Co je pozorovatelnost služby Container Network?
Pozorovatelnost služby Container Network je funkcí sady Advanced Container Networking Services . Poskytuje vám nástroje pro monitorování a diagnostiku na vyšší úrovni, které poskytují přehled o kontejnerizovaných úlohách. Tyto nástroje vám umožňují snadno určit a řešit problémy se sítí a zajistit tak optimální výkon vašich aplikací.
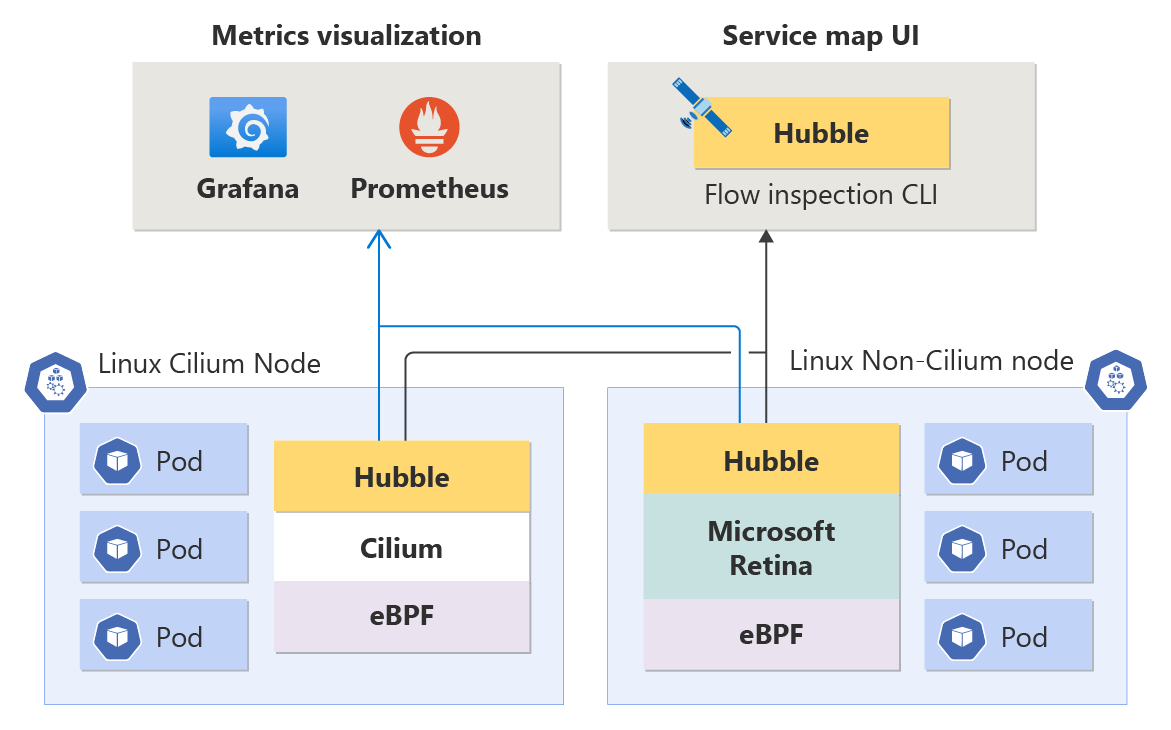
Pozorovatelnost kontejnerové sítě je kompatibilní se všemi linuxovými úlohami bez ohledu na to, jestli je podkladová rovina dat Cilium nebo ne Cilium (obě podporují) zajištění flexibility pro potřeby sítě kontejnerů.
Poznámka:
Pro scénáře roviny dat Cilium je k dispozici pozorovatelnost služby Container Network počínaje Kubernetes verze 1.29. Pozorovatelnost služby Container Network je podporována ve všech distribucích Linuxu, včetně Azure Linuxu počínaje verzí 2.0.
Funkce pozorovatelnosti kontejnerové sítě
Pozorovatelnost služby Container Network nabízí následující možnosti pro monitorování problémů souvisejících se sítí ve vašem clusteru:
Metriky na úrovni uzlů: Pochopení stavu sítě kontejneru na úrovni uzlu je zásadní pro zajištění optimálního výkonu aplikace. Tyto metriky poskytují přehled o objemu provozu, vyřazených paketech, počtu připojení atd. podle uzlu. Metriky jsou uložené ve formátu Prometheus a například je můžete zobrazit v Grafaně.
Metriky DNS (DNS a pod-level): Tyto metriky Prometheus zahrnují informace o zdrojovém a cílovém podu, které umožňují určit problémy související se sítí na podrobné úrovni. Metriky pokrývají objem provozu, zahozené pakety, resetování protokolu TCP, toky paketů L4/L7 atd. Existují také metriky DNS (aktuálně pouze pro roviny dat mimo Cilium), které pokrývají chyby DNS a chybějící odpovědi požadavků DNS.
Protokoly toku Hubble: Protokoly toku poskytují hluboký přehled o síťové aktivitě vašeho clusteru. Veškerá komunikace s pody a z podů se protokoluje, takže můžete v průběhu času zkoumat problémy s připojením. Protokoly toku pomáhají zodpovědět otázky, například: obdržel server požadavek klienta? Jaká je latence odezvy mezi požadavkem klienta a odpovědí serveru?
Hubble CLI: Rozhraní příkazového řádku (CLI) Hubble může načítat protokoly toků v celém clusteru s přizpůsobitelným filtrováním a formátováním.
Uživatelské rozhraní Hubble: Uživatelské rozhraní Hubble je uživatelsky přívětivé rozhraní založené na prohlížeči pro zkoumání síťové aktivity clusteru. Vytvoří graf připojení služby na základě protokolů toku a zobrazí protokoly toku pro vybraný obor názvů. Uživatelé zodpovídají za zřizování a správu infrastruktury potřebné ke spuštění uživatelského rozhraní Hubble.
Klíčové výhody pozorovatelnosti kontejnerové sítě
CNI-Agnostic: Podporováno ve všech variantách Azure CNI, včetně kubenetu.
Cilium a Non-Cilium: Poskytuje jednotné, bezproblémové prostředí v datových rovinách Cilium i non-Cilium.
Pozorovatelnost sítě založená na eBPF: Využívá eBPF (rozšířený filtr paketů Berkeley) k zajištění výkonu a škálovatelnosti k identifikaci potenciálních kritických bodů a problémů se zahlcením dříve, než ovlivní výkon aplikace. Získejte přehled o klíčových ukazatelích stavu sítě, včetně objemu přenosů, zahozených paketů a informací o připojení.
Hloubkový přehled o síťové aktivitě: Zjistěte, jak mezi sebou vaše aplikace komunikují prostřednictvím podrobných protokolů toku sítě.
Zjednodušené možnosti úložiště a vizualizace metrik: Zvolte mezi:
- Azure Managed Prometheus a Grafana: Azure spravuje infrastrukturu a údržbu a umožňuje uživatelům soustředit se na konfiguraci metrik a vizualizaci metrik.
- Bring Your Own (BYO) Prometheus a Grafana: Uživatelé nasazují a konfigurují své vlastní instance a spravují základní infrastrukturu.
Metriky
Metriky na úrovni uzlů
Následující metriky se agregují na každý uzel. Všechny metriky zahrnují popisky:
clusterinstance(Název uzlu)
V případě scénářů roviny dat Cilium poskytuje pozorovatelnost služby Container Network metriky pouze pro Linux, Systém Windows se v současné době nepodporuje. Cilium zveřejňuje několik metrik, včetně následujících metrik používaných službou Container Network Observability.
| Název metriky | Popis | Nadbytečné popisky | Linux | Windows |
|---|---|---|---|---|
| cilium_forward_count_total | Celkový počet přesměrovaných paketů | direction |
✅ | ❌ |
| cilium_forward_bytes_total | Celkový počet přeposlaných bajtů | direction |
✅ | ❌ |
| cilium_drop_count_total | Celkový počet zahozených paketů | direction, reason |
✅ | ❌ |
| cilium_drop_bytes_total | Celkový počet vyřazených bajtů | direction, reason |
✅ | ❌ |
Metriky na úrovni podů (metriky Hubble)
Následující metriky se agregují na pod (informace o uzlu se zachovají). Všechny metriky zahrnují popisky:
clusterinstance(Název uzlu)sourcenebodestination
U odchozího provozu bude popisek s oborem názvů nebo názvem zdrojového source podu.
U příchozího provozu bude popisek s názvem nebo oborem názvů cílového destination podu.
| Název metriky | Popis | Nadbytečné popisky | Linux | Windows |
|---|---|---|---|---|
| hubble_dns_queries_total | Celkový počet požadavků DNS podle dotazu | sourcenebo destination, ( qtypes querytyp dotazu) |
✅ | ❌ |
| hubble_dns_responses_total | Celkový počet odpovědí DNS podle dotazu nebo odpovědi | sourcenebo destination, ( qtypes querytyp dotazu), rcode (návratový kód), ips_returned (počet IP adres) |
✅ | ❌ |
| hubble_drop_total | Celkový počet zahozených paketů | sourcenebo destination, , protocolreason |
✅ | ❌ |
| hubble_tcp_flags_total | Celkový počet paketů TCP podle příznaku | source nebo destination, flag |
✅ | ❌ |
| hubble_flows_processed_total | Celkový počet zpracovaných síťových toků (provoz L4/L7) | sourcenebo destination, , protocol, verdict, typesubtype |
✅ | ❌ |
Omezení
- Metriky na úrovni podů jsou dostupné jenom v Linuxu.
- Rovina dat Cilium se podporuje od Kubernetes verze 1.29.
- Popisky metrik můžou mít drobné rozdíly mezi cilium a necilium shluky.
- U clusterů založených na Cilium jsou metriky DNS dostupné jenom pro pody, které mají v clusterech nakonfigurované zásady sítě Cilium (CNP).
- Protokoly toku nejsou v současné době k dispozici v cloudu, který je ve vzduchu v mezerách.
- Přenosová služba Hubble může dojít k chybovému ukončení, pokud některý z agentů uzlu hubble přestane fungovat a může způsobit přerušení rozhraní příkazového řádku Hubble.
Měřítko
Azure managed Prometheus a Grafana ukládají omezení škálování specifická pro službu. Další informace najdete v tématu Výstřižky metrik Prometheus ve velkém měřítku ve službě Azure Monitor.
Ceny
Důležité
Advanced Container Networking Services je placená nabídka. Další informace o cenách naleznete v tématu Advanced Container Networking Services – Ceny.
Další kroky
- Pokud chcete vytvořit cluster AKS s pozorovatelnostmi kontejnerové sítě, přečtěte si téma Nastavení pozorovatelnosti sítě kontejnerů pro službu Azure Kubernetes Service (AKS).

Azure Kubernetes Service