Trénování vlastního modelu řeči
V tomto článku se dozvíte, jak vytrénovat vlastní model, aby se zlepšila přesnost rozpoznávání ze základního modelu Microsoftu. Přesnost rozpoznávání řeči a kvalita vlastního modelu řeči zůstává konzistentní, i když se uvolní nový základní model.
Poznámka:
Platíte za využití vlastního modelu řeči a hostování koncových bodů. Pokud byl základní model vytvořen 1. října 2023 a novější, bude se vám účtovat také trénování vlastního modelu řeči. Pokud byl základní model vytvořen před říjnem 2023, neúčtují se vám poplatky za trénování. Další informace najdete v tématu Ceny služby Azure AI Speech a část Poplatky za přizpůsobení v průvodci migrací převodu řeči na text 3.2.
Trénování modelu je obvykle iterativní proces. Nejprve vyberete základní model, který je výchozím bodem nového modelu. Model vytrénujete pomocí datových sad, které můžou obsahovat text a zvuk, a pak otestujete. Pokud kvalita nebo přesnost rozpoznávání nevyhovuje vašim požadavkům, můžete vytvořit nový model s více nebo upravenými trénovacími daty a pak to znovu otestovat.
Po vytrénování můžete použít vlastní model po omezenou dobu. Abyste mohli využívat lepší přesnost a kvalitu, musíte pravidelně znovu vytvářet a přizpůsobovat vlastní model z nejnovějšího základního modelu. Další informace najdete v tématu Životní cyklus modelu a koncového bodu.
Důležité
Pokud budete trénovat vlastní model se zvukovými daty, zvolte prostředek AI Services pro oblast služby Speech s vyhrazeným hardwarem pro trénování zvukových dat. Po vytrénování modelu ho můžete podle potřeby zkopírovat do prostředku služby AI Services pro službu Speech v jiné oblasti.
V oblastech s vyhrazeným hardwarem pro trénování vlastní řeči bude služba Speech používat až 100 hodin trénovacích dat zvuku a může zpracovávat přibližně 10 hodin dat za den. Další informace najdete v tabulce poznámek pod čarou v tabulce oblastí .
Vytvořit model
Po nahrání trénovacích datových sad spusťte trénování modelu podle těchto pokynů:
Přihlaste se k sadě Speech Studio.
Vyberte Custom speech> Your project name >Train custom models.
Vyberte Trénovat nový model.
Na stránce Vybrat základní model vyberte základní model a pak vyberte Další. Pokud si nejste jistí, vyberte v horní části seznamu nejnovější model. Název základního modelu odpovídá datu, kdy byl vydán ve formátu RRRRMMDD. Možnosti přizpůsobení základního modelu jsou uvedeny v závorkách za názvem modelu v sadě Speech Studio.
Důležité
Poznamenejte si datum přizpůsobení vypršení platnosti . Toto je poslední datum, ke kterému můžete použít základní model pro trénování. Další informace najdete v tématu Životní cyklus modelu a koncového bodu.
Na stránce Zvolit data vyberte jednu nebo více datových sad, které chcete použít pro trénování. Pokud nejsou dostupné žádné datové sady, zrušte nastavení a pak přejděte do nabídky datových sad služby Speech a nahrajte datové sady.
Zadejte název a popis vlastního modelu a pak vyberte Další.
Volitelně zaškrtněte políčko Přidat test v dalším kroku . Pokud tento krok přeskočíte, můžete později spustit stejné testy. Další informace naleznete v tématu Kvalita rozpoznávání testů a model testování kvantitativní.
Výběrem možnosti Uložit a zavřít spustíte sestavení vlastního modelu.
Vraťte se na stránku Trénovat vlastní modely .
Důležité
Poznamenejte si datum vypršení platnosti . Toto je poslední datum, kdy můžete pro rozpoznávání řeči použít vlastní model. Další informace najdete v tématu Životní cyklus modelu a koncového bodu.
K vytvoření modelu s datovými sadami pro trénování použijte spx csr model create příkaz. Parametry požadavku se sestaví podle následujících pokynů:
-
projectNastavte parametr na ID existujícího projektu. Tento parametr se doporučuje, abyste mohli model také zobrazit a spravovat v nástroji Speech Studio. Spuštěnímspx csr project listpříkazu můžete získat dostupné projekty. - Nastavte požadovaný
datasetparametr na ID datové sady, kterou chcete použít pro trénování. Pokud chcete zadat více datových sad, nastavtedatasetsparametr (množné číslo) a oddělte ID středníkem. - Nastavte požadovaný
languageparametr. Národní prostředí datové sady musí odpovídat národnímu prostředí projektu. Národní prostředí nelze později změnit. Parametr Rozhraní příkazovéholocaleřádkulanguageslužby Speech odpovídá vlastnosti v požadavku JSON a odpovědi. - Nastavte požadovaný
nameparametr. Tento parametr je název zobrazený v sadě Speech Studio. Parametr Rozhraní příkazovéhodisplayNameřádkunameslužby Speech odpovídá vlastnosti v požadavku JSON a odpovědi. - Volitelně můžete vlastnost nastavit
base. Například:--base 5988d691-0893-472c-851e-8e36a0fe7aaf. Pokud tuto možnost nezadátebase, použije se výchozí základní model národního prostředí. Parametr Rozhraní příkazovéhobaseModelřádkubaseslužby Speech odpovídá vlastnosti v požadavku JSON a odpovědi.
Tady je příklad příkazu Rozhraní příkazového řádku služby Speech, který vytvoří model s datovými sadami pro trénování:
spx csr model create --api-version v3.2 --project YourProjectId --name "My Model" --description "My Model Description" --dataset YourDatasetId --language "en-US"
Poznámka:
V tomto příkladu base není nastavená, takže se použije výchozí základní model národního prostředí. Identifikátor URI základního modelu se vrátí v odpovědi.
Měl by se zobrazit text odpovědi v následujícím formátu:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd:copy",
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"deprecationDates": {
"transcriptionDateTime": "2026-07-15T00:00:00Z"
},
"customModelWeightPercent": 30,
"features": {
"supportsTranscriptions": true,
"supportsEndpoints": true,
"supportsTranscriptionsOnSpeechContainers": false,
"supportedOutputFormats": [
"Display",
"Lexical"
]
}
},
"lastActionDateTime": "2024-07-14T21:38:40Z",
"status": "Running",
"createdDateTime": "2024-07-14T21:38:40Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Důležité
Poznamenejte si datum ve adaptationDateTime vlastnosti. Toto je poslední datum, ke kterému můžete použít základní model pro trénování. Další informace najdete v tématu Životní cyklus modelu a koncového bodu.
Poznamenejte si datum ve transcriptionDateTime vlastnosti. Toto je poslední datum, kdy můžete pro rozpoznávání řeči použít vlastní model. Další informace najdete v tématu Životní cyklus modelu a koncového bodu.
Vlastnost nejvyšší úrovně self v těle odpovědi je identifikátor URI modelu. Pomocí tohoto identifikátoru URI získáte podrobnosti o datech ukončení projektu, manifestu a vyřazení modelu. Tento identifikátor URI slouží také k aktualizaci nebo odstranění modelu.
V případě nápovědy k rozhraní příkazového řádku služby Speech s modely spusťte následující příkaz:
spx help csr model
Pokud chcete vytvořit model s datovými sadami pro trénování, použijte Models_Create operaci Rozhraní REST API pro převod řeči na text. Sestavte tělo požadavku podle následujících pokynů:
-
projectNastavte vlastnost na identifikátor URI existujícího projektu. Tato vlastnost se doporučuje, abyste mohli model také zobrazit a spravovat v nástroji Speech Studio. Můžete vytvořit Projects_List žádost o získání dostupných projektů. - Nastavte požadovanou
datasetsvlastnost na identifikátor URI datových sad, které chcete použít pro trénování. - Nastavte požadovanou
localevlastnost. Národní prostředí modelu musí odpovídat národnímu prostředí projektu a základnímu modelu. Národní prostředí nelze později změnit. - Nastavte požadovanou
displayNamevlastnost. Tato vlastnost je název zobrazený v sadě Speech Studio. - Volitelně můžete vlastnost nastavit
baseModel. Například:"baseModel": {"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"}. Pokud tuto možnost nezadátebaseModel, použije se výchozí základní model národního prostředí.
Vytvořte požadavek HTTP POST pomocí identifikátoru URI, jak je znázorněno v následujícím příkladu. Nahraďte YourSubscriptionKey klíčem prostředku služby Speech, nahraďte YourServiceRegion oblastí prostředků služby Speech a nastavte vlastnosti textu požadavku, jak jsme popsali dříve.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Model",
"description": "My Model Description",
"baseModel": null,
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models"
Poznámka:
V tomto příkladu baseModel není nastavená, takže se použije výchozí základní model národního prostředí. Identifikátor URI základního modelu se vrátí v odpovědi.
Měl by se zobrazit text odpovědi v následujícím formátu:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd:copy",
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"deprecationDates": {
"transcriptionDateTime": "2026-07-15T00:00:00Z"
},
"customModelWeightPercent": 30,
"features": {
"supportsTranscriptions": true,
"supportsEndpoints": true,
"supportsTranscriptionsOnSpeechContainers": false,
"supportedOutputFormats": [
"Display",
"Lexical"
]
}
},
"lastActionDateTime": "2024-07-14T21:38:40Z",
"status": "Running",
"createdDateTime": "2024-07-14T21:38:40Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Důležité
Poznamenejte si datum ve adaptationDateTime vlastnosti. Toto je poslední datum, ke kterému můžete použít základní model pro trénování. Další informace najdete v tématu Životní cyklus modelu a koncového bodu.
Poznamenejte si datum ve transcriptionDateTime vlastnosti. Toto je poslední datum, kdy můžete pro rozpoznávání řeči použít vlastní model. Další informace najdete v tématu Životní cyklus modelu a koncového bodu.
Vlastnost nejvyšší úrovně self v těle odpovědi je identifikátor URI modelu. Pomocí tohoto identifikátoru URI získáte podrobnosti o datech ukončení projektu, manifestu a vyřazení modelu. Tento identifikátor URI také použijete k aktualizaci nebo odstranění modelu.
Kopírování modelu
Model můžete zkopírovat do jiného projektu, který používá stejné národní prostředí. Když je například model vytrénovaný pomocí zvukových dat v oblasti s vyhrazeným hardwarem pro trénování, můžete ho podle potřeby zkopírovat do prostředku služby AI Services pro službu Speech v jiné oblasti.
Podle těchto pokynů zkopírujte model do projektu v jiné oblasti:
- Přihlaste se k sadě Speech Studio.
- Vyberte Custom speech> Your project name >Train custom models.
- Vyberte Kopírovat do.
-
Na stránce Kopírovat model řeči vyberte cílovou oblast, do které chcete model zkopírovat.

- Vyberte prostředek služby AI Services pro službu Speech v cílové oblasti nebo vytvořte nový prostředek služby Speech.
- Vyberte projekt, do kterého chcete model zkopírovat, nebo vytvořte nový projekt.
- Vyberte Kopírovat.

Po úspěšném zkopírování modelu budete upozorněni a můžete ho zobrazit v cílovém projektu.
Kopírování modelu přímo do projektu v jiné oblasti se v rozhraní příkazového řádku služby Speech nepodporuje. Model můžete zkopírovat do projektu v jiné oblasti pomocí sady Speech Studio nebo rozhraní SPEECH na textové rozhraní REST API.
Pokud chcete zkopírovat model do jiného prostředku služby Speech, použijte operaci Models_Copy rozhraní REST API pro převod řeči na text. Sestavte tělo požadavku podle následujících pokynů:
- Nastavte požadovanou
targetSubscriptionKeyvlastnost na klíč cílového prostředku služby Speech.
Vytvořte požadavek HTTP POST pomocí identifikátoru URI, jak je znázorněno v následujícím příkladu. Použijte oblast a identifikátor URI modelu, ze kterého chcete kopírovat. Nahraďte YourModelId ID modelu, nahraďte YourSubscriptionKey klíčem prostředku služby Speech, nahraďte YourServiceRegion oblastí prostředků služby Speech a nastavte vlastnosti textu požadavku, jak je popsáno výše.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"targetSubscriptionKey": "ModelDestinationSpeechResourceKey"
} ' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models/YourModelId:copy"
Poznámka:
targetSubscriptionKey Informace o cílovém prostředku služby Speech má pouze vlastnost v textu požadavku.
Měl by se zobrazit text odpovědi v následujícím formátu:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/eb5450a7-3ca2-461a-b2d7-ddbb3ad96540"
},
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae:copy"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-22T23:15:27Z",
"status": "NotStarted",
"createdDateTime": "2022-05-22T23:15:27Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description",
"customProperties": {
"PortalAPIVersion": "3",
"Purpose": "",
"VadKind": "None",
"ModelClass": "None",
"UsesHalide": "False",
"IsDynamicGrammarSupported": "False"
}
}
Připojení modelu
Modely se můžou zkopírovat z jednoho projektu pomocí rozhraní příkazového řádku služby Speech nebo rozhraní REST API, aniž by se připojily k jinému projektu. Propojení modelu je otázkou aktualizace modelu s odkazem na projekt.
Pokud se zobrazí výzva v sadě Speech Studio, můžete je připojit výběrem tlačítka Připojit .
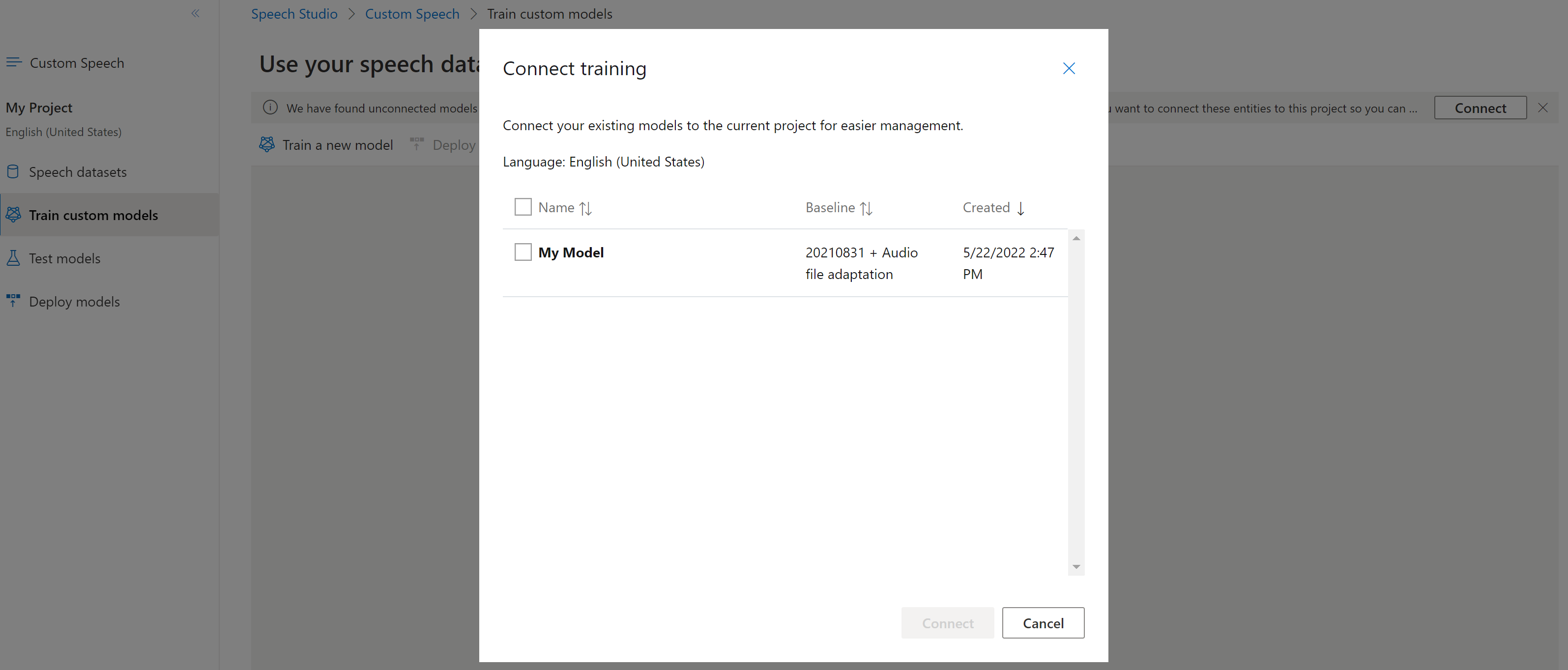
K připojení modelu k projektu použijte spx csr model update příkaz. Parametry požadavku se sestaví podle následujících pokynů:
-
projectNastavte parametr na identifikátor URI existujícího projektu. Tento parametr se doporučuje, abyste mohli model také zobrazit a spravovat v nástroji Speech Studio. Spuštěnímspx csr project listpříkazu můžete získat dostupné projekty. - Nastavte požadovaný
modelIdparametr na ID modelu, který chcete připojit k projektu.
Tady je příklad příkazu Rozhraní příkazového řádku služby Speech, který připojí model k projektu:
spx csr model update --api-version v3.2 --model YourModelId --project YourProjectId
Měl by se zobrazit text odpovědi v následujícím formátu:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}
V případě nápovědy k rozhraní příkazového řádku služby Speech s modely spusťte následující příkaz:
spx help csr model
Pokud chcete připojit nový model k projektu prostředku služby Speech, ve kterém se model zkopíroval, použijte Models_Update operaci rozhraní SPEECH pro textové rozhraní REST API. Sestavte tělo požadavku podle následujících pokynů:
- Nastavte požadovanou
projectvlastnost na identifikátor URI existujícího projektu. Tato vlastnost se doporučuje, abyste mohli model také zobrazit a spravovat v nástroji Speech Studio. Můžete vytvořit Projects_List žádost o získání dostupných projektů.
Vytvořte požadavek HTTP PATCH pomocí identifikátoru URI, jak je znázorněno v následujícím příkladu. Použijte identifikátor URI nového modelu. Nové ID modelu můžete získat z self vlastnosti textu odpovědi Models_Copy . Nahraďte YourSubscriptionKey klíčem prostředku služby Speech, nahraďte YourServiceRegion oblastí prostředků služby Speech a nastavte vlastnosti textu požadavku, jak jsme popsali dříve.
curl -v -X PATCH -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models"
Měl by se zobrazit text odpovědi v následujícím formátu:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}