Výkon a latence
Tento článek obsahuje základní informace o tom, jak latence a propustnost funguje s Azure OpenAI a jak optimalizovat prostředí za účelem zlepšení výkonu.
Principy propustnosti a latence
Při nastavování velikosti aplikace existují dva klíčové koncepty: (1) Propustnost na úrovni systému měřená v tokenech za minutu (TPM) a (2) Doby odezvy na volání (označované také jako latence).
Propustnost na úrovni systému
Tím se podíváte na celkovou kapacitu vašeho nasazení – kolik požadavků za minutu a celkové tokeny, které je možné zpracovat.
U standardního nasazení kvóta přiřazená k vašemu nasazení částečně určuje velikost propustnosti, kterou můžete dosáhnout. Kvóta ale určuje logiku přístupu pouze pro volání nasazení a nevynucuje přímo propustnost. Kvůli změnám latence volání možná nebudete moct dosáhnout propustnosti tak vysoké, jako je kvóta. Přečtěte si další informace o správě kvóty.
Ve zřízeném nasazení se ke koncovému bodu přidělí sada kapacity zpracování modelu. Propustnost, kterou můžete dosáhnout na koncovém bodu, je faktorem obrazce úlohy, včetně množství vstupního tokenu, výstupního množství, rychlosti volání a míry shody mezipaměti. Počet souběžných volání a celkového počtu zpracovaných tokenů se může lišit v závislosti na těchto hodnotách.
Pro všechny typy nasazení je pochopení propustnosti na úrovni systému klíčovou součástí optimalizace výkonu. U daného modelu, verze a kombinace úloh je důležité zvážit propustnost na úrovni systému, protože propustnost se bude u těchto faktorů lišit.
Odhad propustnosti na úrovni systému
Odhad čipu TPM s využitím metrik služby Azure Monitor
Jedním z přístupů k odhadu propustnosti na úrovni systému pro danou úlohu je použití historických dat o využití tokenů. U úloh Azure OpenAI je možné získat přístup ke všem historickým datům o využití a vizualizovat s nativními možnostmi monitorování, které nabízí Azure OpenAI. K odhadu propustnosti na úrovni systému pro úlohy Azure OpenAI jsou potřeba dvě metriky: (1) Zpracované tokeny výzvy a (2) Vygenerované tokeny dokončení.
Při kombinaci metrik zpracovaných výzev (vstupní čip TPM) a vygenerovaných tokenů dokončení (výstupní čip TPM) poskytují odhadované zobrazení propustnosti na úrovni systému na základě skutečného provozu úloh. Tento přístup nepočítá s výhodami ukládání do mezipaměti, takže se jedná o konzervativní odhad propustnosti systému. Tyto metriky je možné analyzovat pomocí minimální, průměrné a maximální agregace za 1 minutu v rámci vícetýdenního časového horizontu. Doporučujeme tato data analyzovat v rámci vícetýdenního časového horizontu, abyste zajistili, že existuje dostatek datových bodů k vyhodnocení. Následující snímek obrazovky ukazuje příklad metriky zpracovaných výzev vizualizovaných ve službě Azure Monitor, která je dostupná přímo prostřednictvím webu Azure Portal.
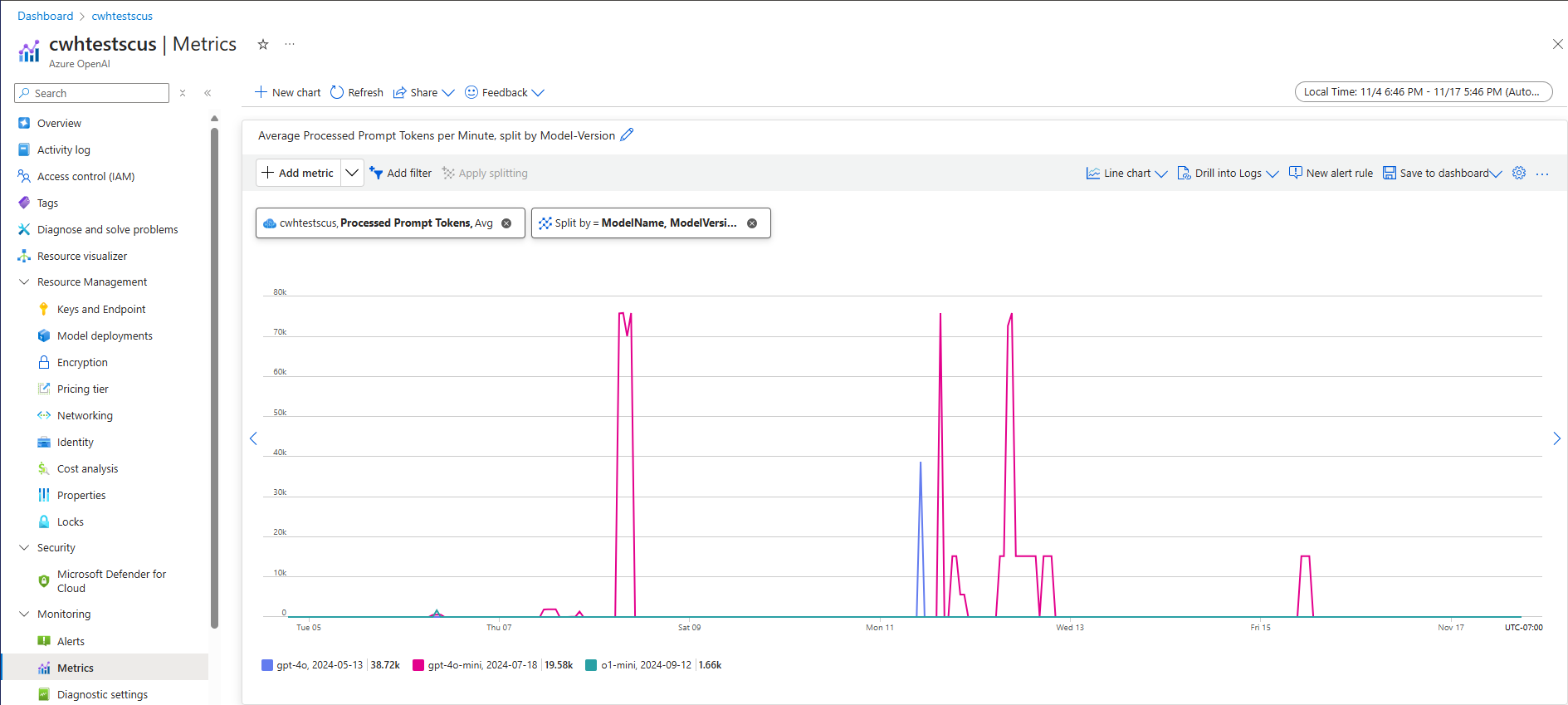
Odhad čipu TPM z dat požadavku
Druhý přístup k odhadované propustnosti na úrovni systému zahrnuje shromažďování informací o využití tokenů z dat požadavků rozhraní API. Tato metoda poskytuje podrobnější přístup k pochopení obrazce úloh na požadavek. Kombinace informací o využití tokenu požadavku s objemem požadavků měřeným v požadavcích za minutu (RPM) poskytuje odhad propustnosti na úrovni systému. Je důležité si uvědomit, že odhad propustnosti systému ovlivní všechny předpoklady pro konzistenci informací o využití tokenů napříč požadavky a objemem požadavků. Výstupní data o využití tokenu najdete v podrobnostech odpovědi rozhraní API pro danou žádost o dokončení chatu služby Azure OpenAI.
{
"body": {
"id": "chatcmpl-7R1nGnsXO8n4oi9UPz2f3UHdgAYMn",
"created": 1686676106,
"choices": [...],
"usage": {
"completion_tokens": 557,
"prompt_tokens": 33,
"total_tokens": 590
}
}
}
Za předpokladu, že všechny požadavky na danou úlohu jsou jednotné, můžou být tokeny výzvy a tokeny dokončení z dat odpovědí rozhraní API vynásobeny odhadovaným RPM a identifikují vstupní a výstupní čip TPM pro danou úlohu.
Jak používat odhady propustnosti na úrovni systému
Po odhadu propustnosti na úrovni systému pro danou úlohu je možné tyto odhady použít k nastavení velikosti standardních a zřízených nasazení. U standardních nasazení je možné vstupní a výstupní hodnoty TPM zkombinovat a odhadnout celkový počet čipů TPM, které se mají přiřadit k danému nasazení. U zřízených nasazení je možné pomocí dat o využití tokenu požadavku nebo vstupních a výstupních hodnot TPM odhadnout počet PTU potřebných k podpoře dané úlohy s využitím kalkulačky kapacity nasazení.
Tady je několik příkladů minimodelu GPT-4o:
| Velikost výzvy (tokeny) | Velikost generování (tokeny) | Žádosti za minutu | Vstupní čip TPM | Výstupní čip TPM | Celkový počet čipů TPM | Požadovány ptu |
|---|---|---|---|---|---|---|
| 800 | 150 | 30 | 24,000 | 4 500 | 28,500 | 15 |
| 5 000 | 50 | 1000 | 5,000,000 | 50 000 | 5,050,000 | 140 |
| 1000 | 300 | 500 | 500,000 | 150,000 | 650,000 | 30 |
Počet jednotek PTU se škáluje zhruba lineárně s četností volání, když distribuce úloh zůstává konstantní.
Latence: Doby odezvy volání
Vysoká úroveň definice latence v tomto kontextu je doba, kterou trvá získání odpovědi z modelu. U žádostí o dokončení a dokončování chatu je latence z velké části závislá na typu modelu, počtu tokenů v příkazovém řádku a počtu vygenerovaných tokenů. Obecně platí, že každý token výzvy v porovnání s každým přírůstkovým vygenerovaným tokenem přidává málo času.
Odhad očekávané latence volání může být u těchto modelů náročný. Latence požadavku na dokončení se může lišit v závislosti na čtyřech primárních faktorech: (1) model, (2) počet tokenů v příkazovém řádku, (3) počet vygenerovaných tokenů a (4) celkové zatížení systému a nasazení. Jedna a tři jsou často hlavními přispěvateli celkového času. Další část obsahuje další podrobnosti o anatomii volání odvozování velkého jazykového modelu.
Zvýšení výkonu
Existuje několik faktorů, které můžete řídit, aby se zlepšila latence jednotlivých volání vaší aplikace.
Výběr modelu
Latence se liší podle toho, jaký model používáte. U identického požadavku počítejte s tím, že různé modely mají různé latence pro volání dokončení chatu. Pokud váš případ použití vyžaduje modely s nejnižší latencí s nejrychlejší dobou odezvy, doporučujeme nejnovější minimodel GPT-4o.
Velikost generování a maximální počet tokenů
Když odešlete požadavek na dokončení do koncového bodu Azure OpenAI, váš vstupní text se převede na tokeny, které se pak posílají do nasazeného modelu. Model obdrží vstupní tokeny a pak začne generovat odpověď. Jedná se o iterativní sekvenční proces, jeden token najednou. Další způsob, jak si to představit, je jako smyčka s n tokens = n iterations. U většiny modelů je generování odpovědi nejpomalejším krokem procesu.
V době požadavku se požadovaná velikost generování (parametr max_tokens) použije jako počáteční odhad velikosti generování. Výpočetní doba pro vygenerování plné velikosti je vyhrazena modelem při zpracování požadavku. Po dokončení generování se uvolní zbývající kvóta. Způsoby snížení počtu tokenů:
max_tokensNastavte parametr pro každé volání co nejmenší.- Zahrňte sekvence zastavení, aby se zabránilo generování dalšího obsahu.
- Generovat méně odpovědí: Parametry best_of a n mohou výrazně zvýšit latenci, protože generují více výstupů. Pro nejrychlejší odpověď buď nezadávejte tyto hodnoty, nebo je nastavte na 1.
Snížení počtu vygenerovaných tokenů na požadavek snižuje latenci každého požadavku.
Streamování
Nastavení stream: true v požadavku zajistí, že služba vrátí tokeny, jakmile budou dostupné, místo čekání na vygenerování celé posloupnosti tokenů. Nezmění čas na získání všech tokenů, ale zkracuje čas první odpovědi. Tento přístup poskytuje lepší uživatelské prostředí, protože koncoví uživatelé můžou číst odpověď při generování.
Streamování je také cenné u velkých volání, která zpracovávají dlouhou dobu. Mnoho klientů a zprostředkující vrstvy mají časové limity pro jednotlivá volání. Kvůli vypršení časového limitu na straně klienta může dojít ke zrušení volání dlouhé generace. Streamováním dat zpět můžete zajistit přijetí přírůstkových dat.
Příklady použití streamování:
Chatovací roboti a konverzační rozhraní
Streamování má vliv na vnímanou latenci. S povoleným streamováním přijímáte tokeny zpět v blocích, jakmile budou k dispozici. U koncových uživatelů tento přístup často vypadá, jako by model reagoval rychleji, i když celková doba dokončení požadavku zůstává stejná.
Příklady, kdy je streamování méně důležité:
Analýza mínění, překlad jazyka, generování obsahu
Existuje mnoho případů použití, kdy provádíte určitou hromadnou úlohu, kde se staráte jenom o dokončený výsledek, ne o odpověď v reálném čase. Pokud je streamování zakázané, nebudete dostávat žádné tokeny, dokud model nedokončí celou odpověď.
Filtrování obsahu
Azure OpenAI obsahuje systém filtrování obsahu, který funguje společně s základními modely. Tento systém funguje spuštěním výzvy i dokončení prostřednictvím souboru klasifikačních modelů zaměřených na detekci a zabránění výstupu škodlivého obsahu.
Systém filtrování obsahu zjistí a provede akce s konkrétními kategoriemi potenciálně škodlivého obsahu ve vstupních výzev i dokončení výstupu.
Přidání filtrování obsahu přináší zvýšení bezpečnosti, ale také latenci. Existuje mnoho aplikací, kde je tento kompromis v výkonu nezbytný, ale existují určité nižší riziko případy použití, kdy zakázání filtrů obsahu ke zlepšení výkonu může být užitečné prozkoumat.
Přečtěte si další informace o vyžádání změn výchozích zásad filtrování obsahu.
Oddělení úloh
Kombinování různých úloh ve stejném koncovém bodu může negativně ovlivnit latenci. Důvodem je to, že (1) jsou rozdělené dohromady během odvozování a krátká volání mohou čekat na delší dokončení a (2) kombinování volání může snížit rychlost dosažení mezipaměti, protože obě soupeří o stejné místo. Pokud je to možné, doporučujeme mít pro každou úlohu samostatná nasazení.
Velikost výzvy
I když má velikost výzvy menší vliv na latenci, než má velikost generování, ovlivňuje celkový čas, zejména v případě, že velikost roste.
Dávkování
Pokud odesíláte více požadavků do stejného koncového bodu, můžete žádosti dávkovat do jednoho volání. Tím se sníží počet požadavků, které potřebujete provést, a v závislosti na scénáři může zlepšit celkovou dobu odezvy. Doporučujeme tuto metodu otestovat, abyste zjistili, jestli vám to pomůže.
Měření propustnosti
U nasazení doporučujeme měřit celkovou propustnost se dvěma mírami:
- Volání za minutu: Počet volání odvozování rozhraní API, která provádíte za minutu. To se dá měřit ve službě Azure Monitor pomocí metriky Požadavků Azure OpenAI a rozdělení podle modeluDeploymentName.
- Celkový počet tokenů za minutu: Celkový počet tokenů zpracovávaných vaším nasazením za minutu To zahrnuje výzvy a vygenerované tokeny. To je často dále rozdělené na měření obou pro hlubší pochopení výkonu nasazení. To se dá měřit ve službě Azure Monitor pomocí metriky zpracovaných odvozovatelné tokeny.
Další informace o monitorování služby Azure OpenAI.
Měření latence volání
Doba trvání každého volání závisí na tom, jak dlouho trvá čtení modelu, generování výstupu a použití filtrů obsahu. Způsob měření času se bude lišit, pokud používáte streamování nebo ne. Pro každý případ doporučujeme použít jinou sadu měr.
Další informace o monitorování služby Azure OpenAI.
Bez streamování:
- Koncový čas požadavku: Celková doba potřebná ke generování celé odpovědi pro požadavky bez streamování měřená bránou rozhraní API. Toto číslo se zvyšuje při nárůstu velikosti výzvy a generování.
Proudem:
- Doba odezvy: Doporučená míra latence (rychlost odezvy) pro požadavky streamování Platí pro nasazení spravovaná ptu a PTU. Počítané jako čas potřebný k zobrazení první odpovědi po odeslání výzvy uživatelem měřeným bránou rozhraní API. Toto číslo se zvyšuje, když se velikost výzvy zvětšuje nebo zmenšuje.
- Průměrná doba generování tokenů od prvního tokenu k poslednímu tokenu vydělená počtem vygenerovaných tokenů měřenou bránou rozhraní API. Tím se měří rychlost generování odpovědí a zvyšuje se zatížení systému. Doporučená míra latence pro požadavky streamování
Shrnutí
Latence modelu: Pokud je pro vás důležitá latence modelu, doporučujeme vyzkoušet minimodel GPT-4o.
Nižší maximální počet tokenů: OpenAI zjistil, že i v případech, kdy je celkový počet vygenerovaných tokenů podobný požadavku s vyšší hodnotou nastavenou pro parametr maximálního tokenu, bude mít vyšší latenci.
Vygenerované tokeny s nižším celkovým součtem: Čím méně tokenů se vygenerovalo rychleji, bude celková odpověď. Mějte na paměti, že to je jako mít smyčku for s
n tokens = n iterations. Snižte počet generovaných tokenů a celková doba odezvy se odpovídajícím způsobem zlepší.Streamování: Povolení streamování může být užitečné při správě očekávání uživatelů v určitých situacích tím, že uživateli umožní zobrazit odpověď modelu, protože se generuje, a nemusí čekat na dokončení posledního tokenu.
Filtrování obsahu zlepšuje bezpečnost, ale má také vliv na latenci. Vyhodnoťte, jestli by některé z vašich úloh mohly těžit ze zásad filtrování upraveného obsahu.