Jak vyhodnotit modely a aplikace generující AI pomocí Azure AI Foundry
Pokud chcete důkladně posoudit výkon generovaných modelů AI a aplikací při použití na podstatnou datovou sadu, můžete zahájit proces vyhodnocení. Během tohoto vyhodnocení se model nebo aplikace testují s danou datovou sadou a jeho výkon se bude kvantitativní měřit pomocí matematických metrik i metrik s asistencí AI. Tato zkušební spuštění poskytuje komplexní přehled o možnostech a omezeních aplikace.
K provedení tohoto vyhodnocení můžete využít funkce vyhodnocení na portálu Azure AI Foundry, komplexní platformu, která nabízí nástroje a funkce pro posouzení výkonu a bezpečnosti vašeho generujícího modelu AI. Na portálu Azure AI Foundry můžete protokolovat, zobrazovat a analyzovat podrobné metriky hodnocení.
V tomto článku se dozvíte, jak vytvořit testovací běh proti modelu, testovací datovou sadu nebo tok s integrovanými metrikami vyhodnocení z uživatelského rozhraní Azure AI Foundry. Pokud chcete větší flexibilitu, můžete vytvořit vlastní tok vyhodnocení a použít vlastní funkci vyhodnocení . Pokud je vaším cílem provést dávkové spuštění pouze bez vyhodnocení, můžete také využít vlastní funkci vyhodnocení.
Požadavky
Pokud chcete spustit vyhodnocení s metrikami s asistencí AI, musíte mít následující připravené:
- Testovací datová sada v jednom z těchto formátů:
csvnebojsonl. - Připojení Azure OpenAI Nasazení jednoho z těchto modelů: modely GPT 3.5, modely GPT 4 nebo Modely Davinci. Vyžaduje se pouze v případě, že spustíte hodnocení kvality s asistencí umělé inteligence.
Vytvoření vyhodnocení s využitím předdefinovaných metrik vyhodnocení
Spuštění vyhodnocení umožňuje generovat výstupy metrik pro každý řádek dat v testovací datové sadě. Můžete zvolit jednu nebo více metrik vyhodnocení, abyste mohli vyhodnotit výstup z různých aspektů. Na portálu Azure AI Foundry můžete vytvořit zkušební spuštění z webu hodnocení, katalogu modelů nebo na stránkách toku výzvy. Pak se zobrazí průvodce vytvořením vyhodnocení, který vás provede procesem nastavení zkušebního spuštění.
Na stránce vyhodnocení
V levé sbalitelné nabídce vyberte Vyhodnocení> a vytvořit nové vyhodnocení.

Ze stránky katalogu modelů
V levé sbalitelné nabídce vyberte Katalog> modelů, přejděte na konkrétní model>, přejděte na kartu > Srovnávací test Vyzkoušet s vlastními daty. Tím se otevře panel vyhodnocení modelu, který vám umožní vytvořit spuštění vyhodnocení pro vybraný model.

Ze stránky toku
V levé sbalitelné nabídce vyberte Tok>výzvy Vyhodnotit>automatizované vyhodnocení.

Cíl vyhodnocení
Když začnete vyhodnocení ze stránky vyhodnocení, musíte nejprve rozhodnout, jaký je cíl vyhodnocení. Zadáním vhodného cíle vyhodnocení můžeme hodnocení přizpůsobit konkrétní povaze vaší aplikace a zajistit přesné a relevantní metriky. Podporujeme tři typy cíle hodnocení:
- Model a výzva: Chcete vyhodnotit výstup vygenerovaný vybraným modelem a uživatelem definovanou výzvou.
- Datová sada: V testovací datové sadě už máte vygenerované výstupy modelu.
- Tok výzvy: Vytvořili jste tok a chcete vyhodnotit výstup z toku.

Vyhodnocení toku datové sady nebo výzvy
Když zadáte průvodce vytvořením vyhodnocení, můžete zadat volitelný název pro spuštění vyhodnocení. V současné době nabízíme podporu pro scénář dotazů a odpovědí, který je určený pro aplikace, které zahrnují odpovědi na dotazy uživatelů a poskytování odpovědí s kontextovými informacemi nebo bez ně.
Volitelně můžete přidat popisy a značky ke zkušebním spuštěním pro vylepšenou organizaci, kontext a snadné načítání.
Pomocí panelu nápovědy můžete také zkontrolovat nejčastější dotazy a průvodce průvodcem.

Pokud vyhodnocujete tok výzvy, můžete vybrat tok, který chcete vyhodnotit. Pokud zahájíte vyhodnocení ze stránky Flow, automaticky vybereme váš tok, který se má vyhodnotit. Pokud máte v úmyslu vyhodnotit jiný tok, můžete vybrat jiný tok. Je důležité si uvědomit, že v rámci toku můžete mít více uzlů, z nichž každá může mít vlastní sadu variant. V takových případech musíte určit uzel a varianty, které chcete vyhodnotit během procesu vyhodnocení.

Konfigurace testovacích dat
Můžete vybrat z existujících datových sad nebo nahrát novou datovou sadu, která se má vyhodnotit. Testovací datová sada musí mít vygenerované výstupy modelu, které se mají použít k vyhodnocení, pokud v předchozím kroku není vybraný žádný tok.
Zvolte existující datovou sadu: Testovací datovou sadu můžete zvolit z vytvořené kolekce datových sad.
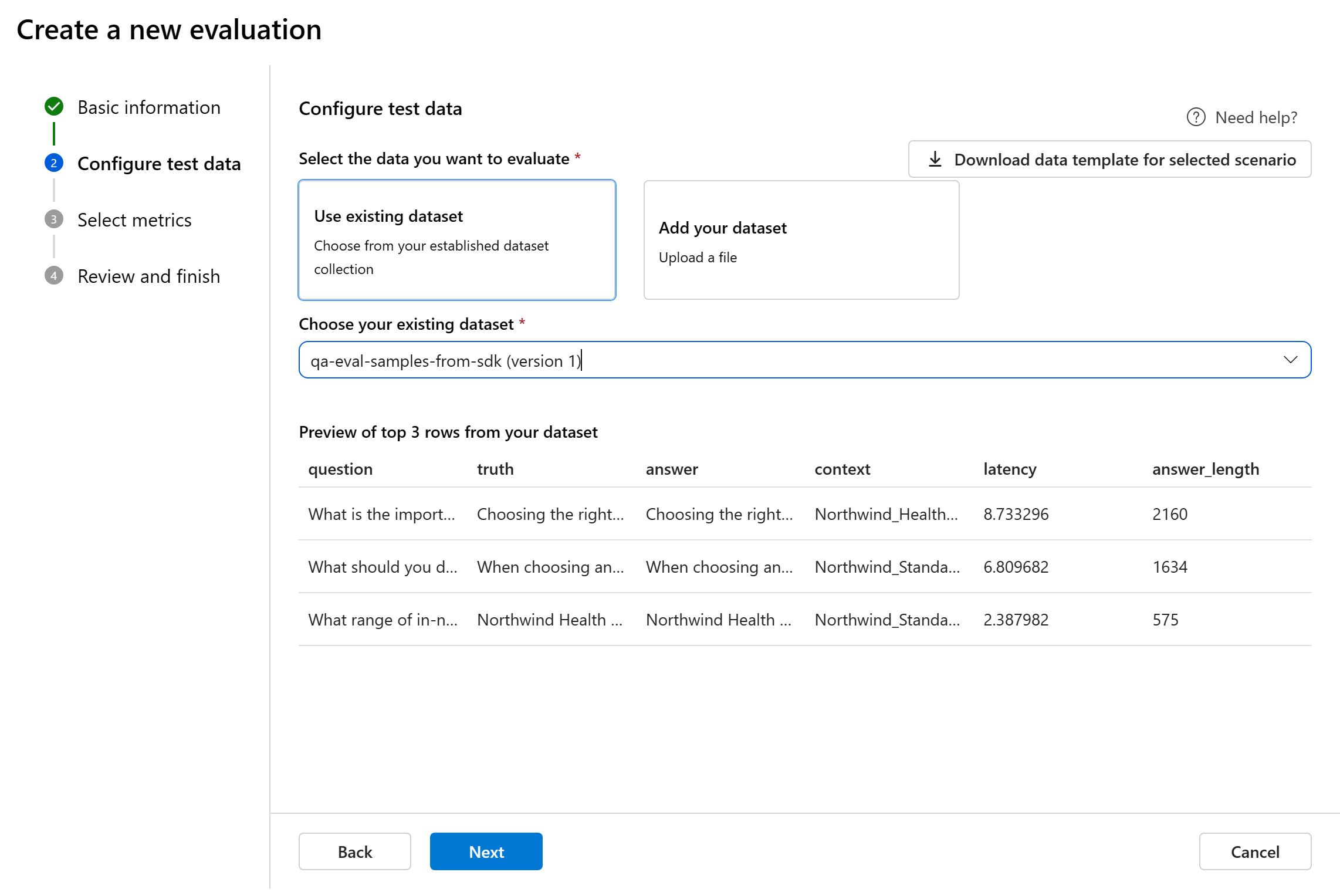
Přidat novou datovou sadu: Soubory můžete nahrát z místního úložiště. Podporujeme
.csvpouze formáty souborů a.jsonlformáty souborů.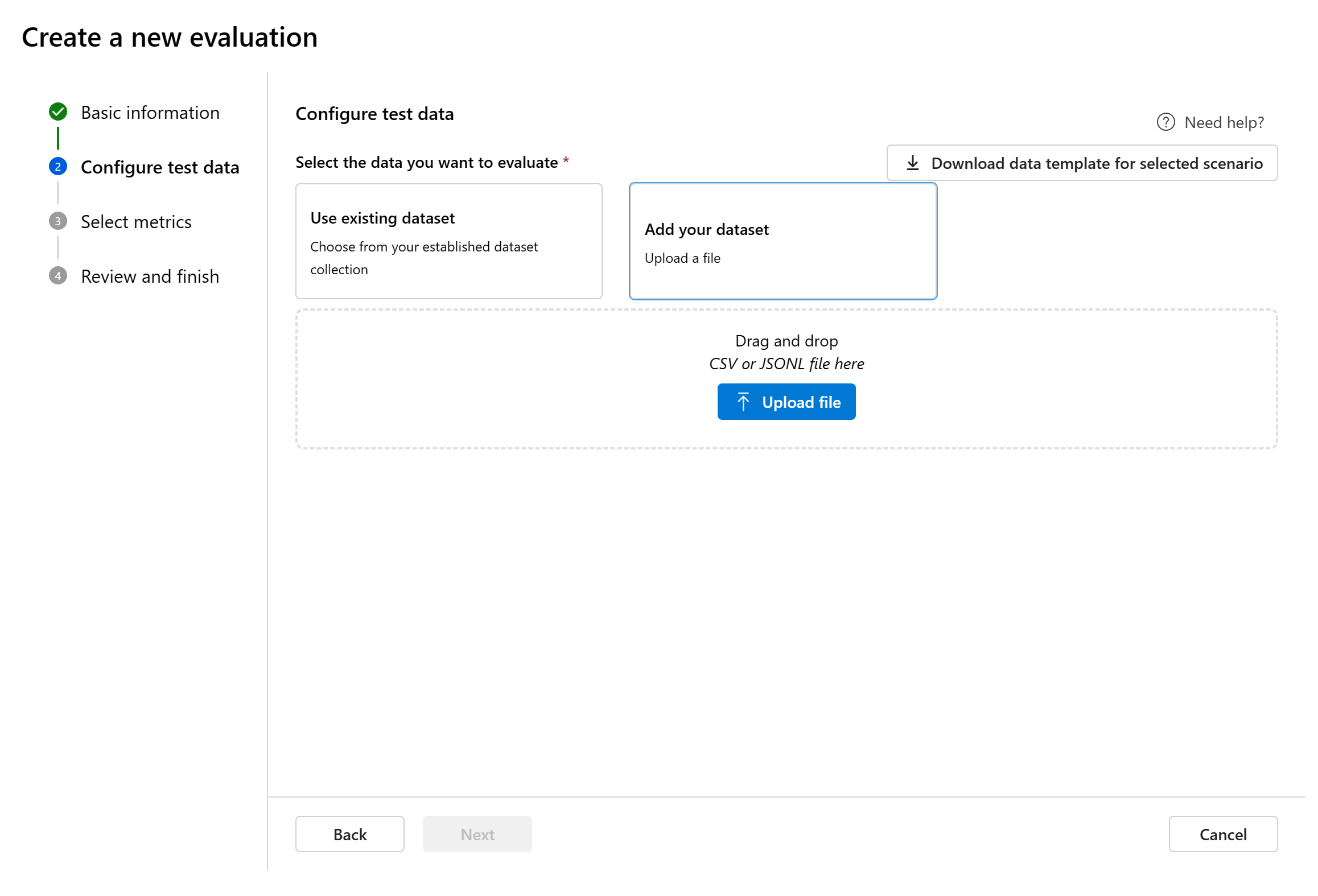
Mapování dat pro tok: Pokud vyberete tok, který se má vyhodnotit, ujistěte se, že jsou vaše datové sloupce nakonfigurované tak, aby odpovídaly požadovaným vstupům pro spuštění toku, aby se spustil dávkové spuštění a vygeneroval výstup pro posouzení. Vyhodnocení se pak provede pomocí výstupu z toku. Pak nakonfigurujte mapování dat pro vstupy vyhodnocení v dalším kroku.




Výběr metrik
Podporujeme tři typy metrik kurátorovaných Microsoftem, abychom usnadnili komplexní vyhodnocení vaší aplikace:
- Kvalita AI (asistovaná AI): Tyto metriky vyhodnocují celkovou kvalitu a soudržnost generovaného obsahu. Ke spuštění těchto metrik vyžaduje nasazení modelu jako soudce.
- Kvalita AI (NLP): Tyto metriky NLP jsou matematické a také vyhodnocují celkovou kvalitu generovaného obsahu. Často vyžadují základní pravdivá data, ale nevyžadují nasazení modelu jako soudce.
- Metriky rizik a bezpečnosti: Tyto metriky se zaměřují na identifikaci potenciálních rizik obsahu a zajištění bezpečnosti generovaného obsahu.

V tabulce najdete úplný seznam metrik, pro které nabízíme podporu v jednotlivých scénářích. Podrobnější informace o jednotlivých definicích metrik a jejich výpočtu najdete v tématu Vyhodnocení a monitorování metrik.
| Kvalita AI (asistovaná AI) | Kvalita AI (NLP) | Metriky rizik a bezpečnosti |
|---|---|---|
| Uzemnění, relevance, soudržnost, plynulost, podobnost GPT | F1 score, ROUGE, score, BLEU score, GLEU score, METEOR score | Obsah související s vlastním poškozením, nenávistný a nespravedlivý obsah, násilné obsah, sexuální obsah, chráněný materiál, nepřímý útok |
Při spouštění hodnocení kvality asistované umělé inteligence je nutné zadat model GPT pro výpočetní proces. Zvolte připojení Azure OpenAI a nasazení s využitím GPT-3.5, GPT-4 nebo modelu Davinci pro naše výpočty.

Metriky kvality AI (NLP) jsou matematicky založené na měřeních, která vyhodnocují výkon vaší aplikace. Často vyžadují základní pravdivá data pro výpočet. ROUGE je řada metrik. Pokud chcete vypočítat skóre, můžete vybrat typ ROUGE. Různé typy metrik ROUGE nabízejí způsoby, jak vyhodnotit kvalitu generování textu. ROUGE-N měří překrývání n-gramů mezi kandidátskými a referenčními texty.

U metrik rizik a bezpečnosti nemusíte zadávat připojení a nasazení. Back-endová služba portálu Azure AI Foundry zřídí model GPT-4, který může generovat skóre závažnosti rizika obsahu a odůvodnění, které vám umožní vyhodnotit vaši aplikaci za poškození obsahu.
Můžete nastavit prahovou hodnotu pro výpočet míry vad pro metriky poškození obsahu (obsah související s vlastním poškozením, nenávistný a nespravedlivý obsah, násilné obsah, sexuální obsah). Rychlost vad se vypočítá tak, že vezme procento instancí s úrovněmi závažnosti (velmi nízká, nízká, střední, vysoká) nad prahovou hodnotou. Ve výchozím nastavení nastavíme prahovou hodnotu na Střední.
U chráněného materiálu a nepřímého útoku se sazba vad počítá tak, že vezme procento instancí, kde je výstup "true" (Defect Rate = (#trues / #instances) × 100).

Poznámka:
Metriky rizik a bezpečnosti s asistencí umělé inteligence jsou hostované back-endovou službou vyhodnocení bezpečnosti Azure AI Foundry a jsou k dispozici pouze v následujících oblastech: USA – východ 2, Francie – střed, Velká Británie – jih, Švédsko – střed
Mapování dat pro vyhodnocení: Je nutné určit, které datové sloupce v datové sadě odpovídají vstupům potřebným při vyhodnocení. Různé vyhodnocovací metriky vyžadují různé typy datových vstupů pro přesné výpočty.

Poznámka:
Pokud vyhodnocujete data, měla by se odpověď namapovat na sloupec odpovědi ve vaší datové sadě ${data$response}. Pokud vyhodnocujete tok, měla by odpověď pocházet z výstupu ${run.outputs.response}toku .
Pokyny ke konkrétním požadavkům mapování dat pro každou metriku najdete v informacích uvedených v tabulce:
Požadavky na metriky dotazů a odpovědí
| Metrika | Dotaz | Response | Kontext | Základní pravda |
|---|---|---|---|---|
| Uzemnění | Povinné: Str | Povinné: Str | Povinné: Str | – |
| Koherence | Povinné: Str | Povinné: Str | – | N/A |
| Plynulost | Povinné: Str | Povinné: Str | – | N/A |
| Relevance | Povinné: Str | Povinné: Str | Povinné: Str | – |
| Podobnost GPT | Povinné: Str | Povinné: Str | – | Povinné: Str |
| F1 – skóre | – | Povinné: Str | – | Povinné: Str |
| Skóre BLEU | – | Povinné: Str | – | Povinné: Str |
| Skóre GLEU | – | Povinné: Str | – | Povinné: Str |
| Skóre METEOR | – | Povinné: Str | – | Povinné: Str |
| SKÓRE VE SPOLEČNOSTI ROUGE | – | Povinné: Str | – | Povinné: Str |
| Obsah související s vlastním poškozením | Povinné: Str | Povinné: Str | – | N/A |
| Nenávistný a nespravedlivý obsah | Povinné: Str | Povinné: Str | – | N/A |
| Násilné obsah | Povinné: Str | Povinné: Str | – | N/A |
| Sexuální obsah | Povinné: Str | Povinné: Str | – | N/A |
| Chráněný materiál | Povinné: Str | Povinné: Str | – | N/A |
| Nepřímý útok | Povinné: Str | Povinné: Str | – | N/A |
- Dotaz: dotaz, který hledá konkrétní informace.
- Odpověď: odpověď na dotaz vygenerovaný modelem.
- Kontext: zdroj, který je vygenerována odpověď s ohledem na (to znamená podkladové dokumenty)...
- Pravdivá pravda: odpověď na dotaz vygenerovaný uživatelem nebo člověkem jako pravdivá odpověď.
Kontrola a dokončení
Po dokončení všech potřebných konfigurací můžete zkontrolovat a pokračovat výběrem možnosti Odeslat a odeslat zkušební spuštění.

Modelování a vyhodnocení výzvy
Pokud chcete vytvořit nové vyhodnocení pro vybrané nasazení modelu a definovanou výzvu, použijte zjednodušený panel vyhodnocení modelu. Toto zjednodušené rozhraní umožňuje konfigurovat a inicializovat vyhodnocení v rámci jednoho konsolidovaného panelu.
Základní informace
Začněte tím, že nastavíte název zkušebního spuštění. Pak vyberte nasazení modelu, které chcete vyhodnotit. Podporujeme modely Azure OpenAI i jiné otevřené modely kompatibilní s modelem jako službou (MaaS), jako jsou modely řady Meta Llama a Phi-3. Volitelně můžete upravit parametry modelu, jako je maximální odezva, teplota a nejvyšší P podle vašich potřeb.
Do textového pole Systémová zpráva zadejte výzvu pro váš scénář. Další informace o tom, jak vytvořit výzvu, naleznete v katalogu výzvy. Můžete se rozhodnout přidat příklad, abyste zobrazili chat, jaké odpovědi chcete. Pokusí se napodobovat všechny odpovědi, které sem přidáte, aby odpovídaly pravidlům stanoveným v systémové zprávě.

Konfigurace testovacích dat
Po nakonfigurování modelu a zobrazení výzvy nastavte testovací datovou sadu, která se použije k vyhodnocení. Tato datová sada se odešle do modelu, aby se vygenerovaly odpovědi pro posouzení. Máte tři možnosti konfigurace testovacích dat:
- Generování ukázkových dat
- Použití existující datové sady
- Přidání datové sady
Pokud datovou sadu nemáte snadno dostupnou a chcete spustit vyhodnocení s malou ukázkou, můžete vybrat možnost použití modelu GPT k vygenerování ukázkových otázek na základě zvoleného tématu. Toto téma vám pomůže přizpůsobit vygenerovaný obsah pro vaši oblast zájmu. Dotazy a odpovědi se vygenerují v reálném čase a máte možnost je podle potřeby znovu vygenerovat.
Poznámka:
Vygenerovaná datová sada se po vytvoření zkušebního spuštění uloží do úložiště objektů blob projektu.

Mapování dat
Pokud se rozhodnete použít existující datovou sadu nebo nahrát novou datovou sadu, budete muset sloupce datové sady namapovat na požadovaná pole pro vyhodnocení. Během vyhodnocení se odpověď modelu vyhodnotí na základě klíčových vstupů, jako jsou:
- Dotaz: Vyžadováno pro všechny metriky
- Kontext: volitelné
- Základní pravda: volitelné, povinné pro metriky kvality AI (NLP)
Tato mapování zajišťují přesné zarovnání mezi vašimi daty a kritérii hodnocení.

Volba metrik vyhodnocení
Posledním krokem je výběr toho, co chcete vyhodnotit. Místo výběru jednotlivých metrik a seznámení se všemi dostupnými možnostmi zjednodušíme proces tím, že vám umožní vybrat kategorie metrik, které nejlépe vyhovují vašim potřebám. Když zvolíte kategorii, budou se všechny relevantní metriky v dané kategorii počítat na základě datových sloupců, které jste zadali v předchozím kroku. Jakmile vyberete kategorie metrik, můžete výběrem možnosti Vytvořit odeslat zkušební spuštění a přejít na stránku vyhodnocení a zobrazit výsledky.
Podporujeme tři kategorie:
- Kvalita AI (asistovaná AI): Musíte jako soudce poskytnout nasazení modelu Azure OpenAI, abyste mohli vypočítat metriky asistované umělé inteligence.
- Kvalita AI (NLP)
- Bezpečnost
| Kvalita AI (asistovaná AI) | Kvalita AI (NLP) | Bezpečnost |
|---|---|---|
| Uzemnění (vyžadování kontextu), relevance (vyžadování kontextu), soudržnost, plynulost | F1 score, ROUGE, score, BLEU score, GLEU score, METEOR score | Obsah související s vlastním poškozením, nenávistný a nespravedlivý obsah, násilné obsah, sexuální obsah, chráněný materiál, nepřímý útok |
Vytvoření vyhodnocení s využitím vlastního toku vyhodnocení
Můžete vyvíjet vlastní metody hodnocení:
Na stránce toku: V levé sbalitelné nabídce vyberte Možnost Vyhodnocení>vlastního vyhodnocení toku>výzvy.

Zobrazení a správa vyhodnocovačů v knihovně vyhodnocovače
Knihovna vyhodnocovače je centralizované místo, kde můžete zobrazit podrobnosti a stav vyhodnocovačů. Můžete zobrazit a spravovat vyhodnocovače kurátorovaných Microsoftem.
Tip
Vlastní vyhodnocovače můžete použít prostřednictvím sady SDK toku výzvy. Další informace najdete v tématu Vyhodnocení pomocí sady SDK toku výzvy.
Knihovna vyhodnocovače také umožňuje správu verzí. V případě potřeby můžete porovnat různé verze práce, obnovit předchozí verze a snadněji spolupracovat s ostatními.
Pokud chcete použít knihovnu vyhodnocovače na portálu Azure AI Foundry, přejděte na stránku Vyhodnocení projektu a vyberte kartu Knihovny vyhodnocovače.

Pokud chcete zobrazit další podrobnosti, můžete vybrat název vyhodnocovače. Můžete zobrazit název, popis a parametry a zkontrolovat všechny soubory přidružené k vyhodnocovaci. Tady je několik příkladů kurátorovaných vyhodnocovačů Microsoftu:
- U vyhodnocovačů výkonu a kvality kurátorovaných Microsoftem můžete zobrazit výzvu k poznámce na stránce s podrobnostmi. Tyto výzvy můžete přizpůsobit vlastnímu případu použití tak, že změníte parametry nebo kritéria podle vašich dat a cílů sady AZURE AI Evaluation SDK. Můžete například vybrat Groundedness-Evaluator a zkontrolovat soubor Výzvy ukazující způsob výpočtu metriky.
- U vyhodnocovačů rizik a bezpečnosti kurátorovaných Microsoftem si můžete prohlédnout definici metrik. Můžete například vybrat vyhodnocovač obsahu souvisejícího s vlastním poškozením a zjistit, co to znamená a jak Microsoft určuje různé úrovně závažnosti pro tuto bezpečnostní metriku.
Další kroky
Přečtěte si další informace o tom, jak vyhodnotit aplikace generující umělé inteligence:
- Vyhodnocení aplikací generující umělé inteligence prostřednictvím dětského hřiště
- Zobrazení výsledků vyhodnocení
- Přečtěte si další informace o technikách zmírnění škod.
- Poznámka k transparentnosti pro vyhodnocení bezpečnosti Azure AI Foundry