Kurz: Část 3 – Vyhodnocení vlastní chatovací aplikace pomocí sady Azure AI Foundry SDK
V tomto kurzu použijete sadu Azure AI SDK (a další knihovny) k vyhodnocení chatovací aplikace, kterou jste vytvořili ve 2. části série kurzů. V této třetí části se naučíte:
- Vytvoření testovací datové sady
- Vyhodnocení chatovací aplikace pomocí vyhodnocovačů Azure AI
- Iterace a vylepšení aplikace
Tento kurz je třetí částí třídílného kurzu.
Požadavky
- Dokončete 2. část série kurzů a sestavte chatovací aplikaci.
- Ujistěte se, že jste dokončili kroky pro přidání protokolování telemetrie z části 2.
Vyhodnocení kvality odpovědí chatovací aplikace
Teď, když víte, že vaše chatovací aplikace dobře reaguje na vaše dotazy, včetně historie chatu, je čas vyhodnotit, jak funguje v několika různých metrikách a dalších datech.
Použijete vyhodnocovač s vyhodnocovací datovou sadou a get_chat_response() cílovou funkcí a pak vyhodnotíte výsledky vyhodnocení.
Po spuštění vyhodnocení pak můžete vylepšit logiku, jako je vylepšení výzvy systému, a sledovat, jak se odpovědi chatovací aplikace mění a zlepšují.
Vytvoření zkušební datové sady
Použijte následující testovací datovou sadu, která obsahuje ukázkové otázky a očekávané odpovědi (pravda).
Ve složce assets vytvořte soubor s názvem chat_eval_data.jsonl.
Vložte tuto datovou sadu do souboru:
{"query": "Which tent is the most waterproof?", "truth": "The Alpine Explorer Tent has the highest rainfly waterproof rating at 3000m"} {"query": "Which camping table holds the most weight?", "truth": "The Adventure Dining Table has a higher weight capacity than all of the other camping tables mentioned"} {"query": "How much do the TrailWalker Hiking Shoes cost? ", "truth": "The Trailewalker Hiking Shoes are priced at $110"} {"query": "What is the proper care for trailwalker hiking shoes? ", "truth": "After each use, remove any dirt or debris by brushing or wiping the shoes with a damp cloth."} {"query": "What brand is TrailMaster tent? ", "truth": "OutdoorLiving"} {"query": "How do I carry the TrailMaster tent around? ", "truth": " Carry bag included for convenient storage and transportation"} {"query": "What is the floor area for Floor Area? ", "truth": "80 square feet"} {"query": "What is the material for TrailBlaze Hiking Pants?", "truth": "Made of high-quality nylon fabric"} {"query": "What color does TrailBlaze Hiking Pants come in?", "truth": "Khaki"} {"query": "Can the warrenty for TrailBlaze pants be transfered? ", "truth": "The warranty is non-transferable and applies only to the original purchaser of the TrailBlaze Hiking Pants. It is valid only when the product is purchased from an authorized retailer."} {"query": "How long are the TrailBlaze pants under warranty for? ", "truth": " The TrailBlaze Hiking Pants are backed by a 1-year limited warranty from the date of purchase."} {"query": "What is the material for PowerBurner Camping Stove? ", "truth": "Stainless Steel"} {"query": "Is France in Europe?", "truth": "Sorry, I can only queries related to outdoor/camping gear and equipment"}
Vyhodnocení pomocí vyhodnocovačů Azure AI
Teď definujte zkušební skript, který bude:
- Kolem logiky chatovací aplikace vygenerujte obálku cílové funkce.
- Načtěte ukázkovou datovou
.jsonlsadu. - Spusťte vyhodnocení, které vezme cílovou funkci, a sloučí testovací datovou sadu s odpověďmi z chatovací aplikace.
- Vygenerujte sadu metrik s asistencí GPT (relevance, uzemnění a soudržnost) pro vyhodnocení kvality odpovědí chatovací aplikace.
- Vypíše výsledky místně a výsledky zapíše do cloudového projektu.
Skript umožňuje zkontrolovat výsledky místně tak, že výsledky vypíšete na příkazovém řádku a do souboru JSON.
Skript také protokoluje výsledky vyhodnocení do cloudového projektu, abyste mohli porovnat spuštění vyhodnocení v uživatelském rozhraní.
V hlavní složce vytvořte soubor s názvem evaluate.py .
Přidejte následující kód pro import požadovaných knihoven, vytvoření klienta projektu a konfiguraci některých nastavení:
import os import pandas as pd from azure.ai.projects import AIProjectClient from azure.ai.projects.models import ConnectionType from azure.ai.evaluation import evaluate, GroundednessEvaluator from azure.identity import DefaultAzureCredential from chat_with_products import chat_with_products # load environment variables from the .env file at the root of this repo from dotenv import load_dotenv load_dotenv() # create a project client using environment variables loaded from the .env file project = AIProjectClient.from_connection_string( conn_str=os.environ["AIPROJECT_CONNECTION_STRING"], credential=DefaultAzureCredential() ) connection = project.connections.get_default(connection_type=ConnectionType.AZURE_OPEN_AI, include_credentials=True) evaluator_model = { "azure_endpoint": connection.endpoint_url, "azure_deployment": os.environ["EVALUATION_MODEL"], "api_version": "2024-06-01", "api_key": connection.key, } groundedness = GroundednessEvaluator(evaluator_model)Přidejte kód pro vytvoření funkce obálky, která implementuje rozhraní pro vyhodnocení dotazů a odpovědí:
def evaluate_chat_with_products(query): response = chat_with_products(messages=[{"role": "user", "content": query}]) return {"response": response["message"].content, "context": response["context"]["grounding_data"]}Nakonec přidejte kód pro spuštění vyhodnocení, zobrazte výsledky místně a získáte odkaz na výsledky vyhodnocení na portálu Azure AI Foundry:
# Evaluate must be called inside of __main__, not on import if __name__ == "__main__": from config import ASSET_PATH # workaround for multiprocessing issue on linux from pprint import pprint from pathlib import Path import multiprocessing import contextlib with contextlib.suppress(RuntimeError): multiprocessing.set_start_method("spawn", force=True) # run evaluation with a dataset and target function, log to the project result = evaluate( data=Path(ASSET_PATH) / "chat_eval_data.jsonl", target=evaluate_chat_with_products, evaluation_name="evaluate_chat_with_products", evaluators={ "groundedness": groundedness, }, evaluator_config={ "default": { "query": {"${data.query}"}, "response": {"${target.response}"}, "context": {"${target.context}"}, } }, azure_ai_project=project.scope, output_path="./myevalresults.json", ) tabular_result = pd.DataFrame(result.get("rows")) pprint("-----Summarized Metrics-----") pprint(result["metrics"]) pprint("-----Tabular Result-----") pprint(tabular_result) pprint(f"View evaluation results in AI Studio: {result['studio_url']}")
Konfigurace zkušebního modelu
Vzhledem k tomu, že zkušební skript často volá model, můžete pro model vyhodnocení zvýšit počet tokenů za minutu.
V části 1 této série kurzů jste vytvořili soubor .env , který určuje název zkušebního modelu, gpt-4o-mini. Pokud máte dostupnou kvótu, zkuste pro tento model zvýšit limit tokenů za minutu. Pokud nemáte dostatečnou kvótu na zvýšení hodnoty, nemějte obavy. Skript je navržený tak, aby zpracovával chyby omezení.
- V projektu na portálu Azure AI Foundry vyberte Modely a koncové body.
- Vyberte gpt-4o-mini.
- Vyberte položku Upravit.
- Pokud máte kvótu ke zvýšení limitu počtu tokenů za minutu, zkuste ho zvýšit na 30.
- Zvolte Uložit a zavřít.
Spuštění zkušebního skriptu
Z konzoly se přihlaste ke svému účtu Azure pomocí Azure CLI:
az loginNainstalujte požadovaný balíček:
pip install azure-ai-evaluation[remote]Teď spusťte zkušební skript:
python evaluate.py
Interpretace výstupu vyhodnocení
Ve výstupu konzoly uvidíte odpověď na každou otázku následovanou tabulkou se souhrnnými metrikami. (Ve výstupu se můžou zobrazit různé sloupce.)
Pokud jste u modelu nemohli zvýšit limit tokenů za minutu, může se zobrazit několik chyb vypršení časového limitu, které se očekávají. Zkušební skript je navržený tak, aby tyto chyby zpracovával a pokračoval ve spuštění.
Poznámka:
Můžete se také setkat s mnoha WARNING:opentelemetry.attributes: – tyto hodnoty je možné bezpečně ignorovat a neovlivňují výsledky vyhodnocení.
====================================================
'-----Summarized Metrics-----'
{'groundedness.gpt_groundedness': 1.6666666666666667,
'groundedness.groundedness': 1.6666666666666667}
'-----Tabular Result-----'
outputs.response ... line_number
0 Could you specify which tent you are referring... ... 0
1 Could you please specify which camping table y... ... 1
2 Sorry, I only can answer queries related to ou... ... 2
3 Could you please clarify which aspects of care... ... 3
4 Sorry, I only can answer queries related to ou... ... 4
5 The TrailMaster X4 Tent comes with an included... ... 5
6 (Failed) ... 6
7 The TrailBlaze Hiking Pants are crafted from h... ... 7
8 Sorry, I only can answer queries related to ou... ... 8
9 Sorry, I only can answer queries related to ou... ... 9
10 Sorry, I only can answer queries related to ou... ... 10
11 The PowerBurner Camping Stove is designed with... ... 11
12 Sorry, I only can answer queries related to ou... ... 12
[13 rows x 8 columns]
('View evaluation results in Azure AI Foundry portal: '
'https://xxxxxxxxxxxxxxxxxxxxxxx')
Zobrazení výsledků vyhodnocení na portálu Azure AI Foundry
Po dokončení zkušebního spuštění zobrazte výsledky vyhodnocení na stránce Vyhodnocení na portálu Azure AI Foundry.
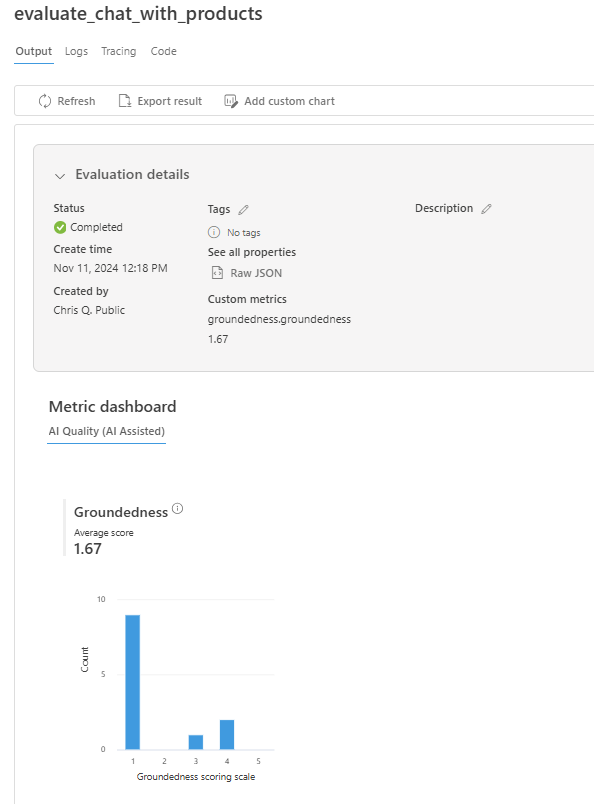
Můžete se také podívat na jednotlivé řádky a zobrazit skóre metrik na jeden řádek a zobrazit úplný kontext nebo dokumenty, které byly načteny. Tyto metriky můžou být užitečné při interpretaci a ladění výsledků vyhodnocení.
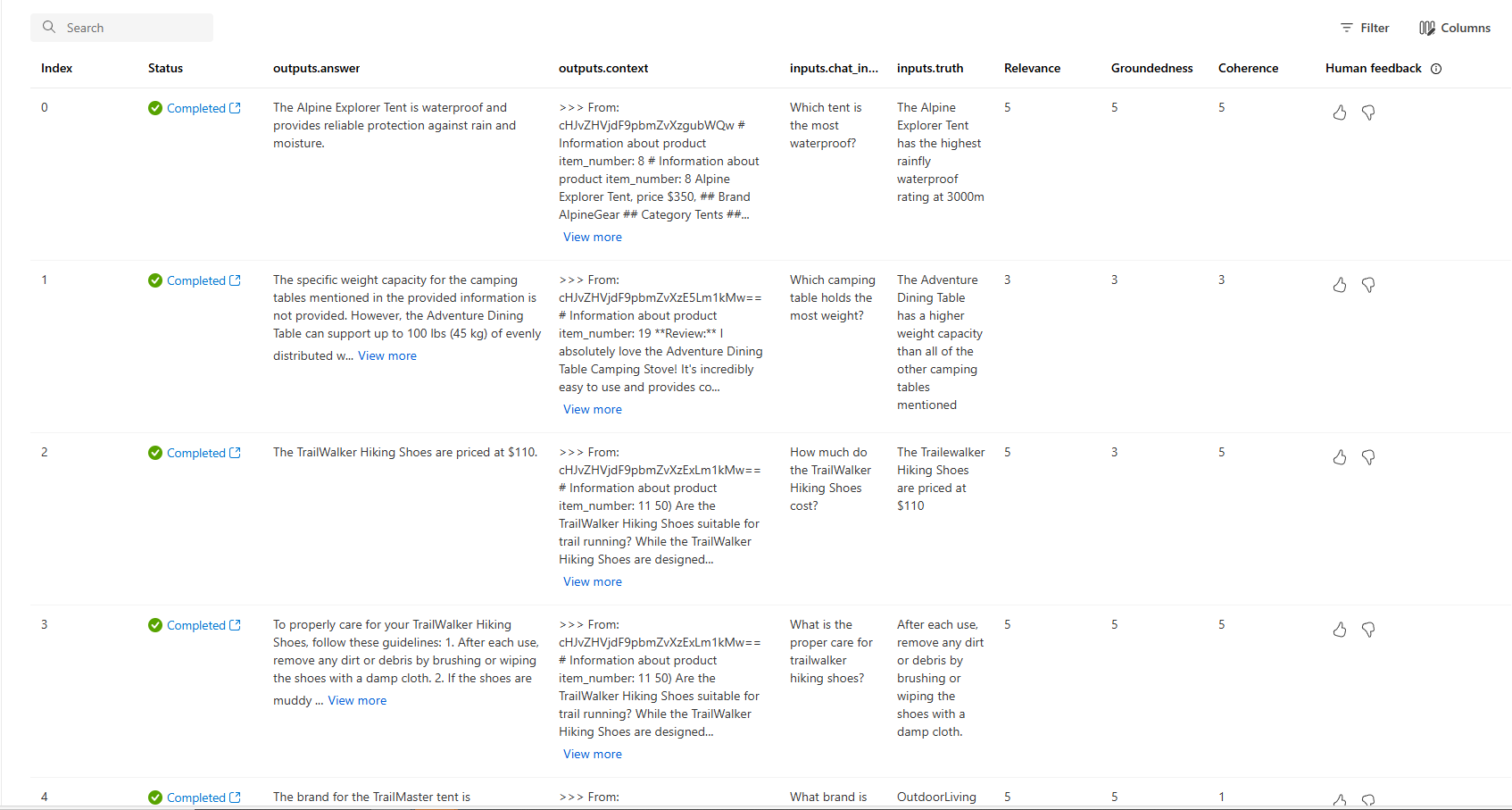
Další informace o výsledcích vyhodnocení na portálu Azure AI Foundry najdete v tématu Jak zobrazit výsledky vyhodnocení na portálu Azure AI Foundry.
Iterace a vylepšení
Všimněte si, že odpovědi nejsou dobře uzemněné. V mnoha případech model odpoví otázkou, nikoli odpovědí. Toto je výsledek pokynů k šabloně výzvy.
- V souboru s informacemi/grounded_chat.prompty najděte větu "Pokud se otázka vztahuje k venkovnímu/kempovacímu vybavení a oblečení, ale nejasné, požádejte o objasnění otázek místo odkazování na dokumenty.".
- Změňte větu na "Pokud otázka souvisí s venkovním/ kempovacím vybavením a oblečením, ale vágní, zkuste odpovědět na základě referenčních dokumentů a požádat o objasnění otázek."
- Uložte soubor a znovu spusťte zkušební skript.
Vyzkoušejte jiné úpravy šablony výzvy nebo zkuste jiné modely, abyste viděli, jak změny ovlivňují výsledky vyhodnocení.
Vyčištění prostředků
Pokud se chcete vyhnout zbytečným nákladům na Azure, měli byste odstranit prostředky, které jste vytvořili v tomto kurzu, pokud už nejsou potřeba. Ke správě prostředků můžete použít Azure Portal.