Vysvětlení délky cest ve službě Azure NetApp Files
Délka souboru a cesty odkazuje na počet znaků Unicode v cestě k souboru, včetně adresářů. Toto omezení je faktorem délky jednotlivých znaků, které jsou určeny velikostí znaku v bajtech. Například NFS a SMB umožňují součásti cesty 255 bajtů. Formát kódování souboru amerického standardního kódu pro výměnu informací (ASCII) používá 8bitové kódování, což znamená, že součásti cesty k souboru (například název souboru nebo složky) v ASCII můžou být až 255 znaků, protože znaky ASCII mají velikost 1 bajt.
Následující tabulka ukazuje podporované délky komponent a cest ve svazcích Azure NetApp Files:
| Komponenta | NFS | SMB |
|---|---|---|
| Velikost komponenty cesty | 255 bajtů | 255 bajtů |
| Velikost délky cesty | Bez omezení | Výchozí: 255 bajtů Maximum v novějších verzích Windows: 32 767 bajtů |
| Maximální velikost cesty pro transversální | 4 096 bajtů | 255 bajtů |
Poznámka:
Svazky se dvěma protokoly používají nejnižší maximální hodnotu.
Pokud je \\SMB-SHAREnázev sdílené složky SMB, přidá název sdílené složky k délce cesty 11 znaků Unicode, protože každý znak je 1 bajt. Pokud je \\SMB-SHARE\apps\archive\filecesta ke konkrétnímu souboru , je to 29 znaků Unicode; každý znak, včetně lomítek, je 1 bajt. U připojení NFS platí stejné koncepty. Cesta připojení /AzureNetAppFiles je 17 znaků Unicode o 1 bajtech.
Azure NetApp Files podporuje stejnou délku cesty pro sdílené složky SMB, které moderní servery s Windows podporují: až 32 767 bajtů. V závislosti na verzi klienta windows ale některé aplikace nemůžou podporovat cesty delší než 260 bajtů. Jednotlivé součásti cesty (hodnoty mezi lomítky, například názvy souborů nebo složek) podporují až 255 bajtů. Například název souboru s velkým písmenem latinky "A" (který zabírá 1 bajt na znak) v cestě k souboru v Azure NetApp Files nesmí překročit 255 znaků.
# mkdir 256charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
mkdir: cannot create directory ‘256charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa’: File name too long
# mkdir 255charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
# ls | grep 255
255charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
Rozlišování velikostí znaků
Nástroj Pro Linux uniutils lze použít k vyhledání bajtové velikosti znaků Unicode zadáním více instancí instance znaku a zobrazením pole bajtů .
Příklad 1: Velké písmeno latinky A se při každém použití zvýší o 1 bajt (s jednou šestnáctkovou hodnotou 41, která je v rozsahu 0–255 znaků ASCII).
# printf %b 'AAA' | uniname
character byte UTF-32 encoded as glyph name
0 0 000041 41 A LATIN CAPITAL LETTER A
1 1 000041 41 A LATIN CAPITAL LETTER A
2 2 000041 41 A LATIN CAPITAL LETTER A
Výsledek 1: Název AAA používá 3 bajty z 255.
Příklad 2: Japonský znak 字 zvýší 3 bajty každé instance. Můžete to také vypočítat pomocí 3 samostatných šestnáctkových hodnot kódu (E5, AD, 97) v zakódovaném poli. Každá šestnáctková hodnota představuje 1 bajt:
# printf %b '字字字' | uniname
character byte UTF-32 encoded as glyph name
0 0 005B57 E5 AD 97 字 CJK character Nelson 1281
1 3 005B57 E5 AD 97 字 CJK character Nelson 1281
2 6 005B57 E5 AD 97 字 CJK character Nelson 1281
Výsledek 2: Soubor s názvem 字字字 používá 9 bajtů z 255.
Příklad 3: Písmeno Ä s diaerézou používá 2 bajty na instanci (C3 + 84).
# printf %b 'ÄÄÄ' | uniname
character byte UTF-32 encoded as glyph name
0 0 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
1 2 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
2 4 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
Výsledek 3: Soubor s názvem ÄÄÄ používá 6 bajtů z 255.
Příklad 4: Speciální znak, například 😃 emoji, spadá do nedefinované oblasti, která překračuje 0 až 3 bajty používané pro znaky Unicode. V důsledku toho používá náhradní dvojici pro kódování znaků. V tomto případě každá instance znaku používá 4 bajty.
# printf %b '😃😃😃' | uniname
character byte UTF-32 encoded as glyph name
0 0 01F603 F0 9F 98 83 😃 Character in undefined range
1 4 01F603 F0 9F 98 83 😃 Character in undefined range
2 8 01F603 F0 9F 98 83 😃 Character in undefined range
Výsledek 4: Soubor s názvem 😃😃😃 používá 12 bajtů z 255.
Většina emoji spadá do rozsahu 4 bajtů, ale může jít až o 7 bajtů. Z více než tisíc standardních emoji je přibližně 180 v základní vícejazyčné rovině (BMP), což znamená, že je možné je zobrazit jako text nebo emoji v Azure NetApp Files v závislosti na podpoře klienta pro daný typ jazyka.
Podrobnější informace o BMP a dalších rovinách Unicode najdete v tématu Principy jazyků svazků v Azure NetApp Files.
Dopad bajtů znaků na délky cesty
Délka cesty je sice považována za počet znaků v názvu souboru nebo složky, ale ve skutečnosti se jedná o velikost podporovaných bajtů v cestě. Vzhledem k tomu, že každý znak přidává k názvu bajtovou velikost, podporují různé znakové sady v různých jazycích různé délky názvu souboru.
Zvažte následující scénáře:
Soubor nebo složka pro název souboru opakuje znak latinky "A". (například AAAAAAAAAAAA)
Vzhledem k tomu, že "A" používá 1 bajt a 255 bajtů je limit velikosti součásti cesty, pak by v názvu souboru bylo povoleno 255 instancí "A".
Soubor nebo složka opakuje japonský znak 字 v názvu.
Vzhledem k tomu, že "字" má velikost 3 bajty, limit délky názvu souboru by byl 85 instancí 字 (3 bajt * 85 = 255 bajtů) nebo celkem 85 znaků.
Soubor nebo složka se zopakuje v názvu emoji tváře (😃).
Grinning face emoji (😃) používá 4 bajty, což znamená název souboru pouze s tímto emoji by umožnil celkem 64 znaků (255 bajtů/4 bajty).
- Soubor nebo složka používá kombinaci různých znaků (tj. Name字😃).
Pokud se v názvu souboru nebo složky používají různé znaky s různými velikostmi bajtů, faktory velikosti bajtů jednotlivých znaků v délce souboru nebo složky. Název souboru nebo složky s názvem字😃 by používal 1+1+1+1+3+4 bajty (11 bajtů) celkové délky 255 bajtů.
Speciální koncepty emoji
Ve klasifikaci BMP existují speciální emoji, jako je například emoji s příznakem: emoji se v závislosti na podpoře klienta vykresluje jako text nebo obrázek. Pokud klient označení obrázku nepodporuje, místo toho používá regionální textová označení.
Například příznak USA používá znaky "nás" (které se podobají latince znaků U+S, ale ve skutečnosti jsou speciálními znaky, které používají různé kódování). Jednoname zobrazuje rozdíly mezi znaky.
# printf %b 'US' | uniname
character byte UTF-32 encoded as glyph name
0 0 000055 55 U LATIN CAPITAL LETTER U
1 1 000053 53 S LATIN CAPITAL LETTER S
# printf %b '🇺🇸' | uniname
character byte UTF-32 encoded as glyph name
0 0 01F1FA F0 9F 87 BA 🇺 Character in undefined range
1 4 01F1F8 F0 9F 87 B8 🇸 Character in undefined range
Znaky určené pro emoji příznaků se překládají na obrázky v podporovaných systémech, ale zůstávají jako textové hodnoty v nepodporovaných systémech. Tyto znaky používají 4 bajty na každý znak pro celkem 8 bajtů při použití emoji příznaku. V názvu souboru (255 bajtů/8 bajtů) se proto povoluje celkem 31 emoji příznaků.
Omezení cest SMB
Ve výchozím nastavení podporují servery Windows a klienti délku cesty až 260 bajtů, ale skutečná délka cesty k souboru je kratší kvůli metadatům přidaných do cest systému Windows, jako <NUL> jsou hodnoty a informace o doméně.
Při překročení limitu cesty ve Windows se zobrazí dialogové okno:
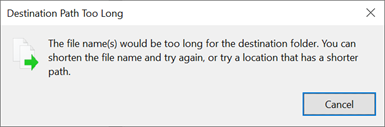
Délky cest SMB je možné prodloužit při použití Windows 10/Windows Serveru 2016 verze 1607 nebo novější změnou hodnoty registru, jak je popsáno v omezení maximální délky cesty. Při změně této hodnoty se délka cesty může rozšířit až na 32 767 bajtů (minus hodnoty metadat).
Jakmile je tato funkce povolená, musíte přistupovat ke sdílené složce SMB pomocí \\?\ cesty, aby byla povolena delší délka cesty. Tato metoda nepodporuje cesty UNC, takže sdílená složka SMB musí být namapována na písmeno jednotky.
Použití \\?\Z: místo toho umožňuje přístup a podporuje delší cesty k souborům.

Poznámka:
Systém Windows CMD v současné době nepodporuje použití \\?\.
Alternativní řešení, pokud nejde zvětšit maximální délku cesty
Pokud není možné povolit maximální délku cesty v prostředí Windows nebo jsou verze klienta windows příliš nízké, existuje alternativní řešení. Sdílenou složku SMB můžete připojit hlouběji do adresářové struktury a snížit délku cesty dotazů.
Například místo mapování \\NAS-SHARE\AzureNetAppFiles na Z:, mapovat \\NAS-SHARE\AzureNetAppFiles\folder1\folder2\folder3\folder4 na Z:.
Omezení cesty NFS
Omezení cesty NFS u svazků Azure NetApp Files mají stejný limit 255 bajtů pro jednotlivé komponenty cest. Každá komponenta se ale vyhodnocuje po jednom a může zpracovat až 4 096 bajtů na požadavek s téměř neomezenou celkovou délkou cesty. Pokud je například každá komponenta cesty 255 bajtů, klient NFS může vyhodnotit až 15 komponent na požadavek (včetně / znaků). cd Například požadavek na cestu nad limitem 4 096 bajtů přináší chybovou zprávu "Název souboru je příliš dlouhý".
Ve většině případů jsou znaky Unicode 1 bajt nebo méně, takže limit 4 096 bajtů odpovídá 4 096 znakům. Pokud je znak větší než 1 bajt, délka cesty je menší než 4 096 znaků. Počet znaků s velikostí větší než 1 bajt je větší než celkový počet znaků než 1 bajt.
Maximální délka cesty se dá dotazovat pomocí getconf PATH_MAX /NFSmountpoint příkazu.
Poznámka:
Limit je definován v limits.h souboru v klientovi NFS. Tyto limity byste neměli upravovat.
Aspekty svazku se dvěma protokoly
Při použití služby Azure NetApp Files pro přístup k duálnímu protokolu může rozdíl v tom, jak se délky cest zpracovávají v nfs a protokolech SMB, vytvářet nekompatibility mezi soubory a složkami. Například protokol SMB systému Windows podporuje v cestě až 32 767 znaků (za předpokladu, že je v klientovi SMB povolená funkce dlouhé cesty), ale podpora systému souborů NFS může tuto velikost překročit. Pokud se v systému souborů NFS vytvoří délka cesty, která překračuje podporu protokolu SMB, klienti nebudou mít po dosažení maximální délky cesty přístup k datům. V těchto případech se při vytváření názvů souborů a složek (a hloubky cesty ke složce) pečlivě zvažte omezení délky cesty k souboru a souborům v protokolech, nebo namapujte sdílené složky SMB blíže k požadované cestě ke složce, abyste snížili délku cesty.
Místo mapování sdílené složky SMB na nejvyšší úroveň svazku přejděte dolů na cestu \\share\folder1\folder2\folder3\folder4, zvažte mapování sdílené složky SMB na celou cestu \\share\folder1\folder2\folder3\folder4. V důsledku toho se písmeno jednotky mapuje na Z: umístění do požadované složky a zmenšuje délku cesty od Z:\folder1\folder2\folder3\folder4\file do Z:\file.
Důležité informace o speciálních znakech
Svazky Azure NetApp Files používají jazykový typ C.UTF-8, který pokrývá mnoho zemí/oblastí a jazyků včetně němčiny, cyrilice, hebrejštiny a většiny čínštiny/japonštiny/korejštiny (CJK). Nejběžnější textové znaky v unicode jsou 3 bajty nebo méně. Speciální znaky, jako jsou emoji, hudební symboly a matematické symboly, jsou často větší než 3 bajty. Některé používají logiku náhradní dvojice UTF-16.
Pokud použijete znak, který Azure NetApp Files nepodporuje, může se zobrazit upozornění s žádostí o jiný název souboru.
Místo příliš dlouhého názvu tato chyba ve skutečnosti vede k příliš velké velikosti znaků, aby se svazek Azure NetApp Files mohl používat přes protokol SMB. V Azure NetApp Files pro toto omezení neexistuje žádné alternativní řešení. Další informace o speciálním zpracování znaků ve službě Azure NetApp Files najdete v tématu Chování protokolu se speciálními znakovými sadami.