Přidání datové sady pro profesionální hlasové trénování
Až budete připraveni vytvořit vlastní text pro hlasový hlas pro vaši aplikaci, je prvním krokem shromáždění zvukových nahrávek a přidružených skriptů pro zahájení trénování hlasového modelu. Podrobnosti o nahrávání hlasových ukázek najdete v tomto kurzu. Služba Speech používá tato data k vytvoření jedinečného hlasu vyladěného tak, aby odpovídala hlasu v záznamech. Po natrénování hlasu můžete v aplikacích začít syntetizovat řeč.
Všechna data, která nahrajete, musí splňovat požadavky na datový typ, který zvolíte. Před nahráním je důležité správně naformátovat data, což zajistí, že služba Speech bude data přesně zpracovávat. Informace o správném formátování dat najdete v tématu Trénování datových typů.
Poznámka:
- Uživatelé s předplatným Standard (S0) můžou současně nahrát pět datových souborů. Pokud dosáhnete limitu, počkejte na dokončení importu alespoň jednoho z datových souborů. Pak to zkuste znovu.
- Maximální počet datových souborů, které je možné importovat na jedno předplatné, je 500 .zip souborů pro uživatele se standardním předplatným (S0). Další podrobnosti najdete v kvótách a omezeních služby Speech.
Nahrání dat
Až budete připraveni nahrát data, přejděte na kartu Příprava trénovacích dat a přidejte první trénovací sadu a nahrajte data. Trénovací sada je sada zvukových promluv a jejich mapovacích skriptů používaných pro trénování hlasového modelu. Trénovací sadu můžete použít k uspořádání trénovacích dat. Služba kontroluje připravenost dat na každou trénovací sadu. Do trénovací sady můžete importovat více dat.
Pokud chcete nahrát trénovací data, postupujte takto:
- Přihlaste se k sadě Speech Studio.
- Vyberte Vlastní hlas>> Název projektu Příprava trénovacích dat Nahrání dat.>
- V Průvodci nahráním dat zvolte datový typ a pak vyberte Další.
- Vyberte místní soubory z počítače nebo zadejte adresu URL úložiště objektů blob v Azure a nahrajte data.
- V části Zadat cílovou trénovací sadu vyberte existující trénovací sadu nebo vytvořte novou. Pokud jste vytvořili novou trénovací sadu, před pokračováním se ujistěte, že je vybraná v rozevíracím seznamu.
- Vyberte Další.
- Zadejte název a popis dat a pak vyberte Další.
- Zkontrolujte podrobnosti o nahrávání a vyberte Odeslat.
Poznámka:
Duplicitní ID nejsou přijata. Promluvy se stejným ID se odeberou.
Z trénování se odeberou duplicitní názvy zvuku. Ujistěte se, že data, která vyberete, neobsahují stejné zvukové názvy v souboru .zip nebo ve více .zip souborech. Pokud jsou ID promluvy (ve zvukových nebo skriptových souborech) duplicitní, budou odmítnuty.
Datové soubory se automaticky ověří, když vyberete Odeslat. Ověření dat zahrnuje řadu kontrol zvukových souborů za účelem ověření jejich formátu, velikosti a vzorkovací frekvence. Pokud dojde k nějakým chybám, opravte je a odešlete je znovu.
Po nahrání dat můžete zkontrolovat podrobnosti v zobrazení podrobností trénovací sady. Na stránce podrobností můžete dále zkontrolovat problém výslovnosti a úroveň šumu pro každou z vašich dat. Skóre výslovnosti na úrovni věty se pohybuje od 0 do 100. Skóre nižší než 70 obvykle značí neshodu řeči nebo skriptu. Promluvy s celkovým skóre nižším než 70 budou odmítnuty. Silné zvýraznění může snížit skóre výslovnosti a ovlivnit vygenerovaný digitální hlas.
Řešení problémů s daty online
Po nahrání můžete zkontrolovat podrobnosti o datech trénovací sady. Než budete pokračovat v trénování hlasového modelu, měli byste se pokusit vyřešit všechny problémy s daty.
Problémy s daty můžete identifikovat a vyřešit v sadě Speech Studio.
Na stránce podrobností přejděte na přijatou nebo odmítnutou datovou stránku. Vyberte jednotlivé promluvy, které chcete změnit, a pak vyberte Upravit.
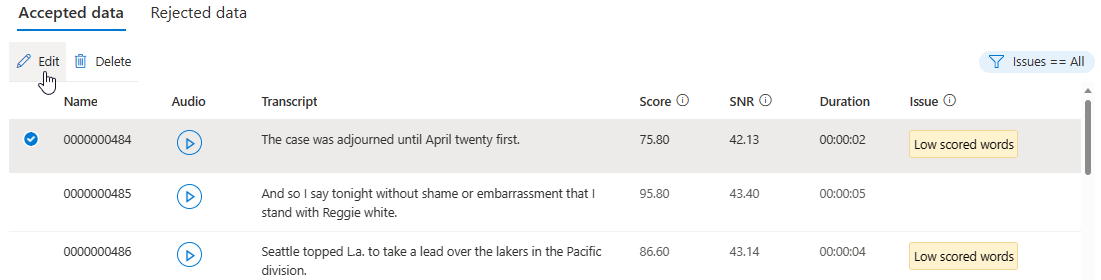
Na základě vašich kritérií můžete zvolit, které problémy s daty se mají zobrazit.
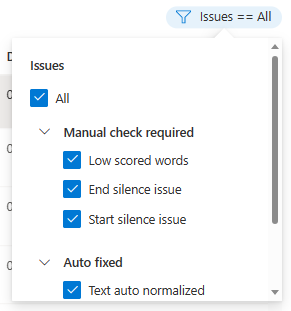
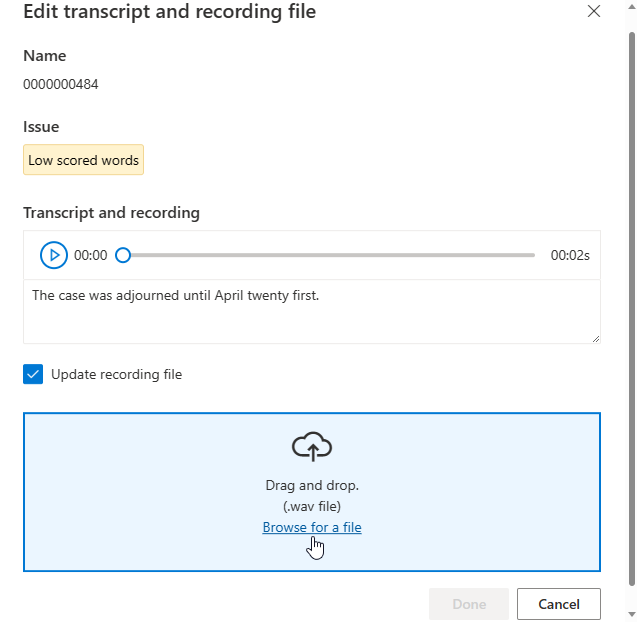
Zobrazí se okno pro úpravy.
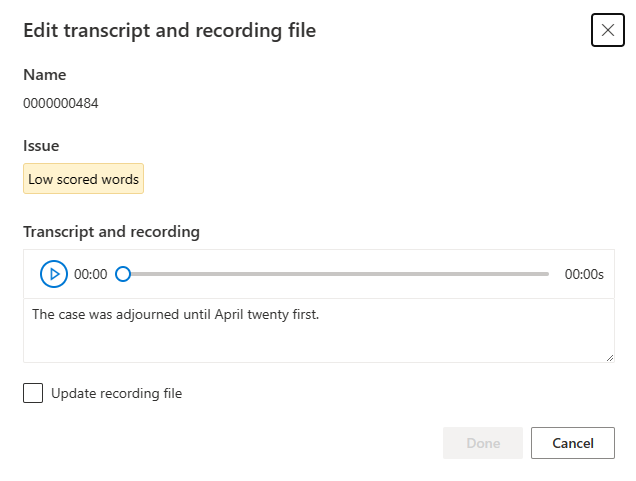
Aktualizujte soubor přepisu nebo záznamu podle popisu problému v okně pro úpravy.
Přepis můžete upravit v textovém poli a pak vybrat Hotovo.
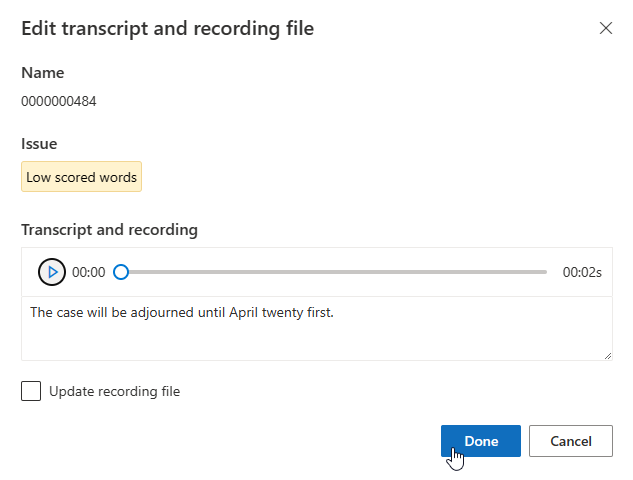
Pokud potřebujete aktualizovat soubor záznamu, vyberte Aktualizovat záznamový soubor a pak nahrajte pevný záznamový soubor (.wav).
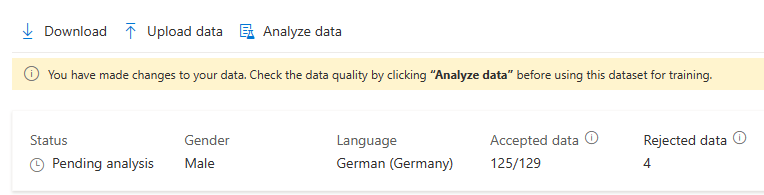
Po provedení změn dat je potřeba zkontrolovat kvalitu dat kliknutím na Analyzovat data před použitím této datové sady pro trénování.
Tuto trénovací sadu pro trénovací model nemůžete vybrat před dokončením analýzy.
Promluvy s problémy můžete odstranit také tak, že je vyberete a kliknete na Odstranit.
Typické problémy s daty
Tyto problémy jsou rozdělené do tří typů. Informace o odpovídajících typech chyb najdete v následujících tabulkách.
Automaticky odmítnuto
Data s těmito chybami nebudou použita pro trénování. Importovaná data s chybami budou ignorována, takže je nemusíte odstraňovat. Tyto chyby dat můžete opravit online nebo znovu nahrát opravená data pro trénování.
| Kategorie | Název | Popis |
|---|---|---|
| Skript | Neplatný oddělovač | ID promluvy a obsah skriptu musíte oddělit znakem tabulátoru. |
| Skript | Neplatné ID skriptu | ID řádku skriptu musí být číselné. |
| Skript | Duplikovaný skript | Každý řádek obsahu skriptu musí být jedinečný. Řádek je duplikován s {}. |
| Skript | Skript je příliš dlouhý | Skript musí být kratší než 1 000 znaků. |
| Skript | Žádný odpovídající zvuk | ID každé promluvy (každý řádek souboru skriptu) musí odpovídat ID zvuku. |
| Skript | Žádný platný skript | V této datové sadě nebyl nalezen žádný platný skript. Opravte řádky skriptu, které se zobrazují v seznamu podrobných problémů. |
| Zvuk | Žádný odpovídající skript | Žádné zvukové soubory neodpovídají ID skriptu. Název souborů .wav se musí shodovat s ID v souboru skriptu. |
| Zvuk | Neplatný formát zvuku | Formát zvuku .wav souborů je neplatný. Pomocí zvukového nástroje, jako je SoX, zkontrolujte formát .wav souboru. |
| Zvuk | Nízká vzorkovací frekvence | Vzorkovací frekvence souborů .wav nemůže být nižší než 16 KHz. |
| Zvuk | Příliš dlouhý zvuk | Doba trvání zvuku je delší než 30 sekund. Rozdělte dlouhý zvuk na několik souborů. Je vhodné, aby promluvy byly kratší než 15 sekund. |
| Zvuk | Žádný platný zvuk | V této datové sadě není nalezen žádný platný zvuk. Zkontrolujte zvuková data a nahrajte je znovu. |
| Neshoda | Výrok s nízkým skóre | Skóre výslovnosti na úrovni vět je nižší než 70. Zkontrolujte skript a zvukový obsah a ujistěte se, že odpovídají. |
Automaticky opraveno
Následující chyby jsou opraveny automaticky, ale měli byste zkontrolovat a ověřit, že jsou opravy provedeny správně.
| Kategorie | Název | Popis |
|---|---|---|
| Neshoda | Automatické pevného ticha | Počáteční ticho je zjištěno, že je kratší než 100 ms a bylo rozšířeno na 100 ms automaticky. Stáhněte si normalizovanou datovou sadu a zkontrolujte ji. |
| Neshoda | Automatické pevného ticha | Koncové ticho je zjištěno, že je kratší než 100 ms a bylo rozšířeno na 100 ms automaticky. Stáhněte si normalizovanou datovou sadu a zkontrolujte ji. |
| Skript | Automaticky normalizované texty | Text se automaticky normalizuje pro číslice, symboly a zkratky. Zkontrolujte skript a zvuk a ujistěte se, že odpovídají. |
Vyžaduje se ruční kontrola
Nevyřešené chyby uvedené v další tabulce ovlivňují kvalitu trénování, ale během trénování nebudou vyloučena data s těmito chybami. Pro vyšší kvalitu trénování je vhodné tyto chyby opravit ručně.
| Kategorie | Název | Popis |
|---|---|---|
| Skript | Nenormalizovaný text | Tento skript obsahuje symboly. Normalizuje symboly tak, aby odpovídaly zvuku. Můžete například normalizovat / lomítko. |
| Skript | Nedostatek otázek promluv | Alespoň 10 procent z celkového počtu promluv by mělo být věty otázek. To pomáhá hlasovým modelům správně vyjádřit dotazovací tón. |
| Skript | Nedostatek vykřičníků promluv | Alespoň 10 procent z celkového počtu promluv by mělo být vykřičník. Díky tomu hlasový model správně vyjadřuje nadšený tón. |
| Skript | Žádná platná interpunkce | Na konec řádku přidejte jednu z následujících položek: úplnou zarážku (poloviční šířku "." nebo plnou šířku '。 ), vykřičník (poloviční šířka '!' nebo plná šířka '!' ) nebo otazník ( poloviční šířka '?' nebo plná šířka '?'). |
| Zvuk | Nízká vzorkovací frekvence neurálního hlasu | Doporučuje se, aby vzorkovací frekvence vašich .wav souborů měla být 24 KHz nebo vyšší pro vytváření neurálních hlasů. Pokud je nižší, automaticky se zvýší na 24 KHz. |
| Objem | Celkový objem je příliš nízký. | Objem by neměl být nižší než -18 dB (10 procent maximálního objemu). Při přípravě vzorku nebo přípravy dat můžete řídit úroveň průměru hlasitosti ve správném rozsahu. |
| Objem | Přetečení svazku | Objem přetečení se zjistí na s {}. Upravte nahrávací zařízení tak, aby se zabránilo přetečení hlasitosti ve špičce. |
| Objem | Zahájit problém s tichou | Prvních 100 ms ticha není čisté. Snižte úroveň hluku záznamu a nechte prvních 100 ms na začátku tiché. |
| Objem | Ukončit problém s tichou | Posledních 100 ms ticha není čisté. Snižte úroveň hluku záznamu a nechte posledních 100 ms na konci tiché. |
| Neshoda | Slabá slova s nízkým skóre | Zkontrolujte skript a zvukový obsah, abyste měli jistotu, že odpovídají, a nastavte úroveň hluku. Zmenšete délku dlouhého ticha nebo rozdělte zvuk na několik promluv, pokud je příliš dlouhý. |
| Neshoda | Zahájit problém s tichou | Před prvním slovem bylo slyšet další zvuk. Zkontrolujte skript a zvukový obsah, abyste měli jistotu, že odpovídají, řídí úroveň hluku a ztište prvních 100 ms. |
| Neshoda | Ukončit problém s tichou | Po posledním slově bylo slyšet další zvuk. Zkontrolujte skript a zvukový obsah, abyste měli jistotu, že odpovídají, řídí úroveň hluku a ztiší posledních 100 ms. |
| Neshoda | Nízký poměr šumu signálu | Úroveň SNR zvuku je nižší než 20 dB. Doporučuje se alespoň 35 dB. |
| Neshoda | Není k dispozici žádné skóre. | Nepovedlo se rozpoznat obsah řeči v tomto zvuku. Zkontrolujte zvuk a obsah skriptu a ujistěte se, že je zvuk platný a odpovídá skriptu. |
Další kroky
K vytvoření profesionálního hlasu potřebujete trénovací datovou sadu. Trénovací datová sada obsahuje zvukové soubory a soubory skriptů. Zvukové soubory jsou nahrávky hlasového talentu čtení skriptových souborů. Soubory skriptu jsou textem zvukových souborů.
V tomto článku vytvoříte trénovací sadu a získáte JEJÍ ID prostředku. Potom pomocí ID prostředku můžete nahrát sadu zvukových souborů a souborů skriptů.
Vytvoření trénovací sady
K vytvoření trénovací sady použijte TrainingSets_Create operaci vlastního hlasového rozhraní API. Sestavte tělo požadavku podle následujících pokynů:
- Nastavte požadovanou
projectIdvlastnost. Viz vytvoření projektu. - Nastavte požadovanou
voiceKindvlastnost naMalehodnotu neboFemale. Druh nelze později změnit. - Nastavte požadovanou
localevlastnost. Toto by mělo být národní prostředí dat trénovací sady. Národní prostředí trénovací sady by mělo být stejné jako národní prostředí prohlášení o souhlasu. Národní prostředí nelze později změnit. Text na seznam národních prostředí řeči najdete tady. - Volitelně můžete nastavit
descriptionvlastnost popisu trénovací sady. Popis trénovací sady lze později změnit.
Vytvořte požadavek HTTP PUT pomocí identifikátoru URI, jak je znázorněno v následujícím příkladu TrainingSets_Create.
- Nahraďte
YourResourceKeyklíčem prostředku služby Speech. - Nahraďte
YourResourceRegionoblastí prostředků služby Speech. - Nahraďte
JessicaTrainingSetIdID trénovací sady podle vašeho výběru. V identifikátoru URI trénovací sady se použije citlivé ID malých a malých písmen a později ho nejde změnit.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2024-02-01-preview"
Měl by se zobrazit text odpovědi v následujícím formátu:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Nahrání dat trénovací sady
K nahrání trénovací sady zvuků a skriptů použijte TrainingSets_UploadData operaci vlastního hlasového rozhraní API.
Před voláním tohoto rozhraní API uložte soubory záznamů a skriptů do azure Blob. V následujícím příkladu jsou https://contoso.blob.core.windows.net/voicecontainer/jessica300/soubory záznamů *.wav, soubory skriptu jsou https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt.
Sestavte tělo požadavku podle následujících pokynů:
- Nastavte požadovanou
kindvlastnost naAudioAndScripthodnotu . Druh určuje typ trénovací sady. - Nastavte požadovanou
audiosvlastnost. V rámciaudiosvlastnosti nastavte následující vlastnosti:- Nastavte požadovanou
containerUrlvlastnost na adresu URL kontejneru Azure Blob Storage, který obsahuje zvukové soubory. Pro kontejner s oprávněními ke čtení i seznamu použijte sdílené přístupové podpisy (SAS). - Nastavte požadovanou
extensionsvlastnost na rozšíření zvukových souborů. - Volitelně můžete nastavit vlastnost tak,
prefixaby nastavil předponu názvu objektu blob.
- Nastavte požadovanou
- Nastavte požadovanou
scriptsvlastnost. V rámciscriptsvlastnosti nastavte následující vlastnosti:- Nastavte požadovanou
containerUrlvlastnost na adresu URL kontejneru Azure Blob Storage, který obsahuje soubory skriptu. Pro kontejner s oprávněními ke čtení i seznamu použijte sdílené přístupové podpisy (SAS). - Nastavte požadovanou
extensionsvlastnost na přípony souborů skriptu. - Volitelně můžete nastavit vlastnost tak,
prefixaby nastavil předponu názvu objektu blob.
- Nastavte požadovanou
Vytvořte požadavek HTTP POST pomocí identifikátoru URI, jak je znázorněno v následujícím příkladu TrainingSets_UploadData.
- Nahraďte
YourResourceKeyklíčem prostředku služby Speech. - Nahraďte
YourResourceRegionoblastí prostředků služby Speech. - Nahraďte
JessicaTrainingSetId, pokud jste v předchozím kroku zadali jiné ID trénovací sady.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2024-02-01-preview"
Hlavička odpovědi obsahuje Operation-Location vlastnost. Pomocí tohoto identifikátoru URI získáte podrobnosti o operaci TrainingSets_UploadData . Tady je příklad hlavičky odpovědi:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2024-02-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345