Vývoj aplikací pomocí llamaIndex a Azure AI Foundry
V tomto článku se dozvíte, jak používat LlamaIndex s modely nasazenými z katalogu modelů Azure AI na portálu Azure AI Foundry.
Modely nasazené v Azure AI Foundry je možné s LlamaIndex použít dvěma způsoby:
Použití rozhraní API pro odvozování modelů Azure AI: Všechny modely nasazené do Azure AI Foundry podporují rozhraní API pro odvozování modelů Azure AI, které nabízí společnou sadu funkcí, které lze použít pro většinu modelů v katalogu. Výhodou tohoto rozhraní API je to, že vzhledem k tomu, že je to stejné pro všechny modely, změna z jednoho na druhé je stejně jednoduchá jako změna používaného nasazení modelu. V kódu nejsou vyžadovány žádné další změny. Při práci s llamaIndex nainstalujte rozšíření
llama-index-llms-azure-inferenceallama-index-embeddings-azure-inference.Použití rozhraní API specifické pro poskytovatele modelu: Některé modely, jako jsou OpenAI, Cohere nebo Mistral, nabízejí vlastní sadu rozhraní API a rozšíření pro LlamaIndex. Tato rozšíření mohou zahrnovat konkrétní funkce, které model podporuje, a proto jsou vhodné, pokud je chcete zneužít. Při práci s
llama-index, nainstalujte rozšíření specifické pro model, který chcete použít, napříkladllama-index-llms-openainebollama-index-llms-cohere.
V tomto příkladu pracujeme s rozhraním API pro odvozování modelu Azure AI.
Požadavky
Ke spuštění tohoto kurzu potřebujete:
Projekt Azure AI, jak je vysvětleno v tématu Vytvoření projektu na portálu Azure AI Foundry.
Model podporující rozhraní API pro odvozování modelů Azure AI nasazené V tomto příkladu
Mistral-Largepoužíváme nasazení, ale používáme libovolný model vašich preferencí. Pro použití funkcí vkládání v llamaIndex potřebujete model vložení, jako jecohere-embed-v3-multilingual.- Můžete postupovat podle pokynů v tématu Nasazení modelů jako bezserverových rozhraní API.
Nainstalovaný Python 3.8 nebo novější, včetně pipu.
Nainstalovali jsme llamaIndex. Můžete to udělat pomocí:
pip install llama-indexV tomto příkladu pracujeme s rozhraním API pro odvozování modelů Azure AI, proto nainstalujeme následující balíčky:
pip install -U llama-index-llms-azure-inference pip install -U llama-index-embeddings-azure-inferenceDůležité
Použití služby odvozování modelu Azure AI vyžaduje verzi
0.2.4prollama-index-llms-azure-inferencenebollama-index-embeddings-azure-inference.
Konfigurace prostředí
Pokud chcete používat LLM nasazené na portálu Azure AI Foundry, budete k němu potřebovat koncový bod a přihlašovací údaje. Pokud chcete získat potřebné informace z modelu, který chcete použít, postupujte takto:
Přejděte do Azure AI Foundry.
Otevřete projekt, ve kterém je model nasazený, pokud ještě není otevřený.
Přejděte na Modely + koncové body a vyberte model, který jste nasadili podle požadavků.
Zkopírujte adresu URL koncového bodu a klíč.
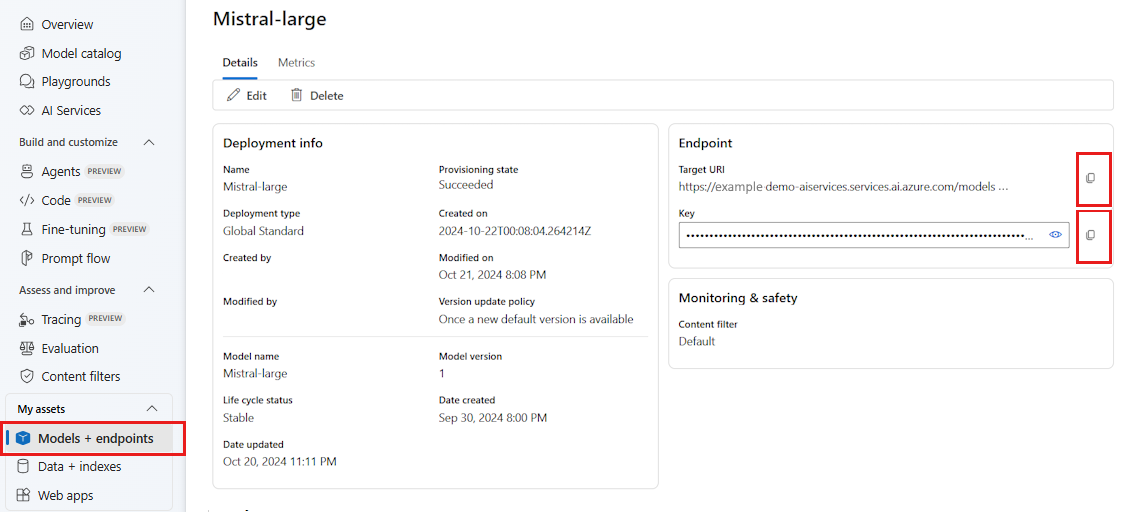
Tip
Pokud byl váš model nasazený s podporou Microsoft Entra ID, nepotřebujete klíč.

V tomto scénáři jsme umístili adresu URL koncového bodu i klíč do následujících proměnných prostředí:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Po nakonfigurování vytvořte klienta pro připojení ke koncovému bodu.
import os
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
)
Tip
Pokud je vaše nasazení modelu hostované ve službě Azure OpenAI nebo prostředku Azure AI Services, nakonfigurujte klienta podle pokynů v modelech Azure OpenAI a ve službě odvozování modelů Azure AI.
Pokud váš koncový bod obsluhuje více než jeden model, jako je služba odvozování modelů Azure AI nebo Modely GitHubu, musíte označit model_name parametr:
import os
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
)
Pokud váš koncový bod podporuje MICROSOFT Entra ID, můžete k vytvoření klienta použít následující kód:
import os
from azure.identity import DefaultAzureCredential
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
)
Poznámka:
Při použití ID Microsoft Entra se ujistěte, že koncový bod byl nasazen pomocí této metody ověřování a že máte požadovaná oprávnění k jeho vyvolání.
Pokud plánujete používat asynchronní volání, je osvědčeným postupem použít asynchronní verzi přihlašovacích údajů:
from azure.identity.aio import (
DefaultAzureCredential as DefaultAzureCredentialAsync,
)
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredentialAsync(),
)
Modely Azure OpenAI a služba odvozování modelů Azure AI
Pokud používáte službu Azure OpenAI nebo službu odvozování modelů Azure AI, ujistěte se, že máte aspoň verzi 0.2.4 integrace LlamaIndex. Pokud api_version potřebujete vybrat konkrétní parametr, použijte parametr api_version.
Pro službu odvozování modelu Azure AI je potřeba předat model_name parametr:
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
)
Pro službu Azure OpenAI:
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint="https://<resource>.openai.azure.com/openai/deployments/<deployment-name>",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
api_version="2024-05-01-preview",
)
Tip
Zkontrolujte, která verze rozhraní API vaše nasazení používá. Při použití nesprávného api_version nebo nepodporovaného modelu vznikne ResourceNotFound výjimka.
Parametry odvození
Způsob odvozování můžete nakonfigurovat pro všechny operace, které používají tohoto klienta, nastavením dalších parametrů. To pomáhá vyhnout se jejich označení při každém volání modelu.
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
temperature=0.0,
model_kwargs={"top_p": 1.0},
)
Parametry, které nejsou podporované v rozhraní API pro odvozování modelů Azure AI (reference), ale dostupné v podkladovém modelu, můžete použít model_extras argument. V následujícím příkladu se předává parametr safe_prompt, který je k dispozici pouze pro Modely Mistral.
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
temperature=0.0,
model_kwargs={"model_extras": {"safe_prompt": True}},
)
Použití modelů LLM
Klienta můžete použít přímo nebo nakonfigurovat modely používané vaším kódem v llamaIndex. Pokud chcete model použít přímo, použijte metodu pro modely instrukcí chatu chat :
from llama_index.core.llms import ChatMessage
messages = [
ChatMessage(
role="system", content="You are a pirate with colorful personality."
),
ChatMessage(role="user", content="Hello"),
]
response = llm.chat(messages)
print(response)
Výstupy můžete streamovat také:
response = llm.stream_chat(messages)
for r in response:
print(r.delta, end="")
Metoda complete je stále k dispozici pro model typu chat-completions. V těchto případech je vstupní text převeden na zprávu s role="user".
Použití modelů vkládání
Stejným způsobem jako vytvoříte klienta LLM, můžete se připojit k modelu vkládání. V následujícím příkladu nastavujeme proměnnou prostředí tak, aby teď odkazovala na model vkládání:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Pak vytvořte klienta:
from llama_index.embeddings.azure_inference import AzureAIEmbeddingsModel
embed_model = AzureAIEmbeddingsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ['AZURE_INFERENCE_CREDENTIAL'],
)
Následující příklad ukazuje jednoduchý test, který ověří, že funguje:
from llama_index.core.schema import TextNode
nodes = [
TextNode(
text="Before college the two main things I worked on, "
"outside of school, were writing and programming."
)
]
response = embed_model(nodes=nodes)
print(response[0].embedding)
Konfigurace modelů používaných vaším kódem
Klienta modelu LLM nebo embeddings můžete použít jednotlivě v kódu, který vyvíjíte pomocí llamaIndex, nebo můžete nakonfigurovat celou relaci pomocí Settings možností. Konfigurace relace má výhodu veškerého kódu pomocí stejných modelů pro všechny operace.
from llama_index.core import Settings
Settings.llm = llm
Settings.embed_model = embed_model
Existují však scénáře, ve kterých chcete pro většinu operací použít obecný model, ale konkrétní model pro daný úkol. V těchto případech je užitečné nastavit model LLM nebo vkládání, který používáte pro každý konstruktor LlamaIndex. V následujícím příkladu nastavíme konkrétní model:
from llama_index.core.evaluation import RelevancyEvaluator
relevancy_evaluator = RelevancyEvaluator(llm=llm)
Obecně platí, že používáte kombinaci obou strategií.