Pokyny k návrhu pro použití replikovaných tabulek ve fondu Synapse SQL
Tento článek poskytuje doporučení pro návrh replikovaných tabulek ve schématu fondu Synapse SQL. Pomocí těchto doporučení můžete zlepšit výkon dotazů snížením složitosti přesunu dat a složitosti dotazů.
Požadavky
Tento článek předpokládá, že znáte koncepty distribuce dat a přesunu dat ve fondu SQL. Další informace najdete v článku o architektuře.
V rámci návrhu tabulky získáte co nejvíce informací o datech a způsobu dotazování dat. Představte si například tyto otázky:
- Jak velká je tabulka?
- Jak často se tabulka aktualizuje?
- Mám tabulky faktů a dimenzí ve fondu SQL?
Co je replikovaná tabulka?
Replikovaná tabulka má úplnou kopii tabulky přístupné na každém výpočetním uzlu. Replikace tabulky eliminuje nutnost převádět data mezi výpočetními uzly před spojením nebo agregací. Vzhledem k tomu, že tabulka obsahuje více kopií, fungují replikované tabulky nejlépe, když je velikost tabulky menší než 2 GB komprimované. 2 GB není pevný limit. Pokud jsou data statická a nemění se, můžete replikovat větší tabulky.
Následující diagram znázorňuje replikovanou tabulku, která je přístupná na jednotlivých výpočetních uzlech. Ve fondu SQL se replikovaná tabulka plně zkopíruje do distribuční databáze na každém výpočetním uzlu.

Replikované tabulky fungují dobře pro tabulky dimenzí ve hvězdicovém schématu. Tabulky dimenzí jsou obvykle spojeny s tabulkami faktů, které se distribuují odlišně než tabulka dimenzí. Rozměry jsou obvykle velikostí, která umožňuje ukládat a udržovat více kopií. Dimenze ukládají popisná data, která se pomalu mění, například jméno zákazníka a adresu a podrobnosti o produktu. Pomalu se měnící povaha dat vede k menší údržbě replikované tabulky.
Zvažte použití replikované tabulky v následujících případech:
- Velikost tabulky na disku je menší než 2 GB bez ohledu na počet řádků. Pokud chcete zjistit velikost tabulky, můžete použít příkaz DBCC PDW_SHOWSPACEUSED :
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate'). - Tabulka se používá ve spojeních, která by jinak vyžadovala přesun dat. Při spojování tabulek, které nejsou distribuovány do stejného sloupce, jako je například tabulka distribuovaná hodnotou hash do tabulky s kruhovým dotazem, se k dokončení dotazu vyžaduje přesun dat. Pokud je jedna z tabulek malá, zvažte replikovanou tabulku. Ve většině případů doporučujeme místo tabulek s kruhovým dotazem používat replikované tabulky. Pokud chcete zobrazit operace přesunu dat v plánech dotazů, použijte sys.dm_pdw_request_steps. BroadcastMoveOperation je typická operace přesunu dat, kterou lze odstranit pomocí replikované tabulky.
Replikované tabulky nemusí přinést nejlepší výkon dotazů v následujících případech:
- Tabulka obsahuje časté operace vložení, aktualizace a odstranění. Operace jazyka pro manipulaci s daty (DML) vyžadují opětovné sestavení replikované tabulky. Opětovné sestavení často může způsobit pomalejší výkon.
- Fond SQL se často škáluje. Škálování fondu SQL změní počet výpočetních uzlů, u kterých dochází k opětovnému sestavení replikované tabulky.
- Tabulka obsahuje velký počet sloupců, ale operace s daty obvykle přistupuje pouze k malému počtu sloupců. V tomto scénáři může být místo replikace celé tabulky efektivnější distribuovat tabulku a pak vytvořit index pro často používané sloupce. Pokud dotaz vyžaduje přesun dat, fond SQL přesune data jenom pro požadované sloupce.
Tip
Další pokyny k indexování a replikovaným tabulkám najdete v taháku pro vyhrazený fond SQL (dříve SQL DW) ve službě Azure Synapse Analytics.
Použití replikovaných tabulek s jednoduchými predikáty dotazů
Než se rozhodnete distribuovat nebo replikovat tabulku, zamyslete se nad typy dotazů, které chcete s tabulkou spouštět. Kdykoli je to možné,
- Pro dotazy s jednoduchými predikáty dotazů, jako je rovnost nebo nerovnost, použijte replikované tabulky.
- Distribuované tabulky můžete použít pro dotazy s komplexními predikáty dotazů, jako je LIKE nebo NOT LIKE.
Dotazy náročné na procesor fungují nejlépe, když se práce distribuuje napříč všemi výpočetními uzly. Například dotazy, které spouštějí výpočty na každém řádku tabulky, fungují s distribuovanými tabulkami lépe než replikované tabulky. Vzhledem k tomu, že replikovaná tabulka je uložena v plném rozsahu na každém výpočetním uzlu, spustí se dotaz náročný na procesor na replikovanou tabulku pro celou tabulku na každém výpočetním uzlu. Dodatečný výpočet může zpomalit výkon dotazů.
Tento dotaz má například složitý predikát. Běží rychleji, když jsou data v distribuované tabulce místo replikované tabulky. V tomto příkladu je možné data distribuovat pomocí kruhového dotazování.
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
Převod existujících tabulek kruhového dotazování na replikované tabulky
Pokud už máte tabulky kruhového dotazování, doporučujeme je převést na replikované tabulky, pokud splňují kritéria uvedená v tomto článku. Replikované tabulky zlepšují výkon oproti tabulkám s kruhovým dotazováním, protože eliminují potřebu přesunu dat. Tabulka kruhového dotazování vždy vyžaduje přesun dat pro spojení.
Tento příklad používá CTAS ke změně DimSalesTerritory tabulky na replikovanou tabulku. Tento příklad funguje bez ohledu na to, jestli DimSalesTerritory je hodnota hash distribuovaná nebo kruhové dotazování.
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Příklad výkonu dotazů pro kruhové dotazování a replikaci
Replikovaná tabulka nevyžaduje přesun dat pro spojení, protože celá tabulka je již na každém výpočetním uzlu. Pokud jsou tabulky dimenzí distribuované pomocí kruhového dotazování, zkopíruje spojení celou tabulku dimenzí do každého výpočetního uzlu. K přesunutí dat obsahuje plán dotazu operaci s názvem BroadcastMoveOperation. Tento typ operace přesunu dat zpomaluje výkon dotazů a eliminuje se pomocí replikovaných tabulek. Pokud chcete zobrazit kroky plánu dotazů, použijte zobrazení sys.dm_pdw_request_steps systémového katalogu.
Například v následujícím dotazu na schéma FactInternetSales je tabulka distribuovaná AdventureWorks hodnotou hash. Tabulky DimDate jsou DimSalesTerritory menší tabulky dimenzí. Tento dotaz vrátí celkový prodej v Severní Amerika pro fiskální rok 2004:
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
Znovu jsme vytvořili DimDate a DimSalesTerritory jako tabulky kruhového dotazování. V důsledku toho dotaz ukázal následující plán dotazu, který má více operací přesunu všesměrového vysílání:
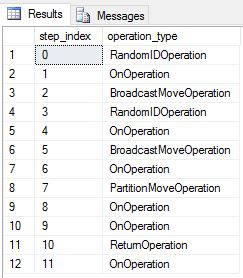
Znovu jsme vytvořili DimDate a DimSalesTerritory jako replikované tabulky spustili dotaz znovu. Výsledný plán dotazu je mnohem kratší a nemá žádné přesuny vysílání.
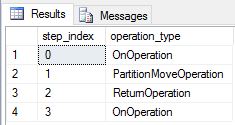
Aspekty výkonu pro úpravu replikovaných tabulek
Fond SQL implementuje replikovanou tabulku udržováním hlavní verze tabulky. Zkopíruje hlavní verzi do první distribuční databáze na každém výpočetním uzlu. Když dojde ke změně, hlavní verze se nejprve aktualizuje a tabulky na jednotlivých výpočetních uzlech se znovu sestaví. Opětovné sestavení replikované tabulky zahrnuje zkopírování tabulky do každého výpočetního uzlu a následné sestavení indexů. Například replikovaná tabulka v DW2000c má pět kopií dat. Hlavní kopie a úplná kopie na každém výpočetním uzlu. Všechna data jsou uložená v distribučních databázích. Fond SQL používá tento model k podpoře rychlejších příkazů úprav dat a flexibilních operací škálování.
Asynchronní opětovné sestavení se aktivuje prvním dotazem na replikovanou tabulku za:
- Data se načtou nebo upraví.
- Instance Synapse SQL se škáluje na jinou úroveň.
- Definice tabulky se aktualizuje.
Opětovné sestavení se nevyžaduje po:
- Operace pozastavení
- Operace obnovení
Opětovné sestavení se neprovádí okamžitě po úpravě dat. Místo toho se opětovné sestavení aktivuje při prvním výběru dotazu z tabulky. Dotaz, který aktivoval opětovné sestavení, se načte okamžitě z hlavní verze tabulky, zatímco data se asynchronně zkopírují do každého výpočetního uzlu. Dokud nebude kopírování dat dokončeno, budou další dotazy nadále používat hlavní verzi tabulky. Pokud u replikované tabulky dojde k nějaké aktivitě, která vynutí další opětovné sestavení, kopírování dat se zneplatní a další příkaz select znovu aktivuje kopírování dat.
Použití indexů konzervativně
Standardní postupy indexování platí pro replikované tabulky. Fond SQL znovu sestaví každý replikovaný index tabulky jako součást opětovného sestavení. Indexy používejte pouze v případech, kdy výkon převáží náklady na opětovné sestavení indexů.
Dávkové načítání dat
Při načítání dat do replikovaných tabulek se pokuste minimalizovat opětovné sestavení dávkováním dohromady. Před spuštěním příkazů select proveďte všechna dávková načtení.
Tento vzor zatížení například načte data ze čtyř zdrojů a vyvolá čtyři opětovné sestavení.
- Načtení ze zdroje 1
- Příkaz Select aktivuje opětovné sestavení 1.
- Načtení ze zdroje 2
- Příkaz Select aktivuje opětovné sestavení 2.
- Načtení ze zdroje 3
- Příkaz Select aktivuje opětovné sestavení 3.
- Načtení ze zdroje 4
- Příkaz Select aktivuje opětovné sestavení 4.
Tento vzor zatížení například načte data ze čtyř zdrojů, ale vyvolá pouze jedno opětovné sestavení.
- Načtení ze zdroje 1
- Načtení ze zdroje 2
- Načtení ze zdroje 3
- Načtení ze zdroje 4
- Příkaz Select aktivuje opětovné sestavení.
Opětovné sestavení replikované tabulky po dávkovém načtení
Pokud chcete zajistit konzistentní dobu provádění dotazů, zvažte vynucení sestavení replikovaných tabulek po dávkovém načtení. V opačném případě první dotaz stále použije přesun dat k dokončení dotazu.
Operace !Sestavit mezipaměť replikované tabulky“ může současně provádět až dvě operace. Pokud se například pokusíte znovu sestavit mezipaměť pro pět tabulek, systém použije staticrc20 (který nelze upravit) k souběžnému sestavení dvou tabulek. Proto se doporučuje vyhnout použití velkých replikovaných tabulek přesahujících 2 GB, protože to může zpomalit opětovné sestavení mezipaměti napříč uzly a zvýšit celkový čas.
Tento dotaz používá zobrazení dynamické správy sys.pdw_replicated_table_cache_state k výpisu replikovaných tabulek, které byly změněny, ale nebyly znovu sestaveny.
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
Pokud chcete aktivovat opětovné sestavení, spusťte v každé tabulce v předchozím výstupu následující příkaz.
SELECT TOP 1 * FROM [ReplicatedTable]
Poznámka:
Pokud plánujete znovu sestavit statistiku replikované tabulky bez mezipaměti, před aktivací mezipaměti nezapomeňte statistiku aktualizovat. Aktualizace statistiky zneplatní mezipaměť, takže pořadí je důležité.
Příklad: Začněte s UPDATE STATISTICSa pak aktivujte opětovné sestavení mezipaměti. V následujících příkladech aktualizuje správná ukázka statistiku a pak aktivuje opětovné sestavení mezipaměti.
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
Pokud chcete monitorovat proces opětovného sestavení, můžete použít sys.dm_pdw_exec_requests, kde command se spustí BuildReplicatedTableCache. Příklad:
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
Tip
Pomocí dotazů na velikost tabulky můžete ověřit, které tabulky mají replikované zásady distribuce a které jsou větší než 2 GB.
Další kroky
Pokud chcete vytvořit replikovanou tabulku, použijte jeden z těchto příkazů:
Přehled distribuovaných tabulek najdete v distribuovaných tabulkách.