Použití poznámkových bloků Jupyter v Nástroji Azure Data Studio
Důležitý
Azure Data Studio se vyřazuje 28. února 2026. Doporučujeme používat Visual Studio Code. Další informace o migraci do editoru Visual Studio Code najdete v tématu Co se děje se sadou Azure Data Studio?
Platí pro:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Jupyter Notebook je opensourcová webová aplikace, která umožňuje vytvářet a sdílet dokumenty obsahující živý kód, rovnice, vizualizace a text vyprávění. Použití zahrnuje čištění a transformaci dat, číselnou simulaci, statistické modelování, vizualizaci dat a strojové učení.
Tento článek popisuje, jak vytvořit nový poznámkový blok v nejnovější verzi nástroje Azure Data Studio a jak začít vytvářet vlastní poznámkové bloky pomocí různých jader.
Podívejte se na toto krátké 5minutové video s úvodem k poznámkovým blokům v Nástroji Azure Data Studio:
Vytvoření poznámkového bloku
Existuje několik způsobů, jak vytvořit nový poznámkový blok. V každém případě se otevře nový soubor s názvem Notebook-1.ipynb .
Přejděte do nabídky Soubor v Nástroji Azure Data Studio a vyberte Nový poznámkový blok.
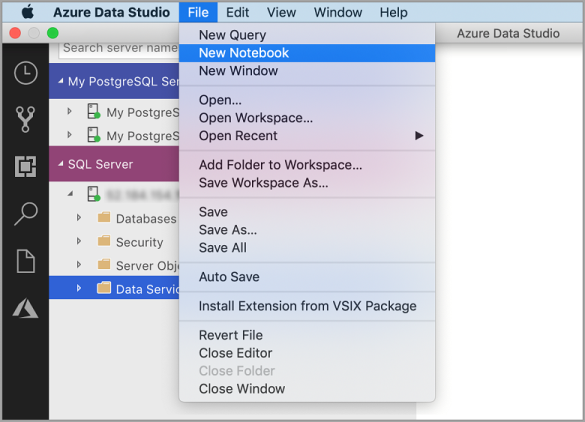
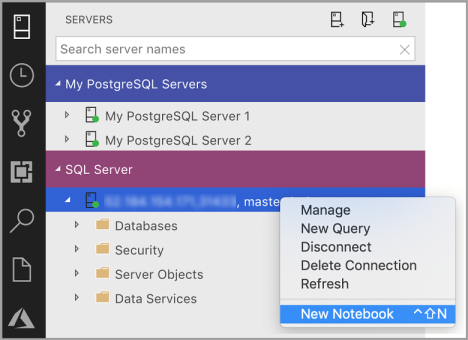
Klikněte pravým tlačítkem na připojení k SQL Serveru a vyberte Nový poznámkový blok.
Otevřete paletu příkazů (Ctrl+Shift+P), zadejte nový poznámkový blok a vyberte příkaz Nový poznámkový blok .

Připojení k jádru
Poznámkové bloky Azure Data Studio podporují řadu různých jader, včetně SQL Serveru, Pythonu, PySparku a dalších. Každé jádro podporuje jiný jazyk v buňkách kódu poznámkového bloku. Například při připojení k jádru SQL Serveru můžete do buňky kódu poznámkového bloku zadat a spustit příkazy T-SQL.
Připojte k němu kontext jádra. Pokud například používáte jádro SQL, můžete se připojit k libovolné instanci SQL Serveru. Pokud používáte jádro Python3, které připojíte k místnímu hostiteli , a toto jádro můžete použít pro místní vývoj v Pythonu.
Jádro SQL se dá použít také k připojení k instancím serveru PostgreSQL. Pokud jste vývojář PostgreSQL a chcete připojit poznámkové bloky k serveru PostgreSQL, stáhněte si rozšíření PostgreSQL na Marketplace rozšíření Azure Data Studio a připojte se k serveru PostgreSQL.
Pokud jste připojení ke clusteru s velkými objemy dat SQL Serveru 2019, je výchozím bodem clusteru připojení koncový bod. Kód Pythonu, Scala a R můžete odeslat pomocí výpočetních prostředků Sparku clusteru.
| jádro | Popis |
|---|---|
| Jádro SQL | Napište kód SQL určený pro relační databázi. |
| Jádro PySpark3 a PySpark | Napište kód Pythonu pomocí výpočetních prostředků Sparku z clusteru. |
| Jádro Sparku | Napište kód Scala a R pomocí výpočetních prostředků Sparku z clusteru. |
| Jádro Pythonu | Napište kód Pythonu pro místní vývoj. |
Další informace o konkrétních jádrech najdete tady:
- Vytvoření a spuštění poznámkového bloku SQL Serveru
- Vytvoření a spuštění poznámkového bloku Pythonu
- Rozšíření Kqlmagic v Nástroji Azure Data Studio – rozšiřuje možnosti jádra Pythonu.
Přidání buňky kódu
Buňky kódu umožňují interaktivně spouštět kód v poznámkovém bloku.
Novou buňku kódu přidáte kliknutím na příkaz +Buňka na panelu nástrojů a výběrem buňky Kód. Za aktuálně vybranou buňku se přidá nová buňka kódu.
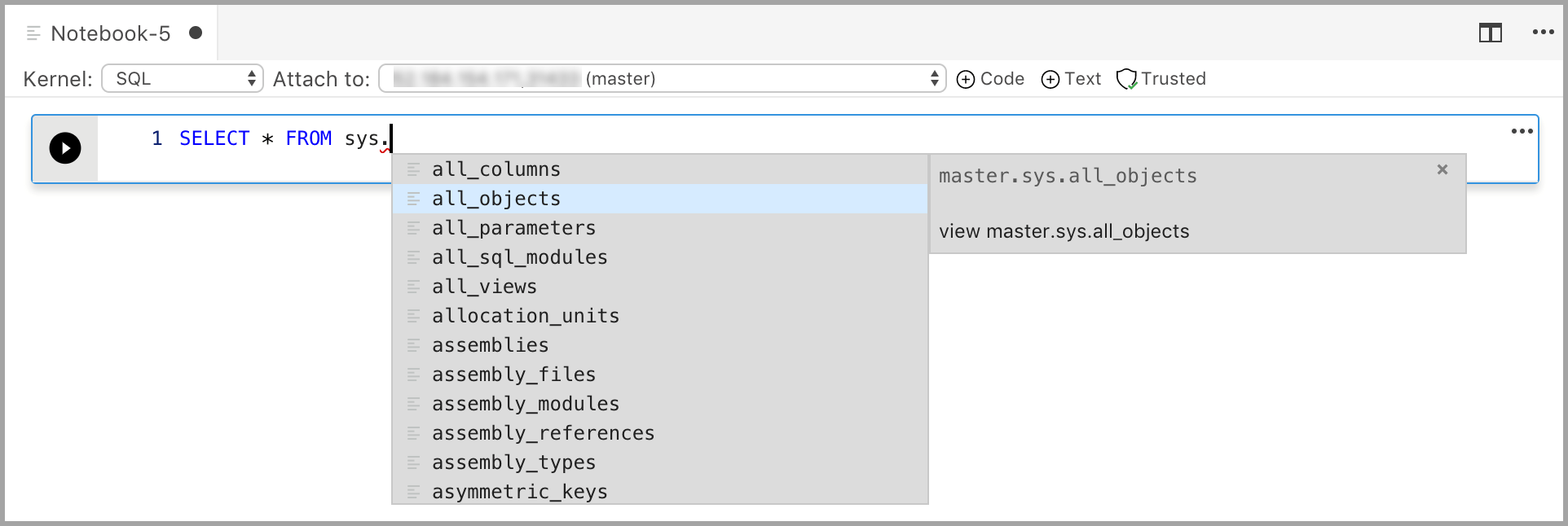
Zadejte kód do buňky pro vybrané jádro. Pokud například používáte jádro SQL, můžete do buňky kódu zadat příkazy T-SQL.
Zadávání kódu s jádrem SQL se podobá editoru dotazů SQL. Buňka kódu podporuje moderní prostředí pro kódování SQL s integrovanými funkcemi, jako je bohatý editor SQL, IntelliSense a integrované fragmenty kódu. Fragmenty kódu umožňují vygenerovat správnou syntaxi SQL pro vytváření databází, tabulek, zobrazení, uložených procedur a aktualizaci existujících databázových objektů. Pomocí fragmentů kódu můžete rychle vytvářet kopie databáze pro účely vývoje nebo testování a generovat a spouštět skripty.
Přidání textové buňky
Textové buňky umožňují dokumentovat kód přidáním textových bloků Markdownu mezi buňky kódu.
Kliknutím na příkaz +Buňka na panelu nástrojů a výběrem textové buňky přidejte novou textovou buňku.
Buňka se spustí v režimu úprav, ve kterém můžete zadat text Markdownu. Při psaní se níže zobrazí náhled.
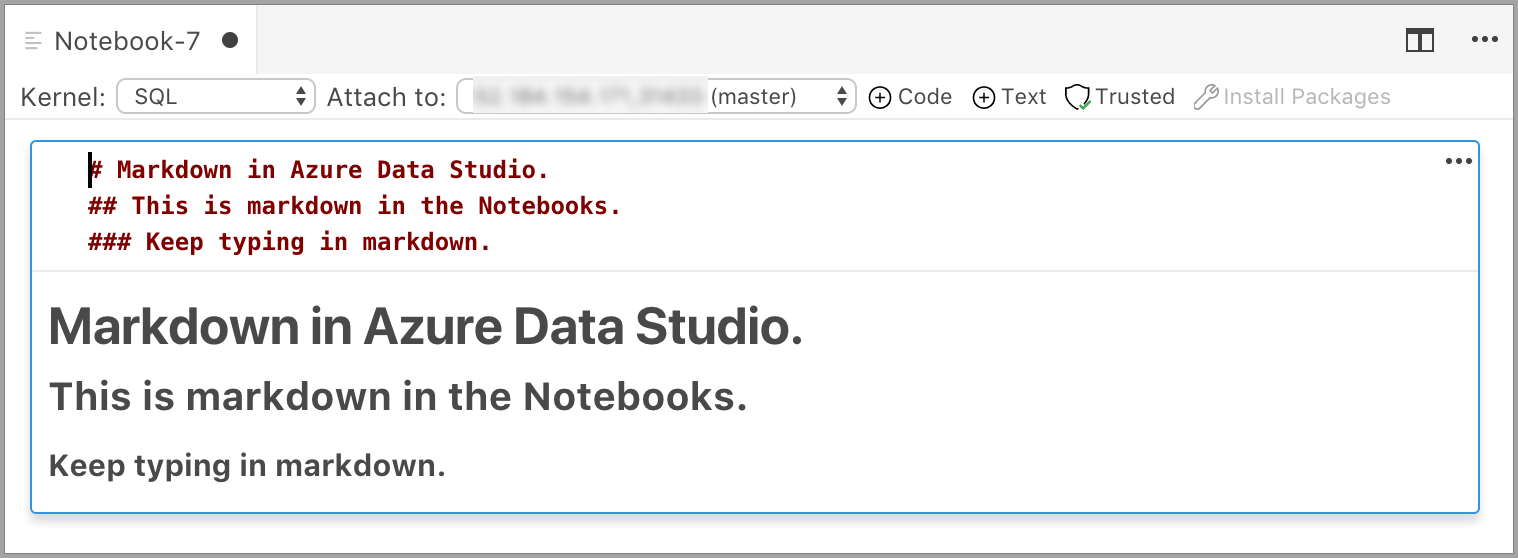
Výběrem mimo text v buňce se zobrazí text Markdownu.
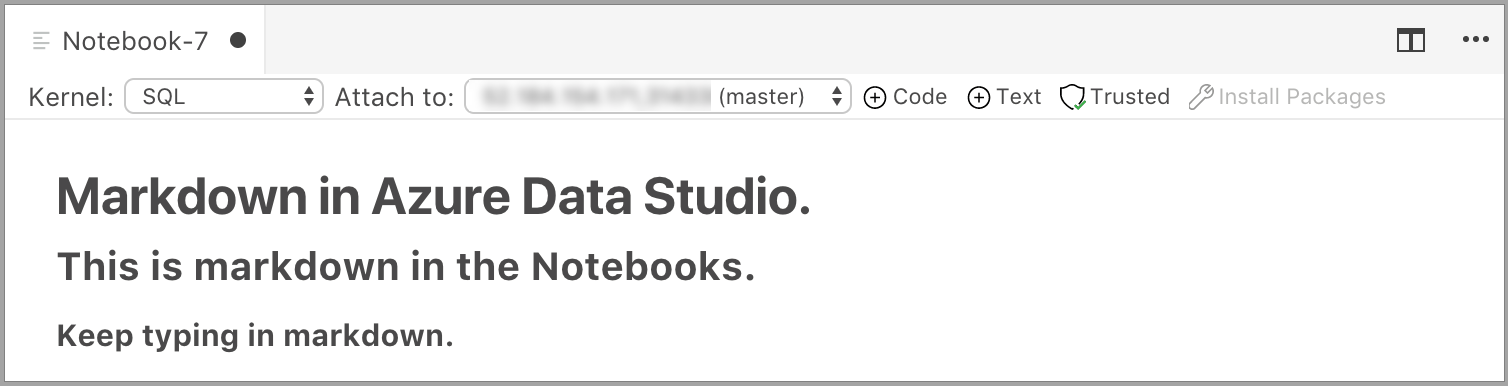
Pokud v textové buňce znovu kliknete, změní se režim úprav.
Spuštění buňky
Pokud chcete spustit jednu buňku, klikněte na Spustit buňku (kruhová černá šipka) vlevo od buňky nebo vyberte buňku a stiskněte klávesu F5. Kliknutím na Tlačítko Spustit vše na panelu nástrojů můžete spustit všechny buňky v poznámkovém bloku – buňky se spustí po jednom a provádění se zastaví, pokud dojde k chybě v buňce.
Výsledky z buňky jsou zobrazeny pod buňkou. Výsledky všech spuštěných buněk v poznámkovém bloku můžete vymazat výběrem tlačítka Vymazat výsledky na panelu nástrojů.
Uložení poznámkového bloku
Pokud chcete poznámkový blok uložit, udělejte jednu z následujících věcí.
- Zadejte Ctrl+S.
- V nabídce Soubor vyberte Uložit.
- V nabídce Soubor vyberte Uložit jako...
- V nabídce Soubor vyberte Uložit vše– tím se uloží všechny otevřené poznámkové bloky.
- Do palety příkazů zadejte Soubor: Uložit.
Poznámkové bloky se ukládají jako .ipynb soubory.
Důvěryhodné a nedůvěryhodné
Poznámkové bloky otevřené v nástroji Azure Data Studio jsou ve výchozím nastavení důvěryhodné.
Pokud otevřete poznámkový blok z jiného zdroje, otevře se v nedůvěryhodném režimu a pak ho můžete nastavit jako důvěryhodný.
Příklady
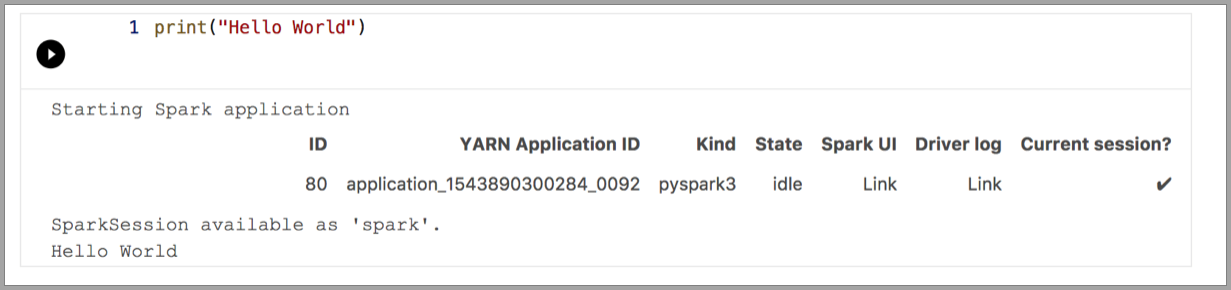
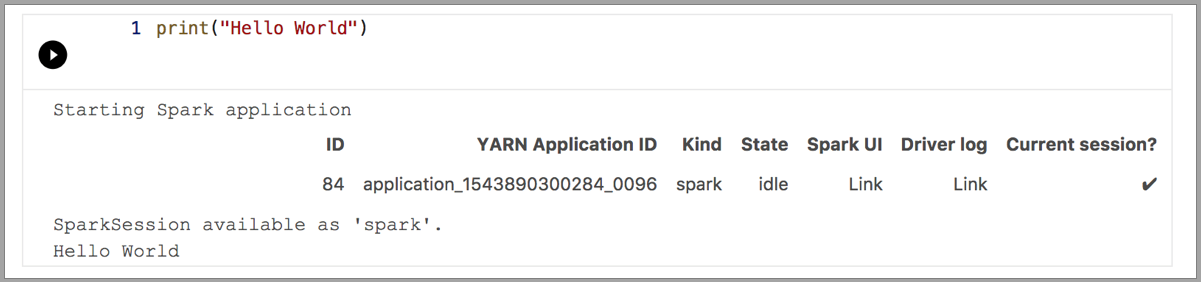
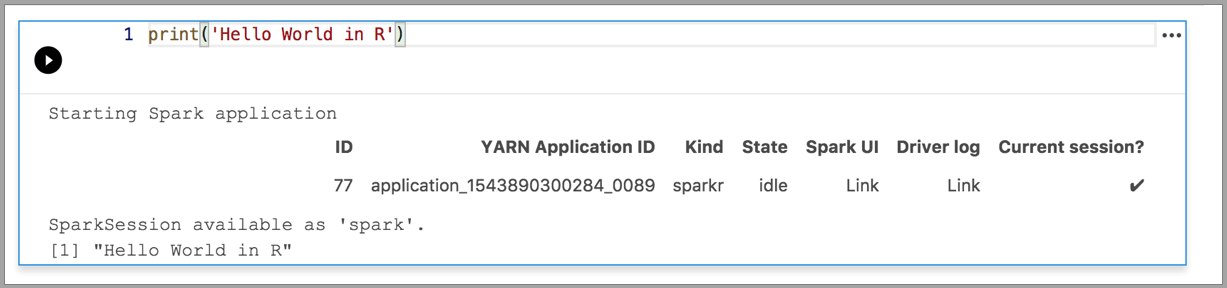
Následující příklady ukazují použití různých jader ke spuštění jednoduchého příkazu Hello World. Vyberte jádro, zadejte ukázkový kód do buňky a klikněte na Spustit buňku.
Pyspark
Spark | Jazyk Scala
Spark | Jazyk R
a Pythonu 3

Další kroky
- Vytvořte a spusťte poznámkový blok SQL Serveru.
- Vytvoření a spuštění poznámkového bloku Pythonu
- Spouštět skripty Pythonu a R v poznámkových blocích Azure Data Studio se službou SQL Server Machine Learning Services
- Nasazení clusteru s velkými objemy dat SQL Serveru pomocí poznámkového bloku Azure Data Studio
- Správa SQL Serveru clustery pro velký objem dat pomocí poznámkových bloků Azure Data Studio
- Spusťte ukázkový poznámkový blok pomocí Sparku.