Základní koncepty
Kdy bude služba Metrics Advisor zastaralá?
Od 20. září 2023 nebudete moct vytvářet nové prostředky Advisoru pro metriky. Služba Metrics Advisor se 1. října 2026 vyřadí z provozu.
Co jsou vícerozměrná data časových řad?
Podívejte se na definici multidimenzionální metriky v glosáři.
Kolik dat je potřeba, aby služba Metrics Advisor spustila detekci anomálií?
Minimálně jeden datový bod může aktivovat detekci anomálií. To ale nepřináší nejlepší přesnost. Služba bude při vytváření datového kanálu předpokládat okno předchozích datových bodů s hodnotou, kterou jste zadali jako pravidlo "fill-gap".
Před časovým razítkem, na kterém chcete detekovat, doporučujeme mít nějaká data. V závislosti na členitosti vašich dat se doporučené množství dat liší podle následujícího postupu.
| Členitost | Doporučené množství dat pro detekci |
|---|---|
| Méně než 5 minut | 4 dny dat |
| 5 minut až 1 den | 28 dnů dat |
| Více než 1 den, až 31 dní | 4 roky dat |
| Více než 31 dní | 48 let dat |
Jaká data služba Metrics Advisor zpracovává a jak se uchovávají data?
- Metrics Advisor zpracovává data časových řad shromážděná ze zdroje dat zákazníka, historická data se používají k výběru modelu a určují očekávanou hranici dat.
- Data časových řad a výsledky odvozování zákazníka budou uloženy v rámci služby. Metrics Advisor neukládá ani nezpracuje zákaznická data mimo oblast, ve které zákazník nasadí instanci služby.
Proč Nástroj Metrics Advisor nezjistí anomálie z historických dat?
Metrics Advisor je navržený pro detekci živých streamovaných dat. Existuje omezení maximální délky historických dat, která služba bude hledat a spouštět detekci anomálií. To znamená, že výsledky detekce anomálií budou mít pouze datové body po určitém nejstarším časovém razítku. Toto nejstarší časové razítko závisí na členitosti vašich dat.
Na základě členitosti dat jsou délky historických dat, které budou mít výsledky detekce anomálií, následující.
| Členitost | Maximální délka historických dat pro detekci anomálií |
|---|---|
| Méně než 5 minut | Čas onboardingu – 13 hodin |
| 5 minut na méně než 1 hodinu | Čas onboardingu – 4 dny |
| 1 hodina až méně než 1 den | Čas onboardingu – 14 dní |
| 1 den | Čas onboardingu – 28 dní |
| Větší než 1 den, méně než 31 dní | Čas onboardingu – 2 roky |
| Více než 31 dní | Čas onboardingu – 24 let |
Jaké jsou limity a uchovávání dat v Advisoru pro metriky?
- Uchovávání dat. Služba Metrics Advisor bude uchovávat maximálně 10 000 časových intervalů , jaké je interval? Počítá se od aktuálního časového razítka bez ohledu na to, jestli jsou k dispozici data, nebo ne. Data se z okna odstraní. Mapování uchovávání dat na počet dnů pro různou členitost metrik
| Členitost(min) | Retention(day) |
|---|---|
| 0 | 6.94 |
| 5 | 34.72 |
| 15 | 104.1 |
| 60(=hodinová) | 416.67 |
| 1440(=denně) | 10000.00 |
- Omezení maximálního počtučasových
Mohou mít více dimenzí v rámci jedné metriky a každá dimenze může mít více hodnot. Maximální kombinace dimenzí pro jednu metriku by neměla překročit 100 tisíc.
- Správci prostředků Advisoru a vlastníci datových kanálů budou upozorněni, když na stránce podrobností datového kanálu dosáhnete 80 % omezení.
- Pokud metrika překročila omezení, bude datový kanál pozastavený a počkejte, až zákazníci budou provádět následné akce. Doporučujeme rozdělit datový kanál na několik datových kanálů pomocí filtrování.
- Omezení maximálního počtu datových bodů uložených v jedné instanci Advisoru pro metriky
Advisor pro metriky počítá celkový počet datových bodů ze všech datových kanálů, které se připojovaly k instanci počínaje prvním časovým razítkem příjmu dat. Maximální počet datových bodů, které se mají uložit v jedné instanci Služby Metrics Advisor, je 2 miliardy.
- Správci prostředků Advisoru pro metriky a všichni uživatelé budou upozorněni na dosažení 80% omezení na stránce seznamu datových kanálů a prostřednictvím stránky pro přidání nového datového kanálu.
- Pokud celkový počet datových bodů překročil omezení, pozastaví se i všechny datové kanály a zablokuje se také onboarding nového kanálu. Doporučuje se odstranit nepoužívané datové kanály nebo vytvořit nový prostředek Metrics Advisor ve vašem předplatném.
Proč se nemůžu přihlásit ke službě Metrics Advisor? Chybová zpráva o vyřazení prostředku z provozu za 90 dnů
Existují dva případy vyřazení prostředku z provozu:
- Vytvoří se prostředek Metrics Advisoru, ale během 90 dnů se nezprovozní žádný datový kanál. Prostředek bude vyřazen z provozu po 90 dnech kvůli nečinnosti.
- Pokud byl vytvořen jeden nebo více datových kanálů, ale do služby Metrics Advisor se neingestují žádná nová data, služba přejde do režimu nečinnosti bez dat, která se mají zpracovat. Systém se stále pokusí pravidelně vybírat data ze zdroje podle členitosti metrik. Pokud však nadále nemá k dispozici žádná data nebo žádné časové řady ke zpracování po dobu 90 po sobě jdoucích dnů, prostředek se vyřadí z provozu. Všechna historická data přidružená k prostředku budou při vyřazení z provozu ztracena.
Pokud chcete restartovat využití, doporučujeme vytvořit nový prostředek a odstranit starý prostředek.
Návody detekovat špičky a poklesy jako anomálie?
Pokud máte předdefinované pevné prahové hodnoty, můžete v konfiguracích detekce anomálií ručně nastavit "pevnou prahovou hodnotu". Pokud žádné prahové hodnoty neexistují, můžete použít inteligentní zjišťování, které využívá umělou inteligenci. Podrobnosti najdete v konfiguraci detekce .
Návody detekovat v souladu s běžnými (sezónními) vzory jako anomáliemi?
Inteligentní zjišťování dokáže zjistit vzor vašich dat, včetně sezónních vzorů. Pak zjistí ty datové body, které neodpovídají běžným vzorům jako anomálie. Podrobnosti najdete v konfiguraci detekce .
Podporuje Služba Metrics Advisor zdroje dat, které jsou za virtuální sítí?
Ne, Nástroj Metrics Advisor v současné době nepodporuje zdroje dat, které jsou za virtuální sítí.
Návody detekovat ploché čáry jako anomálie?
Pokud jsou vaše data obvykle poměrně nestabilní a hodně kolísá a chcete být upozorněna, když se změní na příliš stabilní nebo dokonce se stane plochou čárou, je možné nakonfigurovat "prahovou hodnotu změn" tak, aby takové datové body detekovala, když je změna příliš malá. Podrobnosti najdete v konfiguracích detekce anomálií .
Jak nastavit nastavení e-mailu a povolit upozorňování e-mailem?
Uživatel s oprávněními správce předplatného nebo správce skupiny prostředků musí přejít k prostředku Poradce pro metriky, který se vytvořil na webu Azure Portal, a vybrat kartu Řízení přístupu (IAM).
Výběr možnosti Přidat přiřazení rolí
Vyberte roli správce Poradce pro metriky služeb Cognitive Services a vyberte svůj účet, jak je znázorněno na následujícím obrázku.
Vyberte tlačítko Uložit a přidáte se jako správce prostředku Metrics Advisor. Všechny výše uvedené akce musí provést správce předplatného nebo správce skupiny prostředků.
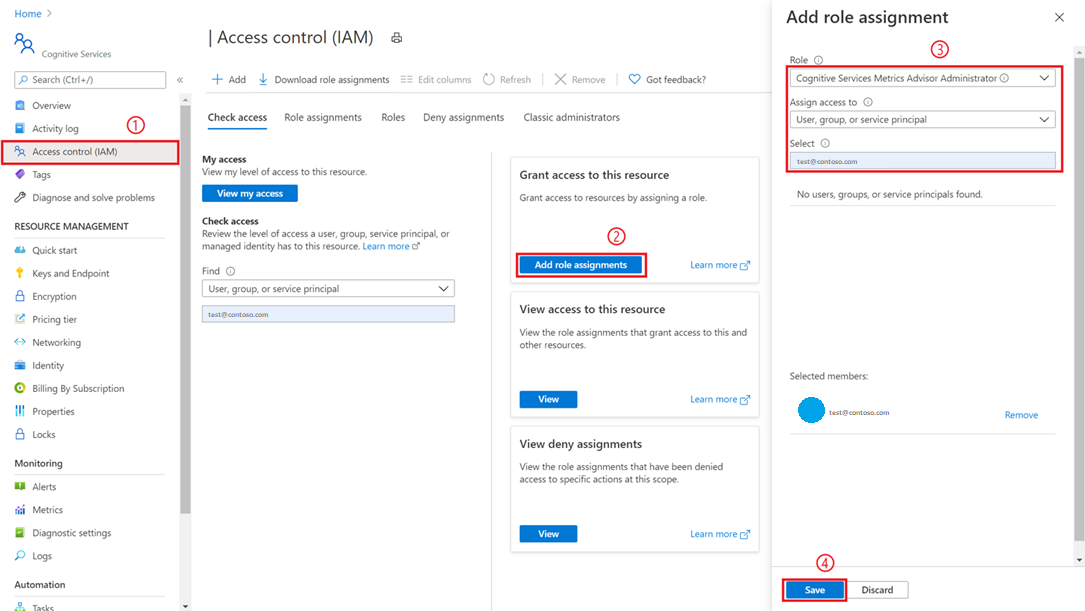
Rozšíření oprávnění může trvat až jednu minutu. Pak vyberte pracovní prostor Poradce pro metriky a v levém navigačním panelu vyberte možnost Nastavení e-mailu. Vyplňte požadované položky, zejména informace týkající se protokolu SMTP.
Vyberte Uložit a pak máte nastavenou konfiguraci e-mailu. Můžete vytvořit nové háky a přihlásit se k odběru anomálií metrik pro výstrahy téměř v reálném čase.

Rozšířené koncepty
Jak Metric Advisor vytvoří diagnostický strom pro vícerozměrné metriky?
Metriku je možné rozdělit na více časových řad podle dimenzí. Metrika Response latency se například monitoruje pro všechny služby vlastněné týmem. Kategorie Service se dá použít jako dimenze k obohacení metriky, takže se rozdělíme Response latency podle Service1atd Service2. Každá služba může být nasazena na různých počítačích v několika datových centrech, takže metrika by mohla být dále rozdělena a Machine Data center.
| Služba | Datové centrum | Počítač |
|---|---|---|
| S1 | DC1 | M1 |
| S1 | DC1 | M2 |
| S1 | DC2 | M3 |
| S1 | DC2 | M4 |
| S2 | DC1 | M1 |
| S2 | DC1 | M2 |
| S2 | DC2 | M5 |
| S2 | DC2 | M6 |
| ... |
Počínaje součtem Response latencymůžeme přejít k podrobnostem metriky podle Servicea Data center Machine. Možná ale dává vlastníkům služeb větší smysl použít cestu Service -Data center>>Machine nebo možná dává smysl, aby technici infrastruktury použili cestu Data Center -Machine> -.>Service Vše závisí na individuálních obchodních požadavcích vašich uživatelů.
V nástroji Metric Advisor můžou uživatelé zadat libovolnou cestu, kterou chtějí přejít k podrobnostem, nebo je zahrnout z jednoho uzlu hierarchické topologie. Přesněji řečeno, hierarchická topologie je směrovaný acyklický graf místo stromové struktury. K dispozici je úplná hierarchická topologie, která se skládá ze všech možných kombinací dimenzí, například takto:

Teoreticky platí, že pokud má dimenze Service Ls odlišné hodnoty, dimenze Data center má Ldc odlišné hodnoty a dimenze Machine má Lm odlišné hodnoty, pak by v hierarchické topologii mohly existovat (Ls + 1) * (Ldc + 1) * (Lm + 1) kombinace dimenzí.
Ale obvykle nejsou všechny kombinace dimenzí platné, což může výrazně snížit složitost. Pokud uživatelé agregují metriku sami, neomezujeme počet dimenzí. Pokud potřebujete použít kumulativní funkce poskytované službou Metrics Advisor, neměl by být počet dimenzí větší než 6. Omezujeme ale počet časových řad rozbalených podle dimenzí metriky na méně než 10 000.
Nástroj diagnostického stromu na stránce diagnostiky zobrazuje pouze uzly, ve kterých byla zjištěna anomálie, a ne celá topologie. To vám pomůže zaměřit se na aktuální problém. Nemusí také zobrazovat všechny anomálie v rámci metriky a místo toho zobrazí nejvyšší anomálie na základě příspěvku. Tímto způsobem můžeme rychle zjistit dopad, rozsah a cestu šíření neobvyklých dat. Což výrazně snižuje počet anomálií, na které se musíme zaměřit, a pomáhá uživatelům pochopit a najít jejich klíčové problémy.
Například když dojde k anomálii, Service = S2 | Data Center = DC2 | Machine = M5má odchylka anomálií vliv na nadřazený uzel Service= S2, který také zjistil anomálii, ale anomálie nemá vliv na celé datové centrum DC2 a všechny služby na M5. Strom incidentu by byl sestaven jako na následujícím snímku obrazovky, horní anomálie je zachycena na Service = S2a původní příčina by mohla být analyzována ve dvou cestách, které oba vedou k Service = S2 | Data Center = DC2 | Machine = M5.
