Konfigurace zásad Apache Rangeru pro Spark SQL ve službě HDInsight s balíčkem zabezpečení podniku
Tento článek popisuje, jak nakonfigurovat zásady Apache Ranger pro Spark SQL s balíčkem zabezpečení podniku ve službě HDInsight.
V tomto článku získáte informace o těchto tématech:
- Vytvořte zásady Apache Rangeru.
- Ověřte použité zásady Ranger.
- Použijte pokyny pro nastavení Apache Rangeru pro Spark SQL.
Požadavky
- Cluster Apache Spark ve službě HDInsight verze 5.1 s balíčkem zabezpečení podniku
Připojení do uživatelského rozhraní pro správu Apache Ranger
Z prohlížeče se připojte k uživatelskému rozhraní správce Ranger pomocí adresy URL
https://ClusterName.azurehdinsight.net/Ranger/.Změňte
ClusterNamenázev clusteru Spark.Přihlaste se pomocí svých přihlašovacích údajů správce Microsoft Entra. Přihlašovací údaje správce Microsoft Entra nejsou stejné jako přihlašovací údaje clusteru HDInsight nebo přihlašovací údaje SSH (Linux HDInsight node Secure Shell).
Vytvoření uživatelů domén
Informace o tom, jak vytvářet sparkuser uživatele domény, najdete v tématu Vytvoření clusteru HDInsight pomocí ESP. V produkčním scénáři uživatelé domény pocházejí z vašeho tenanta Microsoft Entra.
Vytvoření zásady Rangeru
V této části vytvoříte dvě zásady Rangeru:
- Zásady přístupu pro přístup ze
hivesampletableSpark SQL - Zásady maskování pro obfuskování sloupců v
hivesampletable
Vytvoření zásady přístupu Ranger
Otevřete uživatelské rozhraní správce Ranger.
V části HADOOP SQL vyberte hive_and_spark.
Na kartě Přístup vyberte Přidat novou zásadu.
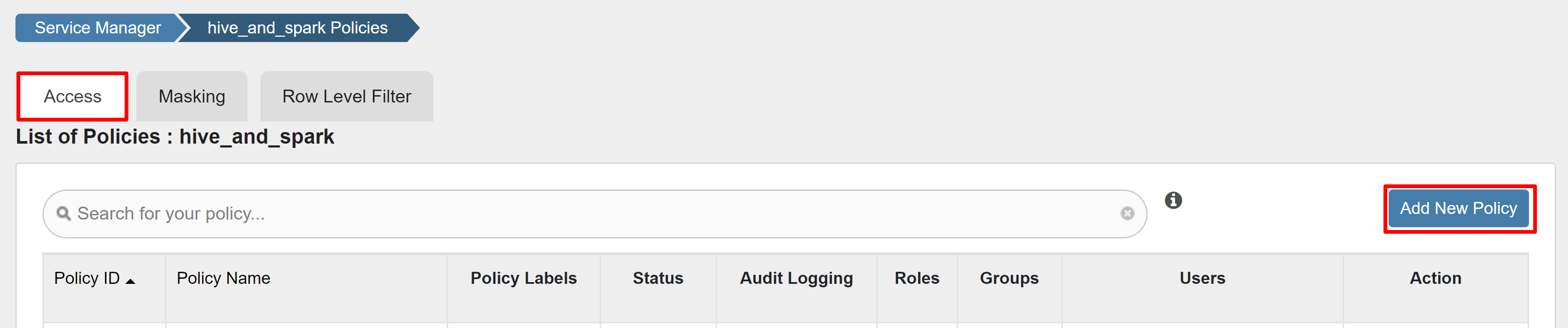
Zadejte následující hodnoty:
Vlastnost Hodnota Název zásady read-hivesampletable-all database default table hivesampletable column * Vybrat uživatele sparkuserOprávnění Vyberte jednu z možností. 
Pokud uživatel domény není automaticky vyplněný pro výběr uživatele, počkejte chvíli, než se Ranger synchronizuje s Microsoft Entra ID.
Výběrem možnosti Přidat zásadu uložte.
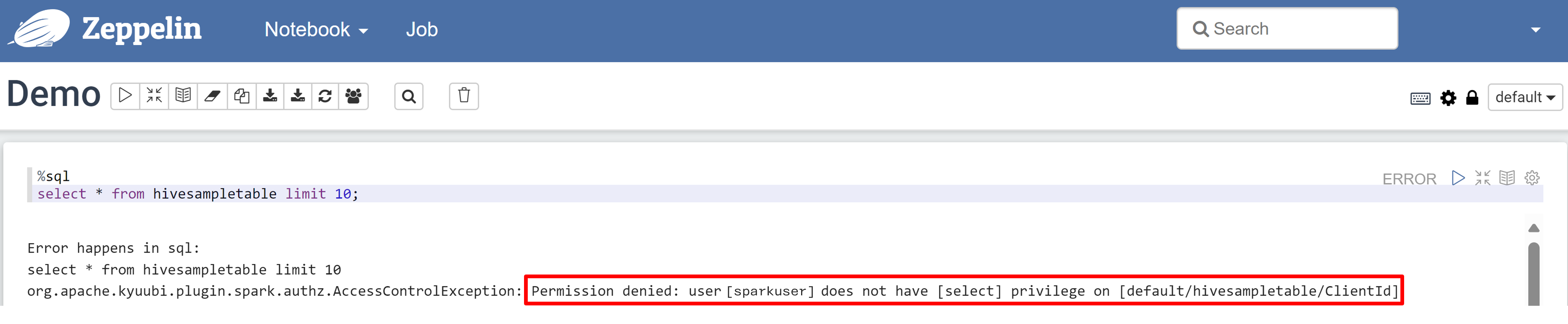
Otevřete poznámkový blok Zeppelin a spuštěním následujícího příkazu ověřte zásadu:
%sql select * from hivesampletable limit 10;Tady je výsledek před uplatněním zásady:
Tady je výsledek po použití zásady:
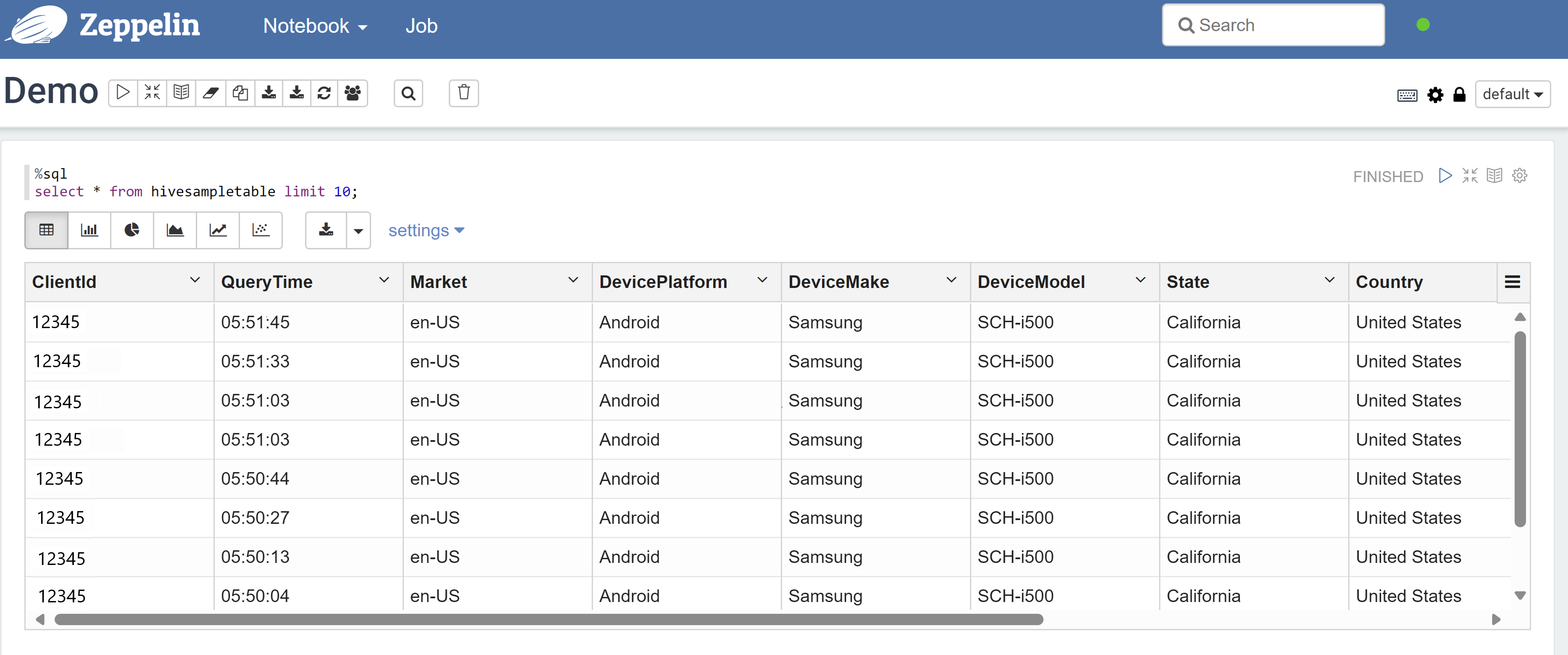




Vytvoření zásady maskování Rangeru
Následující příklad ukazuje, jak vytvořit zásadu pro maskování sloupce:
Na kartě Masking (Masking) vyberte Add New Policy (Přidat novou zásadu).
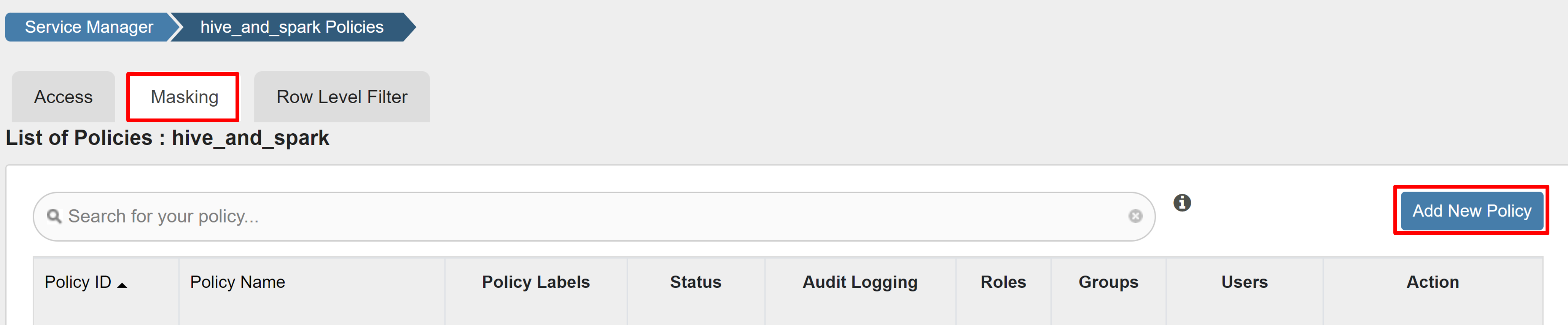
Zadejte následující hodnoty:
Vlastnost Hodnota Název zásady Mask-hivesampletable Databáze Hive default Tabulka Hive hivesampletable Sloupec Hive devicemake Vybrat uživatele sparkuserTypy přístupu Vyberte jednu z možností. Výběr možnosti maskování Hodnoty hash 
Výběrem možnosti Uložit zásadu uložte.
Otevřete poznámkový blok Zeppelin a spuštěním následujícího příkazu ověřte zásadu:
%sql select clientId, deviceMake from hivesampletable;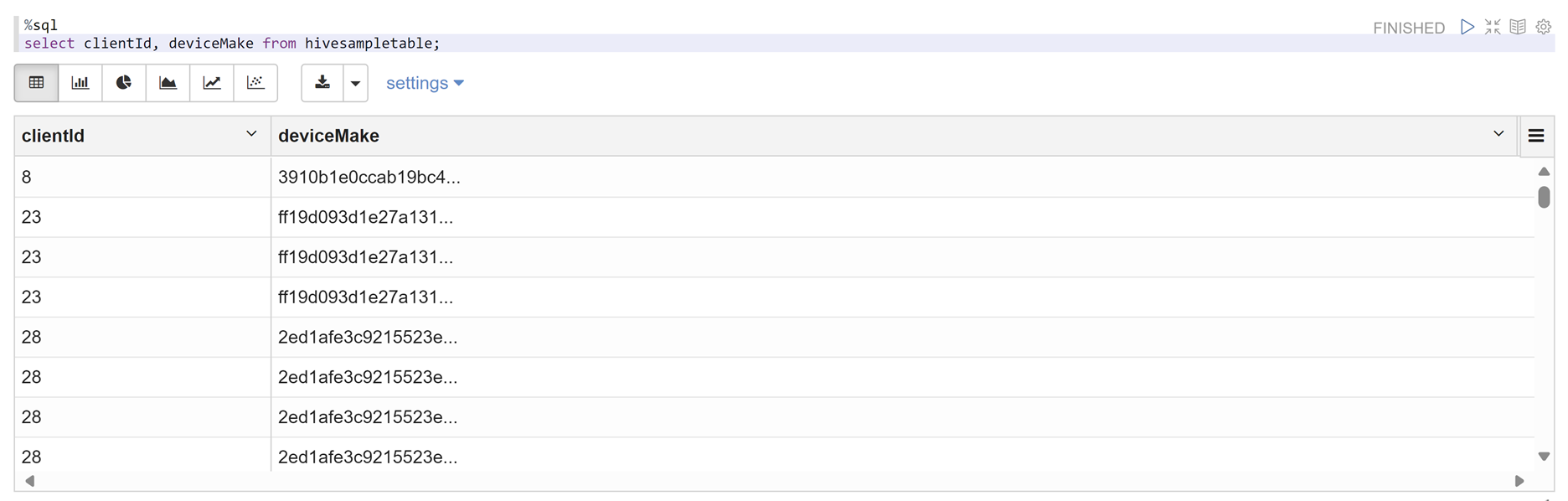



Poznámka:
Ve výchozím nastavení jsou zásady Pro Hive a Spark SQL běžné v Rangeru.
Použití pokynů pro nastavení Apache Rangeru pro Spark SQL
Následující scénáře prozkoumávají pokyny pro vytvoření clusteru HDInsight 5.1 Spark pomocí nové databáze Ranger a použití existující databáze Ranger.
Scénář 1: Použití nové databáze Ranger při vytváření clusteru HDInsight 5.1 Spark
Když k vytvoření clusteru použijete novou databázi Ranger, vytvoří se příslušné úložiště Ranger obsahující zásady Rangeru pro Hive a Spark pod názvem hive_and_spark ve službě Hadoop SQL v databázi Ranger.

Pokud zásady upravíte, použijí se pro Hive i Spark.
Zvažte tyto body:
Pokud máte dvě databáze metastoru se stejným názvem, které se používají pro katalogy Hive (například DB1) i Sparku (například DB1):
- Pokud Spark používá katalog Sparku (
metastore.catalog.default=spark), použijí se zásady pro databázi DB1 katalogu Spark. - Pokud Spark používá katalog Hive (
metastore.catalog.default=hive), použijí se zásady pro databázi DB1 katalogu Hive.
Z pohledu Rangeru neexistuje způsob, jak rozlišovat databáze 1 katalogu Hive a Spark.
V takových případech doporučujeme:
- Použijte katalog Hive pro Hive i Spark.
- Pro katalogy Hive i Spark udržujte různé názvy databází, tabulek a sloupců, aby se zásady neuplatnily na databáze napříč katalogy.
- Pokud Spark používá katalog Sparku (
Pokud používáte katalog Hive pro Hive i Spark, zvažte následující příklad.
Řekněme, že vytvoříte tabulku s názvem table1 prostřednictvím Hivu s aktuálním uživatelem xyz . Vytvoří soubor systému souborů HDFS (Hadoop Distributed File System) s názvem table1.db , jehož vlastníkem je uživatel xyz .
Teď si představte, že ke spuštění relace Spark SQL použijete uživatele abc . Pokud se v této relaci uživatele abc pokusíte napsat cokoli do tabulky1, je vázána k selhání, protože vlastník tabulky je xyz.
V takovém případě doporučujeme pro aktualizaci tabulky použít stejného uživatele v Hive a Spark SQL. Tento uživatel by měl mít dostatečná oprávnění k provádění operací aktualizace.
Scénář 2: Použití existující databáze Ranger (se stávajícími zásadami) při vytváření clusteru HDInsight 5.1 Spark
Když vytvoříte cluster HDInsight 5.1 pomocí existující databáze Ranger, v této databázi se znovu vytvoří nové úložiště Ranger s názvem nového clusteru v tomto formátu: hive_and_spark.

Řekněme, že máte zásady definované v úložišti Ranger již pod názvem oldclustername_hive pro existující databázi Ranger uvnitř služby Hadoop SQL. Chcete sdílet stejné zásady v novém clusteru HDInsight 5.1 Spark. K dosažení tohoto cíle použijte následující kroky.
Poznámka:
Uživatel s oprávněními správce Ambari může provádět aktualizace konfigurace.
Otevřete uživatelské rozhraní Ambari z nového clusteru HDInsight 5.1.
Přejděte do služby Spark3 a přejděte na Konfigurace.
Otevřete konfiguraci advanced ranger-spark-security.

Nebo tuto konfiguraci můžete otevřít také v souboru /etc/spark3/conf pomocí protokolu SSH.
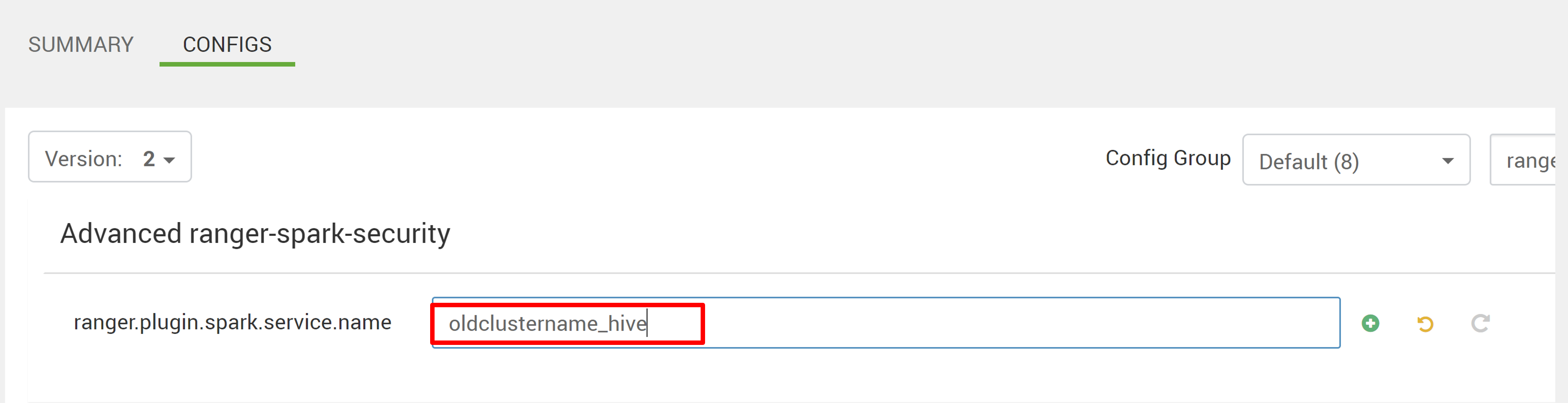
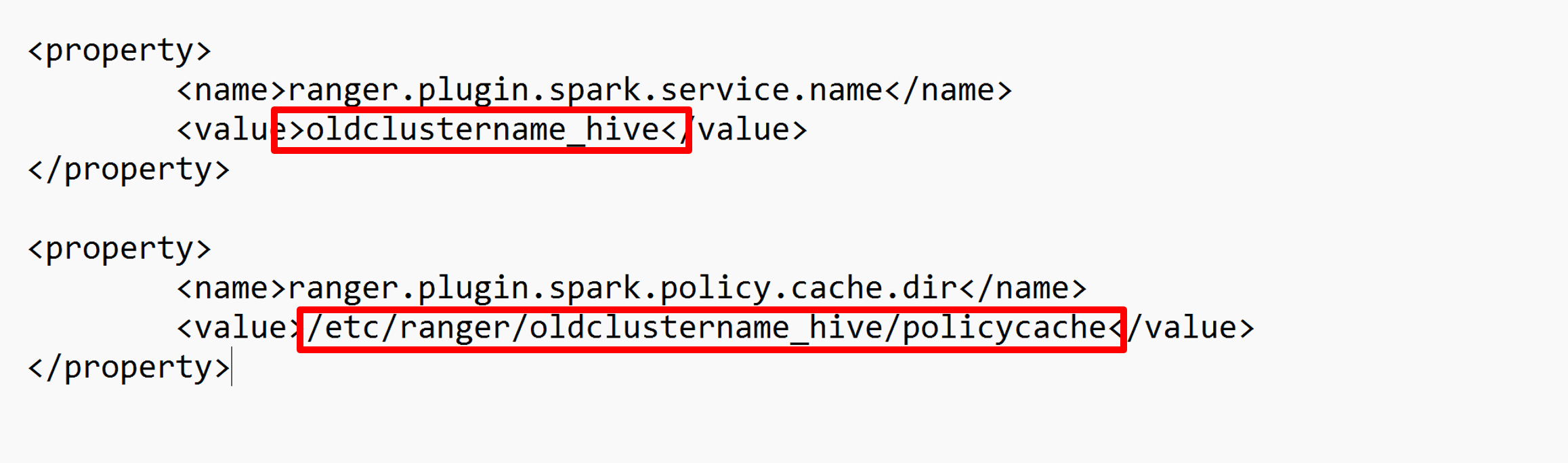
Upravte dvě konfigurace (ranger.plugin.spark.service.name a ranger.plugin.spark.policy.cache.dir) tak, aby ukazovaly na původní úložiště zásad oldclustername_hive a potom uložte konfigurace.
Ambari:
Soubor XML:
Restartujte služby Ranger a Spark z Ambari.
Otevřete uživatelské rozhraní správce Ranger a klikněte na tlačítko Upravit ve službě HADOOP SQL .
Pro oldclustername_hive službu přidejte uživatele rangersparklookup do seznamu policy.download.auth.users a tag.download.auth.users a klikněte na uložit.






Zásady se použijí u databází v katalogu Spark. Pokud chcete získat přístup k databázím v katalogu Hive:
V Ambari přejděte na Konfigurace Spark3>.
Změňte metastore.catalog.default ze Sparku na podregistr.


Známé problémy
- Integrace Apache Rangeru se SparkEM SQL nefunguje, pokud je správce Rangeru dole.
- Když v protokolech auditu Ranger najedete myší na sloupec Prostředek , nemůže se zobrazit celý dotaz, který jste spustili.