Migrace z místního úložiště HDFS do Azure Storage pomocí Azure Data Boxu
Data můžete migrovat z místního úložiště HDFS vašeho clusteru Hadoop do Azure Storage (blob storage nebo Data Lake Storage) pomocí zařízení Data Box. Můžete si vybrat z Data Box Disku, 80 TB Data Boxu nebo 770 TB Data Boxu Heavy.
Tento článek vám pomůže s dokončením těchto úkolů:
- Příprava na migraci dat
- Kopírování dat do zařízení Data Box Disk, Data Box nebo Data Box Heavy
- Odeslání zařízení zpět do Microsoftu
- Použití přístupových oprávnění pro soubory a adresáře (pouze Data Lake Storage)
Požadavky
K dokončení migrace potřebujete tyto věci.
Účet služby Azure Storage.
Místní cluster Hadoop, který obsahuje zdrojová data.
-
Připojte Data Box nebo Data Box Heavy k místní síti a připojte ho.
Pokud jste připraveni, začněme.
Kopírování dat do zařízení Data Box
Pokud se vaše data zapadnou do jednoho zařízení Data Box, zkopírujte data do zařízení Data Box.
Pokud velikost dat překročí kapacitu zařízení Data Box, použijte volitelný postup rozdělení dat mezi několik zařízení Data Box a pak tento krok proveďte.
Pokud chcete zkopírovat data z místního úložiště HDFS do zařízení Data Box, nastavíte několik věcí a pak použijete nástroj DistCp .
Pomocí těchto kroků zkopírujte data přes rozhraní REST API úložiště objektů blob nebo objektů do zařízení Data Box. Rozhraní REST API způsobí, že se zařízení zobrazí jako úložiště HDFS do vašeho clusteru.
Než data zkopírujete přes REST, identifikujte zabezpečení a primitiva připojení pro připojení k rozhraní REST v Data Boxu nebo Data Boxu Heavy. Přihlaste se k místnímu webovému uživatelskému rozhraní Data Boxu a přejděte na stránku Připojit a zkopírovat . V účtech úložiště Azure pro vaše zařízení v části Nastavení přístupu vyhledejte a vyberte REST.
V dialogovém okně Přístup k účtu úložiště a nahrání dat zkopírujte koncový bod služby Blob a klíč účtu úložiště. Z koncového bodu služby Blob Service vynecháte
https://koncové lomítko a koncové lomítko.V tomto případě je koncový bod:
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/. Hostitelská část identifikátoru URI, kterou používáte, je:mystorageaccount.blob.mydataboxno.microsoftdatabox.com. Podívejte se například, jak se připojit k REST přes http.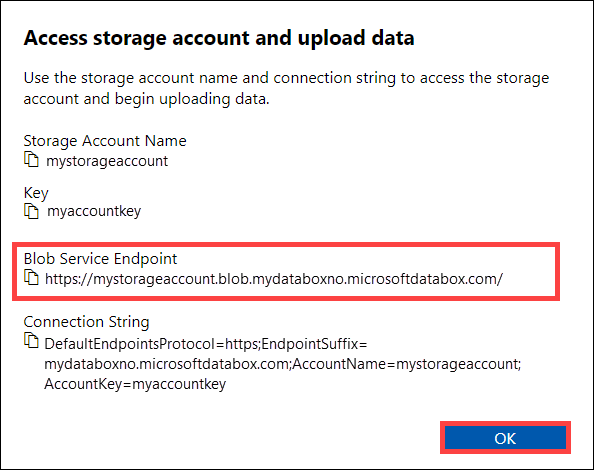
Přidejte koncový bod a IP adresu uzlu Data Box nebo Data Box Heavy do
/etc/hostskaždého uzlu.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comPokud pro DNS používáte nějaký jiný mechanismus, měli byste se ujistit, že je možné přeložit koncový bod Data Boxu.
Nastavte proměnnou
azjarsprostředí na umístěníhadoop-azuresouborů JAR aazure-storagesouborů JAR. Tyto soubory najdete v instalačním adresáři Hadoop.Chcete-li zjistit, zda tyto soubory existují, použijte následující příkaz:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure.<hadoop_install_dir>Zástupný symbol nahraďte cestou k adresáři, do kterého jste nainstalovali Hadoop. Nezapomeňte použít plně kvalifikované cesty.Příklady:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarVytvořte kontejner úložiště, který chcete použít pro kopírování dat. Jako součást tohoto příkazu byste také měli zadat cílový adresář. V tuto chvíli by to mohl být fiktivní cílový adresář.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory><blob_service_endpoint>Zástupný symbol nahraďte názvem koncového bodu služby Blob Service.<account_key>Zástupný symbol nahraďte přístupovým klíčem vašeho účtu.<container-name>Zástupný symbol nahraďte názvem kontejneru.<destination_directory>Zástupný symbol nahraďte názvem adresáře, do kterého chcete data zkopírovat.
Spuštěním příkazu list se ujistěte, že se kontejner a adresář vytvořily.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/<blob_service_endpoint>Zástupný symbol nahraďte názvem koncového bodu služby Blob Service.<account_key>Zástupný symbol nahraďte přístupovým klíčem vašeho účtu.<container-name>Zástupný symbol nahraďte názvem kontejneru.
Zkopírujte data ze systému Hadoop HDFS do úložiště objektů blob Data Boxu do kontejneru, který jste vytvořili dříve. Pokud adresář, do kterého kopírujete, nebyl nalezen, příkaz ho automaticky vytvoří.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory><blob_service_endpoint>Zástupný symbol nahraďte názvem koncového bodu služby Blob Service.<account_key>Zástupný symbol nahraďte přístupovým klíčem vašeho účtu.<container-name>Zástupný symbol nahraďte názvem kontejneru.<exclusion_filelist_file>Zástupný symbol nahraďte názvem souboru, který obsahuje seznam vyloučení souborů.<source_directory>Zástupný symbol nahraďte názvem adresáře, který obsahuje data, která chcete zkopírovat.<destination_directory>Zástupný symbol nahraďte názvem adresáře, do kterého chcete data zkopírovat.
Tato
-libjarsmožnost slouží k zpřístupnění závislýchhadoop-azure*.jarazure-storage*.jarsouborůdistcp. U některých clusterů už k tomu může dojít.Následující příklad ukazuje, jak se
distcppříkaz používá ke kopírování dat.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataZvýšení rychlosti kopírování:
Zkuste změnit počet mapovačů. (Výchozí počet mapovačů je 20. Výše uvedený příklad používá
m= 4 mappers.)Zkuste
-D fs.azure.concurrentRequestCount.out=<thread_number>to. Nahraďte<thread_number>počtem vláken na mapper. Součin počtu mapovačů a počtu vláken na mapovač nesmím*<thread_number>překročit 32.Zkuste spustit více
distcpparalelně.Mějte na paměti, že velké soubory fungují lépe než malé soubory.
Pokud máte soubory větší než 200 GB, doporučujeme změnit velikost bloku na 100 MB s následujícími parametry:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
Odeslání Data Boxu do Microsoftu
Tímto postupem připravíte a odešlete zařízení Data Box do Microsoftu.
Nejprve se připravte na odeslání data Boxu nebo Data Boxu Heavy.
Po dokončení přípravy zařízení stáhněte soubory kusovníku. Tyto soubory kusovníku nebo manifestu použijete později k ověření dat nahraných do Azure.
Vypněte zařízení a odeberte kabely.
Naplánujte vyzvednutí službou UPS.
Informace o zařízeních Data Box najdete v tématu Odeslání Data Boxu.
Informace o zařízeních Data Box Heavy najdete v tématu Odeslání Data Boxu Heavy.
Jakmile Microsoft obdrží vaše zařízení, připojí se k síti datového centra a data se nahrají do účtu úložiště, který jste zadali při zadání objednávky zařízení. Ověřte v souborech kusovníku, že se všechna vaše data nahrají do Azure.
Použití přístupových oprávnění pro soubory a adresáře (pouze Data Lake Storage)
Data už máte v účtu Azure Storage. Teď použijete přístupová oprávnění pro soubory a adresáře.
Poznámka:
Tento krok je potřeba jenom v případě, že jako úložiště dat používáte Azure Data Lake Storage. Pokud jako úložiště dat používáte jenom účet úložiště objektů blob bez hierarchického oboru názvů, můžete tuto část přeskočit.
Vytvoření instančního objektu pro účet s povolenou službou Azure Data Lake Storage
Informace o vytvoření instančního objektu najdete v tématu Postupy: Použití portálu k vytvoření aplikace Microsoft Entra a instančního objektu, který má přístup k prostředkům.
Při provádění kroků v části Přiřazení aplikace k části role článku nezapomeňte k instančnímu objektu přiřadit roli Přispěvatel dat objektů blob služby Storage.
Při provádění kroků v části Získání hodnot pro přihlášení v článku uložte ID aplikace a tajné hodnoty klienta do textového souboru. Potřebuješ je brzo.
Vygenerování seznamu zkopírovaných souborů s jejich oprávněními
Z místního clusteru Hadoop spusťte tento příkaz:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
Tento příkaz vygeneruje seznam zkopírovaných souborů s jejich oprávněními.
Poznámka:
V závislosti na počtu souborů v HDFS může spuštění tohoto příkazu trvat dlouhou dobu.
Vygenerování seznamu identit a jejich mapování na identity Microsoft Entra
copy-acls.pyStáhněte si skript. Podívejte se na pomocné skripty ke stažení a nastavte hraniční uzel tak, aby je spouštěl v části tohoto článku.Spuštěním tohoto příkazu vygenerujte seznam jedinečných identit.
./copy-acls.py -s ./filelist.json -i ./id_map.json -gTento skript vygeneruje soubor s názvem
id_map.jsonobsahující identity, které potřebujete namapovat na identity založené na doplňku.Otevřete soubor
id_map.jsonv textovém editoru.Pro každý objekt JSON, který se zobrazí v souboru, aktualizujte
targetatribut hlavního názvu uživatele Microsoft Entra (UPN) nebo ObjectId (OID) s příslušnou mapovanou identitou. Až to budete hotovi, soubor uložte. Tento soubor budete potřebovat v dalším kroku.
Použití oprávnění ke zkopírovaným souborům a použití mapování identit
Spuštěním tohoto příkazu použijte oprávnění k datům, která jste zkopírovali do účtu s povolenou službou Data Lake Storage:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
<storage-account-name>Zástupný symbol nahraďte názvem vašeho účtu úložiště.<container-name>Zástupný symbol nahraďte názvem kontejneru.<application-id>Nahraďte zástupné<client-secret>symboly ID aplikace a tajným kódem klienta, který jste shromáždili při vytváření instančního objektu.
Příloha: Rozdělení dat mezi několik zařízení Data Box
Než data přesunete na zařízení Data Box, musíte si stáhnout některé pomocné skripty, zajistit, aby se vaše data uspořádala tak, aby se vešla do zařízení Data Box, a vyloučit všechny nepotřebné soubory.
Stáhněte si pomocné skripty a nastavte hraniční uzel tak, aby je spouštěl.
Z hraničního nebo hlavního uzlu místního clusteru Hadoop spusťte tento příkaz:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderTento příkaz naklonuje úložiště GitHub, které obsahuje pomocné skripty.
Ujistěte se, že je v místním počítači nainstalovaný balíček jq .
sudo apt-get install jqNainstalujte balíček Requests python.
pip install requestsNastavte oprávnění ke spuštění požadovaných skriptů.
chmod +x *.py *.sh
Ujistěte se, že jsou vaše data uspořádaná tak, aby se vešla do zařízení Data Box.
Pokud velikost dat překračuje velikost jednoho zařízení Data Box, můžete soubory rozdělit do skupin, které můžete uložit na několik zařízení Data Box.
Pokud vaše data nepřekračují velikost zařízení Data Box, můžete přejít k další části.
Se zvýšenými oprávněními spusťte
generate-file-listskript, který jste stáhli, podle pokynů v předchozí části.Tady je popis parametrů příkazu:
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.Zkopírujte vygenerované seznamy souborů do HDFS, aby byly přístupné pro úlohu DistCp .
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
Vyloučení nepotřebných souborů
Některé adresáře musíte z úlohy DisCp vyloučit. Vylučte například adresáře, které obsahují informace o stavu, které udržují cluster spuštěný.
V místním clusteru Hadoop, kde plánujete zahájit úlohu DistCp, vytvořte soubor, který určuje seznam adresářů, které chcete vyloučit.
Tady je příklad:
.*ranger/audit.*
.*/hbase/data/WALs.*
Další kroky
Zjistěte, jak Data Lake Storage funguje s clustery HDInsight. Další informace najdete v tématu Použití služby Azure Data Lake Storage s clustery Azure HDInsight.