Co jsou provozní kontinuita, vysoká dostupnost a zotavení po havárii?
Tento článek definuje a popisuje plánování kontinuity podnikových procesů a kontinuity podnikových procesů z hlediska správy rizik prostřednictvím návrhu vysoké dostupnosti a zotavení po havárii. I když tento článek neposkytuje explicitní pokyny k tomu, jak splnit vaše vlastní potřeby provozní kontinuity, pomůže vám pochopit koncepty, které se používají v rámci pokynů microsoftu ke spolehlivosti.
Provozní kontinuita je stav, ve kterém může firma pokračovat v provozu během selhání, výpadků nebo havárií. Kontinuita podnikových procesů vyžaduje proaktivní plánování, přípravu a implementaci odolných systémů a procesů.
Plánování kontinuity podnikových procesů vyžaduje identifikaci, pochopení, klasifikaci a správu rizik. Na základě rizik a jejich pravděpodobností navrhujte vysokou dostupnost (HA) i zotavení po havárii (DR).
Vysoká dostupnost spočívá v návrhu řešení, které je odolné vůči každodenním problémům a splnění obchodních potřeb pro dostupnost.
Zotavení po havárii spočívá v plánování řešení neobvyklých rizik a katastrofických výpadků, které můžou mít za následek.
Kontinuita podnikových procesů
Cloudová řešení jsou obecně svázaná přímo s obchodními operacemi. Kdykoli je cloudové řešení nedostupné nebo dochází k závažnému problému, může být dopad na obchodní operace závažný. Závažný dopad může narušit kontinuitu podnikových procesů.
Mezi závažné dopady na kontinuitu podnikových procesů patří:
- Ztráta obchodního příjmu.
- Nemožnost poskytovat uživatelům důležitou službu.
- Porušení závazku, který byl proveden zákazníkovi nebo jiné straně.
Je důležité pochopit a sdělit obchodní očekávání a důsledky selhání důležitým zúčastněným stranám, včetně těch, kteří navrhují, implementují a provozují úlohy. Tyto zúčastněné strany pak reagují sdílením nákladů spojených se schůzkou této vize. Obvykle existuje proces vyjednávání a revizí této vize na základě rozpočtu a dalších omezení.
Plánování kontinuity podnikových procesů
Pokud chcete řídit nebo úplně zabránit negativnímu dopadu na kontinuitu podnikových procesů, je důležité proaktivně vytvořit plán provozní kontinuity. Plán kontinuity podnikových procesů je založený na posouzení rizik a vývoji metod řízení těchto rizik prostřednictvím různých přístupů. Konkrétní rizika a přístupy ke zmírnění se liší pro každou organizaci a úlohu.
Plán provozní kontinuity nebere v úvahu jenom funkce odolnosti samotné cloudové platformy, ale také funkce aplikace. Robustní plán provozní kontinuity zahrnuje také všechny aspekty podpory v podniku, včetně lidí, ručních nebo automatizovaných procesů souvisejících s podnikáním a dalších technologií.
Plánování kontinuity podnikových procesů by mělo zahrnovat následující postupné kroky:
Identifikace rizik. Identifikujte rizika pro dostupnost nebo funkčnost úlohy. Možná rizika mohou být problémy se sítí, selhání hardwaru, lidské chyby, výpadek oblasti atd. Seznamte se s dopadem jednotlivých rizik.
Klasifikace rizik. Klasifikujte každé riziko jako buď běžné riziko, které by mělo být začleněno do plánů vysoké dostupnosti, nebo neobvyklé riziko, které by mělo být součástí plánování zotavení po havárii.
Zmírnění rizik. Strategie zmírnění rizik pro vysokou dostupnost nebo zotavení po havárii pro minimalizaci nebo zmírnění rizik, jako je použití redundance, replikace, převzetí služeb při selhání a zálohování Zvažte také netechnické a procesní zmírnění a kontroly.
Plánování kontinuity podnikových procesů je proces, nikoli jednorázová událost. Každý vytvořený plán provozní kontinuity by se měl pravidelně kontrolovat a aktualizovat, aby se zajistilo, že zůstane relevantní a efektivní a že podporuje aktuální obchodní potřeby.
Identifikace rizik
Počáteční fází plánování kontinuity podnikových procesů je identifikace rizik pro dostupnost nebo funkčnost úlohy. Každé riziko by se mělo analyzovat, aby bylo možné porozumět jejich pravděpodobnosti a závažnosti. Závažnost musí zahrnovat případné výpadky nebo ztrátu dat a také to, jestli by některé aspekty zbytku návrhu řešení mohly kompenzovat negativní účinky.
Následující tabulka obsahuje seznam rizik, která nejsou vyčerpávající, seřazená snížením pravděpodobnosti:
| Příklad rizika | Popis | Pravidelnost (pravděpodobnost) |
|---|---|---|
| Přechodný problém se sítí | Dočasná chyba v komponentě síťového zásobníku, která se dá obnovit po krátké době (obvykle několik sekund nebo méně). | Regulární |
| Restartování virtuálního počítače | Restartování virtuálního počítače, který používáte nebo kterou používá závislá služba. K restartování může dojít, protože virtuální počítač se chybově ukončí nebo potřebuje použít opravu. | Regulární |
| Selhání hardwaru | Selhání komponenty v rámci datacentra, například hardwarového uzlu, racku nebo clusteru | Občasný |
| Výpadek datacentra | Výpadek, který ovlivňuje většinu nebo všechna datacentra, jako je selhání napájení, problém s připojením k síti nebo problémy s topením a chlazením. | Neobyčejný |
| Výpadek oblasti | Výpadek, který ovlivňuje celou metropolitní oblast nebo širší oblast, například velkou přírodní katastrofu. | Velmi neobvyklé |
Plánování kontinuity podnikovýchprocesůch Je důležité zvážit riziko lidských chyb. Kromě toho by se některá rizika, která by mohla tradičně považovat za zabezpečení, výkon nebo provozní rizika, by se také měla považovat za rizika spolehlivosti, protože ovlivňují dostupnost řešení.
Několik příkladů:
| Příklad rizika | Popis |
|---|---|
| Ztráta nebo poškození dat | Data byla odstraněna, přepsána nebo jinak poškozena nehodou nebo z porušení zabezpečení, jako je útok ransomwarem. |
| Chyba softwaru | Nasazení nového nebo aktualizovaného kódu zavádí chybu, která má vliv na dostupnost nebo integritu, takže úloha zůstane ve špatném stavu. |
| Neúspěšná nasazení | Nasazení nové komponenty nebo verze se nezdařilo a řešení zůstane v nekonzistentním stavu. |
| Útoky na dostupnost služby | Systém byl napaden pokusem o zabránění legitimnímu použití řešení. |
| Neautorní správci | Uživatel s oprávněními správce úmyslně provedl škodlivý zásah proti systému. |
| Neočekávaný nárůst provozu do aplikace | Špička provozu zahltila prostředky systému. |
Analýza režimu selhání (FMA) je proces identifikace možných způsobů, kterými může úloha nebo její komponenty selhat a jak se řešení v těchto situacích chová. Další informace najdete v tématu Doporučení k provádění analýzy režimu selhání.
Klasifikace rizik
Plány provozní kontinuity musí řešit běžná i neobvyklá rizika.
Běžná rizika se plánují a očekávají. V cloudovém prostředí je například běžné, že dojde k přechodným selháním , včetně krátkých výpadků sítě, restartování zařízení kvůli opravám, vypršení časového limitu, kdy je služba zaneprázdněná atd. Vzhledem k tomu, že k těmto událostem dochází pravidelně, musí být úlohy odolné vůči nim.
Strategie vysoké dostupnosti musí zvážit a řídit každé riziko tohoto typu.
Neobvyklá rizika jsou obvykle výsledkem nepředvídatelné události, jako je přírodní katastrofa nebo velký síťový útok, což může vést ke katastrofickému výpadku.
Procesy zotavení po havárii řeší tato vzácná rizika.
Vysoká dostupnost a zotavení po havárii jsou vzájemně propojené, a proto je důležité naplánovat strategie pro obě tyto strategie společně.
Je důležité si uvědomit, že klasifikace rizik závisí na architektuře úloh a obchodních požadavcích a některá rizika se dají klasifikovat jako vysoká dostupnost pro jednu úlohu a zotavení po havárii pro jinou úlohu. Například úplný výpadek oblasti Azure by se obecně považoval za riziko zotavení po havárii pro úlohy v této oblasti. U úloh, které používají více oblastí Azure v konfiguraci aktivní-aktivní s úplnou replikací, redundancí a automatickým převzetím služeb při selhání oblastí, se ale výpadek oblasti klasifikuje jako riziko vysoké dostupnosti.
Omezení rizik
Zmírnění rizik se skládá z vývoje strategií pro vysokou dostupnost nebo zotavení po havárii za účelem minimalizace nebo zmírnění rizik pro provozní kontinuitu. Zmírnění rizik může být založené na technologiích nebo na lidské závislosti.
Zmírnění rizik na základě technologií
Technologické zmírnění rizik využívá kontroly rizik, které jsou založené na způsobu implementace a konfigurace úlohy, například:
- Redundance
- Replikace dat
- Převzetí služeb při selhání
- Zálohování
Kontroly rizik založené na technologiích musí být považovány za kontext plánu kontinuity podnikových procesů.
Příklad:
Požadavky na nízké prostoje Některé plány provozní kontinuity nemohou tolerovat žádnou formu rizika výpadků z důvodu striktních požadavků na vysokou dostupnost . Existují určité kontroly založené na technologiích, které mohou vyžadovat čas na to, aby byl člověk upozorněn a pak reagoval. Kontroly rizik založené na technologiích, které zahrnují pomalé ruční procesy, budou pravděpodobně nevhodné pro zahrnutí do strategie zmírnění rizik.
Tolerance k částečnému selhání. Některé plány provozní kontinuity jsou schopné tolerovat pracovní postup, který běží v degradovaném stavu. Když řešení pracuje v degradovaném stavu, můžou být některé komponenty zakázané nebo nefunkční, ale základní obchodní operace se můžou dál provádět. Další informace najdete v tématu Doporučení pro samoopravení a sebezáchování.
Zmírnění rizik na základě člověka
Zmírnění rizik na základě člověka používá kontroly rizik, které jsou založené na obchodních procesech, například:
- Aktivace playbooku odpovědí
- Návrat k ručním operacím.
- Školení a kulturní změny.
Důležité
Jednotlivci, kteří navrhují, implementují, provozují a vyvíjejí úlohu, by měla být příslušná, povzbuzovala k tomu, aby mluvila, pokud mají obavy, a cítili pocit odpovědnosti za systém.
Vzhledem k tomu, že kontroly rizik založené na lidských faktorech jsou často pomalejší než kontroly založené na technologiích a náchylnější k lidské chybě, měl by dobrý plán provozní kontinuity zahrnovat formální proces řízení změn pro cokoli, co by změnilo stav spuštěného systému. Zvažte například implementaci následujících procesů:
- Pečlivě testujte úlohy v souladu se závažností úloh. Pokud chcete zabránit problémům souvisejícím se změnami, nezapomeňte otestovat všechny změny provedené v úloze.
- Zavedení strategických bran kvality v rámci postupů bezpečného nasazení vaší úlohy Další informace najdete v tématu Doporučení pro postupy bezpečného nasazení.
- Formalizace postupů pro ad hoc produkční přístup a manipulaci s daty Tyto aktivity, bez ohledu na to, jak malé, mohou představovat vysoké riziko způsobující incidenty spolehlivosti. Postupy můžou zahrnovat párování s jiným inženýrem, používání kontrolních seznamů a získávání partnerských kontrol před spuštěním skriptů nebo použitím změn.
Vysoká dostupnost
Vysoká dostupnost je stav, ve kterém může konkrétní úloha udržovat potřebnou úroveň provozu na denní bázi, a to i v případě přechodných chyb a občasných selhání. Vzhledem k tomu, že k těmto událostem dochází pravidelně, je důležité, aby každá úloha byla navržena a nakonfigurována pro zajištění vysoké dostupnosti v souladu s požadavky konkrétní aplikace a očekávání zákazníků. Vysoká dostupnost jednotlivých úloh přispívá k vašemu plánu provozní kontinuity.
Vzhledem k tomu, že se vysoká dostupnost může u jednotlivých úloh lišit, je důležité porozumět požadavkům a očekáváním zákazníků při určování vysoké dostupnosti. Například aplikace, kterou vaše organizace používá k objednávání kancelářských dodávek, může vyžadovat relativně nízkou úroveň provozuschopnosti, zatímco kritická finanční aplikace může vyžadovat mnohem vyšší dobu provozu. I v rámci úlohy můžou mít různé toky různé požadavky. Například v aplikaci elektronického obchodování můžou být toky, které podporují procházení a zadávání objednávek zákazníkům, důležitější než plnění objednávek a toky zpracování back-office. Další informace o tocích najdete v tématu Doporučení pro identifikaci a hodnocení toků.
Doba provozu se obvykle měří na základě počtu "devítky" v procentech doby provozu. Procento doby provozu souvisí s tím, kolik výpadků můžete v daném časovém období povolit. Několik příkladů:
- Požadavek na dobu provozu 99,9 % (tři devítky) umožňuje přibližně 43 minut výpadků za měsíc.
- Požadavek na dobu provozu 99,95 % (tři a půl devítky) umožňuje přibližně 21 minut výpadků za měsíc.
Čím vyšší je požadavek na dobu provozu, tím menší odolnost vůči výpadkům máte, a čím více práce musíte udělat, abyste dosáhli této úrovně dostupnosti. Doba provozu se neměří podle doby provozu jedné komponenty, jako je uzel, ale celkovou dostupností celé úlohy.
Důležité
Nepřetěžujte své řešení, aby se dosáhlo vyšší úrovně spolehlivosti, než je odůvodněné. Při rozhodování využijte obchodní požadavky.
Prvky návrhu s vysokou dostupností
Aby bylo možné dosáhnout požadavků na vysokou dostupnost, může úloha obsahovat řadu prvků návrhu. Některé běžné prvky jsou uvedeny a popsány níže v této části.
Poznámka:
Některé úlohy jsou klíčové, což znamená, že jakékoli výpadky můžou mít závažné důsledky pro lidské životy a bezpečnost nebo významné finanční ztráty. Pokud navrhujete kritickou úlohu, je potřeba při návrhu řešení myslet na konkrétní věci a spravovat provozní kontinuitu. Další informace najdete v architektuře Azure Well-Architected Framework: Klíčové úlohy.
Služby a úrovně Azure, které podporují vysokou dostupnost
Řada služeb Azure je navržená tak, aby byla vysoce dostupná a dá se použít k vytváření vysoce dostupných úloh. Několik příkladů:
- Škálovací sady virtuálních počítačů Azure poskytují vysokou dostupnost virtuálních počítačů tím, že automaticky vytváří a spravuje instance virtuálních počítačů a distribuuje tyto instance virtuálních počítačů, aby se snížil dopad selhání infrastruktury.
- služba Aplikace Azure poskytuje vysokou dostupnost prostřednictvím různých přístupů, včetně automatického přesouvání pracovních procesů z uzlu, který není v pořádku, na uzel, který je v pořádku, a poskytuje možnosti pro samoopravení z mnoha běžných typů chyb.
Pomocí průvodce spolehlivostí jednotlivých služeb se seznamte s možnostmi služby, rozhodněte se, které úrovně se mají použít, a určete, které možnosti mají být součástí vaší strategie vysoké dostupnosti.
Projděte si smlouvy o úrovni služeb (SLA) pro každou službu, abyste porozuměli očekávaným úrovním dostupnosti a podmínkám, které potřebujete splnit. Možná budete muset vybrat konkrétní úrovně služeb nebo se jim vyhnout, abyste dosáhli určitých úrovní dostupnosti. Některé služby od Microsoftu se nabízejí s pochopením, že není poskytována žádná smlouva SLA, jako je vývoj nebo úroveň Basic, nebo že by se prostředek mohl uvolnit z vašeho spuštěného systému, jako jsou nabídky založené na spotech. Některé úrovně navíc přidaly funkce spolehlivosti, jako je podpora zón dostupnosti.
Odolnost proti chybám
Odolnost proti chybám je schopnost systému pokračovat v provozu v některých definovaných kapacitách v případě selhání. Webová aplikace může být například navržená tak, aby pokračovala v provozu i v případě, že selže jeden webový server. Odolnost proti chybám je možné dosáhnout prostřednictvím redundance, převzetí služeb při selhání, dělení, řádného snížení výkonu a dalších technik.
Odolnost proti chybám také vyžaduje, aby vaše aplikace zvládly přechodné chyby. Při vytváření vlastního kódu možná budete muset povolit zpracování přechodných chyb sami. Některé služby Azure poskytují integrované zpracování přechodných chyb v některých situacích. Azure Logic Apps například ve výchozím nastavení automaticky opakuje neúspěšné požadavky na jiné služby. Další informace najdete v tématu Doporučení pro zpracování přechodných chyb.
Redundance
Redundance je postup duplikování instancí nebo dat za účelem zvýšení spolehlivosti úlohy.
Redundanci je možné dosáhnout distribucí replik nebo redundantních instancí jedním z následujících způsobů:
- Uvnitř datacentra (místní redundance)
- Mezi zónami dostupnosti v rámci oblasti (redundance zóny)
- Napříč oblastmi (geografická redundance).
Tady je několik příkladů, jak některé služby Azure poskytují možnosti redundance:
- Aplikace Azure Služba umožňuje spouštět více instancí aplikace, abyste zajistili, že aplikace zůstane dostupná i v případě, že selže jedna instance. Pokud povolíte redundanci zón, tyto instance se rozdělí mezi několik zón dostupnosti v oblasti Azure, kterou používáte.
- Azure Storage poskytuje vysokou dostupnost tím, že automaticky replikuje data alespoň třikrát. Tyto repliky můžete distribuovat mezi zóny dostupnosti tím, že povolíte zónově redundantní úložiště (ZRS) a v mnoha oblastech můžete také replikovat data úložiště napříč oblastmi pomocí geograficky redundantního úložiště (GRS).
- Azure SQL Database má více replik, aby se zajistilo, že data zůstanou dostupná i v případě, že selže jedna replika.
Další informace o redundanci najdete v tématu Doporučení pro navrhování redundance a doporučení pro použití zón dostupnosti a oblastí.
Škálovatelnost a elasticita
Škálovatelnost a elasticita jsou schopnosti systému zpracovávat zvýšené zatížení přidáním a odebráním prostředků (škálovatelnosti) a rychle, když se vaše požadavky mění (elasticita). Škálovatelnost a elasticita můžou pomoci systému udržovat dostupnost během špičky.
Mnoho služeb Azure podporuje škálovatelnost. Několik příkladů:
- Škálovací sady virtuálních počítačů Azure, Azure API Management a několik dalších služeb podporují automatické škálování služby Azure Monitor. Pomocí automatického škálování služby Azure Monitor můžete zadat zásady, jako je například "když můj procesor konzistentně překročí 80 %, přidejte další instanci".
- Azure Functions může dynamicky zřizovat instance pro obsluhu vašich požadavků.
- Azure Cosmos DB podporuje propustnost automatického škálování, kdy služba může automaticky spravovat prostředky přiřazené k vašim databázím na základě vámi zadaných zásad.
Škálovatelnost je klíčovým faktorem, který je potřeba vzít v úvahu během částečné nebo úplné poruchy. Pokud replika nebo výpočetní instance není k dispozici, zbývající komponenty možná budou muset nést větší zatížení, aby zvládly zatížení, které dříve zpracovával chybovaný uzel. Zvažte nadměrné zřízení , pokud váš systém nemůže dostatečně rychle škálovat, aby zvládl očekávané změny zatížení.
Další informace o tom, jak navrhnout škálovatelný a elastický systém, najdete v tématu Doporučení pro návrh strategie spolehlivého škálování.
Techniky nasazení nulového výpadku
Nasazení a další změny systému představují významné riziko výpadků. Vzhledem k tomu, že riziko výpadků je výzvou pro požadavky na vysokou dostupnost, je důležité použít postupy nasazení nulového výpadku k provádění aktualizací a změn konfigurace bez nutnosti výpadků.
Techniky nasazení nulového výpadku můžou zahrnovat:
- Aktualizace podmnožině prostředků najednou
- Řízení objemu provozu, který dosáhne nového nasazení
- Monitorování jakéhokoli dopadu na uživatele nebo systém
- Rychle opravíte problém, například vrácením zpět k předchozímu známému dobrému nasazení.
Další informace o technikách nasazení bez výpadků najdete v tématu Postupy bezpečného nasazení.
Samotný Azure používá pro naše vlastní služby přístupy k nasazení s nulovým výpadkem. Při vytváření vlastních aplikací můžete nasazení s nulovými výpadky přijmout prostřednictvím různých přístupů, například:
- Azure Container Apps poskytuje více revizí vaší aplikace, které je možné použít k dosažení nasazení s nulovými výpadky.
- Azure Kubernetes Service (AKS) podporuje celou řadu technik nasazení bez výpadků.
I když nasazení s nulovými výpadky jsou často přidružená k nasazením aplikací, měly by se také použít ke změnám konfigurace. Tady je několik způsobů, jak bezpečně použít změny konfigurace:
- Azure Storage umožňuje změnit přístupové klíče účtu úložiště v několika fázích, což brání výpadkům během operací obměny klíčů.
- Aplikace Azure Konfigurace poskytuje příznaky funkcí, snímky a další funkce, které vám pomůžou řídit způsob použití změn konfigurace.
Pokud se rozhodnete neimplementovat nasazení s nulovými výpadky, ujistěte se, že definujete časová období údržby, abyste mohli provádět změny systému v době, kdy je uživatelé očekávají.
Automatické testování
Je důležité otestovat schopnost vašeho řešení odolat výpadkům a selháním, které považujete za účelem zajištění vysoké dostupnosti. Mnohé z těchto selhání je možné simulovat v testovacích prostředích. Testování schopnosti vašeho řešení automaticky tolerovat nebo zotavit se z různých typů chyb se nazývá chaos engineering. Chaos engineering je kritický pro vyspělé organizace s přísnými standardy pro vysokou dostupnost. Azure Chaos Studio je nástroj pro přípravu chaosu, který dokáže simulovat některé běžné typy chyb.
Další informace najdete v tématu Doporučení pro návrh strategie testování spolehlivosti.
Monitorování a upozorňování
Monitorování vás informuje o stavu systému, a to i v případě, že proběhne automatizované zmírnění rizik. Monitorování je důležité pro pochopení toho, jak se vaše řešení chová, a sledovat počáteční signály selhání, jako je zvýšení míry chyb nebo vysoká spotřeba prostředků. Díky upozorněním můžete proaktivně přijímat důležité změny ve vašem prostředí.
Azure nabízí celou řadu možností monitorování a upozorňování, včetně následujících:
- Azure Monitor shromažďuje protokoly a metriky z prostředků a aplikací Azure a může odesílat výstrahy a zobrazovat data na řídicích panelech.
- Azure Monitor Application Insights poskytuje podrobné monitorování vašich aplikací.
- Azure Service Health a Azure Resource Health monitorují stav platformy Azure a vašich prostředků.
- Naplánované události radí, kdy je naplánována údržba virtuálních počítačů.
Další informace najdete v tématu Doporučení pro návrh spolehlivé strategie monitorování a upozorňování.
Zotavení po havárii
Havárie je jedinečná, neobvyklá a závažná událost, která má větší a delší dopad, než aplikace může zmírnit prostřednictvím aspektu vysoké dostupnosti návrhu. Mezi příklady havárií patří:
- Přírodní katastrofy, jako jsou hurikány, zemětřesení, záplavy nebo požáry.
- Lidské chyby, které mají za následek velký dopad, jako je náhodné odstranění produkčních dat nebo chybně nakonfigurovaná brána firewall, která zveřejňuje citlivá data.
- Závažné bezpečnostní incidenty, jako jsou útoky na dostupnost služby nebo ransomware, které vedou k poškození dat, ztrátě dat nebo výpadkům služeb.
Zotavení po havárii spočívá v plánování reakce na tyto typy situací.
Poznámka:
Měli byste dodržovat doporučené postupy v rámci vašeho řešení, abyste minimalizovali pravděpodobnost těchto událostí. I po pečlivém proaktivním plánování je však vhodné naplánovat, jak byste na tyto situace reagovali, pokud dojde k jejich vzniku.
Požadavky na zotavení po havárii
Vzhledem k raritě a závažnosti událostí havárie přináší plánování zotavení po havárii různá očekávání pro vaši reakci. Mnoho organizací přijímá skutečnost, že v případě havárie je určitá úroveň výpadku nebo ztráty dat nepochybná. Úplný plán zotavení po havárii musí pro každý tok zadat následující důležité obchodní požadavky:
Cíl bodu obnovení (RPO) je maximální přijatelná doba trvání přijatelné ztráty dat v případě havárie. RPO se měří v jednotkách času, například "30 minut dat" nebo "čtyři hodiny dat".
Cíl doby obnovení (RTO) je maximální přijatelná doba trvání výpadku v případě havárie, kdy specifikace definuje "výpadek". RTO se měří také v jednotkách času, například "osm hodin výpadku".
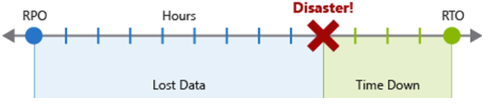
Každá komponenta nebo tok v úloze můžou mít jednotlivé hodnoty RPO a RTO. Prozkoumejte rizika scénáře havárie a potenciální strategie zotavení při rozhodování o požadavcích. Proces určení cíle bodu obnovení (RPO) a RTO efektivně vytváří požadavky na zotavení po havárii pro vaši úlohu v důsledku jedinečných obchodních obav (náklady, dopad, ztráta dat atd.).
Poznámka:
I když je lákavé zaměřit se na plánovanou dobu obnovení a cíl bodu obnovení nuly (bez výpadků a ztráty dat v případě havárie), je v praxi obtížné a nákladné implementovat. Je důležité, aby technické a obchodní zúčastněné strany projednaly tyto požadavky společně a rozhodly se o realistických požadavcích. Další informace najdete v tématu Doporučení pro definování cílů spolehlivosti.
Plány zotavení po havárii
Bez ohledu na příčinu havárie je důležité vytvořit dobře definovaný a testovatelný plán zotavení po havárii. Tento plán se použije jako součást návrhu infrastruktury a aplikace, aby ho aktivně podporoval. Můžete vytvořit více plánů zotavení po havárii pro různé typy situací. Plány zotavení po havárii se často spoléhají na řízení procesů a ruční zásah.
Zotavení po havárii není automatická funkce Azure. Mnoho služeb ale poskytuje funkce a možnosti, které můžete použít k podpoře strategií zotavení po havárii. Měli byste si projít příručky pro spolehlivost jednotlivých služeb Azure, abyste pochopili, jak služba funguje, a její schopnosti a pak je namapujte na plán zotavení po havárii.
Následující části obsahují seznam některých běžných prvků plánu zotavení po havárii a popisují, jak vám může Azure pomoct s jejich dosažením.
Převzetí služeb při selhání a navrácení služeb po obnovení
Některé plány zotavení po havárii zahrnují zřízení sekundárního nasazení v jiném umístění. Pokud havárie ovlivní primární nasazení řešení, provoz pak může převzít služby při selhání do jiné lokality. Převzetí služeb při selhání vyžaduje pečlivé plánování a implementaci. Azure poskytuje celou řadu služeb, které vám pomůžou s převzetím služeb při selhání, například:
- Azure Site Recovery poskytuje automatizované převzetí služeb při selhání pro místní prostředí a řešení hostovaná virtuálními počítači v Azure.
- Azure Front Door a Azure Traffic Manager podporují automatizované převzetí služeb při selhání příchozího provozu mezi různými nasazeními vašeho řešení, například v různých oblastech.
Než proces převzetí služeb při selhání zjistí, že primární instance selhala, a přechod na sekundární instanci obvykle nějakou dobu trvá. Ujistěte se, že rto úlohy je v souladu s časem převzetí služeb při selhání.
Je také důležité zvážit navrácení služeb po obnovení, což je proces obnovení operací v primární oblasti po obnovení. Navrácení služeb po obnovení může být složité pro plánování a implementaci. Například data v primární oblasti můžou být zapsána po zahájení převzetí služeb při selhání. Budete muset pečlivě rozhodovat o tom, jak tato data zpracováváte.
Zálohování
Zálohování zahrnuje pořízení kopie dat a jejich bezpečné uložení po definovanou dobu. Při zálohování se můžete zotavit z havárií, když automatické převzetí služeb při selhání na jinou repliku není možné nebo když dojde k poškození dat.
Při použití záloh v rámci plánu zotavení po havárii je důležité vzít v úvahu následující skutečnosti:
Umístění úložiště. Pokud používáte zálohy jako součást plánu zotavení po havárii, měly by se ukládat samostatně na hlavní data. Zálohy se obvykle ukládají v jiné oblasti Azure.
Ztráta dat. Vzhledem k tomu, že zálohy se obvykle provádějí zřídka, obnovení zálohování obvykle zahrnuje ztrátu dat. Z tohoto důvodu by se mělo obnovení zálohování použít jako poslední možnost a plán zotavení po havárii by měl určovat posloupnost kroků a pokusů o obnovení, které musí proběhnout před obnovením ze zálohy. Je důležité zajistit, aby byl cíl bodu obnovení úlohy v souladu s intervalem zálohování.
Doba obnovení. Obnovení zálohování často trvá dlouho, takže je důležité otestovat zálohy a procesy obnovení, abyste ověřili jejich integritu a pochopili, jak dlouho proces obnovení trvá. Ujistěte se, že rto úlohy tvoří dobu potřebnou k obnovení zálohy.
Mnoho datových služeb Azure a služeb úložiště podporuje zálohování, například následující:
- Azure Backup poskytuje automatizované zálohy pro disky virtuálních počítačů, účty úložiště, AKS a různé další zdroje.
- Mnoho databázových služeb Azure, včetně Azure SQL Database a Azure Cosmos DB, má pro vaše databáze možnost automatizovaného zálohování.
- Azure Key Vault poskytuje funkce pro zálohování tajných kódů, certifikátů a klíčů.
Automatizovaná nasazení
K rychlému nasazení a konfiguraci požadovaných prostředků v případě havárie použijte prostředky infrastruktury jako kódu (IaC), jako jsou soubory Bicep, šablony ARM nebo konfigurační soubor Terraformu. Použití IaC zkracuje dobu obnovení a potenciál chyby v porovnání s ručním nasazováním a konfigurací prostředků.
Testování a přechod k podrobnostem
Je důležité pravidelně ověřovat a testovat plány zotavení po havárii a také širší strategii spolehlivosti. Do podrobností zahrňte všechny lidské procesy a nezaměřte se jen na technické procesy.
Pokud jste procesy zotavení neotestovali v simulaci havárie, pravděpodobně budete při jejich použití ve skutečné havárii čelit velkým problémům. Testováním plánů zotavení po havárii a požadovaných procesů můžete také ověřit proveditelnost rto.
Další informace najdete v tématu Doporučení pro návrh strategie testování spolehlivosti.
Související obsah
- Pomocí průvodců spolehlivostí služeb Azure získáte informace o tom, jak každá služba Azure podporuje spolehlivost v jejím návrhu, a dozvíte se o možnostech, které můžete integrovat do plánů vysoké dostupnosti a zotavení po havárii.
- Využijte architekturu Azure Well-Architected Framework: Pilíř spolehlivosti, abyste se dozvěděli více o tom, jak navrhnout spolehlivé úlohy v Azure.
- Pomocí perspektivy dobře navržená architektura ve službách Azure se dozvíte více o tom, jak nakonfigurovat každou službu Azure tak, aby splňovala vaše požadavky na spolehlivost a v rámci dalších pilířů dobře navržená architektura.
- Další informace o plánování zotavení po havárii najdete v tématu Doporučení pro návrh strategie zotavení po havárii.