Rychlý start: Rozpoznávání záměrů pomocí konverzačního jazyka Understanding
Referenční dokumentace | Package (NuGet) | Další ukázky na GitHubu
V tomto rychlém startu použijete služby Speech a Language k rozpoznávání záměrů ze zvukových dat zachycených z mikrofonu. Konkrétně použijete službu Speech k rozpoznávání řeči a modelu CLU (Conversational Language Understanding) k identifikaci záměrů.
Důležité
Konverzační language Understanding (CLU) je k dispozici pro C# a C++ se sadou Speech SDK verze 1.25 nebo novější.
Požadavky
- Předplatné Azure. Můžete si ho zdarma vytvořit.
- Na webu Azure Portal vytvořte prostředek jazyka.
- Získejte klíč prostředku jazyka a koncový bod. Po nasazení prostředku jazyka vyberte Přejít k prostředku a zobrazte a spravujte klíče.
- Na webu Azure Portal vytvořte prostředek služby AI Services pro službu Speech .
- Získejte klíč prostředku a oblast služby Speech. Po nasazení prostředku služby Speech vyberte Přejít k prostředku a zobrazte a spravujte klíče.
Nastavení prostředí
Sada Speech SDK je k dispozici jako balíček NuGet a implementuje .NET Standard 2.0. Sadu Speech SDK nainstalujete později v této příručce, ale nejprve si projděte průvodce instalací sady SDK, kde najdete další požadavky.
Nastavení proměnných prostředí
Tento příklad vyžaduje proměnné prostředí s názvem LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEYa SPEECH_REGION.
Aby vaše aplikace získala přístup k prostředkům služeb Azure AI, musí být ověřená. V tomto článku se dozvíte, jak pomocí proměnných prostředí ukládat přihlašovací údaje. Pak můžete přistupovat k proměnným prostředí z kódu, abyste aplikaci ověřili. V produkčním prostředí použijte bezpečnější způsob, jak ukládat přihlašovací údaje a přistupovat k němu.
Důležité
Doporučujeme ověřování Microsoft Entra ID se spravovanými identitami pro prostředky Azure, abyste se vyhnuli ukládání přihlašovacích údajů s aplikacemi, které běží v cloudu.
Používejte klíče rozhraní API s opatrností. Nezahrnujte klíč rozhraní API přímo do kódu a nikdy ho nevštěvujte veřejně. Pokud používáte klíče rozhraní API, bezpečně je uložte ve službě Azure Key Vault, pravidelně je obměňujte a omezte přístup ke službě Azure Key Vault pomocí řízení přístupu na základě rolí a omezení přístupu k síti. Další informace o bezpečném používání klíčů ROZHRANÍ API ve vašich aplikacích najdete v tématu Klíče rozhraní API se službou Azure Key Vault.
Další informace o zabezpečení služeb AI najdete v tématu Ověřování požadavků na služby Azure AI.
Pokud chcete nastavit proměnné prostředí, otevřete okno konzoly a postupujte podle pokynů pro operační systém a vývojové prostředí.
- Pokud chcete nastavit proměnnou
LANGUAGE_KEYprostředí, nahraďteyour-language-keyjedním z klíčů pro váš prostředek. - Pokud chcete nastavit proměnnou
LANGUAGE_ENDPOINTprostředí, nahraďteyour-language-endpointjednou z oblastí vašeho prostředku. - Pokud chcete nastavit proměnnou
SPEECH_KEYprostředí, nahraďteyour-speech-keyjedním z klíčů pro váš prostředek. - Pokud chcete nastavit proměnnou
SPEECH_REGIONprostředí, nahraďteyour-speech-regionjednou z oblastí vašeho prostředku.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Poznámka:
Pokud potřebujete získat přístup pouze k proměnné prostředí v aktuální spuštěné konzole, můžete místo toho nastavit proměnnou setsetxprostředí .
Po přidání proměnných prostředí budete možná muset restartovat všechny spuštěné programy, které budou muset přečíst proměnnou prostředí, včetně okna konzoly. Pokud například jako editor používáte Sadu Visual Studio, restartujte sadu Visual Studio před spuštěním příkladu.
Vytvoření projektu Konverzační služby Language Understanding
Jakmile máte vytvořený prostředek jazyka, vytvořte v sadě Language Studio projekt pro porozumění konverzačnímu jazyku. Projekt je pracovní oblast pro vytváření vlastních modelů ML na základě vašich dat. K vašemu projektu má přístup jenom vy a ostatní, kteří mají přístup k používanému prostředku jazyka.
Přejděte do sady Language Studio a přihlaste se pomocí svého účtu Azure.
Vytvoření projektu pro porozumění konverzačnímu jazyku
Pro účely tohoto rychlého startu si můžete stáhnout tento ukázkový projekt domácí automatizace a importovat ho. Tento projekt dokáže předpovědět zamýšlené příkazy ze vstupu uživatele, například zapnutí a vypnutí světel.
V části Vysvětlení otázek a konverzačního jazyka v sadě Language Studio vyberte Porozumění konverzačnímu jazyku.
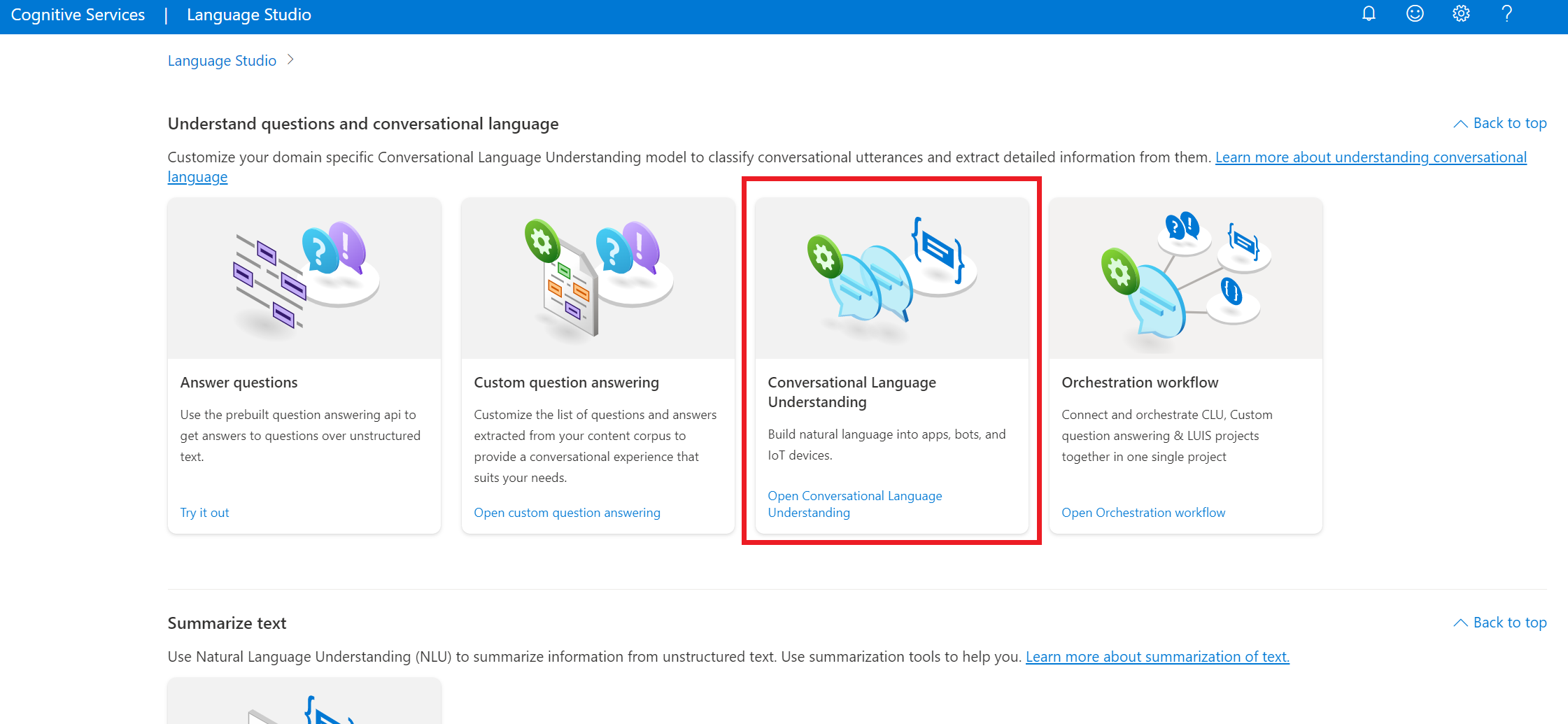
Tím se dostanete na stránku projektů pro porozumění konverzačnímu jazyku. Vedle tlačítka Vytvořit nový projekt vyberte Importovat.
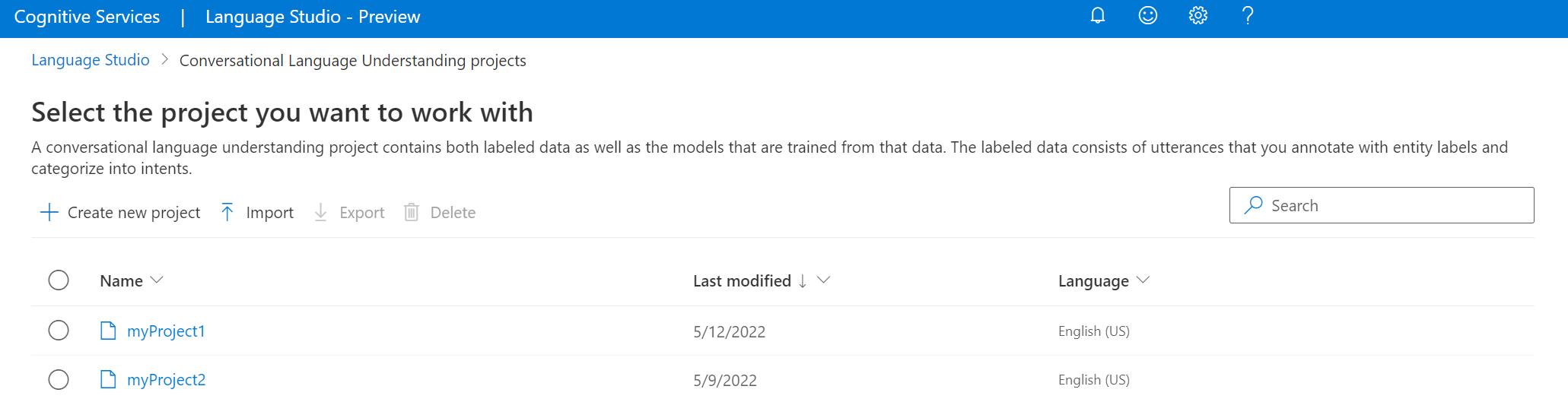
V zobrazeném okně nahrajte soubor JSON, který chcete importovat. Ujistěte se, že váš soubor dodržuje podporovaný formát JSON.


Po dokončení nahrávání se dostanete na stránku definice schématu. Pro účely tohoto rychlého startu je schéma již sestavené a promluvy jsou už označené záměry a entitami.
Trénování vašeho modelu
Obvykle byste po vytvoření projektu měli vytvořit schéma a označovat promluvy. Pro účely tohoto rychlého startu jsme už naimportovali připravený projekt s sestaveným schématem a označenými promluvami.
Pokud chcete vytrénovat model, musíte zahájit trénovací úlohu. Výstupem úspěšné trénovací úlohy je trénovaný model.
Zahájení trénování modelu v sadě Language Studio:
V nabídce na levé straně vyberte Trénovat model .
V horní nabídce vyberte Spustit trénovací úlohu .
Vyberte Vytrénovat nový model a do textového pole zadejte nový název modelu. V opačném případě chcete nahradit existující model modelem natrénovaným na nových datech, vyberte Přepsat existující model a pak vyberte existující model. Přepsání natrénovaného modelu je nevratné, ale nebude mít vliv na nasazené modely, dokud nový model nenasadíte.
Vyberte režim trénování. Pro rychlejší trénování můžete zvolit standardní trénování , ale je k dispozici pouze pro angličtinu. Nebo můžete zvolit rozšířené trénování , které je podporováno pro jiné jazyky a vícejazyčné projekty, ale zahrnuje delší dobu trénování. Přečtěte si další informace o režimech trénování.
Vyberte metodu rozdělení dat. Můžete zvolit automatické rozdělení testovací sady z trénovacích dat , kde systém rozdělí promluvy mezi trénovací a testovací sady podle zadaných procent. Nebo můžete použít ruční rozdělení trénovacích a testovacích dat, tato možnost je povolená jenom v případě, že jste do testovací sady přidali promluvy při označování promluv.
Vyberte tlačítko Trénovat.
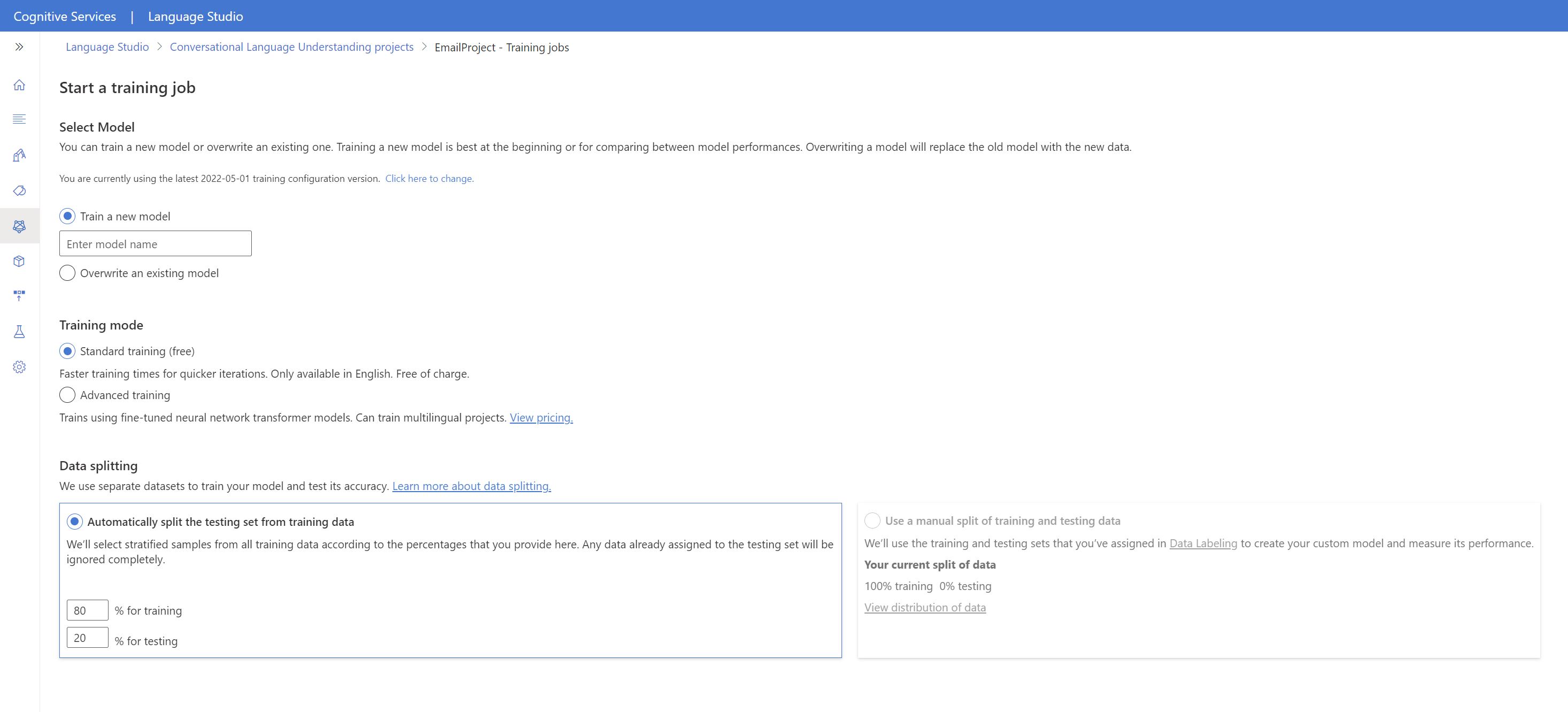
V seznamu vyberte ID trénovací úlohy. Zobrazí se panel, kde můžete zkontrolovat průběh trénování, stav úlohy a další podrobnosti o této úloze.
Poznámka:
- Pouze úspěšně dokončené trénovací úlohy vygenerují modely.
- Trénování může nějakou dobu trvat několik minut až několik hodin na základě počtu promluv.
- Najednou můžete mít spuštěnou pouze jednu úlohu trénování. Do dokončení spuštěné úlohy nemůžete spustit jiné trénovací úlohy v rámci stejného projektu.
- Strojové učení používané k trénování modelů se pravidelně aktualizuje. Pokud chcete vytrénovat předchozí verzi konfigurace, vyberte Možnost Vybrat, pokud chcete změnit stránku Spustit trénovací úlohu a zvolte předchozí verzi.

Nasazení modelu
Obecně platí, že po trénování modelu byste zkontrolovali jeho podrobnosti o vyhodnocení. V tomto rychlém startu jednoduše nasadíte model a zpřístupníte ho pro vyzkoušení v sadě Language Studio nebo můžete volat rozhraní API pro predikce.
Nasazení modelu v sadě Language Studio:
V nabídce na levé straně vyberte Nasazení modelu .
Výběrem možnosti Přidat nasazení spusťte Průvodce přidáním nasazení .
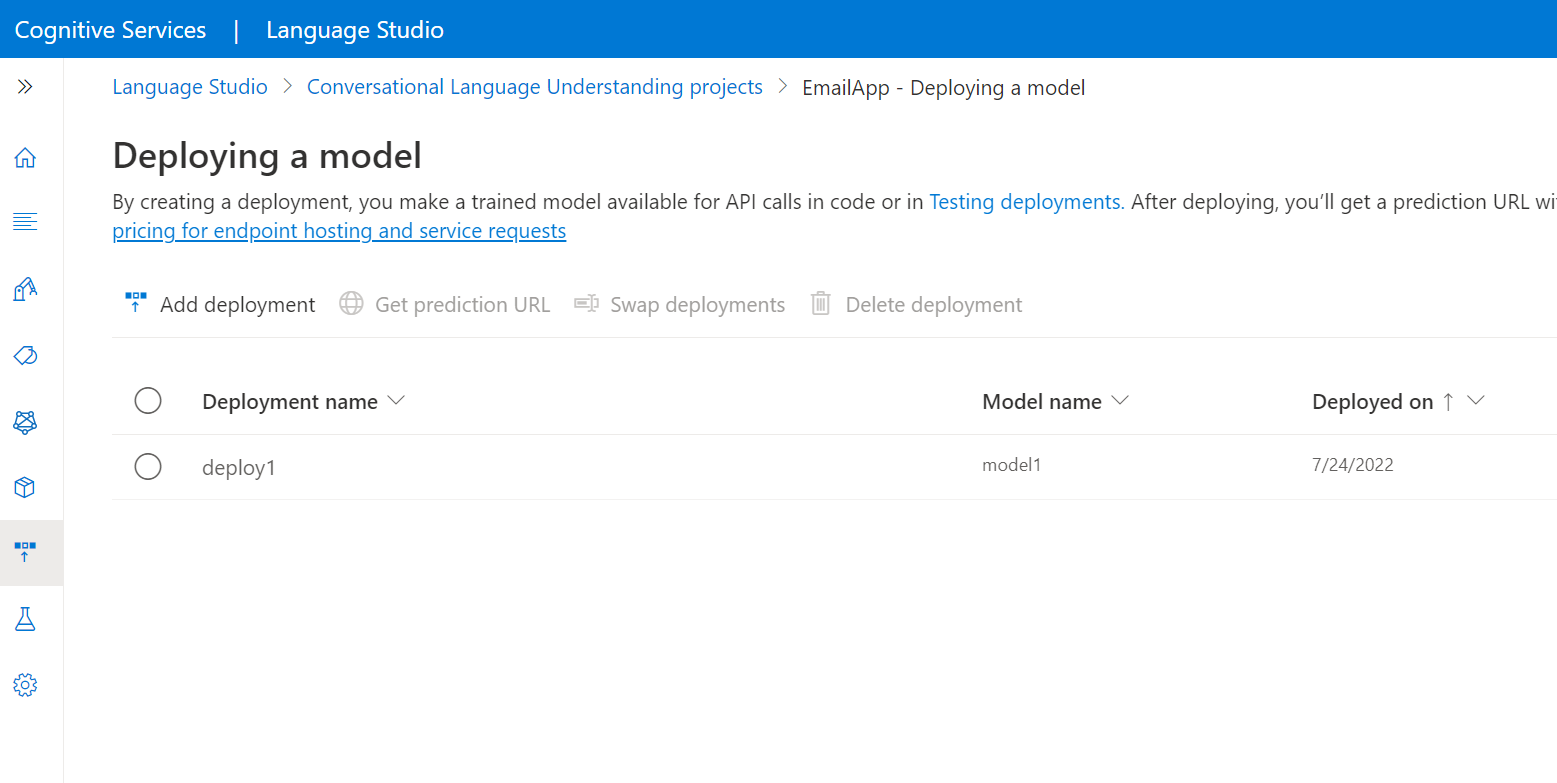
Výběrem možnosti Vytvořit nový název nasazení vytvořte nové nasazení a v rozevíracím seznamu níže přiřaďte natrénovaný model. Pokud chcete efektivně nahradit model používaný existujícím nasazením, můžete jinak vybrat možnost Přepsat existující název nasazení.
Poznámka:
Přepsání existujícího nasazení nevyžaduje změny volání rozhraní API pro predikce, ale výsledky, které získáte, budou založené na nově přiřazeného modelu.
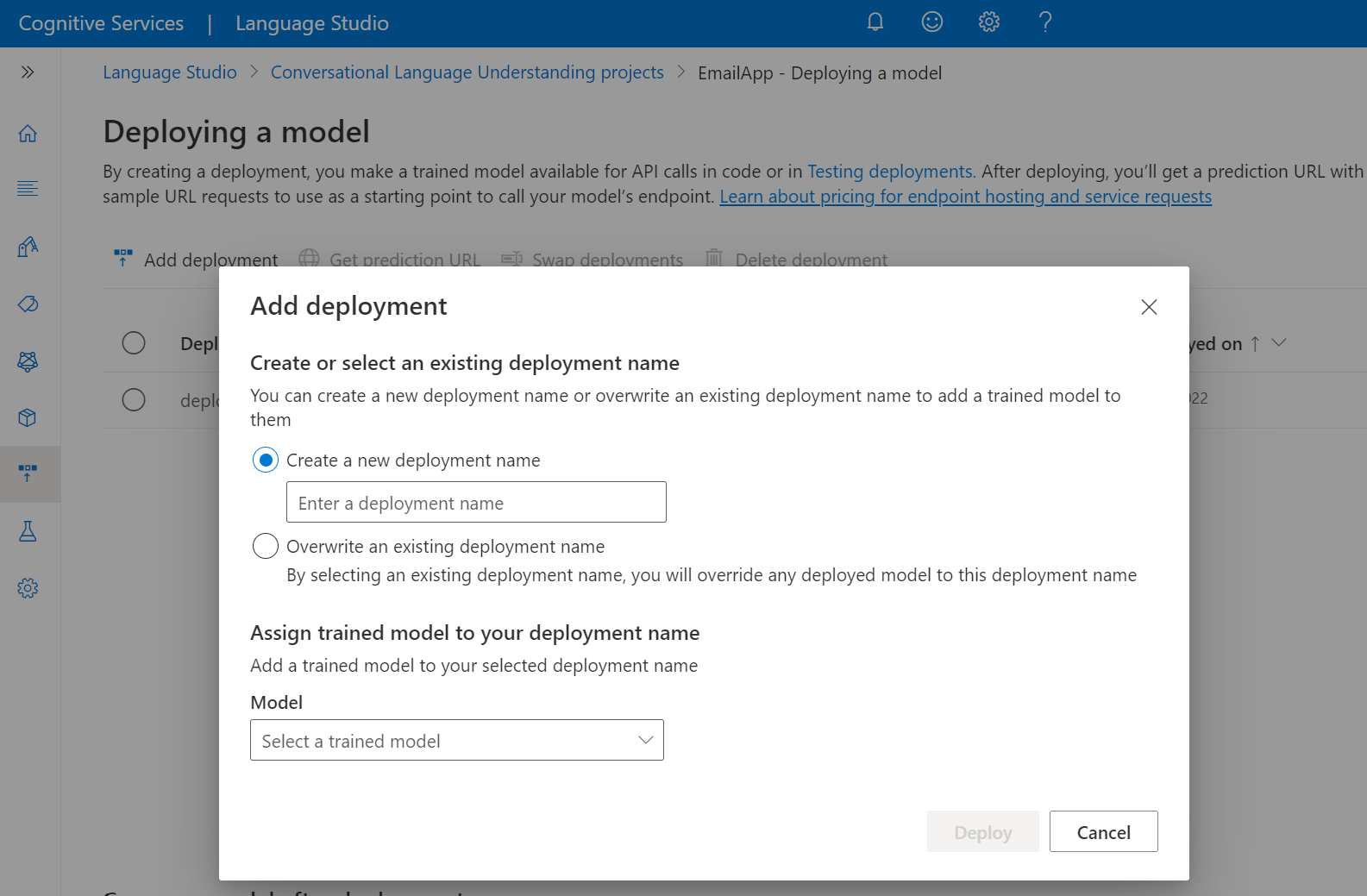
V rozevíracím seznamu Model vyberte natrénovaný model.
Výběrem možnosti Nasadit spustíte úlohu nasazení.
Po úspěšném nasazení se vedle něj zobrazí datum vypršení platnosti. Vypršení platnosti nasazení je v případě, že nasazený model nebude dostupný pro predikci, což obvykle nastane dvanáct měsíců po vypršení platnosti konfigurace trénování.


Název projektu a název nasazení použijete v další části.
Rozpoznávání záměrů z mikrofonu
Pomocí těchto kroků vytvořte novou konzolovou aplikaci a nainstalujte sadu Speech SDK.
Otevřete příkazový řádek, ve kterém chcete nový projekt, a vytvořte konzolovou aplikaci pomocí rozhraní příkazového řádku .NET CLI. Soubor
Program.csby se měl vytvořit v adresáři projektu.dotnet new consoleNainstalujte sadu Speech SDK do nového projektu pomocí rozhraní příkazového řádku .NET.
dotnet add package Microsoft.CognitiveServices.SpeechNahraďte obsah
Program.csnásledujícím kódem.using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent; class Program { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" static string languageKey = Environment.GetEnvironmentVariable("LANGUAGE_KEY"); static string languageEndpoint = Environment.GetEnvironmentVariable("LANGUAGE_ENDPOINT"); static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); // Your CLU project name and deployment name. static string cluProjectName = "YourProjectNameGoesHere"; static string cluDeploymentName = "YourDeploymentNameGoesHere"; async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); // Creates an intent recognizer in the specified language using microphone as audio input. using (var intentRecognizer = new IntentRecognizer(speechConfig, audioConfig)) { var cluModel = new ConversationalLanguageUnderstandingModel( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); var collection = new LanguageUnderstandingModelCollection(); collection.Add(cluModel); intentRecognizer.ApplyLanguageModels(collection); Console.WriteLine("Speak into your microphone."); var recognitionResult = await intentRecognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (recognitionResult.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent Id: {recognitionResult.IntentId}."); Console.WriteLine($" Language Understanding JSON: {recognitionResult.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (recognitionResult.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent not recognized."); } else if (recognitionResult.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (recognitionResult.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(recognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } } } }V
Program.cssaděcluProjectNameacluDeploymentNameproměnných na názvy projektu a nasazení. Informace o tom, jak vytvořit projekt a nasazení CLU, naleznete v tématu Vytvoření projektu Konverzační language Understanding.Pokud chcete změnit jazyk rozpoznávání řeči, nahraďte
en-USjiným podporovaným jazykem. Napříklades-ESpro španělštinu (Španělsko). Výchozí jazyk jeen-US, pokud nezadáte jazyk. Podrobnosti o tom, jak identifikovat jeden z více jazyků, které by mohly být mluvené, najdete v tématu identifikace jazyka.
Spuštěním nové konzolové aplikace spusťte rozpoznávání řeči z mikrofonu:
dotnet run
Důležité
Ujistěte se, že jste nastavili LANGUAGE_KEYproměnné , LANGUAGE_ENDPOINTSPEECH_KEYa SPEECH_REGION prostředí, jak je popsáno výše. Pokud tyto proměnné nenastavíte, ukázka selže s chybovou zprávou.
Po zobrazení výzvy promluvte do mikrofonu. To, co mluvíte, by mělo být výstupem jako text:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Poznámka:
Podpora odpovědi JSON pro CLU prostřednictvím vlastnosti LanguageUnderstandingServiceResponse_JsonResult byla přidána do sady Speech SDK verze 1.26.
Záměry se vrátí v pořadí pravděpodobnosti s největší pravděpodobností nejméně pravděpodobné. Tady je naformátovaná verze výstupu JSON, kde topIntent má HomeAutomation.TurnOn skóre spolehlivosti 0,97712576 (97,71 %). Druhý nejpravděpodobnější záměr může mít HomeAutomation.TurnOff skóre spolehlivosti 0,8985081 (84,31 %).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Poznámky
Teď, když jste dokončili rychlý start, tady jsou některé další aspekty:
- Tento příklad používá
RecognizeOnceAsyncoperaci k přepisu promluv do 30 sekund nebo do zjištění ticha. Informace o nepřetržitém rozpoznávání delšího zvuku, včetně vícejazyčných konverzací, najdete v tématu Rozpoznávání řeči. - Pokud chcete rozpoznat řeč ze zvukového souboru, použijte
FromWavFileInputmístoFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav"); - Pro komprimované zvukové soubory, jako je MP4, nainstalujte GStreamer a použijte
PullAudioInputStreamneboPushAudioInputStream. Další informace naleznete v tématu Použití komprimovaného vstupního zvuku.
Vyčištění prostředků
K odebrání prostředků jazyka a řeči, které jste vytvořili, můžete použít Azure Portal nebo rozhraní příkazového řádku Azure (CLI ).
Referenční dokumentace | Package (NuGet) | Další ukázky na GitHubu
V tomto rychlém startu použijete služby Speech a Language k rozpoznávání záměrů ze zvukových dat zachycených z mikrofonu. Konkrétně použijete službu Speech k rozpoznávání řeči a modelu CLU (Conversational Language Understanding) k identifikaci záměrů.
Důležité
Konverzační language Understanding (CLU) je k dispozici pro C# a C++ se sadou Speech SDK verze 1.25 nebo novější.
Požadavky
- Předplatné Azure. Můžete si ho zdarma vytvořit.
- Na webu Azure Portal vytvořte prostředek jazyka.
- Získejte klíč prostředku jazyka a koncový bod. Po nasazení prostředku jazyka vyberte Přejít k prostředku a zobrazte a spravujte klíče.
- Na webu Azure Portal vytvořte prostředek služby AI Services pro službu Speech .
- Získejte klíč prostředku a oblast služby Speech. Po nasazení prostředku služby Speech vyberte Přejít k prostředku a zobrazte a spravujte klíče.
Nastavení prostředí
Sada Speech SDK je k dispozici jako balíček NuGet a implementuje .NET Standard 2.0. Sadu Speech SDK nainstalujete později v této příručce, ale nejprve si projděte průvodce instalací sady SDK, kde najdete další požadavky.
Nastavení proměnných prostředí
Tento příklad vyžaduje proměnné prostředí s názvem LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEYa SPEECH_REGION.
Aby vaše aplikace získala přístup k prostředkům služeb Azure AI, musí být ověřená. V tomto článku se dozvíte, jak pomocí proměnných prostředí ukládat přihlašovací údaje. Pak můžete přistupovat k proměnným prostředí z kódu, abyste aplikaci ověřili. V produkčním prostředí použijte bezpečnější způsob, jak ukládat přihlašovací údaje a přistupovat k němu.
Důležité
Doporučujeme ověřování Microsoft Entra ID se spravovanými identitami pro prostředky Azure, abyste se vyhnuli ukládání přihlašovacích údajů s aplikacemi, které běží v cloudu.
Používejte klíče rozhraní API s opatrností. Nezahrnujte klíč rozhraní API přímo do kódu a nikdy ho nevštěvujte veřejně. Pokud používáte klíče rozhraní API, bezpečně je uložte ve službě Azure Key Vault, pravidelně je obměňujte a omezte přístup ke službě Azure Key Vault pomocí řízení přístupu na základě rolí a omezení přístupu k síti. Další informace o bezpečném používání klíčů ROZHRANÍ API ve vašich aplikacích najdete v tématu Klíče rozhraní API se službou Azure Key Vault.
Další informace o zabezpečení služeb AI najdete v tématu Ověřování požadavků na služby Azure AI.
Pokud chcete nastavit proměnné prostředí, otevřete okno konzoly a postupujte podle pokynů pro operační systém a vývojové prostředí.
- Pokud chcete nastavit proměnnou
LANGUAGE_KEYprostředí, nahraďteyour-language-keyjedním z klíčů pro váš prostředek. - Pokud chcete nastavit proměnnou
LANGUAGE_ENDPOINTprostředí, nahraďteyour-language-endpointjednou z oblastí vašeho prostředku. - Pokud chcete nastavit proměnnou
SPEECH_KEYprostředí, nahraďteyour-speech-keyjedním z klíčů pro váš prostředek. - Pokud chcete nastavit proměnnou
SPEECH_REGIONprostředí, nahraďteyour-speech-regionjednou z oblastí vašeho prostředku.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Poznámka:
Pokud potřebujete získat přístup pouze k proměnné prostředí v aktuální spuštěné konzole, můžete místo toho nastavit proměnnou setsetxprostředí .
Po přidání proměnných prostředí budete možná muset restartovat všechny spuštěné programy, které budou muset přečíst proměnnou prostředí, včetně okna konzoly. Pokud například jako editor používáte Sadu Visual Studio, restartujte sadu Visual Studio před spuštěním příkladu.
Vytvoření projektu Konverzační služby Language Understanding
Jakmile máte vytvořený prostředek jazyka, vytvořte v sadě Language Studio projekt pro porozumění konverzačnímu jazyku. Projekt je pracovní oblast pro vytváření vlastních modelů ML na základě vašich dat. K vašemu projektu má přístup jenom vy a ostatní, kteří mají přístup k používanému prostředku jazyka.
Přejděte do sady Language Studio a přihlaste se pomocí svého účtu Azure.
Vytvoření projektu pro porozumění konverzačnímu jazyku
Pro účely tohoto rychlého startu si můžete stáhnout tento ukázkový projekt domácí automatizace a importovat ho. Tento projekt dokáže předpovědět zamýšlené příkazy ze vstupu uživatele, například zapnutí a vypnutí světel.
V části Vysvětlení otázek a konverzačního jazyka v sadě Language Studio vyberte Porozumění konverzačnímu jazyku.
Tím se dostanete na stránku projektů pro porozumění konverzačnímu jazyku. Vedle tlačítka Vytvořit nový projekt vyberte Importovat.
V zobrazeném okně nahrajte soubor JSON, který chcete importovat. Ujistěte se, že váš soubor dodržuje podporovaný formát JSON.
Po dokončení nahrávání se dostanete na stránku definice schématu. Pro účely tohoto rychlého startu je schéma již sestavené a promluvy jsou už označené záměry a entitami.
Trénování vašeho modelu
Obvykle byste po vytvoření projektu měli vytvořit schéma a označovat promluvy. Pro účely tohoto rychlého startu jsme už naimportovali připravený projekt s sestaveným schématem a označenými promluvami.
Pokud chcete vytrénovat model, musíte zahájit trénovací úlohu. Výstupem úspěšné trénovací úlohy je trénovaný model.
Zahájení trénování modelu v sadě Language Studio:
V nabídce na levé straně vyberte Trénovat model .
V horní nabídce vyberte Spustit trénovací úlohu .
Vyberte Vytrénovat nový model a do textového pole zadejte nový název modelu. V opačném případě chcete nahradit existující model modelem natrénovaným na nových datech, vyberte Přepsat existující model a pak vyberte existující model. Přepsání natrénovaného modelu je nevratné, ale nebude mít vliv na nasazené modely, dokud nový model nenasadíte.
Vyberte režim trénování. Pro rychlejší trénování můžete zvolit standardní trénování , ale je k dispozici pouze pro angličtinu. Nebo můžete zvolit rozšířené trénování , které je podporováno pro jiné jazyky a vícejazyčné projekty, ale zahrnuje delší dobu trénování. Přečtěte si další informace o režimech trénování.
Vyberte metodu rozdělení dat. Můžete zvolit automatické rozdělení testovací sady z trénovacích dat , kde systém rozdělí promluvy mezi trénovací a testovací sady podle zadaných procent. Nebo můžete použít ruční rozdělení trénovacích a testovacích dat, tato možnost je povolená jenom v případě, že jste do testovací sady přidali promluvy při označování promluv.
Vyberte tlačítko Trénovat.
V seznamu vyberte ID trénovací úlohy. Zobrazí se panel, kde můžete zkontrolovat průběh trénování, stav úlohy a další podrobnosti o této úloze.
Poznámka:
- Pouze úspěšně dokončené trénovací úlohy vygenerují modely.
- Trénování může nějakou dobu trvat několik minut až několik hodin na základě počtu promluv.
- Najednou můžete mít spuštěnou pouze jednu úlohu trénování. Do dokončení spuštěné úlohy nemůžete spustit jiné trénovací úlohy v rámci stejného projektu.
- Strojové učení používané k trénování modelů se pravidelně aktualizuje. Pokud chcete vytrénovat předchozí verzi konfigurace, vyberte Možnost Vybrat, pokud chcete změnit stránku Spustit trénovací úlohu a zvolte předchozí verzi.
Nasazení modelu
Obecně platí, že po trénování modelu byste zkontrolovali jeho podrobnosti o vyhodnocení. V tomto rychlém startu jednoduše nasadíte model a zpřístupníte ho pro vyzkoušení v sadě Language Studio nebo můžete volat rozhraní API pro predikce.
Nasazení modelu v sadě Language Studio:
V nabídce na levé straně vyberte Nasazení modelu .
Výběrem možnosti Přidat nasazení spusťte Průvodce přidáním nasazení .
Výběrem možnosti Vytvořit nový název nasazení vytvořte nové nasazení a v rozevíracím seznamu níže přiřaďte natrénovaný model. Pokud chcete efektivně nahradit model používaný existujícím nasazením, můžete jinak vybrat možnost Přepsat existující název nasazení.
Poznámka:
Přepsání existujícího nasazení nevyžaduje změny volání rozhraní API pro predikce, ale výsledky, které získáte, budou založené na nově přiřazeného modelu.
V rozevíracím seznamu Model vyberte natrénovaný model.
Výběrem možnosti Nasadit spustíte úlohu nasazení.
Po úspěšném nasazení se vedle něj zobrazí datum vypršení platnosti. Vypršení platnosti nasazení je v případě, že nasazený model nebude dostupný pro predikci, což obvykle nastane dvanáct měsíců po vypršení platnosti konfigurace trénování.
Název projektu a název nasazení použijete v další části.
Rozpoznávání záměrů z mikrofonu
Pomocí těchto kroků vytvořte novou konzolovou aplikaci a nainstalujte sadu Speech SDK.
Vytvořte nový projekt konzoly C++ v sadě Visual Studio Community 2022 s názvem
SpeechRecognition.Nainstalujte sadu Speech SDK do nového projektu pomocí správce balíčků NuGet.
Install-Package Microsoft.CognitiveServices.SpeechSpeechRecognition.cppObsah nahraďte následujícím kódem:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; using namespace Microsoft::CognitiveServices::Speech::Intent; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" auto languageKey = GetEnvironmentVariable("LANGUAGE_KEY"); auto languageEndpoint = GetEnvironmentVariable("LANGUAGE_ENDPOINT"); auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); auto cluProjectName = "YourProjectNameGoesHere"; auto cluDeploymentName = "YourDeploymentNameGoesHere"; if ((size(languageKey) == 0) || (size(languageEndpoint) == 0) || (size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto intentRecognizer = IntentRecognizer::FromConfig(speechConfig, audioConfig); std::vector<std::shared_ptr<LanguageUnderstandingModel>> models; auto cluModel = ConversationalLanguageUnderstandingModel::FromResource( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); models.push_back(cluModel); intentRecognizer->ApplyLanguageModels(models); std::cout << "Speak into your microphone.\n"; auto result = intentRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedIntent) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; std::cout << " Intent Id: " << result->IntentId << std::endl; std::cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl; } else if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you update the subscription info?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }V
SpeechRecognition.cppsaděcluProjectNameacluDeploymentNameproměnných na názvy projektu a nasazení. Informace o tom, jak vytvořit projekt a nasazení CLU, naleznete v tématu Vytvoření projektu Konverzační language Understanding.Pokud chcete změnit jazyk rozpoznávání řeči, nahraďte
en-USjiným podporovaným jazykem. Napříklades-ESpro španělštinu (Španělsko). Výchozí jazyk jeen-US, pokud nezadáte jazyk. Podrobnosti o tom, jak identifikovat jeden z více jazyků, které by mohly být mluvené, najdete v tématu identifikace jazyka.
Sestavte a spusťte novou konzolovou aplikaci, která spustí rozpoznávání řeči z mikrofonu.
Důležité
Ujistěte se, že jste nastavili LANGUAGE_KEYproměnné , LANGUAGE_ENDPOINTSPEECH_KEYa SPEECH_REGION prostředí, jak je popsáno výše. Pokud tyto proměnné nenastavíte, ukázka selže s chybovou zprávou.
Po zobrazení výzvy promluvte do mikrofonu. To, co mluvíte, by mělo být výstupem jako text:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Poznámka:
Podpora odpovědi JSON pro CLU prostřednictvím vlastnosti LanguageUnderstandingServiceResponse_JsonResult byla přidána do sady Speech SDK verze 1.26.
Záměry se vrátí v pořadí pravděpodobnosti s největší pravděpodobností nejméně pravděpodobné. Tady je naformátovaná verze výstupu JSON, kde topIntent má HomeAutomation.TurnOn skóre spolehlivosti 0,97712576 (97,71 %). Druhý nejpravděpodobnější záměr může mít HomeAutomation.TurnOff skóre spolehlivosti 0,8985081 (84,31 %).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Poznámky
Teď, když jste dokončili rychlý start, tady jsou některé další aspekty:
- Tento příklad používá
RecognizeOnceAsyncoperaci k přepisu promluv do 30 sekund nebo do zjištění ticha. Informace o nepřetržitém rozpoznávání delšího zvuku, včetně vícejazyčných konverzací, najdete v tématu Rozpoznávání řeči. - Pokud chcete rozpoznat řeč ze zvukového souboru, použijte
FromWavFileInputmístoFromDefaultMicrophoneInput:auto audioInput = AudioConfig::FromWavFileInput("YourAudioFile.wav"); - Pro komprimované zvukové soubory, jako je MP4, nainstalujte GStreamer a použijte
PullAudioInputStreamneboPushAudioInputStream. Další informace naleznete v tématu Použití komprimovaného vstupního zvuku.
Vyčištění prostředků
K odebrání prostředků jazyka a řeči, které jste vytvořili, můžete použít Azure Portal nebo rozhraní příkazového řádku Azure (CLI ).
Referenční dokumentace | Další ukázky na GitHubu
Sada Speech SDK pro Javu nepodporuje rozpoznávání záměru pomocí jazyka CLU (Conversational Language Understanding). Vyberte jiný programovací jazyk nebo odkazy na Javu a ukázky propojené od začátku tohoto článku.