Agregace transformace v mapování toku dat
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Toky dat jsou k dispozici ve službě Azure Data Factory i v kanálech Azure Synapse. Tento článek se týká mapování toků dat. Pokud s transformacemi začínáte, přečtěte si úvodní článek Transformace dat pomocí mapování toku dat.
Transformace Agregace definuje agregace sloupců v datových proudech. Pomocí Tvůrce výrazů můžete definovat různé typy agregací, jako je SUMA, MIN, MAX a COUNT seskupené podle existujících nebo počítaných sloupců.
Seskupit podle
Vyberte existující sloupec nebo vytvořte nový počítaný sloupec, který se použije jako klauzule seskupit podle agregace. Pokud chcete použít existující sloupec, vyberte ho v rozevíracím seznamu. Pokud chcete vytvořit nový počítaný sloupec, najeďte myší na klauzuli a klikněte na Vypočítaný sloupec. Tím se otevře tvůrce výrazů toku dat. Po vytvoření počítaného sloupce zadejte název výstupního sloupce pod pole Název jako . Pokud chcete přidat další klauzuli group by, najeďte myší na existující klauzuli a klikněte na ikonu plus.
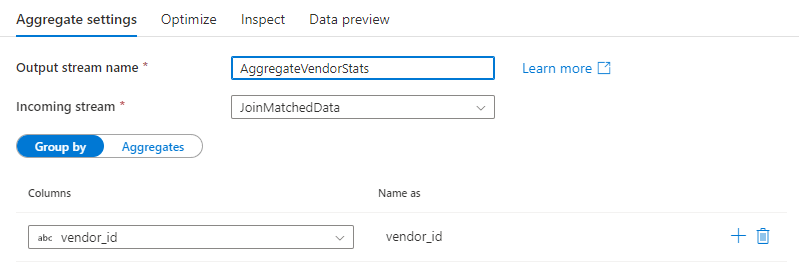
Klauzule group by je volitelná v agregační transformaci.
Agregované sloupce
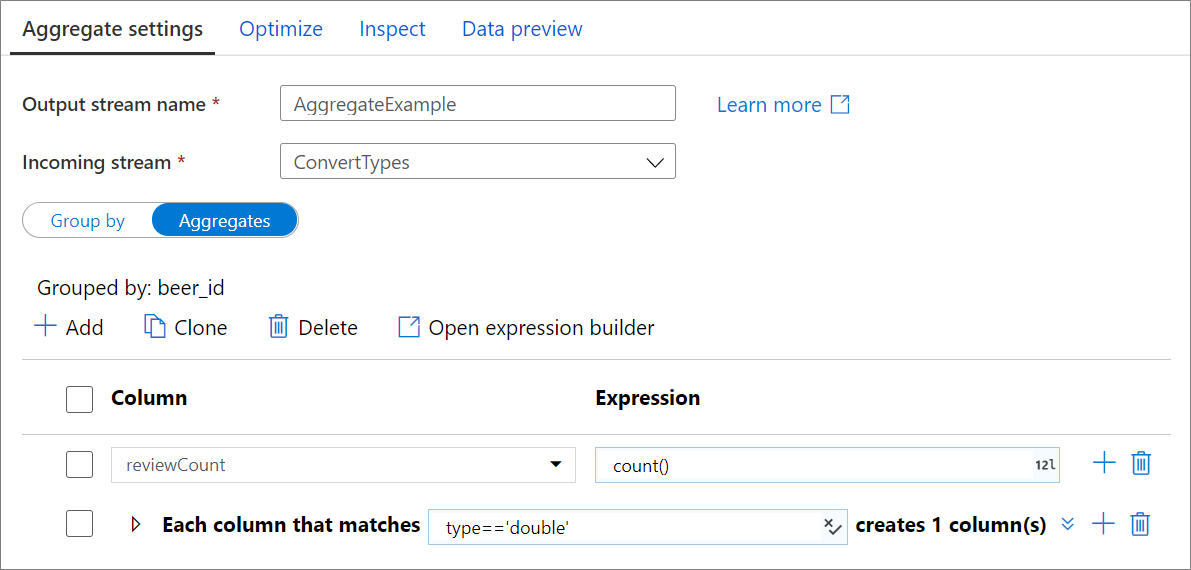
Přejděte na kartu Agregace a sestavte agregační výrazy. Existující sloupec můžete přepsat agregací nebo vytvořit nové pole s novým názvem. Výraz agregace se zadává do pravého pole vedle selektoru názvů sloupců. Pokud chcete výraz upravit, klikněte na textové pole a otevřete tvůrce výrazů. Pokud chcete přidat další agregované sloupce, klikněte na Přidat nad seznam sloupců nebo na ikonu plus vedle existujícího agregovaného sloupce. Zvolte buď Přidat sloupec , nebo Přidat vzor sloupce. Každý agregační výraz musí obsahovat aspoň jednu agregační funkci.
Poznámka:
V režimu ladění tvůrce výrazů nemůže vytvářet náhledy dat s agregačními funkcemi. Pokud chcete zobrazit náhledy dat pro agregované transformace, zavřete tvůrce výrazů a prohlédněte si data na kartě Náhled dat.
Vzory sloupců
Pomocí vzorů sloupců použijte stejnou agregaci u sady sloupců. To je užitečné, pokud chcete zachovat mnoho sloupců ze vstupního schématu, protože se ve výchozím nastavení zahodí. Heuristické použití, jako first() je zachování vstupních sloupců prostřednictvím agregace.
Opětovné připojení řádků a sloupců
Agregační transformace se podobají agregačním dotazům výběrů SQL. Sloupce, které nejsou součástí vaší skupiny podle klauzule nebo agregačních funkcí, neprojdou výstupem agregované transformace. Pokud chcete do agregovaného výstupu zahrnout další sloupce, proveďte jednu z následujících metod:
- Použijte agregační funkci, například
last()nebofirst()k zahrnutí tohoto dalšího sloupce. - Znovu připojte sloupce k výstupnímu streamu pomocí vzoru samoobslužného spojení.
Odebrání duplicitních řádků
Běžným použitím agregační transformace je odebrání nebo identifikace duplicitních položek ve zdrojových datech. Tento proces se označuje jako odstranění duplicitních dat. Na základě sady skupin podle klíčů použijte heuristická volba k určení, který duplicitní řádek chcete zachovat. Běžné heuristiky jsou first(), last(), max()a min(). Pomocí vzorů sloupců můžete pravidlo použít pro každý sloupec s výjimkou sloupců seskupit podle sloupců.
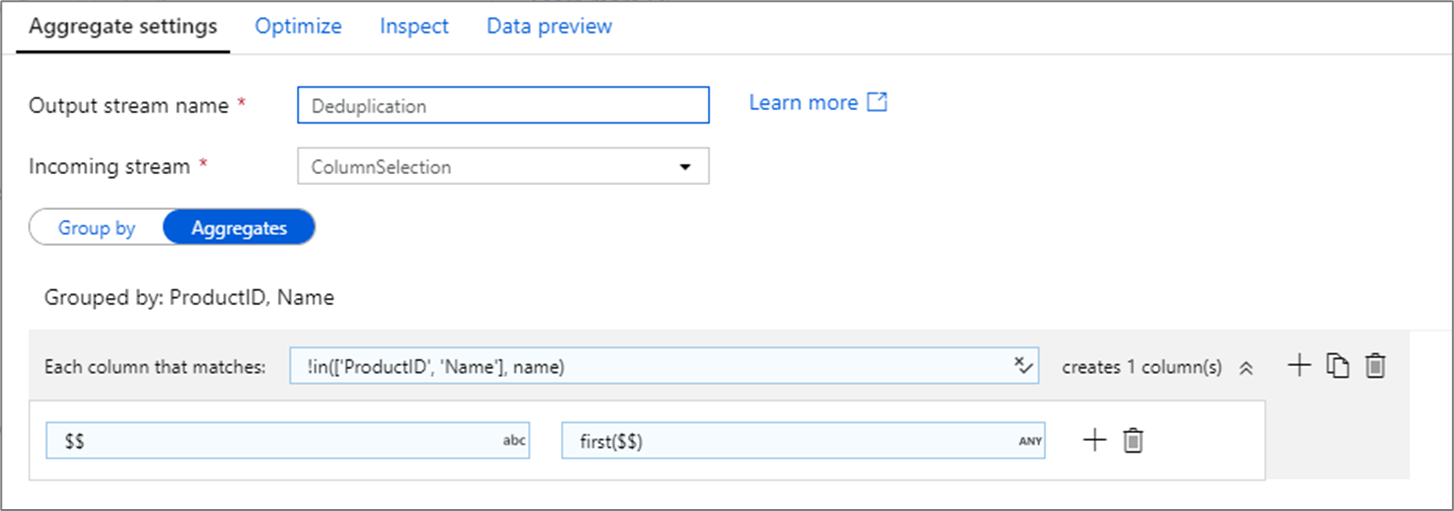
Ve výše uvedeném příkladu se sloupce ProductID používají Name k seskupení. Pokud mají dva řádky stejné hodnoty pro tyto dva sloupce, považují se za duplicitní. V této agregační transformaci se hodnoty prvního řádku shodují a všechny ostatní se zahodí. Pomocí syntaxe vzoru sloupce jsou všechny sloupce, jejichž názvy nejsou ProductID , a Name jsou namapovány na jejich existující název sloupce a mají hodnotu prvních odpovídajících řádků. Výstupní schéma je stejné jako vstupní schéma.
Ve scénářích count() ověření dat je možné funkci použít ke zjištění počtu duplicit.
Skript toku dat
Syntaxe
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
Příklad
Následující příklad přebírá příchozí datový proud MoviesYear a seskupuje řádky podle sloupce year. Transformace vytvoří agregovaný sloupec avgrating , který se vyhodnotí jako průměr sloupce Rating. Tato agregační transformace má název AvgComedyRatingsByYear.
V uživatelském rozhraní vypadá tato transformace jako na následujícím obrázku:
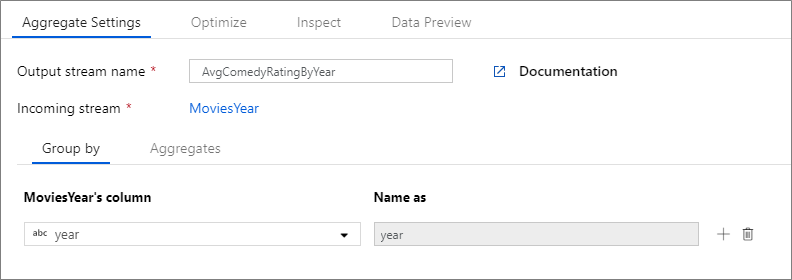
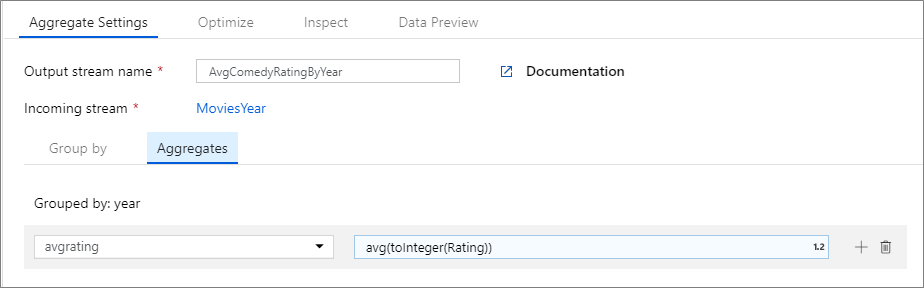
Skript toku dat pro tuto transformaci je v následujícím fragmentu kódu.
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
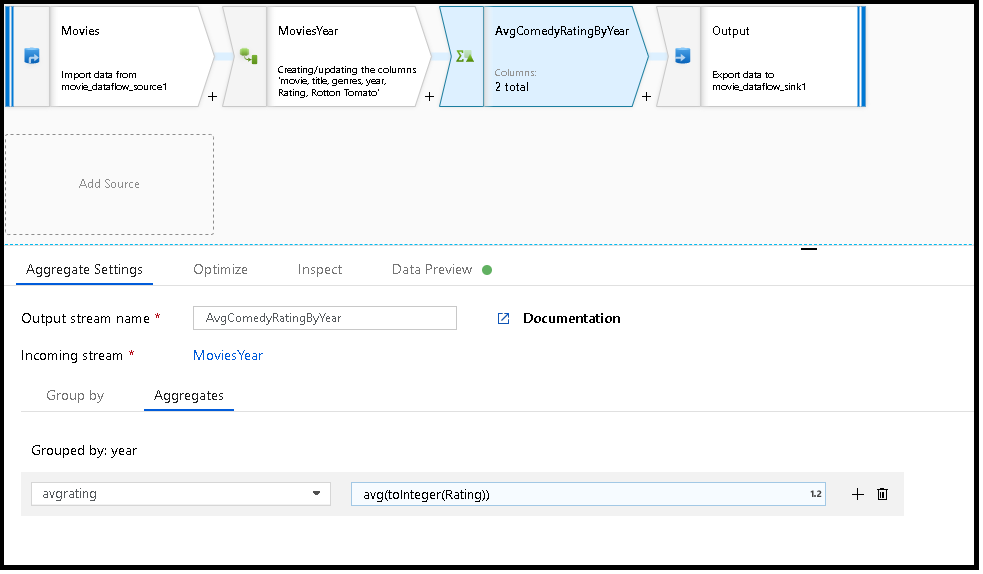
MoviesYear: Odvozený sloupec definující sloupce roku a nadpisu AvgComedyRatingByYear: Agregace transformace pro průměrné hodnocení comedies seskupených podle roku avgrating: Název nového sloupce, který se vytváří pro agregovanou hodnotu
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
Související obsah
- Definování agregace založené na okně pomocí transformace okna