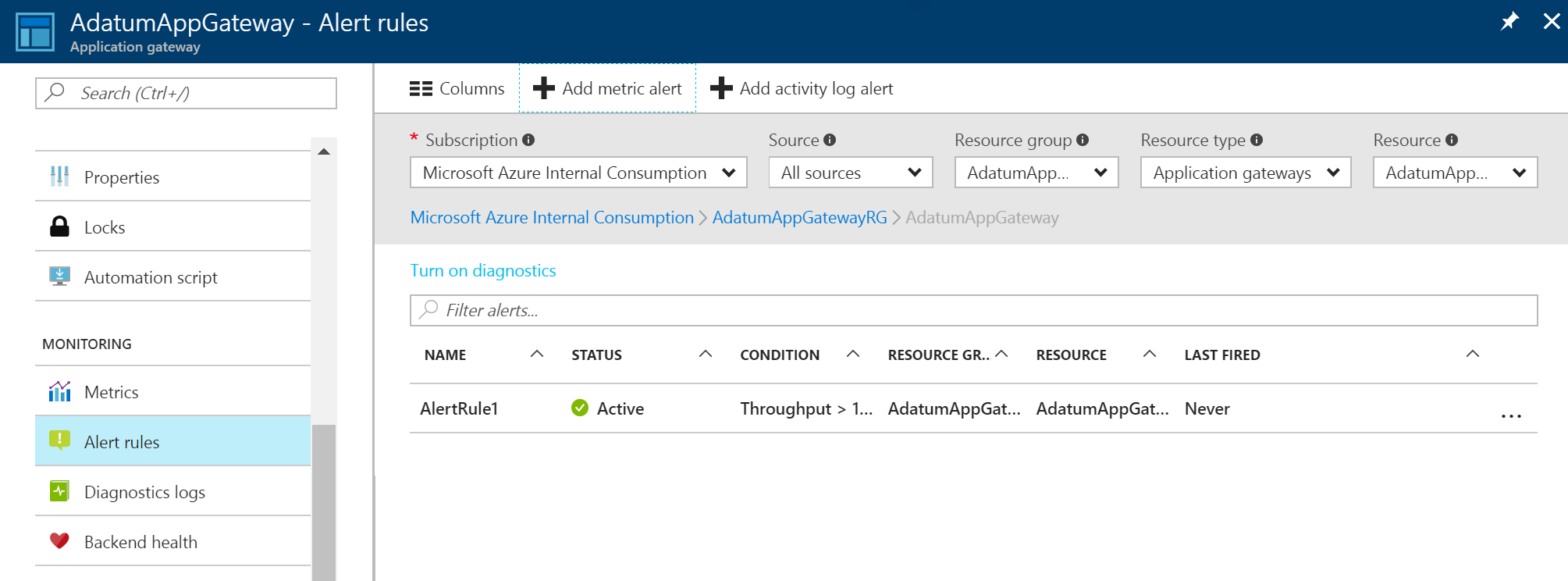
Další informace o upozorněních najdete v tématu Příjem oznámení výstrah.
Další informace o webhoocích a o tom, jak je můžete používat s upozorněními, najdete v tématu Konfigurace webhooku pro upozornění metriky Azure.
Další kroky
- Vizualizujte protokoly čítačů a událostí pomocí protokolů služby Azure Monitor.
- Vizualizujte protokol aktivit Azure pomocí příspěvku na blogu Power BI .
- Zobrazte a analyzujte protokoly aktivit Azure v Power BI a další blogovém příspěvku.