Strategie vývoje a nasazení databází (VB)
Při prvním nasazení aplikace řízené daty můžete naslepo zkopírovat databázi ve vývojovém prostředí do produkčního prostředí. Provedení slepé kopie v následných nasazeních ale přepíše všechna data zadaná do produkční databáze. Nasazení databáze místo toho zahrnuje použití změn provedených ve vývojové databázi od posledního nasazení do produkční databáze. Tento kurz zkoumá tyto výzvy a nabízí různé strategie, které vám pomůžou s kronikou a použitím změn provedených v databázi od posledního nasazení.
Úvod
Jak bylo popsáno v předchozích kurzech, nasazení aplikace ASP.NET zahrnuje zkopírování příslušného obsahu z vývojového prostředí do produkčního prostředí. Nasazení není jednorázová událost, ale spíše něco, co se stane při každém vydání nové verze softwaru nebo při zjištění a vyřešení chyb nebo problémů se zabezpečením. Při kopírování ASP.NET stránek, obrázků, souborů JavaScriptu a dalších takových souborů do produkčního prostředí se nemusíte zabývat tím, jak se tyto soubory od posledního nasazení změnily. Soubor můžete slepě zkopírovat do produkčního prostředí a přepíšete existující obsah. Tato jednoduchost se bohužel nevztahuje na nasazení databáze.
Při prvním nasazení aplikace řízené daty můžete naslepo zkopírovat databázi ve vývojovém prostředí do produkčního prostředí. Provedení slepé kopie v následných nasazeních ale přepíše všechna data zadaná do produkční databáze. Nasazení databáze místo toho zahrnuje použití změn provedených ve vývojové databázi od posledního nasazení do produkční databáze. Tento kurz zkoumá tyto výzvy a nabízí různé strategie, které vám pomůžou s kronikou a použitím změn provedených v databázi od posledního nasazení.
Výzvy spojené s nasazením databáze
Před prvním nasazením aplikace řízené daty existuje pouze jedna databáze, a to databáze ve vývojovém prostředí, což je důvod, proč při prvním nasazení aplikace řízené daty můžete databázi ve vývojovém prostředí slepě zkopírovat do produkčního prostředí. Jakmile je ale aplikace nasazená, existují dvě kopie databáze: jedna ve vývoji a jedna v produkčním prostředí.
Mezi nasazeními můžou být vývojové a produkční databáze nesynchronní. I když schéma produkční databáze zůstává beze změny, může se při přidání nových funkcí změnit schéma vývojové databáze. Můžete přidávat nebo odebírat sloupce, tabulky, zobrazení nebo uložené procedury. Do vývojové databáze se také můžou přidávat důležitá data. Mnoho aplikací řízených daty zahrnuje vyhledávací tabulky naplněné pevně zakódovanými daty specifickými pro aplikaci, která není možné upravovat uživatelem. Web aukce může mít například rozevírací seznam s možnostmi, které popisují podmínku dražené položky: Nová, Lajk nová, Dobrá a Spravedlivá. Místo pevného kódování těchto možností přímo v rozevíracím seznamu je obvykle lepší je umístit do databázové tabulky. Pokud se během vývoje přidá do tabulky nová podmínka s názvem Poor, pak se při nasazování aplikace musí stejný záznam přidat do vyhledávací tabulky v produkční databázi.
V ideálním případě by nasazení databáze zahrnovalo zkopírování databáze z vývoje do produkčního prostředí. Mějte ale na paměti, že po nasazení aplikace a obnovení vývoje se produkční databáze naplní skutečnými daty od skutečných uživatelů. Pokud byste tedy při dalším nasazení jednoduše zkopírovali databázi z vývoje do produkčního prostředí, přepsali byste produkční databázi a ztratili by její stávající data. Výsledkem je, že nasazení databáze se omezuje na použití změn provedených ve vývojové databázi od posledního nasazení.
Vzhledem k tomu, že nasazení databáze zahrnuje použití změn ve schématu a případně dat od posledního nasazení, musí být historie změn zachována (nebo určena v době nasazení), aby bylo možné tyto změny použít v produkčním prostředí. Pro správu a použití změn datového modelu existuje celá řada technik.
Definování směrného plánu
Pokud chcete zachovat změny databáze aplikace, musíte mít nějaký počáteční stav, což je směrný plán, na který se změny použijí. V jednom extrémním počátečním stavu může být prázdná databáze bez tabulek, zobrazení nebo uložených procedur. Takový směrný plán má za následek velký protokol změn, protože musí zahrnovat vytvoření všech tabulek, zobrazení a uložených procedur databáze spolu se všemi změnami provedenými po počátečním nasazení. Na druhém konci spektra můžete nastavit směrný plán jako verzi databáze, která je původně nasazena do produkčního prostředí. Výsledkem této volby je mnohem menší protokol změn, protože zahrnuje pouze změny provedené v databázi po prvním nasazení. To je přístup, který dávám přednost. A samozřejmě můžete zvolit přístup, který je více uprostřed cesty, a definovat základní hodnoty jako určitý bod mezi počátečním vytvořením databáze a prvním nasazením databáze.
Jakmile zvolíte směrný plán, zvažte vygenerování skriptu SQL, který je možné spustit pro opětovné vytvoření základní verze. Takový skript umožňuje rychle znovu vytvořit základní verzi databáze. Tato funkce je obzvláště užitečná ve větších projektech, kde na projektu pracuje více vývojářů nebo v dalších prostředích, jako je testování nebo příprava, a každý z nich potřebuje vlastní kopii databáze.
Máte k dispozici celou řadu nástrojů pro generování skriptu SQL základní verze. V SQL Server Management Studio (SSMS) můžete kliknout pravým tlačítkem na databázi, přejít do podnabídky Úkoly a zvolit možnost Generovat skripty. Tím se spustí Průvodce skriptem, který vám dá pokyn k vygenerování souboru, který obsahuje příkazy SQL pro vytvoření objektů s databáze. Další možností je Průvodce publikováním databáze, který může vygenerovat příkazy SQL nejen pro vytvoření schématu databáze, ale také dat v databázových tabulkách. Průvodce publikováním databáze byl podrobně prozkoumán v kurzu Nasazení databáze . Bez ohledu na to, jaký nástroj použijete, byste nakonec měli mít soubor skriptu, který můžete použít k opětovnému vytvoření základní verze databáze, pokud to bude potřeba.
Dokumentace změn databáze v préce
Nejjednodušší způsob, jak během fáze vývoje udržovat protokol změn datového modelu, je zaznamenat změny v prázi. Pokud například během vývoje již nasazené aplikace přidáte do Employees tabulky nový sloupec, odeberete sloupec z Orders tabulky a přidáte novou tabulku (ProductCategories), zachováte textový soubor nebo dokument Microsoftu Word s následující historií:
| Změnit datum | Změnit podrobnosti |
|---|---|
| 2009-02-03: | Přidání sloupce DepartmentID (intNOT NULL) do Employees tabulky Přidání omezení cizího klíče z Departments.DepartmentID do Employees.DepartmentID. |
| 2009-02-05: | Odebrání sloupce TotalWeight z Orders tabulky Data už jsou zachycená v přidružených OrderDetails záznamech. |
| 2009-02-12: | Vytvořili jsme ProductCategories tabulku. Existují tři sloupce: (, , ), NOT NULLCategoryName (nvarchar(50), NOT NULL) a Active (bit, NOT NULL). IDENTITYintProductCategoryID Přidání omezení primárního klíče do ProductCategoryIDa výchozí hodnoty 1 do Active. |
Tento přístup má řadu nevýhod. Pro začátek neexistuje žádná naděje na automatizaci. Kdykoli je potřeba tyto změny použít v databázi – například při nasazení aplikace – musí vývojář ručně implementovat každou změnu, jednu po druhé. Kromě toho, pokud potřebujete rekonstruovat konkrétní verzi databáze ze směrného plánu pomocí protokolu změn, bude to trvat déle a déle s tím, jak se zvětšuje velikost protokolu. Další nevýhodou této metody je, že srozumitelnost a úroveň podrobností každé položky protokolu změn je ponechána osobě, která změnu zaznamenává. V týmu s více vývojáři můžou někteří vytvářet podrobnější, čitelnější nebo přesnější záznamy než jiní. Jsou také možné překlepy a další chyby při zadávání dat související s člověkem.
Hlavní výhodou dokumentování změn databáze v prázi je jednoduchost. K vytváření a změnám databázových objektů nepotřebujete znalost syntaxe SQL. Místo toho můžete zaznamenat změny v prází a implementovat je prostřednictvím grafického uživatelského rozhraní SQL Server Management Studio s.
Udržování protokolu změn v prose není jistě příliš sofistikované a nebude dobře fungovat u určitých projektů, jako jsou projekty, které mají velký rozsah, mají časté změny datového modelu nebo zahrnují více vývojářů. Ale viděl jsem, že tento přístup funguje docela dobře v malých, jednočlenných projektech, které mají jen občas změny datového modelu a kde samostatný vývojář nemá silné zkušenosti se syntaxí SQL pro vytváření a změny databázových objektů.
Poznámka
I když jsou informace v protokolu změn technicky potřeba pouze do doby nasazení, doporučujeme uchovávat historii změn. Ale místo udržování jediného neustále se rozšiřujícího souboru protokolu změn zvažte použití jiného souboru protokolu změn pro každou verzi databáze. Obvykle budete chtít mít verzi databáze při každém nasazení. Díky údržbě protokolu změn můžete počínaje standardními hodnotami znovu vytvořit libovolnou verzi databáze spuštěním skriptů protokolu změn od verze 1 a pokračovat, dokud nedosáhnete verze, kterou potřebujete znovu vytvořit.
Záznam příkazů ZMĚN SQL
Hlavní nevýhodou údržby zápisu změn v prázi je nedostatečná automatizace. V ideálním případě by implementace změn databáze v produkční databázi v době nasazení byla stejně snadná jako kliknutí na tlačítko pro spuštění skriptu, a nemuselo by se ručně provádět seznam pokynů. Tato automatizace je možná udržováním protokolu změn, který obsahuje příkazy SQL používané ke změně datového modelu.
Syntaxe SQL obsahuje řadu příkazů pro vytváření a úpravy různých databázových objektů. Například příkaz CREATE TABLE při spuštění vytvoří novou tabulku se zadanými sloupci a omezeními. Příkaz ALTER TABLE upraví existující tabulku, přidá, odebere nebo upraví její sloupce nebo omezení. Existují také příkazy pro vytváření, úpravy a odstraňování indexů, zobrazení, uživatelem definovaných funkcí, uložených procedur, triggerů a dalších databázových objektů.
Když se vrátíme k našemu předchozímu příkladu, obrázek, který během vývoje již nasazené aplikace přidáte do Employees tabulky nový sloupec, odeberete z Orders tabulky sloupec a přidáte novou tabulku (ProductCategories). Výsledkem těchto akcí by byl soubor protokolu změn s následujícími příkazy SQL:
-- Add the DepartmentID column
ALTER TABLE [Employees] ADD [DepartmentID]
int NOT NULL
-- Add a foreign key constraint between Departments.DepartmentID and Employees.DepartmentID
ALTER TABLE [Employees] ADD
CONSTRAINT [FK_Departments_DepartmentID]
FOREIGN
KEY ([DepartmentID])
REFERENCES
[Departments] ([DepartmentID])
-- Remove TotalWeight column from Orders
ALTER TABLE [Orders] DROP COLUMN
[TotalWeight]
-- Create the ProductCategories table
CREATE TABLE [ProductCategories]
(
[ProductCategoryID]
int IDENTITY(1,1) NOT NULL,
[CategoryName]
nvarchar(50) NOT NULL,
[Active]
bit NOT NULL CONSTRAINT [DF_ProductCategories_Active] DEFAULT
((1)),
CONSTRAINT
[PK_ProductCategories] PRIMARY KEY CLUSTERED ( [ProductCategoryID])
)
Odeslání těchto změn do produkční databáze v době nasazení je operace jedním kliknutím: otevřete SQL Server Management Studio, připojte se k produkční databázi, otevřete okno Nový dotaz, vložte obsah protokolu změn a kliknutím na Spustit spusťte skript.
Použití nástroje pro porovnání k synchronizaci datových modelů
Dokumentování změn databáze v prase je snadné, ale implementace změn vyžaduje, aby vývojář prováděl každou změnu v produkční databázi jeden po druhém; Dokumentování změn příkazů SQL umožňuje implementaci těchto změn v produkční databázi stejně snadno a rychle jako kliknutí na tlačítko, ale vyžaduje učení a zvládnutí příkazů a syntaxe SQL pro vytváření a změny databázových objektů. Nástroje pro porovnávání databází využijí z obou přístupů to nejlepší a zahodí ty nejhorší.
Nástroj pro porovnání databází porovná schéma nebo data dvou databází a zobrazí souhrnnou sestavu ukazující, jak se databáze liší. Kliknutím na tlačítko pak můžete vygenerovat příkazy SQL pro synchronizaci jednoho nebo více databázových objektů. Stručně řečeno, nástroj pro porovnání databází můžete použít k porovnání vývojových a produkčních databází v době nasazení a vygenerování souboru obsahujícího příkazy SQL, které při spuštění aplikují změny na schéma produkční databáze tak, aby zrcadlil schéma vývojové databáze.
Existuje celá řada nástrojů pro porovnávání databází třetích stran, které nabízí řada různých dodavatelů. Jedním z takových příkladů je SQL Compare od Red Gate Software. Pojďme si projít proces použití nástroje SQL Compare k porovnání a synchronizaci schémat vývojových a produkčních databází.
Poznámka
V době psaní tohoto článku byla aktuální verze SQL Compare verze 7.1, přičemž edice Standard stála 395 USD. Můžete si stáhnout bezplatnou 14denní zkušební verzi.
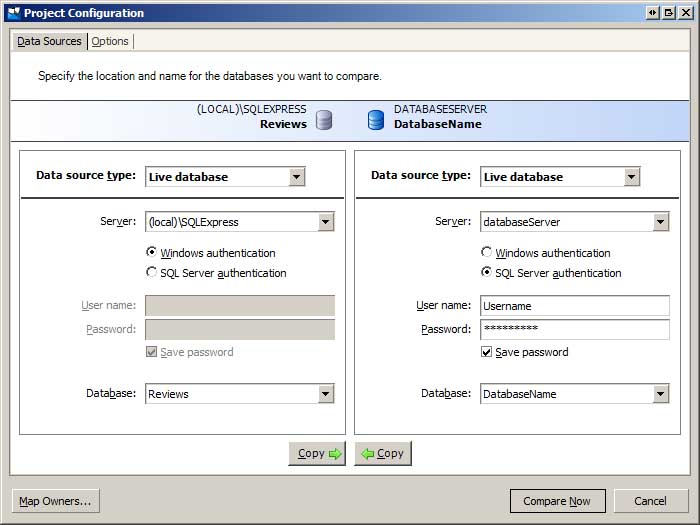
Když se spustí porovnání SQL, otevře se dialogové okno Projekty porovnání, ve kterém se zobrazí uložené projekty SQL Compare. Vytvoření nového projektu Tím spustíte Průvodce konfigurací projektu, který zobrazí výzvu k zadání informací o databázích k porovnání (viz obrázek 1). Zadejte informace o databázích vývojového a produkčního prostředí.
Obrázek 1: Porovnání vývojových a produkčních databází (kliknutím zobrazíte obrázek v plné velikosti)
{kind=link}
Poznámka
Pokud je vaše databáze vývojového prostředí soubor databáze edice SQL Express ve App_Data složce vašeho webu, budete ji muset zaregistrovat na databázovém serveru SQL Server Express, abyste ji mohli vybrat v dialogovém okně zobrazeném na obrázku 1. Nejjednodušší způsob, jak toho dosáhnout, je otevřít SQL Server Management Studio (SSMS), připojit se k databázovému serveru SQL Server Express a připojit databázi. Pokud nemáte na počítači nainstalovanou aplikaci SSMS, můžete si stáhnout a nainstalovat bezplatnou SQL Server Management Studio.
Kromě výběru databází, které chcete porovnat, můžete také zadat různá nastavení porovnání na kartě Možnosti. Jednou z možností, kterou můžete chtít zapnout, je ignorovat názvy omezení a indexů. Vzpomeňte si, že v předchozím kurzu jsme do vývojové a produkční databáze přidali databázové objekty aplikačních služeb. Pokud jste pomocí aspnet_regsql.exe nástroje vytvořili tyto objekty v produkční databázi, zjistíte, že se názvy primárního klíče a jedinečných omezení mezi vývojovou a produkční databází liší. V důsledku toho nástroj SQL Compare označí všechny tabulky aplikačních služeb jako odlišné. Můžete buď ponechat políčko Ignorovat názvy omezení a indexů nezaškrtnuté a názvy omezení synchronizovat, nebo můžete dát nástroji SQL Compare pokyn, aby tyto rozdíly ignoroval.
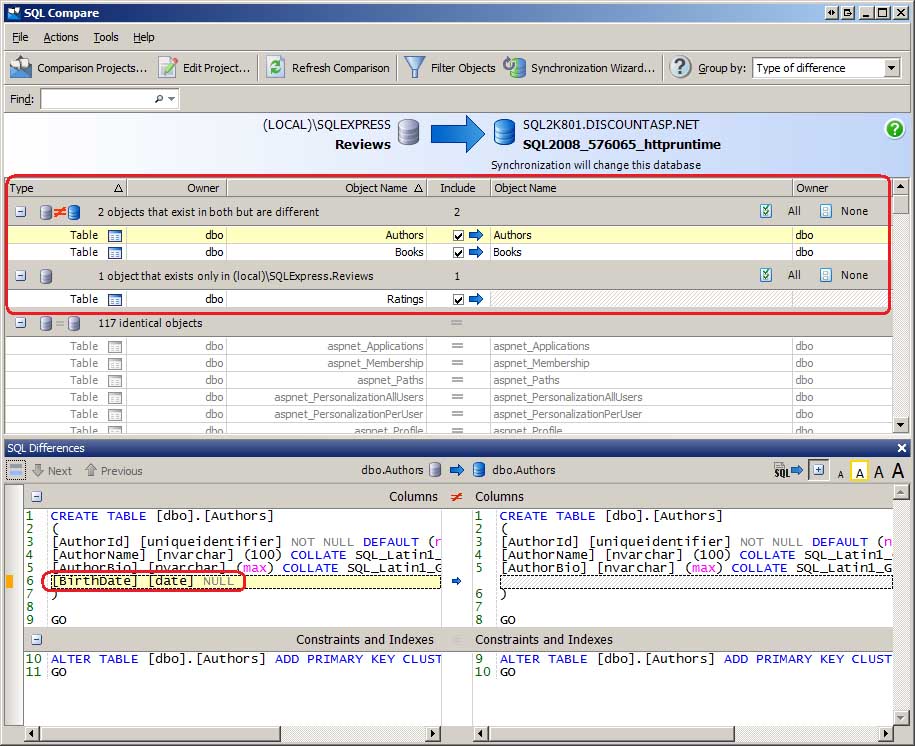
Po výběru databází, které se mají porovnat (a kontrole možností porovnání), klikněte na tlačítko Porovnat a zahajte porovnávání. Během několika dalších sekund sql compare prozkoumá schémata obou databází a vygeneruje sestavu, jak se liší. Záměrně jsem provedl(a) několik úprav vývojové databáze, abych ukázal, jak jsou takové nesrovnalosti zaznamenány v rozhraní SQL Compare. Jak ukazuje obrázek 2, přidali BirthDate jsme do Authors tabulky sloupec, odebrali ho ISBN z Books tabulky a přidali novou tabulku , která má umožnit uživatelům, Ratingskteří navštíví web, hodnotit hodnocené knihy.
Poznámka
Změny datového modelu provedené v tomto kurzu byly provedeny pro ilustraci pomocí nástroje pro porovnání databází. V budoucích kurzech tyto změny v databázi nenajdete.
Obrázek 2: Porovnání SQL Seznamy rozdíly mezi vývojovou a produkční databází (kliknutím zobrazíte image v plné velikosti)
{kind=link}
Sql Compare rozdělí databázové objekty do skupin a rychle vám ukáže, jaké objekty existují v obou databázích, ale liší se, které objekty existují v jedné databázi, ale ne v druhé a které objekty jsou identické. Jak vidíte, existují dva objekty, které existují v obou databázích, ale liší se: Authors tabulka s přidaným sloupcem a Books tabulka, která měla jeden odebraný. Existuje jeden objekt, který existuje pouze ve vývojové databázi, a to nově vytvořená Ratings tabulka. A v obou databázích je 117 objektů, které jsou identické.
Při výběru databázového objektu se zobrazí okno Rozdíly SQL, které ukazuje, jak se tyto objekty liší. Okno Rozdíly SQL zobrazené dole na obrázku 2 zvýrazňuje, že Authors tabulka ve vývojové databázi obsahuje BirthDate sloupec, který se v tabulce v produkční databázi nenajde Authors .
Po kontrole rozdílů a výběru objektů, které chcete synchronizovat, je dalším krokem vygenerování příkazů SQL potřebných k aktualizaci schématu produkční databáze tak, aby odpovídalo vývojové databázi. To se provádí prostřednictvím Průvodce synchronizací. Průvodce synchronizací potvrdí, které objekty se mají synchronizovat, a shrne plán akcí (viz obrázek 3). Databáze můžete synchronizovat okamžitě nebo můžete vygenerovat skript pomocí příkazů SQL, které můžete spouštět v klidu.
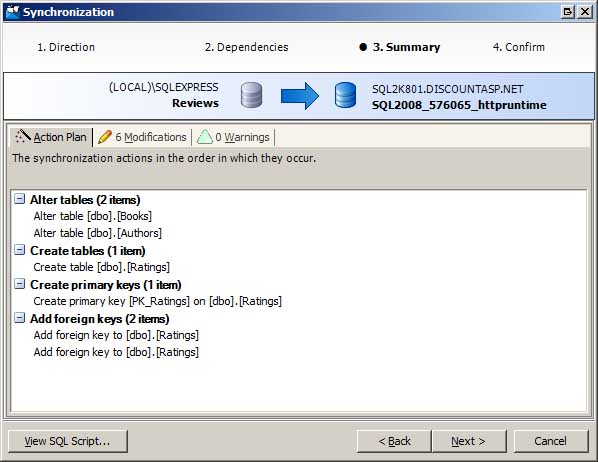
Obrázek 3: Synchronizace schémat databází pomocí Průvodce synchronizací (kliknutím zobrazíte obrázek v plné velikosti)
{kind=link}
Nástroje pro porovnání databází, jako je Red Gate Software s SQL Compare, umožňují aplikovat změny schématu vývojové databáze na produkční databázi tak snadno, jako je ukazatel myši a kliknutí.
Poznámka
SQL Compare porovnává a synchronizuje dvě schémata databází. Bohužel nesrovnává a nesynchronizuje data ve dvou tabulkách databází. Red Gate Software nabízí produkt s názvem SQL Data Compare , který porovnává a synchronizuje data mezi dvěma databázemi, ale je to samostatný produkt od SQL Compare a stojí další 395 USD.
Přecházení aplikace během nasazení do režimu offline
Jak jsme viděli v těchto kurzech, nasazení je proces, který zahrnuje několik kroků: kopírování ASP.NET stránek, stránek předlohy, souborů CSS, souborů JavaScriptu, obrázků a dalšího nezbytného obsahu z vývojového prostředí do produkčního prostředí; kopírování informací o konfiguraci specifické pro produkční prostředí v případě potřeby; a použije změny datového modelu od posledního nasazení. V závislosti na počtu souborů a složitosti změn v databázi může dokončení těchto kroků trvat několik sekund až několik minut. Během tohoto okna je webová aplikace v provozu a uživatelé, kteří navštíví web, může docházet k chybám nebo neočekávanému chování.
Při nasazování webu je nejlepší převést webovou aplikaci do režimu offline, dokud se nasazení nedokončilo. Převést aplikaci do offline režimu (a po dokončení procesu nasazení ji znovu spustit) je stejně snadné jako nahrát soubor a pak ho odstranit. Počínaje ASP.NET 2.0, pouhá přítomnost souboru s názvem app_offline.htm v kořenovém adresáři aplikace přenese celý web "offline". Na každý požadavek na stránku ASP.NET na tomto webu se automaticky odpoví obsahem app_offline.htm souboru. Po odebrání souboru se aplikace vrátí do online režimu.
Převést aplikaci během nasazení do offline režimu pak stačí nahrát app_offline.htm soubor do kořenového adresáře produkčního prostředí před zahájením procesu nasazení a po dokončení nasazení ho odstranit (nebo přejmenovat na něco jiného). Další informace o této technice najdete v článku Johna Petersona o ASP.NET aplikace offline.
Souhrn
Hlavní výzva při nasazení aplikace řízené daty se zaměřuje na nasazení databáze. Vzhledem k tomu, že existují dvě verze databáze – jedna ve vývojovém prostředí a jedna v produkčním prostředí – můžou se tato dvě schémata databází po přidání nových funkcí do vývoje nesynchronizovat. A co víc, protože produkční databáze je naplněná skutečnými daty od skutečných uživatelů, nemůžete přepsat produkční databázi upravenou vývojovou databází stejně jako při nasazování souborů, které tvoří aplikaci (stránky ASP.NET, soubory obrázků atd.). Nasazení databáze místo toho zahrnuje implementaci přesné sady změn provedených ve vývojové databázi v produkční databázi od posledního nasazení.
Tento kurz se zabýval třemi technikami údržby a použití protokolu změn databáze. Nejjednodušším způsobem je zaznamenat změny v préce. I když tato taktika dělá implementaci těchto změn v produkční databázi ruční proces, nevyžaduje znalost příkazů SQL pro vytváření a změny databázových objektů. Sofistikovanější přístup, který je mnohem přijatelnější ve větších projektech nebo projektech s více vývojáři, je zaznamenat změny jako řadu příkazů SQL. To výrazně ztěžuje zavádění těchto změn do cílové databáze. Nejlepšího z obou přístupů lze dosáhnout pomocí nástroje pro porovnávání databází, jako je red Gate Software s SQL Compare.
Tento kurz uzavírá naše zaměření na nasazení aplikace řízené daty. V další sadě kurzů se dozvíte, jak reagovat na chyby v produkčním prostředí. Podíváme se na to, jak místo žluté obrazovky smrti zobrazit popisnou chybovou stránku. A uvidíme, jak protokolovat podrobnosti o chybách a jak vás upozornit, když k takovým chybám dojde.
Všechno nejlepší na programování!