Označení dat v sadě Language Studio
Před trénováním modelu potřebujete dokumenty označovat vlastními entitami, které chcete extrahovat. Popisování dat je zásadní krok v životním cyklu vývoje. V tomto kroku můžete vytvořit typy entit, které chcete extrahovat z dat, a označovat tyto entity v dokumentech. Tato data se použijí v dalším kroku při trénování modelu, aby se váš model mohl učit z označených dat. Pokud už máte data označená jako označená, můžete je přímo naimportovat do projektu, ale musíte se ujistit, že vaše data mají stejný formát. Další informace o importu označených dat do projektu najdete v tématu vytvoření projektu .
Před vytvořením vlastního modelu NER je nejprve potřeba data označovat. Pokud vaše data ještě nejsou označená, můžete je označit v sadě Language Studio. Označená data informují model o tom, jak interpretovat text, a slouží k trénování a vyhodnocení.
Požadavky
Než budete moct data označovat, potřebujete:
- Úspěšně vytvořený projekt s nakonfigurovaným účtem služby Azure Blob Storage
- Textová data, která se nahrála do vašeho účtu úložiště
Další informace najdete v životním cyklu vývoje projektu.
Pokyny k označování dat
Po přípravě dat budete muset data označovat tak, že navrhnete schéma a vytvoříte projekt. Označení dat je důležité, aby model věděl, která slova budou přidružená k typům entit, které potřebujete extrahovat. Když označíte data v sadě Language Studio (nebo importujete označená data), budou tyto popisky uloženy v dokumentu JSON v kontejneru úložiště, který jste připojili k tomuto projektu.
Při označování dat mějte na paměti:
Obecně platí, že více označená data vedou k lepším výsledkům za předpokladu, že jsou data označená přesně.
Přesnost, konzistence a úplnost označených dat jsou klíčovými faktory pro určení výkonu modelu.
- Popisek přesně: Vždy označte každou entitu správným typem. Uveďte jenom to, co chcete extrahovat, vyhněte se zbytečným datům v popiscích.
- Popisek konzistentně: Stejná entita by měla mít stejný popisek ve všech dokumentech.
- Popisek je zcela: Všechny instance entity ve všech dokumentech označte. Pomocí funkce automatického označování můžete zajistit úplné označování.
Označení dat
K označení dat použijte následující postup:
Přejděte na stránku projektu v sadě Language Studio.
V nabídce na levé straně vyberte Popisky dat. Seznam všech dokumentů najdete v kontejneru úložiště.
Tip
Filtry v horní nabídce můžete použít k zobrazení neoznačené dokumenty, abyste je mohli začít popisovat. Filtry můžete použít také k zobrazení dokumentů, které jsou označené určitým typem entity.
Přejděte na jedno zobrazení dokumentu z levé strany v horní nabídce nebo vyberte konkrétní dokument, který chcete začít popisovat. Seznam všech
.txtdokumentů dostupných v projektu najdete vlevo. K procházení dokumentů můžete použít tlačítko Zpět a Další v dolní části stránky.Poznámka:
Pokud jste pro svůj projekt povolili více jazyků, najdete v horní nabídce rozevírací seznam Jazyk , který umožňuje vybrat jazyk každého dokumentu.
V pravém podokně přidejte do projektu typ entity, abyste mohli začít popisovat data pomocí nich.
Dokument můžete označovat dvěma způsoby:
Možnost Popis Popisek pomocí štětce Vyberte ikonu štětce vedle typu entity v pravém podokně a pak zvýrazněte text v dokumentu, který chcete přidat k poznámce s tímto typem entity. Popisek pomocí nabídky Zvýrazněte slovo, které chcete označit jako entitu, a zobrazí se nabídka. Vyberte typ entity, který chcete pro tuto entitu přiřadit. Následující snímek obrazovky ukazuje popisky pomocí štětce.
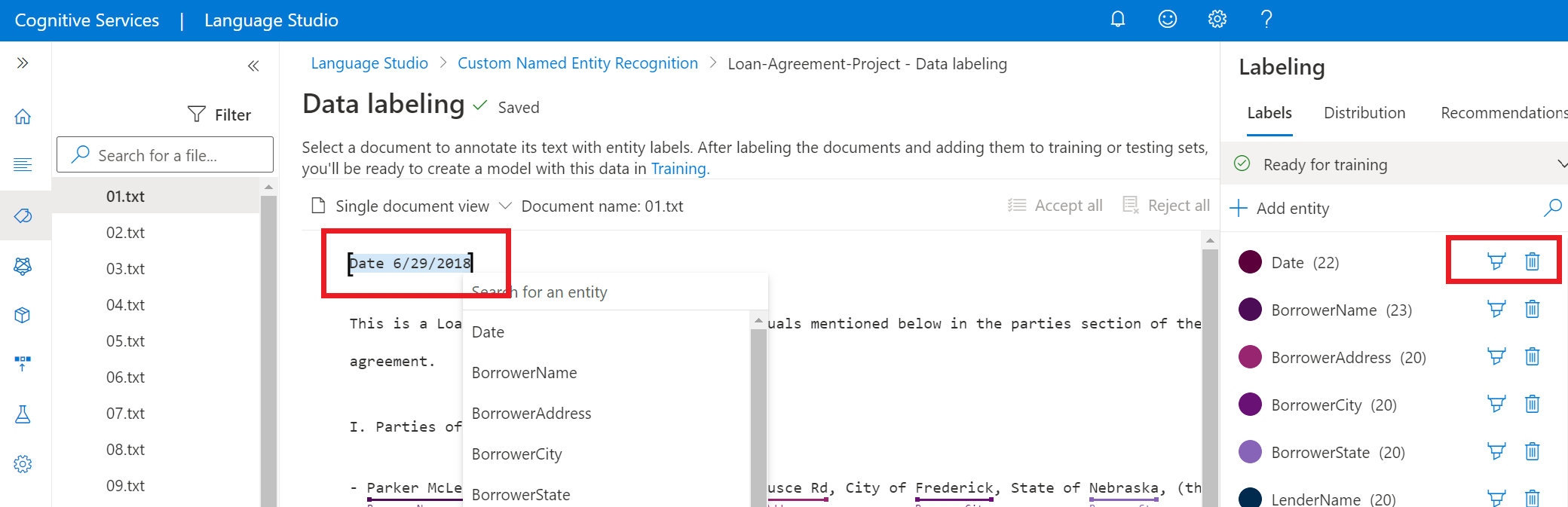
V pravém bočním podokně v pivotu Popisky najdete všechny typy entit v projektu a počet označených instancí na každý z nich.
V dolní části pravého bočního podokna můžete přidat aktuální dokument, který si prohlížíte, do trénovací sady nebo testovací sady. Ve výchozím nastavení se do trénovací sady přidají všechny dokumenty. Přečtěte si další informace o trénovacích a testovacích sadách a o tom, jak se používají k trénování a vyhodnocování modelů.
Tip
Pokud plánujete používat automatické rozdělení dat, použijte výchozí možnost přiřazení všech dokumentů do trénovací sady.
V pivotu Distribuce můžete zobrazit distribuci napříč trénovacími a testovacími sadami. Máte dvě možnosti zobrazení:
- Celkový počet instancí , ve kterých můžete zobrazit počet všech označených instancí určitého typu entity.
- dokumenty s alespoň jedním popiskem , kde se každý dokument počítá, pokud obsahuje aspoň jednu označenou instanci této entity.
Když popisky označíte, změny se budou pravidelně synchronizovat, pokud ještě nebyly uloženy, zobrazí se v horní části stránky upozornění. Pokud chcete uložit ručně, vyberte tlačítko Uložit štítky v dolní části stránky.

Odebrání popisků
Odebrání popisku
- Vyberte entitu, ze které chcete odebrat popisek.
- Procházejte zobrazenou nabídku a vyberte Odebrat popisek.
Odstranění entit
Pokud chcete entitu odstranit, vyberte ikonu odstranění vedle entity, kterou chcete odebrat. Odstraněním entity odeberete všechny její označené instance z vaší datové sady.
Další kroky
Po označení dat můžete začít trénovat model , který se naučí na základě vašich dat.