Process more files than ever and use Parquet with Azure Data Lake Analytics
In a recent release, Azure Data Lake Analytics (ADLA) takes the capability to process large amounts of files of many different formats to the next level. This blog post is showing you an end to end walk-through of generating many Parquet files from a rowset, and process them at scale with ADLA as well as accessing them from a Spark Notebook.
Problem Statement
A common problem our customers face is that they need to process data stored in many thousand files in commonly used structured file formats such as Parquet, either because they ingest many (potentially small) files or because their data is partitioned into many folders and files due to the physical design to achieve scale-out in other systems such as Hadoop's Hive or in Spark (see this description of the Hive Metastore partitioning layout for example). Since ADLA originally was designed to operate on very large files that had internal structure that helped with scale-out, it was only designed to operate on a couple of hundred to about 2000 files, had a file format designed for this internal structure to back the U-SQL tables, and was not providing a mechanism to create files that were dynamically partitioned into different folders and files.
The good news is that ADLA and U-SQL now has added capabilities to address all of these restrictions.
Process hundreds of thousands of files in a single U-SQL job!
ADLA increases the scale limit to schematize and process files from the low thousands to several hundred-thousand files in a single U-SQL job with an easy-to-use syntax - so-called file sets. A future blog post will provide more in-depth details on the inner workings and the scale.
In addition, ADLA now supports file sets on OUTPUT statements (in private preview) that gives you the ability to dynamically partition your data into different folders and paths with the same easy-to-use file set syntax. This can help you to partition data for further consumption with other analytics engines such as Hive or Spark, or allows you to create separate files for sharing.
Process Parquet in Azure Data Lake with U-SQL
We have expanded our built-in support for standard file formats with native Parquet support for extractors and outputters (in public preview). Parquet is one of the major open source structured data formats used when processing data at scale. It enables more efficient data exchange between different analytics engines (that know how to query Parquet files) than CSV.
Putting it all together in a simple end-to-end example
The following simple example brings the high-scale file processing, the new Parquet support, and also the new ability to dynamically partition your data into many files together. Additionally, it also shows how the generated Parquet files can be easily consumed by Azure DataBricks.
Generating thousands of Parquet files
The first step in the example is the schematization of a single, large file called /input/tpch/biglineitems.tbl that contains about 3TB of line item data in a pipe delimited format into a set of Parquet files that are partitioned based on the supplier id associated with a line item.
// The following @@FeaturePreviews flags are only needed while the features are in preview
// Special runtimes may be required if the feature is still in private preview
// Contact us at usql at microsoft dot com if you need access to the private preview
SET @@FeaturePreviews = "EnableParquetUdos:on"; // Public Preview
SET @@FeaturePreviews = "DataPartitionedOutput:on"; // Private Preview (needs special runtime)
@input =
EXTRACT order_key long,
part_key int,
supp_key int,
linenumber int,
quantity int,
extendedprice double,
discount double,
tax double,
returnflag string,
linestatus string,.
ship_date DateTime,
commit_date DateTime,
receipt_date DateTime,
ship_instruct string,
ship_mode string,
comment string
FROM "/input/tpch/biglineitems.tbl"
USING Extractors.Csv();
OUTPUT @input
TO "/output/parquet/biglineitems/supplier={supp_key}/data.parquet"
USING Outputters.Parquet(
columnOptions:
"1~snappy,2~snappy,3~snappy,4~snappy,5~snappy,6~snappy,7~snappy,8~snappy,9~snappy,10~snappy,11~snappy,
12~snappy,13~snappy,14~snappy,15~snappy"
);
The EXTRACT statement schematizes the pipe delimited file using the built-in text extractor. The subsequent OUTPUT statement generates the supplier files using the new built-in Parquet outputter, using a simple file set path to map the supplier id column into the directory name, thus generating one directory for every distinct supplier id which contains all the line item data for that particular supplier in a Parquet file called data.parquet. This structure is aligned with the partitioning scheme used by Hive and Spark to simplify its later use with these open source analytics engines. The Parquet outputter will compress all columns with the snappy compression and will use the default micro-second resolution for the datetime typed columns (note that for HDInsight's Spark engine, that would need to be changed to milli-seconds). The U-SQL Parquet outputter also supports the gzip and brotli compression formats.
As the following job graph image shows, there is the potential scaling the Parquet generation job out to several thousand nodes:
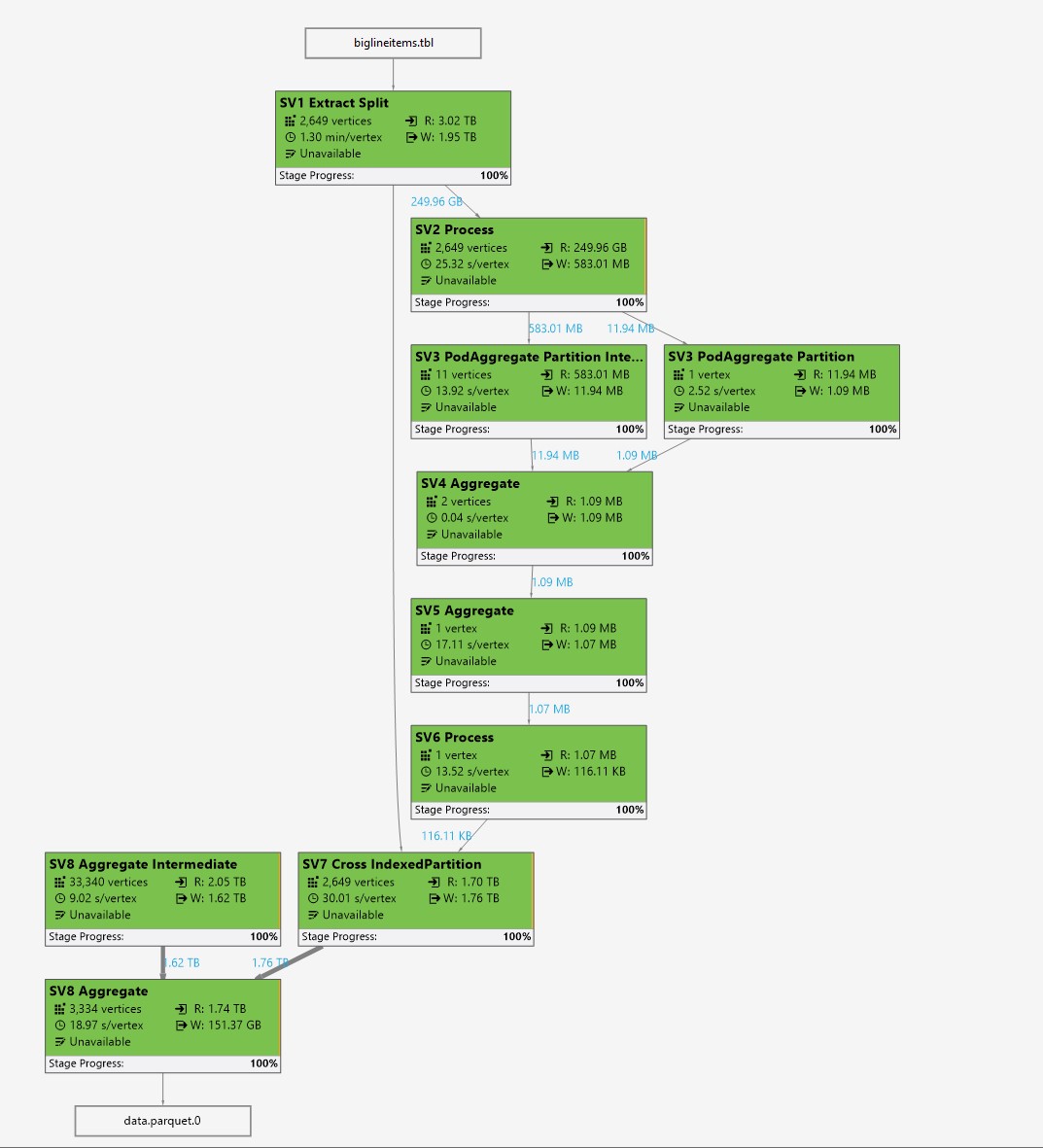
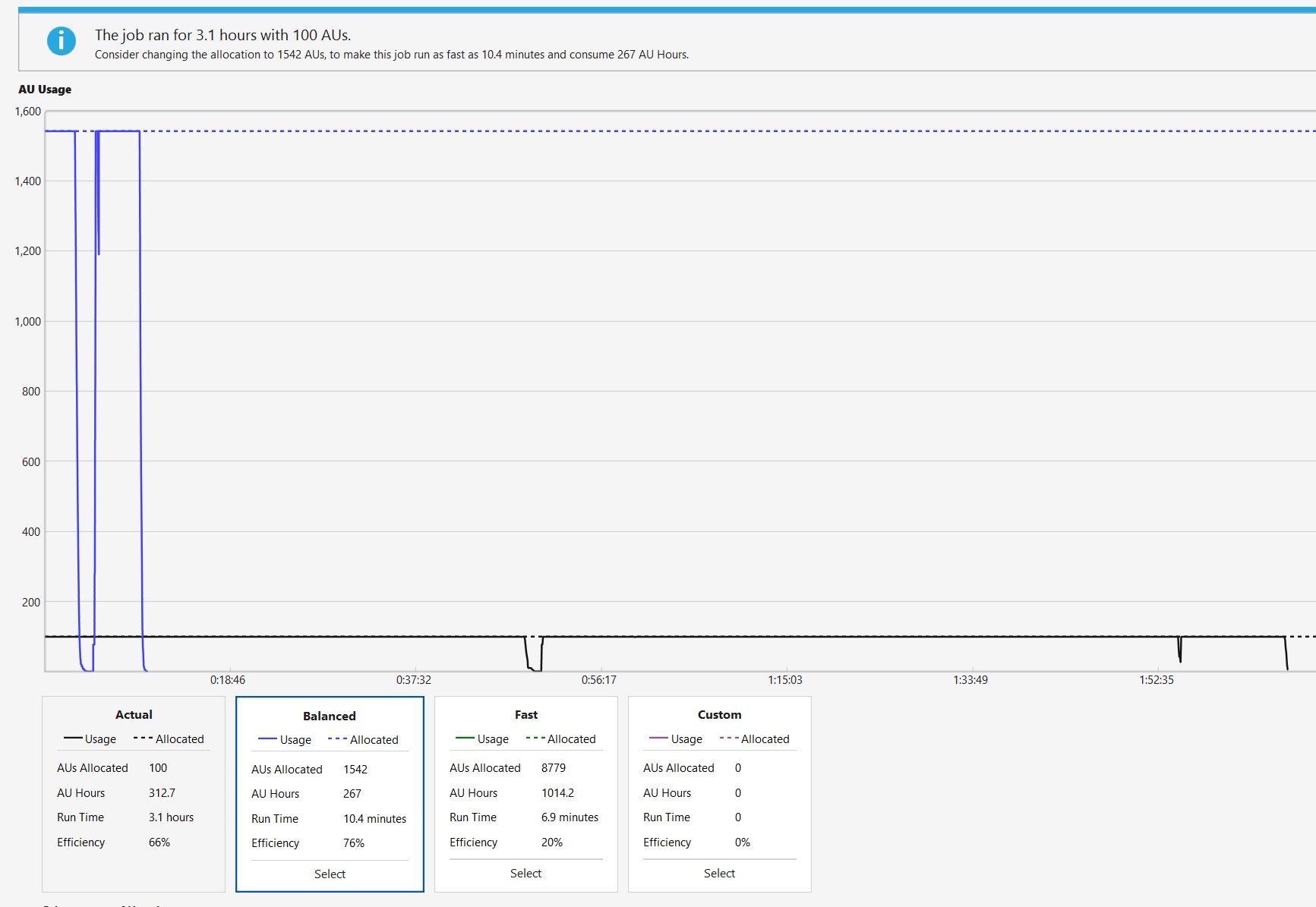
In fact, the AU modeler predicts that if the job is submitted with about 8700 AUs, it can finish in about 7 minutes of runtime and with 1540 AUs it would be done in about 10 minutes (the finalization phase is not accounted for in this number):
For the given data set, this generates 10000 folders, each containing a file of about 13.5 MB to 18.6 MB in size, as the following script determines:
// As of time of publishing this blog, this script has to be run with a private runtime to enable
// fast file sets with Parquet Extractors (otherwise this script will time out during compilation)
SET @@FeaturePreviews = "EnableParquetUdos:on";
SET @@FeaturePreview = "InputFileGrouping:on";
// Would be better to use a custom extractor that does not actually parse the file for this use case,
// since we do not make use of any of the data columns and only need the number of files and their file lengths.
@data =
EXTRACT order_key long,
supp_key int,
file_size = FILE.LENGTH()
FROM "/output/parquet/biglineitems/supplier={supp_key}/data.parquet"
USING Extractors.Parquet();
@result =
SELECT COUNT(DISTINCT supp_key) AS supp_count,
MIN(file_size) AS min_file_sz,
MAX(file_size) AS max_file_sz
FROM @data;
OUTPUT @result
TO "/output/parquetfiles_stats.csv"
USING Outputters.Csv(outputHeader : true);
Since we used the input file set grouping preview, the job actually can execute on 150 nodes instead of the 10000 nodes without it:

This set of Parquet files can now be processed in other U-SQL jobs to prepare other data sets for analysis or be analyzed using one of the other analytics platforms like Azure DataBricks.
Processing thousands of files in ADLA
The above script already showed you how easy and efficient U-SQL is to scale out its processing over thousands of files. The following U-SQL script queries over the same files and creates a smaller subset of the line item data in a single CSV file for line items that are shipped via air, rail or ship, and for suppliers with the id between 200 and 300. In this case though the query processing will optimize.
SET @@FeaturePreviews = "EnableParquetUdos:on";
SET @@FeaturePreviews = "InputFileGrouping:on";
@data =
EXTRACT order_key long,
supp_key int,
linenumber int,
quantity int,
extendedprice double,
discount double,
tax double,
returnflag string,
linestatus string,
ship_date DateTime,
commit_date DateTime,
receipt_date DateTime,
ship_instruct string,
ship_mode string,
comment string
FROM "/output/parquet/biglineitems/supplier={supp_key}/data.parquet"
USING Extractors.Parquet();
@result =
SELECT * FROM @data WHERE supp_key BETWEEN 200 AND 299 AND ship_mode IN("AIR", "RAIL", "SHIP");
OUTPUT @result
TO "/output/suppliers200to299.csv"
USING Outputters.Csv(outputHeader : true);
Note that this time the EXTRACT statement uses the file set path pattern to query all the files satisfying the pattern. As importantly, the predicate on the supp_key column is being pushed in the EXTRACT expression by the query optimizer, so that only the files for the specified suppliers need to be read, instead of the 10000 files that could match the file set path pattern. The following job graph shows you that it only reads the 100 files:

Analyzing U-SQL generated Parquet files with Spark
Now if you want to analyze your Parquet Data using Spark, you can easily do so with an Azure DataBricks notebook. Since Azure Databricks uses a service principal to access the Azure Data Lake Store (ADLS) account, you will need to create or use an existing service principal and provide it at least read and execute permission to the files and folders in the ADLS account. Then you create an Azure DataBricks cluster with the same service principal to access the ADLS account from DataBricks (I used a default cluster for the example). Once this setup is complete, you can create for example a Spark SQL notebook.
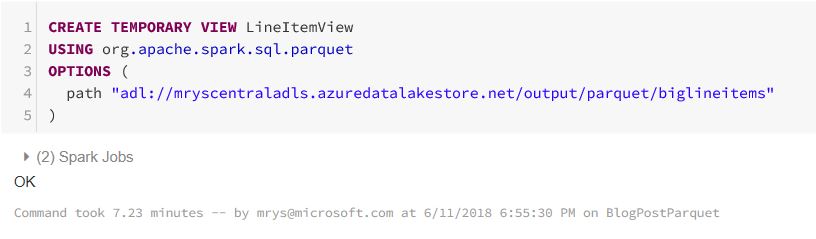
In the following example, I create a temporary view on the data set with the following statement
CREATE TEMPORARY VIEW LineItemView
USING org.apache.spark.sql.parquet
OPTIONS (
path "adl://mryscentraladls.azuredatalakestore.net/output/parquet/biglineitems"
)
and then run my Spark SQL query:
SELECT * FROM LineItemView WHERE supplier BETWEEN 200 AND 300 AND ship_mode IN('AIR', 'RAIL', 'SHIP');
As the following screen shot shows, the view creation is taking over 7 minutes, which mainly is spent in scanning the 10000 directories:
The query itself get's executed in 24 seconds (subsequent runs will be faster because they will benefit from caching):

Summary
With its latest release, ADLA is offering some new, unparalleled capabilities for processing files of any formats including Parquet at tremendous scale. For more details on the presented capabilities as well as many more interesting capabilities, please visit the Azure Data Lake blog’s release note post.