Vlastní modely Document Intelligence
Tento obsah se vztahuje na: ![]() v4.0 (GA) | Předchozí verze:
v4.0 (GA) | Předchozí verze:![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
::: moniker-end
Tento obsah se vztahuje na: ![]() v2.1 | Nejnovější verze:
v2.1 | Nejnovější verze: ![]() v4.0 (GA)
v4.0 (GA)
Funkce Document Intelligence používá pokročilou technologii strojového učení k identifikaci dokumentů, detekci a extrakci informací z formulářů a dokumentů a vrácení extrahovaných dat ve strukturovaném výstupu JSON. Pomocí funkce Document Intelligence můžete použít modely analýzy dokumentů, předem připravené nebo předem natrénované nebo vytrénované samostatné vlastní modely.
Vlastní modely teď zahrnují vlastní klasifikační modely pro scénáře, ve kterých potřebujete před vyvoláním modelu extrakce identifikovat typ dokumentu. Klasifikátorové modely jsou k dispozici od 2023-07-31 (GA) rozhraní API. Klasifikační model je možné spárovat s vlastním modelem extrakce a analyzovat a extrahovat pole z formulářů a dokumentů specifických pro vaši firmu. Samostatné vlastní modely extrakce je možné kombinovat a vytvářet složené modely.
Vlastní typy modelů dokumentů
Vlastní modely dokumentů můžou být jedním ze dvou typů, vlastní šablonou nebo vlastním formulářem a vlastními neurálními nebo vlastními modely dokumentů. Proces označování a trénování pro oba modely je stejný, ale modely se liší následujícím způsobem:
Vlastní modely extrakce
Pokud chcete vytvořit vlastní model extrakce, označte datovou sadu dokumentů hodnotami, které chcete extrahovat, a vytrénujte model na označené datové sadě. Abyste mohli začít, potřebujete jenom pět příkladů stejného formuláře nebo typu dokumentu.
Vlastní neurální model
Důležité
Rozhraní Document Intelligence v4.0 2024-11-30 (GA) API podporuje vlastní neurální model překrývající se pole, detekci podpisu a tabulku, spolehlivost na úrovni řádků a buněk.
Vlastní neurální (vlastní dokument) model používá modely hlubokého učení a základní model natrénovaný na velké kolekci dokumentů. Při trénování modelu s označenou datovou sadou se pak tento model doladí nebo přizpůsobí vašim datům. Vlastní neurální modely podporují extrakci klíčových datových polí ze strukturovaných, částečně strukturovaných a nestrukturovaných dokumentů. Při výběru mezi těmito dvěma typy modelů začněte neurálním modelem, abyste zjistili, jestli vyhovuje vašim funkčním potřebám. Další informace o vlastních modelech dokumentů najdete v neurálních modelech .
Vlastní model šablony
Vlastní šablona nebo vlastní model formuláře závisí na konzistentní vizuální šabloně k extrahování označených dat. Odchylky ve vizuální struktuře dokumentů ovlivňují přesnost modelu. Strukturované formuláře, jako jsou dotazníky nebo aplikace, jsou příklady konzistentních vizuálních šablon.
Trénovací sada se skládá ze strukturovaných dokumentů, kde je formátování a rozložení statické a konstantní z jedné instance dokumentu na další. Vlastní modely šablon podporují páry klíč-hodnota, značky výběru, tabulky, pole podpisu a oblasti. Modely šablon a lze je trénovat na dokumentech v libovolném podporovaném jazyce. Další informace najdete v tématu Vlastní modely šablon.
Pokud jazyk dokumentů a scénářů extrakce podporuje vlastní neurální modely, doporučujeme pro vyšší přesnost používat vlastní neurální modely.
Tip
Chcete-li potvrdit, že vaše školicí dokumenty představují konzistentní vizuální šablonu, odeberte všechna uživatelsky zadaná data z každého formuláře v sadě. Pokud jsou prázdné formuláře identické ve vzhledu, představují konzistentní vizuální šablonu.
Další informace najdete v tématu Interpretace a zlepšení přesnosti a spolehlivosti pro vlastní modely.
Požadavky na vstup
Nejlepšíchvýsledkůch
Podporované formáty souborů:
Model PDF Obrázek: jpeg/jpg,png,bmp,tiff,heifsystém Microsoft Office:
Word (docx), Excel (xlsx), PowerPoint (pptx)Čteno ✔ ✔ ✔ Rozložení ✔ ✔ ✔ Obecný dokument ✔ ✔ Předpřipravený ✔ ✔ Vlastní extrakce ✔ ✔ Vlastní klasifikace ✔ ✔ ✔ ✱ systém Microsoft Office soubory nejsou v současné době podporovány pro jiné modely nebo verze.
U SOUBORŮ PDF a TIFF je možné zpracovat až 2 000 stránek (s předplatným úrovně Free se zpracuje pouze první dvě stránky).
Velikost souboru pro analýzu dokumentů je 500 MB pro placenou úroveň (S0) a 4 MB pro bezplatnou úroveň (F0).
Rozměry obrázku musí být mezi 50 x 50 pixelů a 10 000 px x 10 000 pixelů.
Pokud jsou soubory PDF uzamčené heslem, musíte před odesláním toto uzamčení odebrat.
Minimální výška extrahovaného textu je 12 pixelů pro obrázek o velikosti 1024 x 768 pixelů. Tato dimenze odpovídá hodnotě
8-point text v 150 bodech na paleč.Pro trénování vlastního modelu je maximální počet stránek pro trénovací data 500 pro vlastní model šablony a 50 000 pro vlastní neurální model.
Pro trénování vlastního modelu extrakce je celková velikost trénovacích dat 50 MB pro model šablony a 1G MB pro neurální model.
Pro trénování modelu vlastní klasifikace je
1GBcelková velikost trénovacích dat s maximálně 10 000 stránkami.
Optimální trénovací data
Trénovací vstupní data jsou základem jakéhokoli modelu strojového učení. Určuje kvalitu, přesnost a výkon modelu. Proto je důležité vytvořit nejlepší trénovací vstupní data, která jsou pro váš projekt Document Intelligence možná. Při použití vlastního modelu Document Intelligence poskytujete vlastní trénovací data. Tady je několik tipů, které vám pomůžou efektivně trénovat modely:
Pokud je to možné, používejte místo souborů PDF založených na obrázku text. Jedním ze způsobů, jak identifikovat soubor PDF založený na obrázku, je zkusit vybrat konkrétní text v dokumentu. Pokud můžete vybrat jenom celý obrázek textu, dokument je založený na obrázku, nikoli na textu.
Uspořádejte trénovací dokumenty pomocí podsložky pro každý formát (JPEG/JPG, PNG, BMP, PDF nebo TIFF).
Použijte formuláře, které mají dokončená všechna dostupná pole.
V každém poli používejte formuláře s odlišnými hodnotami.
Pokud jsou vaše obrázky nízké kvality, použijte větší datovou sadu (více než pět trénovacích dokumentů).
Určete, jestli potřebujete použít jeden nebo více modelů složených do jednoho modelu.
Zvažte segmentování datové sady do složek, kde každá složka představuje jedinečnou šablonu. Vytrénujte jeden model na složku a vytvořte výsledné modely do jednoho koncového bodu. Přesnost modelu se může snížit, pokud máte různé formáty analyzované pomocí jednoho modelu.
Pokud má formulář varianty formátů a konců stránek, zvažte segmentaci datové sady a natrénování více modelů. Vlastní formuláře spoléhají na konzistentní šablonu vizuálu.
Ujistěte se, že máte vyváženou datovou sadu díky tomu, že se započítávání formátů, typů dokumentů a struktury.
Režim sestavení
Operace build custom model přidává podporu pro šablony a neurální vlastní modely. Předchozí verze rozhraní REST API a klientských knihoven podporovaly pouze jeden režim sestavení, který se teď označuje jako režim šablony .
Modely šablon přijímají pouze dokumenty, které mají stejnou základní strukturu stránky – jednotný vzhled vizuálu – nebo stejné relativní umístění prvků v dokumentu.
Neurální modely podporují dokumenty, které mají stejné informace, ale různé struktury stránek. Příklady těchto dokumentů zahrnují formuláře USA W2, které sdílejí stejné informace, ale liší se ve vzhledu napříč společnostmi.
Tato tabulka obsahuje odkazy na odkazy na sadu SDK programovacího jazyka buildu a ukázky kódu na GitHubu:
| Programovací jazyk | Referenční informace k sadě SDK | Ukázka kódu |
|---|---|---|
| C#/.NET | DocumentBuildMode – struktura | Sample_BuildCustomModelAsync.cs |
| Java | DocumentBuildMode – třída | BuildModel.java |
| JavaScript | Typ DocumentBuildMode | buildModel.js |
| Python | DocumentBuildMode – výčet | sample_build_model.py |
Porovnání funkcí modelu
Následující tabulka porovnává vlastní šablony a vlastní neurální funkce:
| Funkce | Vlastní šablona (formulář) | Vlastní neurální (dokument) |
|---|---|---|
| Struktura dokumentu | Šablona, formulář a strukturovaná | Strukturovaná, částečně strukturovaná a nestrukturovaná |
| Doba trénování | 1 až 5 minut | 20 minut až 1 hodina |
| Extrakce dat | Páry klíč-hodnota, tabulky, značky výběru, souřadnice a podpisy | Páry klíč-hodnota, značky výběru a tabulky |
| Překrývající se pole | Nepodporováno | Podporováno |
| Varianty dokumentů | Vyžaduje model pro každou variantu. | Používá jeden model pro všechny varianty. |
| Podpora jazyků | Vlastní šablona podpory jazyka | Podpora jazyka – vlastní neurální |
Vlastní klasifikační model
Klasifikace dokumentů je nový scénář podporovaný funkcí Document Intelligence s rozhraním 2023-07-31 API (ga verze 3.1). Rozhraní API klasifikátoru dokumentů podporuje scénáře klasifikace a rozdělení. Trénování klasifikačního modelu pro identifikaci různých typů dokumentů, které vaše aplikace podporuje. Vstupní soubor klasifikačního modelu může obsahovat více dokumentů a klasifikuje každý dokument v přidruženém rozsahu stránek. Další informace najdete v modelech vlastní klasifikace .
Poznámka:
Model v4.0 2024-11-30 (GA) klasifikace dokumentů podporuje typy dokumentů Office pro klasifikaci. Tato verze rozhraní API také zavádí přírůstkové trénování klasifikačního modelu.
Vlastní nástroje modelu
Modely Document Intelligence verze 3.1 a novější podporují následující nástroje, aplikace a knihovny, programy a knihovny:
| Funkce | Zdroje informací | ID modelu |
|---|---|---|
| Vlastní model | • Document Intelligence Studio • REST API • Sada C# SDK • Python SDK |
custom-model-id |
Životní cyklus vlastního modelu
Životní cyklus vlastního modelu závisí na verzi rozhraní API, která se používá k jeho trénování. Pokud je verze rozhraní API obecná dostupnost (GA), má vlastní model stejný životní cyklus jako tato verze. Vlastní model není k dispozici pro odvozování, když je verze rozhraní API zastaralá. Pokud je verze rozhraní API verze Preview, má vlastní model stejný životní cyklus jako verze Preview rozhraní API.
Document Intelligence v2.1 podporuje následující nástroje, aplikace a knihovny:
Poznámka:
Vlastní typy modelů vlastní neurální a vlastní šablona jsou k dispozici s rozhraními API Document Intelligence verze 3.1 a v3.0.
| Funkce | Zdroje informací |
|---|---|
| Vlastní model | • Nástroj pro popisování document intelligence• ROZHRANÍ REST API • Sada SDK klientské knihovny• Kontejner Document Intelligence Dockeru |
Vytvoření vlastního modelu
Extrahujte data z konkrétních nebo jedinečných dokumentů pomocí vlastních modelů. Potřebujete následující zdroje informací:
Předplatné Azure. Můžete si ho zdarma vytvořit.
Instance Document Intelligence na webu Azure Portal K vyzkoušení služby můžete použít cenovou úroveň Free (
F0). Po nasazení prostředku vyberte Přejít k prostředku a získejte klíč a koncový bod.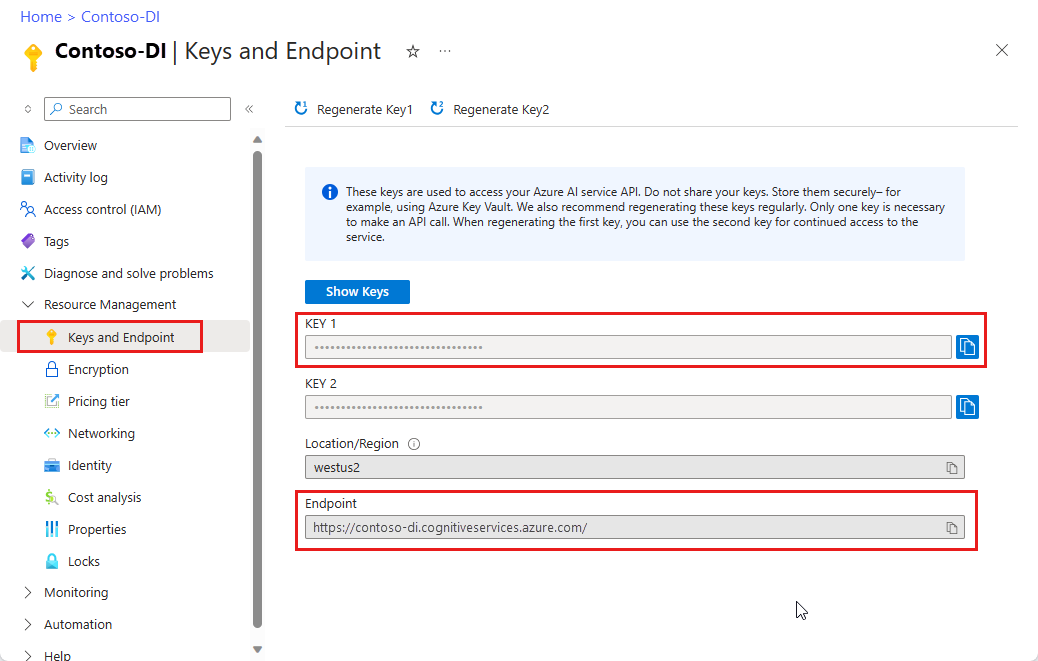
Ukázkový nástroj popisování
Tip
- Pro vylepšené prostředí a pokročilou kvalitu modelu vyzkoušejte sadu Document Intelligence v3.0 Studio.
- Sada v3.0 Studio podporuje jakýkoli model natrénovaný s daty označenými v2.1.
- Podrobné informace o migraci z verze 2.1 na verzi 3.0 najdete v průvodci migrací rozhraní API.
- Podívejte se na naše rozhraní REST API nebo C#, Java, JavaScript nebo Python SDK. /quickstarts to get started with the v3.0 version.
Nástroj Document Intelligence Sample Labeling je opensourcový nástroj, který umožňuje testovat nejnovější funkce funkcí Document Intelligence a Optické rozpoznávání znaků (OCR).
Vyzkoušejte rychlý start s ukázkovým nástrojem popisování, abyste mohli začít sestavovat a používat vlastní model.
Document Intelligence Studio
Poznámka:
Document Intelligence Studio je k dispozici s rozhraními API v3.1 a v3.0.
Na domovské stránce nástroje Document Intelligence Studio vyberte Vlastní modely extrakce.
V části Moje projekty vyberte Vytvořit projekt.
Vyplňte pole podrobností projektu.
Nakonfigurujte prostředek služby přidáním účtu úložiště a kontejneru objektů blob pro připojení trénovacího zdroje dat.
Zkontrolujte a vytvořte projekt.
Přidejte ukázkové dokumenty k označení, sestavení a otestování vlastního modelu.
Podrobný návod k vytvoření prvního vlastního modelu extrakce najdete v tématu Vytvoření vlastního modelu extrakce.
Souhrn extrakce vlastních modelů
Tato tabulka porovnává podporované oblasti extrakce dat:
| Model | Pole formuláře | Značky výběru | Strukturovaná pole (tabulky) | Podpis | Popisování oblastí | Překrývající se pole |
|---|---|---|---|---|---|---|
| Vlastní šablona | ✔ | ✔ | ✔ | ✔ | ✔ | není k dispozici |
| Vlastní neurální | ✔ | ✔ | ✔ | ✔ | * | ✔ |
Symboly tabulky:
✔ – Podporováno
**n/a – momentálně není k dispozici;
*-Chová se jinak v závislosti na modelu. U modelů šablon se syntetická data generují v době trénování. U neurálních modelů je vybráno ukončení textu rozpoznané v oblasti.
Tip
Při výběru mezi těmito dvěma typy modelů začněte vlastním neurálním modelem, pokud vyhovuje vašim funkčním potřebám. Další informace o vlastních neurálních modelech najdete v neurálních modelech.
Možnosti vývoje vlastních modelů
Následující tabulka popisuje funkce dostupné v přidružených nástrojích a klientských knihovnách. Osvědčeným postupem je zajistit, abyste používali kompatibilní nástroje uvedené tady.
| Typ dokumentu | REST API | Sada SDK | Popisky a testovací modely |
|---|---|---|---|
| Vlastní šablona v 4.0 v3.1 v3.0 | Funkce Document Intelligence 3.1 | Document Intelligence SDK | Document Intelligence Studio |
| Vlastní neurální v4.0 v3.1 v3.0 | Funkce Document Intelligence 3.1 | Document Intelligence SDK | Document Intelligence Studio |
| Vlastní formulář v2.1 | Document Intelligence 2.1 GA API | Document Intelligence SDK | Ukázkový nástroj pro popisování |
Poznámka:
Vlastní modely šablon natrénované pomocí rozhraní API 3.0 budou mít několik vylepšení oproti rozhraní API 2.1, které vychází z vylepšení modulu OCR. Datové sady používané k trénování vlastního modelu šablony pomocí rozhraní API 2.1 je stále možné použít k trénování nového modelu pomocí rozhraní API verze 3.0.
Nejlepšíchvýsledkůch
Podporované formáty souborů jsou JPEG/JPG, PNG, BMP, TIFF a PDF (vložené nebo naskenované texty). Soubory PDF s vloženým textem jsou nejvhodnější pro eliminaci možných chyb při extrakci a umístění znaků.
U souborů PDF a TIFF je možné zpracovat až 2 000 stránek. S předplatným úrovně Free se zpracovávají pouze první dvě stránky.
Velikost souboru musí být menší než 500 MB pro placenou úroveň (S0) a 4 MB pro bezplatnou úroveň (F0).
Rozměry obrázku musí být v rozmezí 50 × 50 až 10 000 × 10 000 pixelů.
Rozměry PDF jsou až 17 x 17 palců, odpovídající formátu papíru Legal nebo A3 nebo menší.
Celková velikost trénovacích dat je 500 stránek nebo méně.
Pokud jsou soubory PDF uzamčené heslem, musíte před odesláním toto uzamčení odebrat.
Tip
Trénovací data:
- Pokud je to možné, místo obrázkových dokumentů používejte textové dokumenty PDF. Naskenované dokumenty PDF se zpracovávají jako obrázky.
- Zadejte pouze jednu instanci formuláře pro každý dokument.
- U vyplněných formulářů použijte příklady, které mají vyplněná všechna pole.
- Používejte formuláře s různými hodnotami v každém poli.
- Pokud mají obrázky formulářů nižší kvalitu, použijte větší datovou sadu. Použijte například 10 až 15 obrázků.
Podporované jazyky a národní prostředí
Úplný seznam podporovaných jazyků najdete na naší stránce podpory jazyků – vlastní modely .
Další kroky
Zkuste zpracovat vlastní formuláře a dokumenty pomocí nástroje Document Intelligence Sample Labeling.
Dokončete rychlý start s funkcí Document Intelligence a začněte vytvářet aplikaci pro zpracování dokumentů ve zvoleném vývojovém jazyce.
Zkuste pomocí nástroje Document Intelligence Studio zpracovat vlastní formuláře a dokumenty.
Dokončete rychlý start s funkcí Document Intelligence a začněte vytvářet aplikaci pro zpracování dokumentů ve zvoleném vývojovém jazyce.