Použití předem vytvořeného modelu rozpoznávání textu v Power Automate
Předdefinovaný model rozpoznávání textu v AI Builder extrahuje tištěný a ručně psaný text z obrázků a dokumentů. Pomocí tohoto modelu Power Automate můžete vytvářet pracovní postupy, které automaticky zpracovávají text z naskenovaných dokumentů, fotografií a souborů PDF, což umožňuje efektivní zpracování dat a integraci s jinými aplikacemi.
Tento dokument obsahuje návod k používání předdefinovaného modelu rozpoznávání textu v Power Automate.
Inicializace toku Power Automate
Inicializace Power Automate toku je prvním krokem při nastavování automatizovaného procesu. Tento krok umožňuje definovat aktivační událost a počáteční vstupní parametry pro váš tok. Při inicializaci můžete zajistit, aby se tok spustil správně a měl potřebné informace k efektivnímu zpracování úloh rozpoznávání textu.
K inicializaci toku postupujte následovně:
Přihlaste se ke službě Power Automate.
V navigační nabídce vlevo vyberte Moje toky a potom vyberte Nový tok>Okamžitý cloudový tok.
Pojmenujte tok, vyberte Umožňuje ruční spuštění toku v části Zvolte, jak aktivovat tento tok a pak vyberte Vytvořit.
Rozbalte Umožňuje ruční spuštění toku, vyberte + Přidat vstup>Soubor jako typ vstupu.
Vyberte položku + Nový krok>AI Builder a poté vyberte Rozpoznání textu v obrázku nebo dokumentu PDF v seznamu akcí.
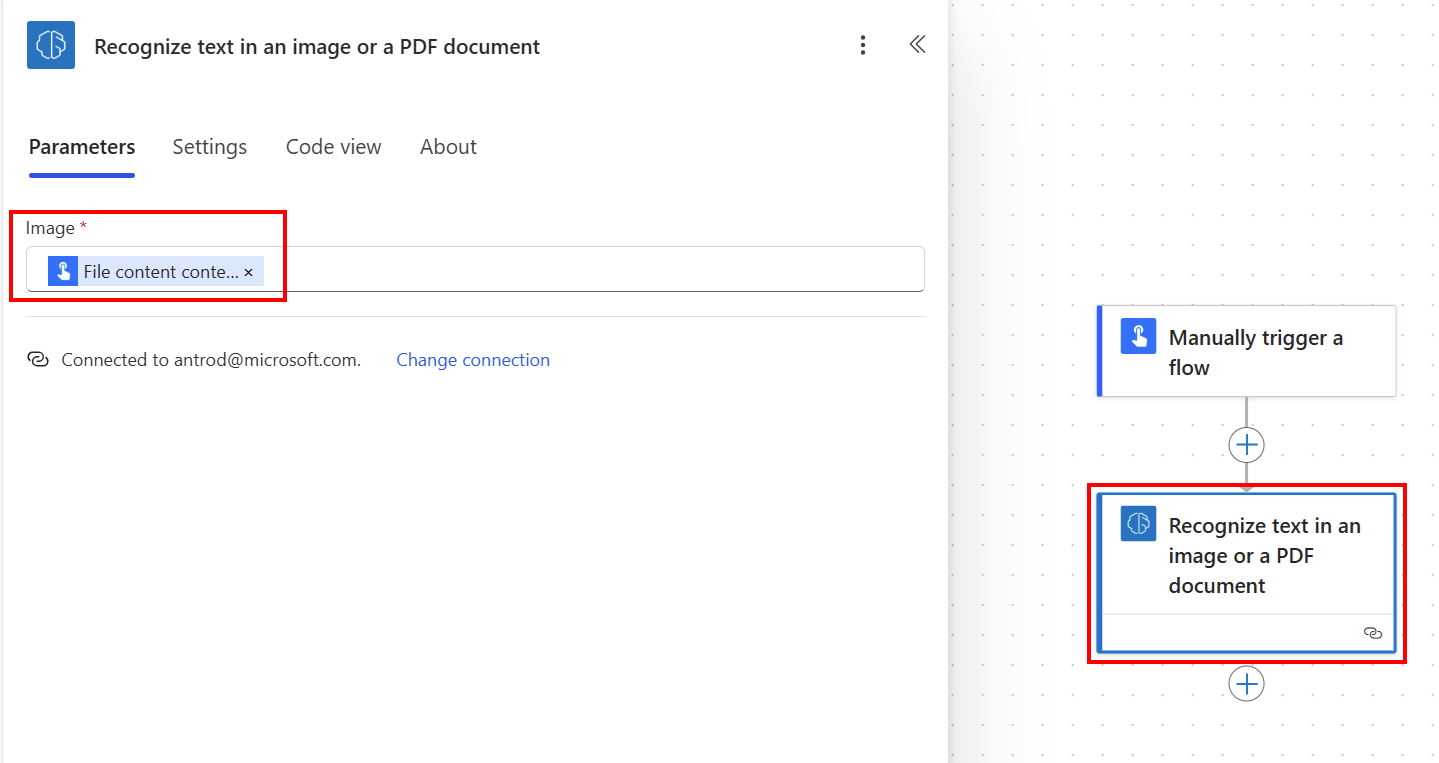
Vyberte vstup Obrázek a poté vyberte Obsah souboru ze seznamu Dynamický obsah:
Chcete-li zpracovat výsledky, můžete použít buď celý text dokumentu, text stránky nebo text dokumentu řádek po řádku.
Získání celého textu dokumentu nebo textu celé stránky
Tato volba je užitečná, pokud potřebujete provést akci s celým textem dokumentu nebo s určitým textem stránky. Příkladem použití textu stránky je, když chcete vyhledat podřetězec nebo ho předat podřízené akci.
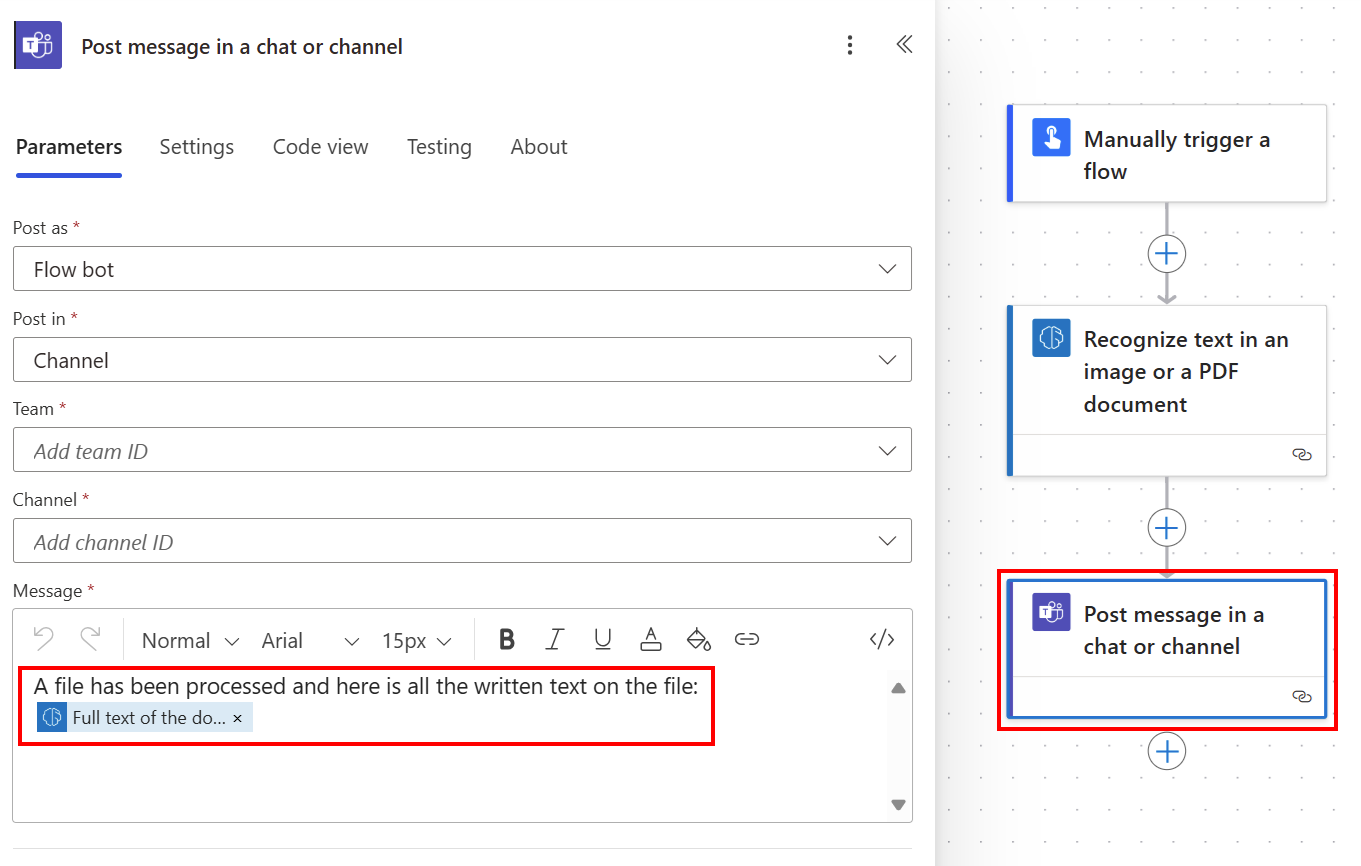
Veškerý extrahovaný text můžete publikovat v kanálu Teams pomocí úplného textu dokumentu ze seznamu dynamického obsahu.
Získání textu dokumentu řádek po řádku
Získání textu dokumentu řádek po řádku může být užitečné, pokud potřebujete izolovat konkrétní řádek textu nebo přeformátovat text podle potřeby.
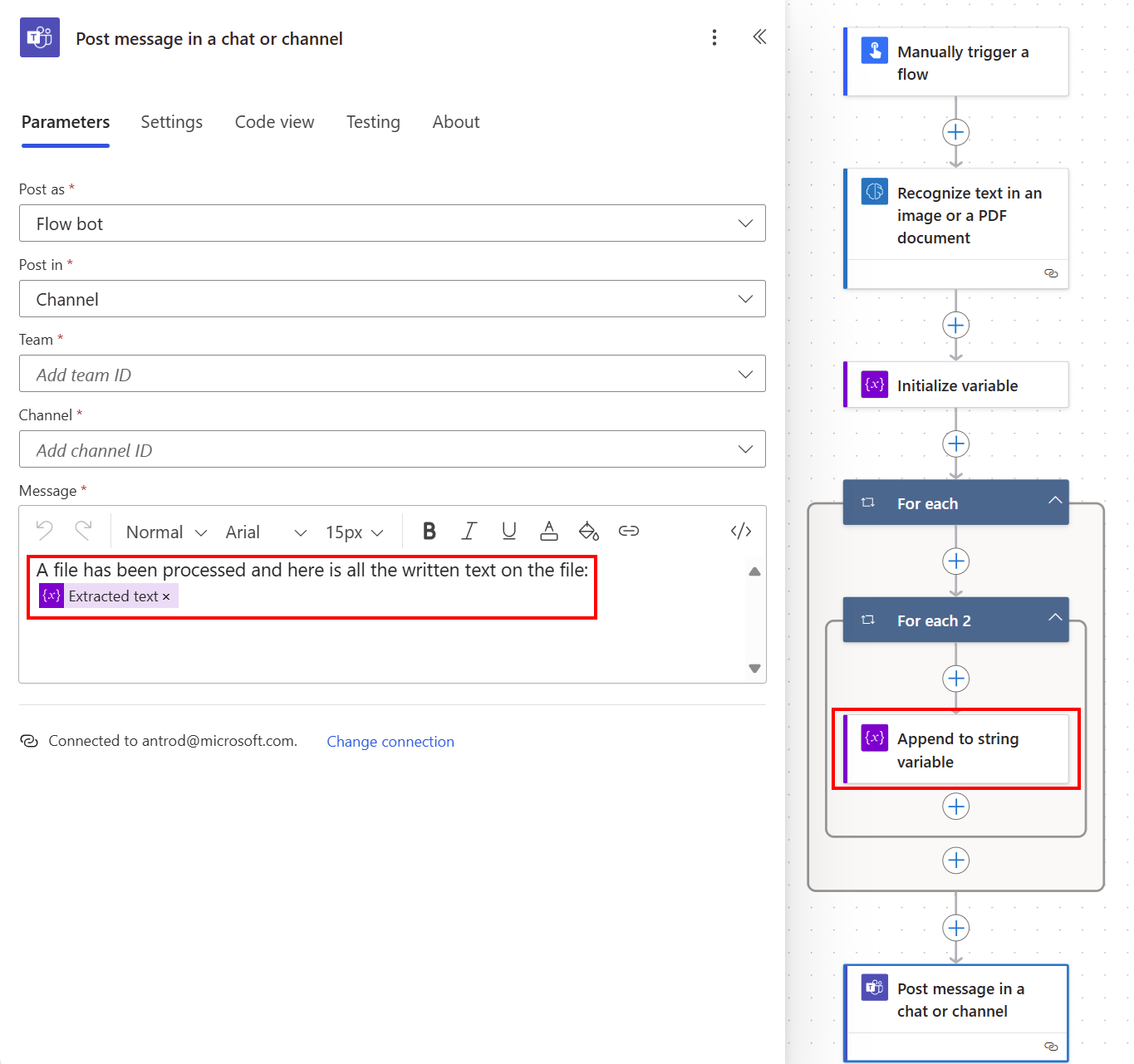
Pokud chcete vytvořit řetězcovou proměnnou, vyberte +Nový krok>Ovládací prvek a pak vyberte Inicializovat proměnnou.
Například ji pojmenujte Extrahovaný text.
Vyberte +Nový krok>Ovládací prvek a pak vyberte Připojit k řetězcové proměnné.
V poli hodnota vyberte Text ze seznamu Dynamický obsah.
Automaticky vygeneruje dvě akce Použít na každý při čtení seznamu řádků textu v seznamu stránek. Veškerý extrahovaný text pak můžete zveřejnit v kanálu Teams.
Blahopřejeme! Vytvořili jste tok, který využívá model pro rozpoznávání textu. Tento tok můžete dále rozvíjet tak, aby vyhovoval vašim potřebám. Vpravo nahoře vyberte Uložit a pak vyberte Testovat, abyste mohli tok vyzkoušet.
Parametry
Předdefinovaný model rozpoznávání textu v AI Builder obsahuje následující vstupní a výstupní parametry.
Vstup
| Name | Požadováno | Type | Description |
|---|---|---|---|
| Obrázek | Ano | soubor | Obrázek k analýze |
Výstup
Zjištěný text je vložen do dílčího seznamu řádky seznamu výsledky. Nejprve musíte vybrat sloupec řádky z akce Použít na všechny pro zobrazení všech následujících sloupců.
| Jméno | Typ | Popis |
|---|---|---|
| Text | řetězec | Řetězce obsahující řádek zjištěného textu |
| Číslo stránky | string | Číslo stránky detekovaného textu |
| Souřadnice | float (číslo s plovoucí řádovou čárkou) | Souřadnice detekovaného textu |
| Celý text dokumentu | string | Zjištěn celý text |
| Celý text stránky | string | Zjištěny celý text stránky |