Latence v úložišti objektů blob
Latence, na kterou se někdy odkazuje jako doba odezvy, je doba, po kterou musí aplikace čekat na dokončení požadavku. Latence může přímo ovlivnit výkon aplikace. Nízká latence je často důležitá pro scénáře s lidmi ve smyčce, jako je provádění transakcí platební karty nebo načítání webových stránek. Systémy, které potřebují zpracovávat příchozí události ve vysokém tempu, jako je protokolování telemetrie nebo události IoT, také vyžadují nízkou latenci. Tento článek popisuje, jak porozumět a měřit latenci operací s objekty blob bloku a jak navrhovat aplikace pro nízkou latenci.
Azure Storage nabízí dvě různé možnosti výkonu pro objekty blob bloku: Premium a Standard. Objekty blob bloku úrovně Premium nabízejí výrazně nižší a konzistentnější latenci než standardní objekty blob bloku prostřednictvím vysoce výkonných disků SSD. Další informace najdete v tématu Účty úložiště objektů blob bloku Premium.
Latence služby Azure Storage
Latence služby Azure Storage souvisí s mírami požadavků pro operace azure Storage. Frekvence požadavků se také označuje jako vstupně-výstupní operace za sekundu (IOPS).
Pokud chcete vypočítat rychlost požadavků, nejprve určete dobu, po kterou se má každý požadavek dokončit, a pak vypočítejte, kolik požadavků je možné zpracovat za sekundu. Předpokládejme například, že dokončení požadavku trvá 50 milisekund (ms). Aplikace používající jedno vlákno s jednou nevyřízenou operací čtení nebo zápisu by měla dosáhnout 20 IOPS (1 sekunda nebo 1000 ms / 50 ms na požadavek). Teoreticky pokud se počet vláken zdvojnásobí na dvě, aplikace by měla být schopná dosáhnout 40 IOPS. Pokud jsou nevyřízené asynchronní operace čtení nebo zápisu pro každé vlákno zdvojnásobené na dvě, měla by být aplikace schopná dosáhnout 80 IOPS.
Vpraxich Na straně služby může být latence proměnlivá kvůli tlaku na systém Azure Storage, rozdíly v používaných médiích úložiště, šum z jiných úloh, úlohy údržby a další faktory. Síťové připojení mezi klientem a serverem může mít vliv na latenci služby Azure Storage kvůli zahlcení, přesměrování nebo jiným přerušením.
Šířka pásma služby Azure Storage, označovaná také jako propustnost, souvisí s rychlostí požadavků a dá se vypočítat vynásobením frekvence požadavků (IOPS) velikostí požadavku. Například za předpokladu, že 160 požadavků za sekundu má každý 256 KiB dat za sekundu propustnost 40 960 KiB za sekundu nebo 40 MiB za sekundu.
Metriky latence pro objekty blob bloku
Azure Storage poskytuje dvě metriky latence pro objekty blob bloku. Tyto metriky můžete zobrazit na webu Azure Portal:
Latence E2E (End-to-End) měří interval od přijetí prvního paketu požadavku do doby, než Azure Storage přijme potvrzení klienta u posledního paketu odpovědi.
Latence serveru měří interval od přijetí posledního paketu požadavku do vrácení prvního paketu odpovědi ze služby Azure Storage.
Následující obrázek ukazuje průměrnou latenci E2E a průměrnou latenci serveru úspěchu pro ukázkovou úlohu, která volá Get Blob operaci:
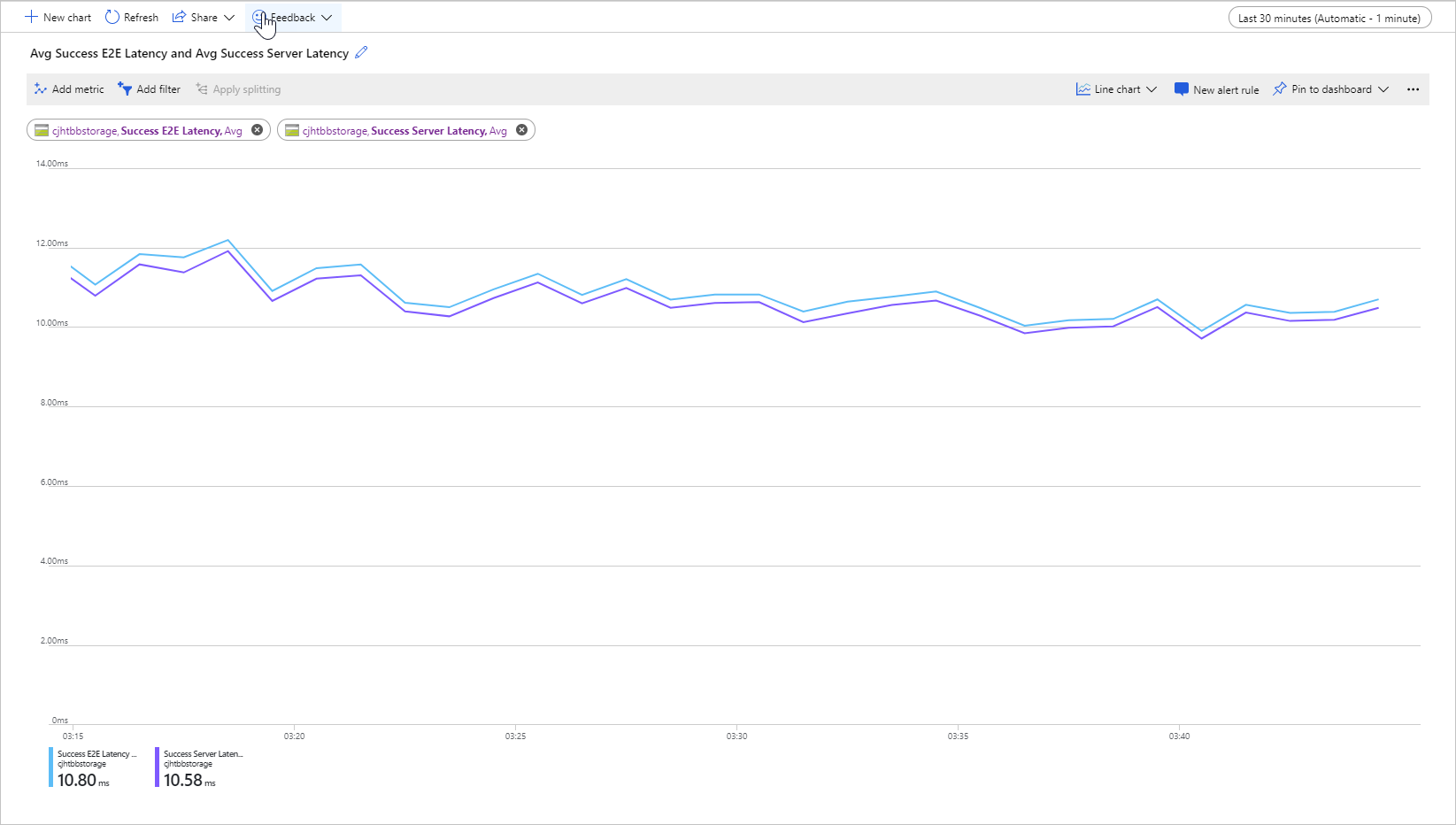
Za normálních podmínek je mezi kompletní latencí a latencí serveru malá mezera, což je to, co obrázek ukazuje pro ukázkovou úlohu.
Pokud zkontrolujete metriky latence mezi koncovými body a serverem a zjistíte, že koncová latence je výrazně vyšší než latence serveru, prozkoumejte a vyřešte zdroj další latence.
Pokud je latence koncového a serveru podobná, ale vyžadujete nižší latenci, zvažte migraci do úložiště objektů blob bloku úrovně Premium.
Faktory ovlivňující latenci
Hlavním faktorem ovlivňující latenci je velikost operace. Dokončení větších operací trvá déle, protože množství dat přenášených přes síť a zpracovávané službou Azure Storage.
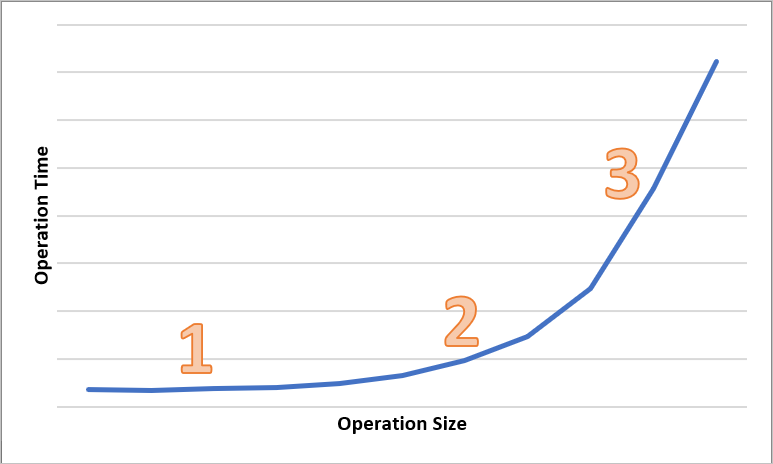
Následující diagram znázorňuje celkový čas pro operace různých velikostí. U malých objemů dat je interval latence převážně vynaložený na zpracování požadavku, nikoli na přenos dat. Interval latence se zvyšuje jen mírně, protože se velikost operace zvyšuje (v následujícím diagramu je označená jako 1). S tím, jak se velikost operace dále zvyšuje, je více času vynaloženo na přenos dat, aby se celkový interval latence rozdělil mezi zpracování požadavků a přenosem dat (v následujícím diagramu je označený jako 2). Při větších velikostech operací je interval latence téměř výhradně strávený při přenosu dat a zpracování požadavků je z velké části nevýznamné (v následujícím diagramu je označeno 3).
Faktory konfigurace klienta, jako je souběžnost a podprocesy, mají vliv také na latenci. Celková propustnost závisí na tom, kolik požadavků na úložiště probíhá v libovolném časovém okamžiku a jak vaše aplikace zpracovává vlákna. Klientské prostředky, včetně procesoru, paměti, místního úložiště a síťových rozhraní, můžou také ovlivnit latenci.
Zpracování požadavků služby Azure Storage vyžaduje prostředky procesoru a paměti klienta. Pokud je klient pod tlakem kvůli nevyužitým virtuálním počítačům nebo nějakému procesu v systému, je k dispozici méně prostředků pro zpracování požadavků služby Azure Storage. Jakékoli kolize nebo nedostatek klientských prostředků způsobí zvýšení celkové latence bez zvýšení latence serveru, což zvýší mezeru mezi těmito dvěma metrikami.
Stejně důležité je síťové rozhraní a kanál sítě mezi klientem a službou Azure Storage. Samotná fyzická vzdálenost může být významným faktorem, například pokud je klientský virtuální počítač v jiné oblasti Azure nebo v místním prostředí. Další faktory, jako jsou segmenty směrování sítě, směrování ISP a stav internetu, můžou ovlivnit celkovou latenci úložiště.
Pokud chcete vyhodnotit latenci, nejprve vytvořte základní metriky pro váš scénář. Standardní metriky poskytují očekávanou latenci koncového a koncového serveru v kontextu vašeho aplikačního prostředí v závislosti na vašem profilu úloh, nastavení konfigurace aplikace, klientských prostředcích, síťovém kanálu a dalších faktorech. Pokud máte základní metriky, můžete snadněji identifikovat neobvyklé a normální podmínky. Metriky standardních hodnot také umožňují sledovat vliv změněných parametrů, jako je konfigurace aplikace nebo velikosti virtuálních počítačů.