Přehled možností generující brány AI ve službě Azure API Management
PLATÍ PRO: Všechny úrovně služby API Management
Tento článek představuje funkce ve službě Azure API Management, které vám pomůžou spravovat rozhraní API pro generování AI, například rozhraní API poskytovaná službou Azure OpenAI. Azure API Management poskytuje celou řadu zásad, metrik a dalších funkcí pro zvýšení zabezpečení, výkonu a spolehlivosti pro rozhraní API obsluhující vaše inteligentní aplikace. Souhrnně se těmto funkcím říká funkce brány generující umělé inteligence (GenAI) pro vaše rozhraní API pro generování AI.
Poznámka:
- Tento článek se zaměřuje na možnosti správy rozhraní API vystavených službou Azure OpenAI. Řada funkcí brány GenAI se vztahuje na jiná rozhraní API pro velký jazykový model (LLM), včetně těch dostupných prostřednictvím rozhraní API pro odvozování modelů Azure AI.
- Možnosti generující brány AI jsou funkce stávající brány rozhraní API služby API Management, nikoli samostatné brány rozhraní API. Další informace o službě API Management najdete v přehledu služby Azure API Management.
Problémy při správě rozhraní API pro generování AI
Jedním z hlavních prostředků, které máte ve službách generující umělé inteligence, jsou tokeny. Služba Azure OpenAI přiřazuje kvótu pro nasazení modelu vyjádřená v tokenech za minutu (TPM), která se pak distribuuje mezi uživatele modelu – například různé aplikace, vývojářské týmy, oddělení v rámci společnosti atd.
Azure usnadňuje připojení jedné aplikace ke službě Azure OpenAI: Můžete se připojit přímo pomocí klíče rozhraní API s limitem TPM nakonfigurovaným přímo na úrovni nasazení modelu. Když ale začnete s růstem portfolia aplikací, zobrazí se více aplikací, které volají jednotlivé nebo dokonce více koncových bodů služby Azure OpenAI nasazených jako instance jednotek propustnosti s průběžnými platbami nebo zřízené jednotky propustnosti (PTU). To přináší určité výzvy:
- Jak se sleduje využití tokenů napříč více aplikacemi? Dají se křížové poplatky vypočítat pro více aplikací nebo týmů, které používají modely služby Azure OpenAI?
- Jak zajistíte, aby jedna aplikace nespotřebovává celou kvótu TPM a ostatní aplikace neměly možnost používat modely služby Azure OpenAI?
- Jak se klíč rozhraní API bezpečně distribuuje napříč více aplikacemi?
- Jak se zatížení distribuuje napříč několika koncovými body Azure OpenAI? Můžete zajistit, aby se potvrzená kapacita v PTU vyčerpala, než se vrátíte k instancím průběžných plateb?
Zbytek tohoto článku popisuje, jak vám může azure API Management pomoct tyto problémy vyřešit.
Import prostředku služby Azure OpenAI jako rozhraní API
Importujte rozhraní API z koncového bodu služby Azure OpenAI do služby Azure API Management pomocí prostředí s jedním kliknutím. Služba API Management zjednodušuje proces onboardingu tím, že automaticky naimportuje schéma OpenAPI pro rozhraní Azure OpenAI API a nastaví ověřování do koncového bodu Azure OpenAI pomocí spravované identity a odebere potřebu ruční konfigurace. V rámci stejného uživatelsky přívětivého prostředí můžete předem nakonfigurovat zásady pro limity tokenů a generovat metriky tokenů.

Zásady omezení tokenů
Nakonfigurujte zásady omezení tokenu Azure OpenAI pro správu a vynucování limitů pro jednotlivé příjemce rozhraní API na základě využití tokenů služby Azure OpenAI. Pomocí této zásady můžete nastavit limity vyjádřené v tokenech za minutu (TPM).
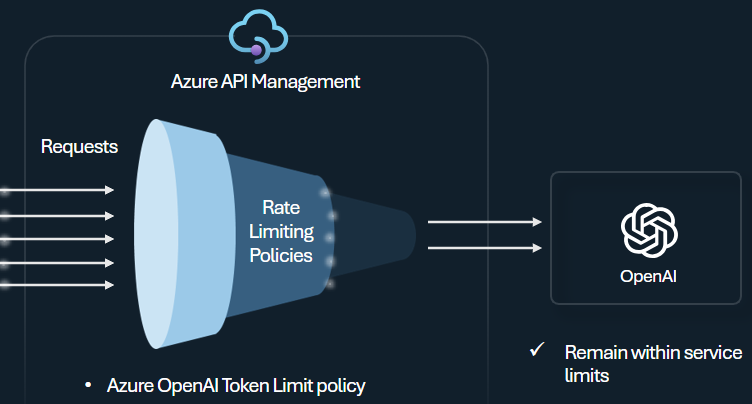
Tato zásada poskytuje flexibilitu při přiřazování limitů založených na tokenech na jakémkoli klíči čítače, jako je klíč předplatného, původní IP adresa nebo libovolný klíč definovaný výrazem zásad. Zásada také umožňuje předem přepočítat tokeny výzvy na straně služby Azure API Management, což minimalizuje zbytečné požadavky na back-end služby Azure OpenAI, pokud výzva už limit překročí.
Následující základní příklad ukazuje, jak nastavit limit TPM 500 na klíč předplatného:
<azure-openai-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</azure-openai-token-limit>
Tip
Aby bylo možné spravovat a vynucovat limity tokenů pro rozhraní API LLM dostupné prostřednictvím rozhraní API pro odvozování modelů Azure AI, poskytuje služba API Management ekvivalentní zásady omezení tokenů llm.
Generování zásad metrik tokenů
Zásada metriky tokenu Azure OpenAI odesílá metriky do Application Insights o spotřebě tokenů LLM prostřednictvím rozhraní API služby Azure OpenAI. Tato zásada poskytuje přehled o využití modelů služby Azure OpenAI napříč několika aplikacemi nebo uživateli rozhraní API. Tato zásada může být užitečná pro scénáře vracení peněz, monitorování a plánování kapacity.
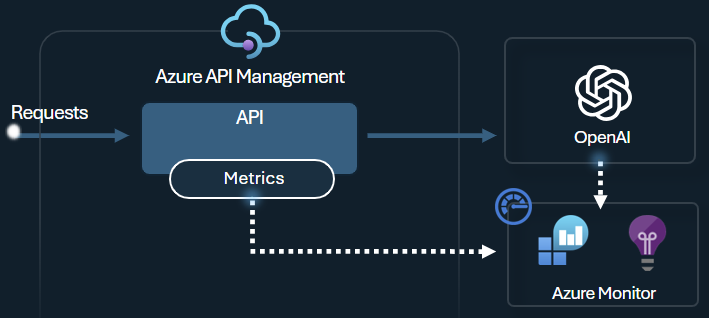
Tato zásada zachycuje metriky využití výzev, dokončení a celkového využití tokenů a odesílá je do oboru názvů Application Insights podle vašeho výběru. Kromě toho můžete nakonfigurovat nebo vybrat z předdefinovaných dimenzí rozdělení metrik využití tokenů, abyste mohli analyzovat metriky podle ID předplatného, IP adresy nebo vlastní dimenze podle vašeho výběru.
Například následující zásada odesílá metriky do Application Insights rozdělené podle IP adresy klienta, rozhraní API a uživatele:
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
Tip
Pokud chcete odesílat metriky pro rozhraní LLM API dostupná prostřednictvím rozhraní API pro odvozování modelů Azure AI, poskytuje služba API Management ekvivalentní zásady metriky llm-emit-token-metric .
Back-endový nástroj pro vyrovnávání zatížení a jistič
Jednou z výzev při vytváření inteligentních aplikací je zajistit odolnost aplikací vůči selháním back-endu a zvládnout vysoké zatížení. Konfigurací koncových bodů služby Azure OpenAI pomocí back-endů ve službě Azure API Management můžete vyrovnávat zatížení napříč nimi. Můžete také definovat pravidla jističe, která přestanou předávat požadavky back-endům služby Azure OpenAI, pokud nereagují.
Back-endový nástroj pro vyrovnávání zatížení podporuje vyrovnávání zatížení na základě kruhového dotazování, váženého a prioritního vyrovnávání zatížení. Díky tomu můžete flexibilně definovat strategii distribuce zatížení, která vyhovuje vašim konkrétním požadavkům. Například definujte priority v konfiguraci nástroje pro vyrovnávání zatížení, abyste zajistili optimální využití konkrétních koncových bodů Azure OpenAI, zejména těch zakoupených jako PTU.
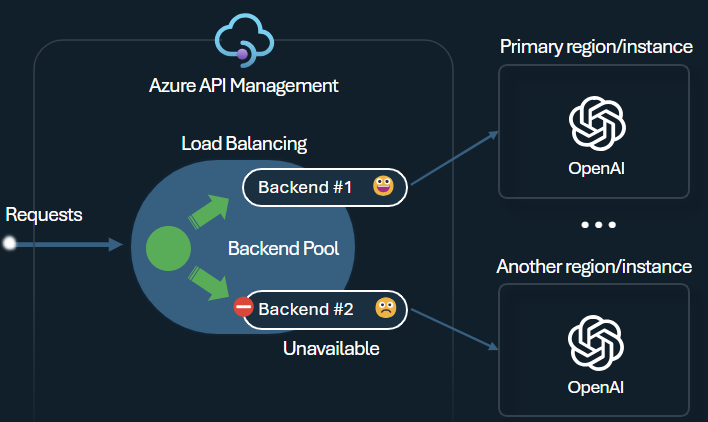
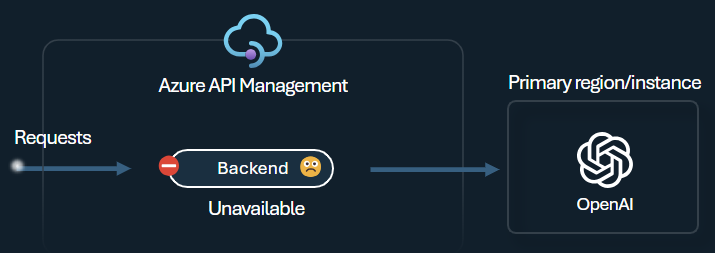
Jistič back-endu obsahuje dynamickou dobu trvání jízdy a používá hodnoty z hlavičky Opakovat až po poskytnutí back-endu. To zajišťuje přesné a včasné obnovení back-endů, což maximalizuje využití back-endů s prioritou.
Zásady sémantického ukládání do mezipaměti
Nakonfigurujte sémantické zásady ukládání do mezipaměti Azure OpenAI tak, aby optimalizovaly použití tokenu uložením dokončování pro podobné výzvy.
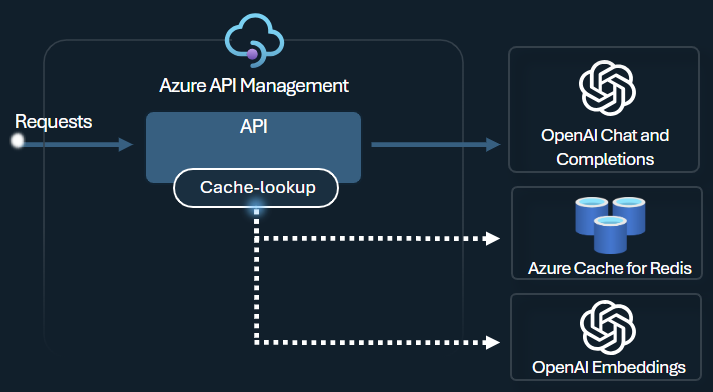
Ve službě API Management povolte sémantické ukládání do mezipaměti pomocí Azure Redis Enterprise nebo jiné externí mezipaměti kompatibilní s RediSearch a onboarded to Azure API Management. Pomocí rozhraní API pro vkládání služby Azure OpenAI ukládá zásady azure-openai-smantic-cache-store a azure-openai-semantic-cache-lookup a načítá sémanticky podobné dokončování výzvy z mezipaměti. Tento přístup zajišťuje opakované použití dokončení, což vede ke snížení spotřeby tokenů a zvýšení výkonu odezvy.
Tip
Aby bylo možné povolit sémantické ukládání do mezipaměti pro rozhraní LLM API dostupná prostřednictvím rozhraní API pro odvozování modelů Azure AI, poskytuje služba API Management ekvivalentní zásady llm-semantic-cache-store-policy a zásady llm-semantic-cache-lookup-policy .
Testovací prostředí a ukázky
- Testovací prostředí pro možnosti brány GenAI služby Azure API Management
- Azure API Management (APIM) – Ukázka Azure OpenAI (Node.js)
- Ukázkový kód Pythonu pro použití Azure OpenAI se službou API Management
Aspekty architektury a návrhu
- Referenční architektura brány GenAI s využitím služby API Management
- Akcelerátor cílových zón brány centra AI
- Návrh a implementace řešení brány s využitím prostředků Azure OpenAI
- Použití brány před několika nasazeními nebo instancemi Azure OpenAI
Související obsah
- Blog: Představení funkcí GenAI ve službě Azure API Management
- Blog: Integrace zabezpečení obsahu Azure se službou API Management pro koncové body Azure OpenAI
- Školení: Správa rozhraní API pro generování AI pomocí služby Azure API Management
- Inteligentní vyrovnávání zatížení pro koncové body OpenAI a Azure API Management
- Ověřování a autorizace přístupu k rozhraním API Azure OpenAI pomocí služby Azure API Management